
-
Posts
44 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by smaster
-
Hey, So I've stopped the docker network completely and I now believe there should be nothing major running. I also tried again to pause or cancel, but nothing happened. The diags are attached. Thanks and sorry for the hassle, just trying to do this the right way. tower-diagnostics-20240108-0346.zip
-
Hey, I found the culprit. It was mongodb. It's fixed and the last 2 error messages are when I press "pause" or "cancel" in the parity check. Here they are: Jan 7 00:53:28 Tower nginx: 2024/01/07 00:53:28 [error] 20161#20161: *24622960 connect() to unix:/var/run/emhttpd.socket failed (11: Resource temporarily unavailable) while connecting to upstream, client: 192.168.1.105, server: , request: "POST /update.htm HTTP/1.1", upstream: "http://unix:/var/run/emhttpd.socket:/update.htm", host: "192.168.1.118", referrer: "http://192.168.1.118/Main" Jan 7 00:53:49 Tower nginx: 2024/01/07 00:53:49 [error] 20161#20161: *24622934 connect() to unix:/var/run/emhttpd.socket failed (11: Resource temporarily unavailable) while connecting to upstream, client: 192.168.1.105, server: , request: "POST /update.htm HTTP/1.1", upstream: "http://unix:/var/run/emhttpd.socket:/update.htm", host: "192.168.1.118", referrer: "http://192.168.1.118/Main" Diags attached and there are a few more errors that I got previously, here is an example of one: Jan 6 21:48:08 Tower kernel: pcieport 0000:00:1c.4: AER: Multiple Corrected error received: 0000:06:00.0 Jan 6 21:48:08 Tower kernel: atlantic 0000:06:00.0: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID) Jan 6 21:48:08 Tower kernel: atlantic 0000:06:00.0: device [1d6a:d107] error status/mask=00000041/0000a000 Any idea how to get the parity check going and making sure it's all good before going about a parity swap? Thanks a bunch. tower-diagnostics-20240107-0057.zip
-
Should a docker constantly restarting stop me from cancelling or pausing the parity check? When pressing pause or cancel here, it essentially doesn't do anything. Thanks.
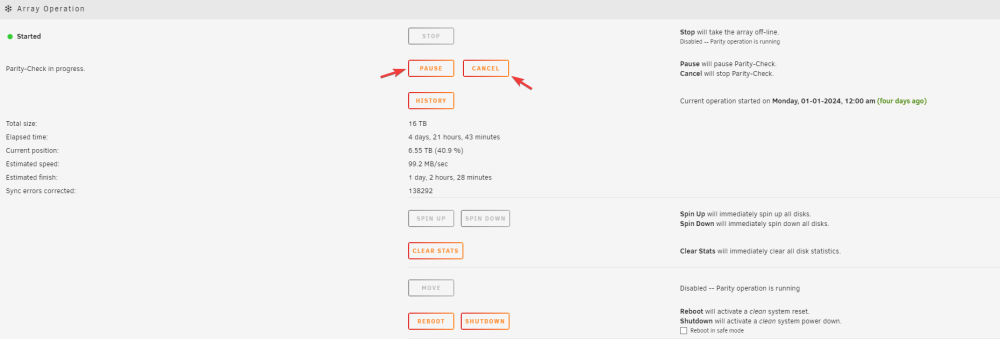
-
Thanks for your answers. I have a follow-up, currently my parity check seems to be stuck at 40.9% for a few days and even when I press cancel or pause it doesn't do anything. I'm just worried that the parity isn't fully up-to-date or correct and when doing a parity swap some data will be lost. I attached the diags if that helps. Thanks a bunch. tower-diagnostics-20240105-1510.zip
-
Hey guys, I currently have 30 drives in my array. Parities are 16TB and 14TB. I've had a drive failure (3TB) and want to replace it with a 16TB drive. I know the fact that the replacement being larger makes the process a little different and I'd just like to confirm that I have the right idea: Stop Array Remove the failed hard drive Insert the new hard drive In the "Main" section of unRAID, unassign the 14TB parity Assign the new 16TB drive to parity Assign the old parity drive in place of the failed drive Proceed to a parity swap (essentially transferring the data from the old parity to the new one) Start the array and rebuild the old drive from the newly created parity If this is all correct, I'd just like to also ask a few questions: While the new parity drive is being built, is the array inaccessible? Is there anything I can do to my new drive before I put it in my server that will speed up the process? Pre-clear or something along those lines? I'd like to avoid as much downtime as possible. Thanks for your time.
