

BasWeg
-
Posts
49 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by BasWeg
-
-
On 12/1/2023 at 2:44 PM, Iker said:
The Community Applications ZnapZend plugin is currently broken because the plugin executes early in the boot process, even before the Pool is imported, mounted and working, so the plugin doesn't find any valid pools and exits early in the boot process. One way to make it work with the latest version is using the Docker version; here is my current docker-compose spec:
version: '3' services: znapzend: image: oetiker/znapzend:master container_name: znapzend hostname: znapzend-main privileged: true devices: - /dev/zfs command: ["znapzend --logto /mylogs/znapzend.log"] restart: unless-stopped volumes: - /var/log/:/mylogs/ - /etc/localtime:/etc/localtime:ro networks: - znapzend networks: znapzend: name: znapzendThe only downside is that if you are replicating data to another machine, you have to access the container and the destination machine and set up the SSH keys, or ... you have to mount a specific volume with the keys and known host in the container.
Best
Since I also use the znapzend plugin, does your solution just work with the old stored znapzend configuration?
-
I'm going to try @Marshalleqsolution:
https://forums.unraid.net/topic/41333-zfs-plugin-for-unraid/?do=findComment&comment=1250880
and-
 1
1
-
-
ok, then I need to rename all my dockers, too.
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT HDD 5.45T 1.79T 3.67T - - 2% 32% 1.00x ONLINE - NVME 928G 274G 654G - - 8% 29% 1.00x ONLINE - SSD 696G 254G 442G - - 13% 36% 1.00x ONLINE - SingleSSD 464G 16.6G 447G - - 1% 3% 1.00x ONLINE -
HDD and SSD are raidz1-0 with 3 discs each.
So, to update, I should remember the zpool status (UIDs for each array), and create arrays afterwards with these UIDS? -
Me, too. But I'm afraid if this is still working with the build in version of zfs. So, I'm still on the latest release with zfs plug-in.
My understanding is, that my solution to have the mountpoints to /mnt/ is not ok anymore? -
Hi,
sorry, but I do not get this working for my Ryzen 3700X
I've addedmodprobe.blacklist=acpi_cpufreq amd_pstate.shared_mem=1and of course the modprobe amd_pstate
amd_pstate is loaded, but cpufreq-info shows:
analyzing CPU 0: driver: amd-pstate CPUs which run at the same hardware frequency: 0 CPUs which need to have their frequency coordinated by software: 0 maximum transition latency: 131 us. available cpufreq governors: corefreq-policy, conservative, ondemand, userspace, powersave, performance, schedutil current CPU frequency is 3.59 GHz. analyzing CPU 1: driver: amd-pstateand if I look into corefreq-cli the system is always running at full speed.
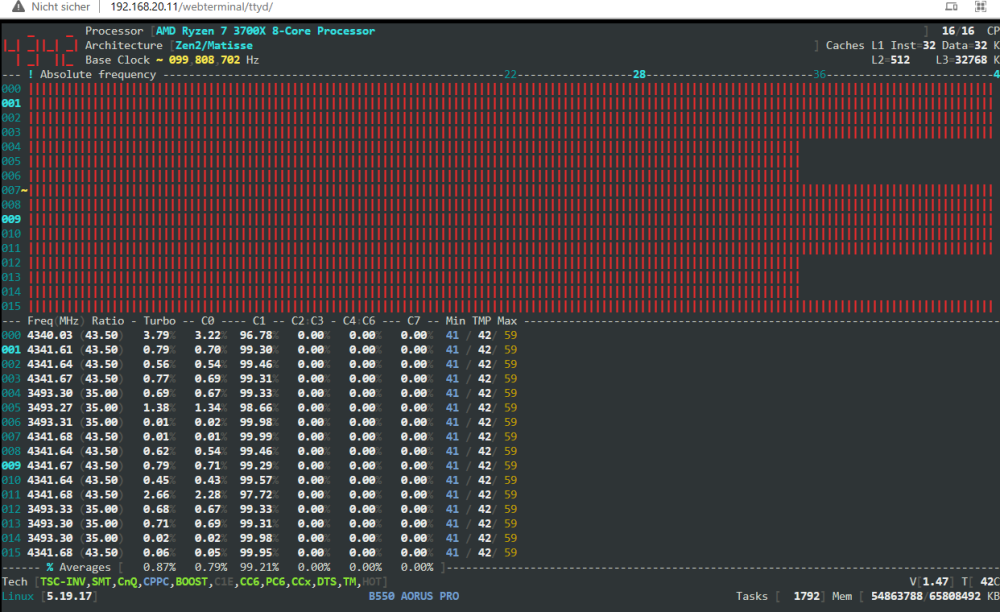
before the system has a minimum of 2200MHz.
