

-
Posts
165 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Yivey_unraid
-

[Support] Nginx Proxy Manager (NPM) Official
Yivey_unraid replied to mgutt's topic in Docker Containers
That solved that too! Thanks! -
[Support] Nginx Proxy Manager (NPM) Official
Yivey_unraid replied to mgutt's topic in Docker Containers
I'm sorry, but now you lost me. ELI5... What container should I set to Host or Bridge, and when? No, locally (and remote) everything works fine! THIS IS IT! (I think...) Thank you! I first tried adding a wildcard domain in the PiHole WEB-UI but didn't get that to work. This above seems to be the solution though! I added a "02-wildcard-dns.conf" file to /etc/dynmasq.d/ (host path for my PiHole container: /mnt/user/appdata/pihole/dnsmasq.d/). In that conf I added: address=/mydomain.com/192.168.1.4 Then restarted PiHole. Before I started everything I ran this in the Unraid CLI to see where the URL routes to: nslookup mydomain.com and that pointed to my public IP. Same result running: nslookup servicesubdomain.mydomain.com After restarting PiHole and running the same commands they come back to 192.168.1.4 So I guess it's working. The subdomains I have setup in NPM shows as normal with a guilty SSL cert when surfing to them locally. Only "downside" is that if I only surf to "mydomain.com" I'm routed to Unraid UI since that's the servers IP, insecure no SSL. Same if I surf to any type of subdomain that not proxied in NPM. It's only in the local LAN, so not a major issue. Surfing to Unraid UI through the normal IP is equally "open", just feels more hidden. I guess it's just a feeling... I do have a strong root password. If anyone have any suggestion for this to only work on URLs in NPM I'm all ears. Perhaps wildcard wasn't the right choice. -
[Support] Nginx Proxy Manager (NPM) Official
Yivey_unraid replied to mgutt's topic in Docker Containers
Thank you for the answer! I’m aware of the ToS prohibiting non-HTML content. Don’t use Nextcloud and for Plex I don’t see the need. I’m running my Pihole on the server at the moment, but I’m looking into building/setting up a PFsense or OPNsense router. That would also host the Pihole (or similar service). But that’s some time away, and right now I only have my ASUS router. When setting it up on Pihole, how exactly would that be done? My NPM (and all my services) has the same IP as my server and I don’t see a way to point Local DNS to a specific port, only IP. EDIT: Right now I do have a public IP, but my ISP is finicky about it and looks like they might start charge for it. That was why I wanted to setup CF tunnel to not be dependent of that. -
[Support] Nginx Proxy Manager (NPM) Official
Yivey_unraid replied to mgutt's topic in Docker Containers
Hi! Perhaps this is a question already answered, but I can’t find it and perhaps I’m not searching for the right words. Anyway, thank you for this container! I’ve setup NPM and Cloudflare Tunnel with my own Cloudflare SSL certificate. This now work perfectly for all my different containers, but took some time to troubleshoot (mostly because of my lack of knowledge in the area). Now I was thinking, instead of every time I’m on my local LAN and I go to https://myservicename.mydomain.com all traffic has to outside of my network and out to Cloudflare and then back, I’d like to set it up so when I’m on my LAN that URL points directly to that services local IP without leaving the network. How do I manage this best? Do I use Pihole local DNS and point to NPM somehow? Or can this be handled directly in NPM? Sure, I can use the IPs when I’m at home, but it would be nice to just use the same URLs everywhere. 👍 -
Sorry for reposting, but I fear this question disappeared due to someone posting their whole log file in plain text.
-
No, sorry! This perhaps should've been two different threads, I just put them in the same because I thought they were (are) related. But I can see how it causes problem following along. 😬 Originally my "only" problem was these weird streaming issues with glitches/freezings/pixelations/errors and artwork being displayed with artifacts in Plex UI. Like this: But it was during my troubleshooting of these issues, and subsequently multiple different Docker container installs, that I got the: Error: filesystem layer verification failed for digest sha256 So to hopefully make it clear: - The streaming issues occur intermittently, no matter what type of device is played on, no matter what type of media is played etc etc. - The sha256 error is occurring intermittently during some, not all, installs/updates of Docker containers. Seems to help to remove unused volumes in Portainer. Since sha256 seems (?) to be a checksum problem, could that point to a network issue?