-
Sorry for the late reply, but after letting it all rebuild everything went well and without errors. I appreciate your time and will make this as solved. Take care!
-
Thanks for your response. I just started the rebuild, but it still says that disk 3 and 5 are being emulated. It's that normal? Here are the diags while the rebuild is happening. Thanks for your time! tower-diagnostics-20230711-2015.zip
-
Hey, I noticed a week ago that 2 of my drives started being emulated and I immediately restarted my server seeing if it would get fixed. I realise now that this was a mistake and I should've taken a diagnostic before. After the restart and seeing that nothing changed, I preformed extended SMART tests on both disks and after a lot of time both drives came back without errors. I also plugged both drives with m new connectors in case that could've been the problem. I'm not sure what the correct procedure is here, since I can't fully check my drives due to not being at home but I do have access to my network via a vpn. Should it be fine for me to perform a rebuild? Do I need to start the array in maintenance mode? Just trying to get things done the right way to avoid any data loss. I'm also attaching my current diagnostics. Thanks. tower-diagnostics-20230711-1406.zip
-
No worries, I know how life can be!
-
Thanks for this 🙂 Have you had a chance to look at anything unbound related?
-
You mean for unbound or pihole?
-
As you can see at the top it's the repo linked in the original post and the last line has the different capitalised config location... Weird! I'll just wait for your unbound version too! Like this I can get the perfect pack! 🙂
-
It is odd indeed, if you check on unRAID it still seems to give me the two folders... Did you manage to find something for unbound? if I may suggest something, maybe having both in the same container wouldn't be a bad idea, to have all the options for DNS. Thanks 🙂
-
This is how the template looks (I didn't change anything): So from what I see one of them is lower case and the other uppercase, maybe best to change the template? Or am I doing something wrong? Regarding an unbound template or build, that would be great so we could have the full setup consolidated here. Thanks for all your help!
-
Hey, First of all thanks for continuing the great work in this container. I've installed it and I'm able to access it. I have a few questions, some aren't quite related but I hope you could help me 🙂 Is it normal that the docker container creates two different folders in my appdata? In this case they are "pihole-dot-doh" and "Pihole-DoT-DoH". If so, could I just understand why? Also, how would I be able to add unbound to this setup to direct pihole to a self-hosted recursive DNS? Thanks for your time!
-
No, just plain CPU running. It's an intel 11900 on a Gigabyte Z590 AORUS MASTER motherboard.
-
Thank you very much! Although you're not ruling anything out at least it gives me some peace of mind. I will maybe run some diagnostics soon and also upgrade to the latest version of unRAID. Thanks again 🙂
-
Bumping once more...
-
Bump again, hopefully this time is the charm! Just looking to see if someone can tell me all is "OK" or whether I should be worried or not. Thanks!
-
Bumping, hoping someone can help out :-)
-
Hello all, I just got a "Machine Check Events" error. It appeared on the "Fix common problems" plugin and this is the suggested fix: "Your server has detected hardware errors. You should install mcelog via the NerdPack plugin, post your diagnostics and ask for assistance on the Unraid forums. The output of mcelog (if installed) has been logged" I checked this link and decided to check the syslog, but couldn't see if it was a harmless error or not. I attached my diagnostics to this message to hopefully have someone take a look and see if all is well or I should be worried. Thanks! tower-diagnostics-20221111-1642.zip
-
 Just to confirm that once I change "Docker custom network type" to "ipvlan" everything works fine when having the "Host access to custom networks" set to "Yes". On "macvlan" however, everything is off. I currently have the 6.10.3 version (latest at the moment). For now, I shall leave it on ipvlan, maybe I'll test it in macvlan in the next version.
Just to confirm that once I change "Docker custom network type" to "ipvlan" everything works fine when having the "Host access to custom networks" set to "Yes". On "macvlan" however, everything is off. I currently have the 6.10.3 version (latest at the moment). For now, I shall leave it on ipvlan, maybe I'll test it in macvlan in the next version. -
+1 to this being a problem. The moment I activate: "Host access to custom networks" my router gets confused about where to attribute my static IP and it causes all sorts of issues. I need this setting for some of my services to work and it causing instability is definitely not great.
-
I finally found the culprit! For anyone finding this thread, the container causing my logs to be overflowed was: Rimgo by Joshndroid's Repository. Thanks for your assistance!
-
Thank you for your reponse. Before I delete the docker.img file, as a last ditch effort would it be possible for me to stop all my dockers and one by one find out which is causing the problem? Or is this a more deep-rooted issue that can only be fixed by a wipe? Thanks.