Tips and Tweaks tells me, that there is no governor
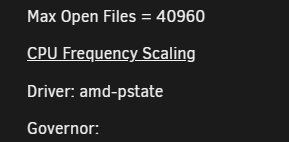
Any Idea?
best regards
Bastian -
On 4/10/2022 at 7:16 PM, Iker said:
2022.08.02
- Warning - Please Update your exclusion pattern!
- Add - Browse Button for Datasets
- Add - Support for listing volumes!!
- Add - Lua script backend for loading dataset information (50% faster loading times)
- Change - Exclusion pattern for datasets (Please check http://lua-users.org/wiki/PatternsTutorial)
- Change - UI columns re-organized to the unraid way (sort of)
Hi,
I've just updated the plugin and corrected the exclusion pattern.
Nevertheless the Main Page does show following warning:"Warning: session_start(): Cannot start session when headers already sent in /usr/local/emhttp/plugins/dynamix/include/DefaultPageLayout.php(522) : eval()'d code on line 3"
Any idea? (I've cleared the browser cache of course)
UNRAID Version 6.9.2
-
Ah ok. It was possible in the past, but since zfs is a kernel Module it is not possible anymore.
-
1 hour ago, ich777 said:
To pull the update please restart your server or upgrade to Unraid 6.10.0-RC4 if you want to try the Unraid RC series (if you restart your server make sure that your Server has a active internet connection on boot and is actually able to connect to the internet).
is it possible to update without reboot? -
28 minutes ago, Xxharry said:
ok so I followed that and this is below is what my share looks like. I can mount the nfs share from the networks listed in there but I can not place any files in it. what did I miss?
root@UnRAID:~# zfs get sharenfs citadel/vsphere NAME PROPERTY VALUE SOURCE citadel/vsphere sharenfs [email protected]/24,[email protected]/24,fsid=1,anongid=100,anonuid=99,all_squash localDoes the user 99:100 (nobody:users) have the correct rights in the folder citadel/vsphere?
-
37 minutes ago, Joly0 said:
Hey, i am trying to hide the auto generated docekr datasets, but mountpoint is "legacy" and dont know exactly what to write into the exclusion. Any instructions you could give for that?
Btw great update, works nice so far, compatibility to dark theme is nice
An example is documented in the settings.
I've my docker files in
/mnt/SingleSSD/docker/zpool is SingleSSD
Dataset is docker, so the working pattern for exclusion is:
/^SingleSSD\/docker\/.*/ -
8 hours ago, Xxharry said:
How can I share zfs dataset via nfs? TIA
I've done this via dataset properties.
To share a dataset:
zfs set sharenfs='rw=@<IP_RANGE>,fsid=<FileSystemID>,anongid=100,anonuid=99,all_squash' <DATASET>
<IP_RANGE> is something like 192.168.0.0/24, to restrict rw access. Just have a look to the nfs share properties.
<FileSystemID> is an unique ID you need to set. I've started with 1 and with every shared dataset I've increased the number
<DATASET> dataset you want to share.
The magic was the FileSystemID, without setting this ID, it was not possible to connect from any client.
To unshare a dataset, you can easily set:
zfs set sharenfs=off <DATASET>
-
2
-
 2
2
-
-
35 minutes ago, Marshalleq said:
So it turns out these are definitely not snapshots, something is creating datasets. The mount points are all saying they're legacy. Apparently that's when it's set in fstab, which of course they're not. I'm guessing it's something odd with docker folder mode so I'm going to go back to an image and try that.