-
That is what I have done when I've spun up new containers of Plex from different repositories. Tried linuxserver, Binhex, Plex official and a clean Hotio. Just installed them plain and just added a test folder containing a few different videos in various resolution and dynamic range. Same weird streaming issues in all.
-
Yes, I've also tried resetting the appdata from backup. Sorry, I've tried so many things over the past weeks it's hard to keep track of what I've presented as "tried". I also have support threads regarding this going in a few different forums also, since I'm not really sure what is the problem. I could be hardware, it could be Plex, it could be Docker or the created containers, it could be my network and it could be.... I don't know, karma?! 🙄 Do you by any chance have any insight into the "Error: filesystem layer verification failed for digest sha256" problem? I did switch from Docker image to directory last spring, should I try to revert back? I guess it shouldn't matter..
-
Mm, but i have been using Plex for 10+ years and generally speaking been a happy camper. So I’m willing to fight this, as in my opinion, neither Emby nor Jellyfin is even close to compete with the user experience and the WAF.
-
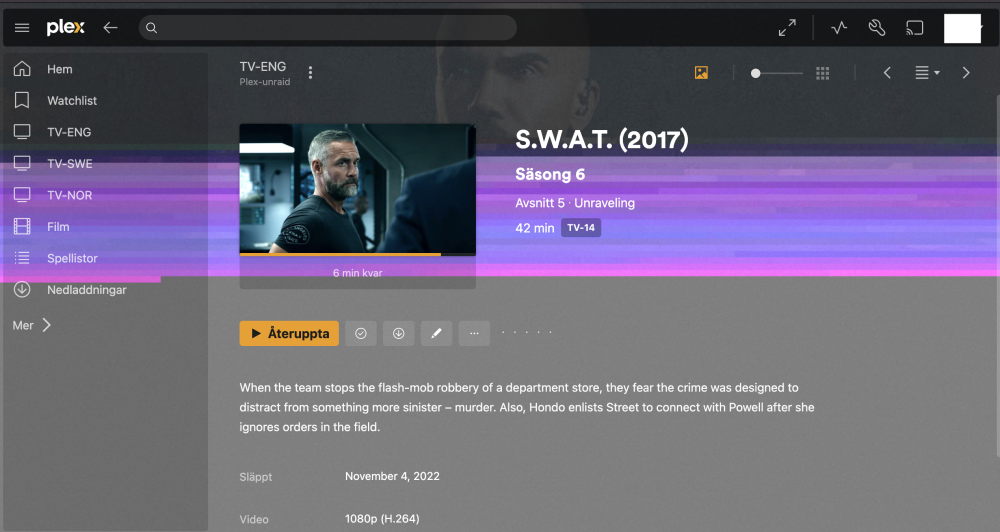
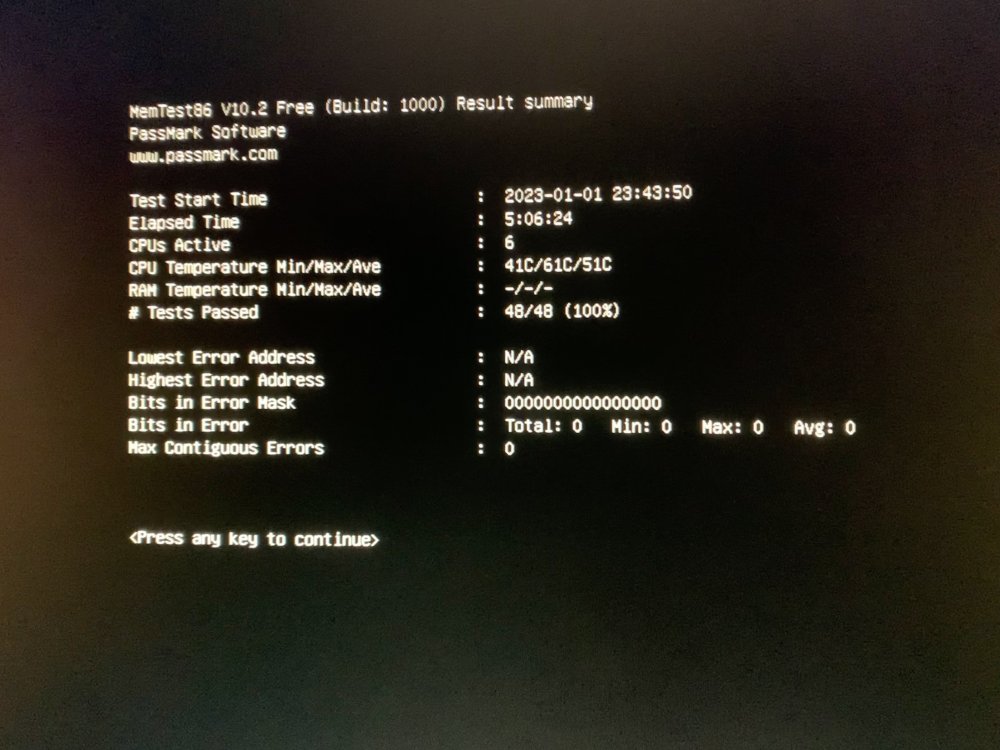
Nobody have any suggestions on the Plex streaming issue? I’ve tried multiple things to solve it without any success… I’ve nuked the docker image on the server and reinstalled Plex. I’ve tried multiple fresh installs of Plex using different Docker repositories (binhex, linuxserver, official Plex). I’ve run a memtest86 to make sure my RAM is good, multiple passes. No errors. I’ve changed wall outlets, a desperate move I know… I’ve also tried installing Jellyfin and tried streaming the same files through that, and that has actually been working. Haven’t been able to produce the same issues with that. So… Plex does seem to be the culprit. Unfortunately. Is there some dependencies that Plex have that isn’t included in the Docker containers? Since all Plex containers I've installed have the same problem I figure it has to be something else?! This is the Plex.app on my Mac. This sort of graphical errors I also get from time to time. I’d say exclusively on the artworks, posters and backgrounds like in this screenshot. Since that’s stored on the server in the appdata library, there must be either something corrupting the file when it’s transferred over the network to the Mac (or any other device I have, all present the same intermittent issues) or some sort of file corruption on the cache that is intermittent?! I really don’t get it... Please help! I’m loosing faith here!
-
Keep getting "Error: filesystem layer verification failed for digest sha256" sometimes when I'm installing or upgrading Docker containers. It has me worried... Any idea what it might be?