from https://daveparrish.net/posts/2020-11-10-Managing-ZFS-Snapshots-ignore-Docker-snapshots.html
QuoteDOCKER ON ZFS
Docker uses a compatible layered file system to manage it’s images. The file system used can be modified in the Docker settings. By default, on root ZFS system Docker will use ZFS as the file system for images. Also, by default, the datasets are created in the root of the pool which docker was installed. This causes Docker to create many datasets which look something like this:
$ zfs list -d 1 zroot | head NAME USED AVAIL REFER MOUNTPOINT zroot 42.4G 132G 96K none zroot/0004106facc034e1d2d75d4372f4b7f28e1aba770e715b48d0ed1dd9221f70c9 212K 132G 532M legacy zroot/006a51b4a6b323b10e9885cc8ef9023a725307e61f334e5dd373076d80497a52 44.6M 132G 388M legacy zroot/00d07f72b0c5e3fed2f69eeebbe6d82cdc9c188c046244ab3163dbdac592ae2b 6.89M 132G 6.88M legacyso, I think it is wanted as it is
")
-
On 9/20/2021 at 2:14 PM, ich777 said:
Yes, but also keep in mind, many people here, at least from what I know, using a USB thumb drive as "Array" to start the Array and in this case this would be very slow...
I always recommend using a path instead of an image because it saves much space and previously I had a few issues with the images on my system.
I would always try the path first and if it doesn't work move over to the image file.
Sorry for the silly question... how can I change from docker image file to folder?
-
ok,
but can I leave the docker.img in ZFS, or should I put in one extra drive for unraid array? -
23 hours ago, steini84 said:
The thing is that we are not making any changes just shipping ZFS 2.1 by default. We have shipped 2.0 by default until now because of this deadlock problem, and 2.1 if you enabled "unstable builds" (see the first post).
ZFS 2.0 only supports kernels 3.10 - 5.10, but unRAID 6.10 will ship with (at least) kernel 5.13.8 therefore we have to upgrade to ZFS 2.1
So if you are running ZFS 2.1 now on 6.9.2 or 6.10.0-rc1 there wont be any changes:
You can check what version is running i two ways:
root@Tower:~# dmesg | grep -i zfs [ 69.055201] ZFS: Loaded module v2.1.0-1, ZFS pool version 5000, ZFS filesystem version 5 [ 70.692637] WARNING: ignoring tunable zfs_arc_max (using 2067378176 instead) root@Tower:~# cat /sys/module/zfs/version 2.1.0-1I've following configuration:
root@UnraidServer:~# cat /sys/module/zfs/version 2.0.0-1 root@UnraidServer:~# dmesg | grep -i zfs [ 56.483956] ZFS: Loaded module v2.0.0-1, ZFS pool version 5000, ZFS filesystem version 5 [1073920.595334] Modules linked in: iscsi_target_mod target_core_user target_core_pscsi target_core_file target_core_iblock dummy xt_mark xt_CHECKSUM ipt_REJECT nf_reject_ipv4 ip6table_mangle ip6table_nat iptable_mangle nf_tables vhost_net tun vhost vhost_iotlb tap xt_nat xt_tcpudp veth macvlan xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xt_addrtype iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 br_netfilter xfs nfsd lockd grace sunrpc md_mod zfs(PO) zunicode(PO) zzstd(O) zlua(O) zavl(PO) icp(PO) zcommon(PO) znvpair(PO) spl(O) it87 hwmon_vid ip6table_filter ip6_tables iptable_filter ip_tables x_tables bonding amd64_edac_mod edac_mce_amd kvm_amd kvm wmi_bmof crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel r8125(O) aesni_intel crypto_simd mpt3sas cryptd r8169 glue_helper raid_class i2c_piix4 ahci nvme realtek nvme_core ftdi_sio scsi_transport_sas rapl i2c_core wmi k10temp ccp libahci usbserial acpi_cpufreq buttonSo, what should I do? Change to unstable and see if it still works?
")
-
28 minutes ago, Arragon said:
Doesn't need the array to be started for serivces like SMB and Docker to run?
Yes. You need one drive - for me an USB stick - as array to start services.
-
9 hours ago, Marshalleq said:
Can I just say that I don't have this issue and I do store docker.img on a ZFS drive. I have no idea why - I did have the issue for a while, but one of the updates fixed it. I don't even run an unraid cache drive or array (I'm entirely ZFS) so couldn't anyway. So it may not apply to everyone.
For me it is the same. Only zfs. I hope I can leave it as it is.
-
22 minutes ago, mosaati said:
Jus to make sure. I don't have to edit this script, copy and paste, right?
yes
-
1
-
-
1 hour ago, mosaati said:
Sorry to bring this back. I just noticed this in my log. I Have SSD and HDD pools mounted to /mnt/SSD and /mnt/HDD.
Just to be sure. My commands will be like this?
echo "SSD /mnt/SSD/ zfs rw,default 0 0" >> /etc/mtab echo "HDD /mnt/HDD/ zfs rw,default 0 0" >> /etc/mtabNo, you need to execute the command for every dataset inside the pool.
https://forums.unraid.net/topic/41333-zfs-plugin-for-unraid/?do=findComment&comment=917605
I'm using following script in UserScripts to be executed at "First Start Array only"
#!/bin/bash #from testdasi (https://forums.unraid.net/topic/41333-zfs-plugin-for-unraid/?do=findComment&comment=875342) #echo "[pool]/[filesystem] /mnt/[pool]/[filesystem] zfs rw,default 0 0" >> /etc/mtab #just dump everything in for n in $(zfs list -H -o name) do echo "$n /mnt/$n zfs rw,default 0 0" >> /etc/mtab done-
1
-
-
1 hour ago, tr0910 said:
Thx, using ZFS for VM and Dockers now. Yes, its good. Only issue is updating ZFS when you update unRaid.
Regarding unraid and enterprise, it seems that the user base is more the bluray and DVD hoarders. There are only a few of us that use unRaid outside of this niche. I'll be happy when ZFS is baked in.
Which version of ZFS do you have working with VM and Dockers now?
-
The original smb reference is pretty old.
And one topic later testdasi had a solution
-
to be honest, no. I've nothing to do with linux internal stuff
-
56 minutes ago, tabbse said:
Hello, I'm new here. first of all i would like to thank @steini84 for his great plugin! I am not sure whether my question is correct here, as it is actually a Samba (SMB) problem, which only occurs in connection with ZFS. To access a ZFS device via SMB, you have to edit the Samba extras. Mine looks like this:
[Media]
path = /mnt/HDD/Media
comment =
browseable = yes
public = no
valid users = tabbse
writeable = yes
vfs objects =I updated from 6.8.3 to 6.9.0 and since then I get the same error message in the system log as soon as I access an SMB share.
Mar 2 09:28:21 UNRAID smbd[14859]: ../../source3/lib/sysquotas.c:565(sys_get_quota)
Mar 2 09:28:21 UNRAID smbd[14859]: sys_path_to_bdev() failed for path [.]!I can access the share, but it's very annoying as hundreds of lines of the same error message were generated during normal operation (e.g. browsing directories). I've already researched and the only thing I've found is that there is a problem with ZFS because SMB expects a mountpoint entry in /etc/fstab. A guy also came up with a workaround. I quote:
"The workaround is pretty simple: add the ZFS subvolume you're using as a share to /etc/fstab. If your share is not a ZFS subvolume, but your share directory is located beneath an auto-mounted ZFS subvolume (not listed in /etc/fstab), add that subvolume to /etc/fstab and the error will go away. No hacky scripts involved."
I have no idea how to do it or if it will cause any problems. I can give you the link to the site where I got this information but I didn't know if it is against forum rules. Does anyone else have the same problem or know how to solve it? Thank you very much in advance and if I am wrong here please tell me where else I can ask the question.
Hi,
please check this post
This is the workaround, I'm using.
best regards
Bastian
-
So, what's about the other .img files, used for VMs and so on? Are there any issues?
I'm still at RC1 with zfs-2.0.0-1





Erlaubt der neue Linux Kernel stromsparende AMD Server?
in Deutsch
Posted
Also bei mir funktioniert es erst seit 6.12.6 (hatte vorher 6.11.5).
Meine einzigste Änderung ist in sylinux cfg das amd_pstate=passive
Im go file war kein modprobe nötig
label Unraid OS menu default kernel /bzimage append rcu_nocbs=0-15 isolcpus=6-7,14-15 pcie_acs_override=downstream,multifunction initrd=/bzroot amd_pstate=passive vfio_iommu_type1.allow_unsafe_interrupts=1 video=efifb:off idle=halt