-
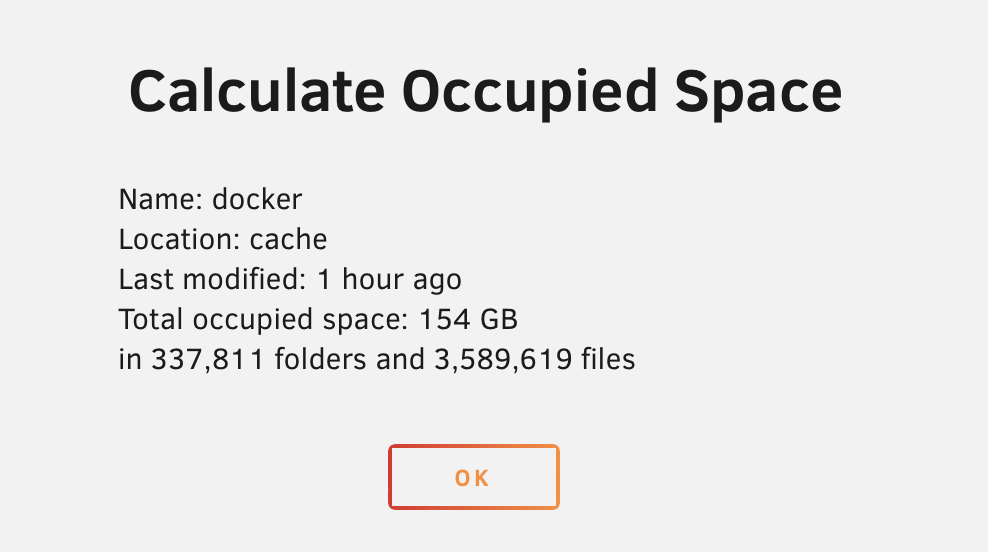
Ok, I managed to install Portainer and deleted a bunch of volumes that was unused. After that I was able to update the container without any problem. What I don't understand though is why the size of the /docker directory is so different depending on where I look: /mnt/user/system/docker is set to cache:prefer and is on a 250 GB SSD. Checking it's size in Terminal. Calculating /mnt/cache/system/docker in Unraid UI. Something doesn't add up?!? The streaming issues persist also... But perhaps I should nuke and rebuild /docker directory?


-
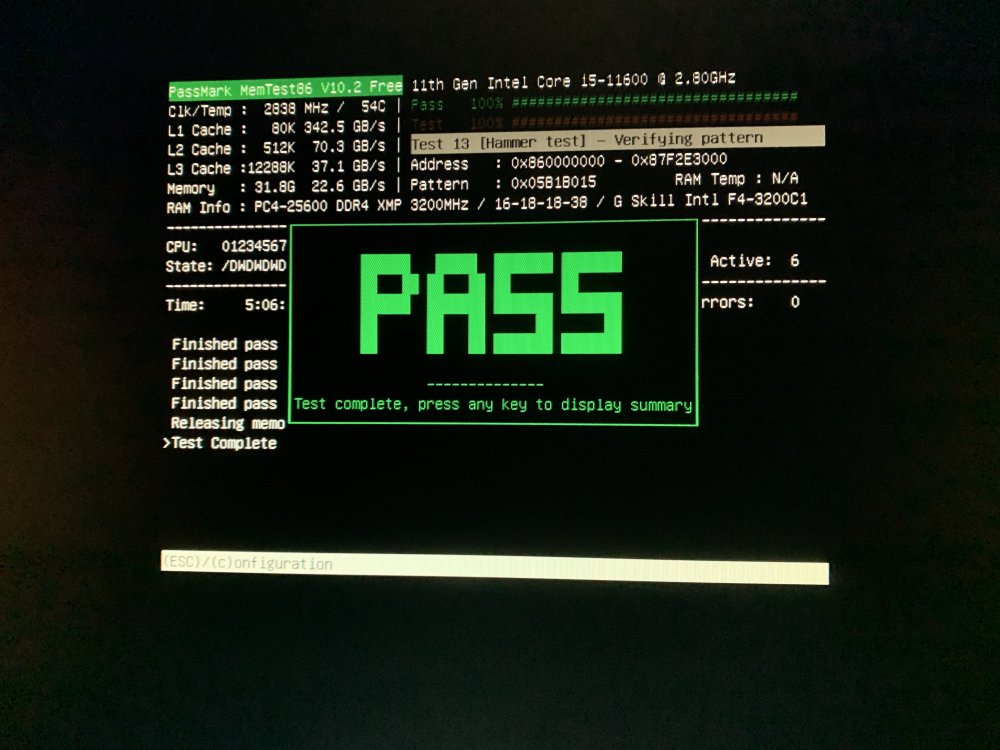
Hi! I just tried to update binhex-qBitVPN but pulling the latest image gives me this: Pulling image: binhex/arch-qbittorrentvpn:latest IMAGE ID [679001613]: Pulling from binhex/arch-qbittorrentvpn. IMAGE ID [e130c81b086a]: Already exists. IMAGE ID [f0c2d8550f0e]: Already exists. IMAGE ID [e8b87bc620a7]: Already exists. IMAGE ID [7b303ad07582]: Already exists. IMAGE ID [e6cff58d3325]: Already exists. IMAGE ID [ed093e4b8303]: Pulling fs layer.Downloading 100% of 4 KB.Verifying Checksum.Download complete.Extracting.Pull complete. IMAGE ID [0a7e7d1b57dc]: Pulling fs layer.Downloading 100% of 12 KB.Verifying Checksum.Download complete.Extracting.Pull complete. IMAGE ID [acdab43f922d]: Pulling fs layer.Downloading 100% of 3 KB.Verifying Checksum.Download complete.Extracting.Pull complete. IMAGE ID [a873d56991c3]: Pulling fs layer.Downloading 100% of 11 MB.Verifying Checksum.Download complete.Extracting.Pull complete. IMAGE ID [bf4455564214]: Pulling fs layer.Downloading 100% of 293 B.Verifying Checksum.Download complete.Extracting.Pull complete. IMAGE ID [47be8f93f574]: Pulling fs layer.Downloading 100% of 2 KB.Verifying Checksum.Download complete.Extracting.Pull complete. IMAGE ID [9a45b4ff2318]: Pulling fs layer.Downloading 100% of 3 KB.Download complete.Extracting.Pull complete. IMAGE ID [d77252f0b421]: Pulling fs layer.Downloading 100% of 383 B.Verifying Checksum.Download complete.Extracting.Pull complete. IMAGE ID [d1631fdb6136]: Pulling fs layer.Downloading 100% of 181 MB.Verifying Checksum. TOTAL DATA PULLED: 192 MB Error: filesystem layer verification failed for digest sha256:d1631fdb61368a5121f94f4a89dcaa24f36e2d1bd9402729aaccbba2a8403a02 I've never seen this Error: filesystem layer verification failed for digest sha256 before, and googling it doesn't give much. A few posts point towards checksum errors and doing a Memtest. Suggesting it's more of a HW issue than SW. Any ideas? Did a Memtest86 last night actually, just prior to this reboot of the server and prior to this error presenting itself. Showed no faults at all. Ran 4 passes. The thing is that I've been troubleshooting my Plex install for the last month now. That is why I did the Memtest. I have these intermittent streaming errors/freezes/glitches/pixelations on everything I stream. Doesn't matter if it's direct play or transcoding. Doesn't matter what container I use (Hotio, Binhex, linuxserver) or if I'm HW or SW transcoding. Doesn't matter if it's played local or remote. Doesn't matter what device is used, or if it's wireless or wired. Doesn't matter what version of Plex I'm running. More comprehensive explanation on Reddit here. These streaming issues has driven me crazy and I'm more and more convinced that it's some kind of HW problem. If you have any suggestion regarding that issue I'm all ears. Plan right now for troubleshooting that is: - Exchange the router currently acting as a switch in the office for a 2.5 GbE QNAP switch I had already ordered. See if the router for some reason can't handle the traffic, even though it is light. - Remove the Shelly Plug S that is used to measure power consumption of the server. If I really stretch my imagination the Plex issues might have started all the way back in October when I started using the plug... Perhaps it's introducing some weird overtones or something.... Yeah I know, but I'm desperate... 🤷♂️ Attached Unraid diagnostics and Plex server logs (confirmed playback issues occur from Dec 27, 2022 13:55:16 and forward). Best regards define7-diagnostics-20230102-2210.zip Plex Media Server.log.zip
-
Dear Squid! As usual, thank you for your great work for this community! I just have a question regarding having appdata split over multiple pools, and backup thereof. I have all but one appdata-folder on /cache and only my Plex appdata on a separate pool /cache_plex. FCP flags this as a problem: So far I've just ignored it, since the update seems to still be functioning correctly. Question is, can I leave it as is (and solve the issue of "how to backup my plex pool" this way) or is this a bad practice? Merry Christmas!
-
Like I wrote in the post, it is only set to Yes in the screenshot due to it not working properly when I tested so I turned it off. I will definitely try this and get back to you when I’m back home again. 👍 I created the file on macOS and added the path lines within the unRAID UI to get proper formatting (I believe).
-
@hugenbdd any possibility that you could show a setup of how to ignore a folder, using the text file method? I've tried with this setup (Disable Mover running on a schedule: Yes in this picture is only because I want it turned off when it's not working properly) The path it points to: /mnt/cache/appdata/plugins/CA_Mover_Tuning/ignore_file_list.txt This is how the txt-file is written: I tried both with and without the second line with the *. Please, any suggestion on how to solve this?


-
I've done the same thing, and it works for me. I think your problem is the trailing / in your path. Try it like this instead: Never mind. I thought it worked but no... Looking at the log (enabled logging, and looking at unraids logs) I see that it skipped one file then transferred everything else in the directory.
-
Transferred the files from Disk 1, stopped array, and changed format back-and-forth to trigger unRAID to format the drive. Worked well and now the used space is correct. Must have been something wrong with me using the drive in Ubuntu.
-
Not that I know of. Unless UFS Explorer somehow did something to cause all 11.6 TB it created on (reacued to) the disk to leave the space “occupied”? 🤷♂️
-
What is the cause, normally, of this behavior? So I probably did format the drive? Haha, I was so crazy tired when I dealed with this in the middle of the night.. 😅
-
I'm afraid I don't really follow you. Shouldn't computing /mnt/disk1 using file manager plugin show the exact content on Drive 1? Or check mnt/drive1 in MC? Since it only seem to contain 30 GB instead of 11.6 TB that unRAID UI is showing, then what could the problem be? EDIT: I've booted into Ubuntu to check there and I see the same files as I did in unRAID (30 GB). None of the visible files in Ubuntu is something that is important, just appdata backup and flash backup. Both those will get recreated. Could I just format and partition the drive to like ext4 in Ubuntu and then restart into unRAID? That should make the drive unmountable and I could let unRAID format it and then rebuild from parity. Or is there some other way, that won't involve a new parity check? I guess not, but one could hope.. Maybe just reboot into unRAID, change file system for the drive to BTFS and start the array. That would trigger a format, right? Then maybe change back to XFS since that's what I'd prefer..
-
Yes, I normally never use disk shares nor are they normally activated. 99% of the file transfers during my recovery was done through MC, file manager plugin (excellent plugin btw) or rsync so using disk shares wasn't the problem here. I just needed it for a few things and that's why it was activated. Now my current problem is that I forgot (probably) to delete the content of one of the XFS formatted 18 TB drives I was using as middle "cache" during the recovery, before I put it into the array. Result is a duplicates problem that I haven't been able to solve yet. The drive (Disk 1) shows as 11.6 TB full in Main's tab, but I can only see 30 GB worth of files in /mnt/disk1 when checking in MC or Krusader of File manager plugin. Did try to run extended FCP test and dupeGuru without a result. Also tried Czkawka and that looks more promising. I'll look more into it after the parity build is complete in a few hours, but I will do a restart and post diagnostics first if the original problem in this thread persists.
-
I've just added a parity drive and it is building parity now, so I'll wait for that to finish and after that I'll restart and post diagnostics. Normally I don't, but I've been trying to solve a previous problem with file system corruption and used disk share for part of the file moving. Ah, should've seen that. I just left the file structure as UFS Explorer spat it out. Now I've gone through those unnamed folders and the share is deleted. Perfect, in case someone else leaves the files that UFS Explorer creates as top directory like me... 😅
-
Anyone?
-
Ok, I think I'll just bookmark your forum post instead. I don't have docker-compose CLI tool. 👍













