

Caennanu
-
Posts
159 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Caennanu
-
-
Hey Guys,
Been using crushftp for a bit now, a lil on the down low.
The webgui and ftp clients connect just fine, is why i haven't run into an issue yet.
However, since i want to start serving the files via an webpage, i need to find the files.
Even tho i set the FTP folder variable, i cannot find the uploaded files i can find using the webgui.
So i'm wondering, where are the files and folders etc. stored?
It seems to be like an in-memory thing?
-
NAT aside, i've got another question / request.
The other day pterodactyl screwed itsself up due to improper updating of the deamon. Eventually was able to fix this, but it resulted in multiple folders used by the docker containers to get other permissions, which caused the servers not to start because they didn't have write permissions. (i fixed this because of having a backup that also had the permissions)
So my question is: can the guide be expanded to include troubleshooting steps on what to do when folder and file permissions specific to pterodactyl are botched?
(i would offer a suggestion / write-up if i knew how to actually fix this, but i don't :()
-
On 1/27/2023 at 11:08 PM, helomen said:
Hello everyone,
I need your help! I have successfully run pterodactyl exactly according to the great instructions of IBRACORP until almost the end. Unfortunately I have problems with the console in the game server (panel). I can access and play Minecraft on this server, but all the time I get the error message "We're having some trouble connecting to your server, please wait...". I also get a 502 error message in the log for the node. Does anyone have an idea how I can solve this problem? I am using the "NginxProxyManager". Thank you already for your help.
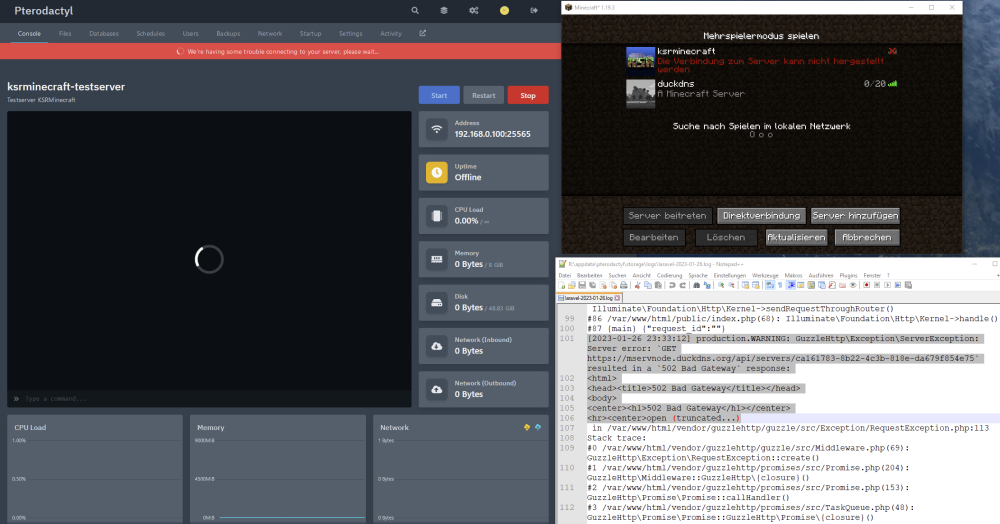
Dev-Tools ind FF shows this: Firefox cannot connect to the server at wss://xxxxxxnode.duckdns.org/api/servers/xxxxxxxx-8594-488d-86fb-c935583da9e7/ws.
I still have some understanding issues with forwarding ports. Currently I have the following setting:
Router:
TCP&UDP: 80 -> 1880 (for Nginx Proxy Manager).
TCP&UDP: 443 -> 18443 (for Nginx Proxy Manager)
Nginx Proxy Manager:
XXXXXX_node.duckdns.org -> 8002 (host port in wings to container port 8080)
XXXXXX_panel.duckdns.org -> 8001 (Port in panel to container port 80)
panel:
172.19.0.3:80/TCP <-> 192.168.0.100:8001
wings:
172.19.0.2:2022/TCP <-> 192.168.0.100:2022
172.19.0.2:8080/TCP <-> 192.168.0.100:8002 Is that correct?
XXXXXX_node.duckdns.org/ shows this message in the browser: {"error":"The required authorization heads were not present in the request."} -> So, wings seems to be reachable from the browser
I have already invested several hours without success and don't know what to do. Therefore I am glad about any help. Thank you very much!
i think you have the same problem as me. you do not have the option to enable hair-pin nat or nat loopback. I bet if you are on the same LAN as the server, the node elements will work just fine.
-
So to give an extra update.
I have now installed nginx and followed the written guide, aside of the fact i'm feeling like the writeup is missing something (setting up a node reverse proxy without telling the panel where to find it?), it still isn't working externally. i can acces the panel, but cannot interact with the node.
My geuss is that it is because i do not have a router that supports NAT loopback.
Any suggestions on how to circumvent this? (i feel like this is the issue, but since its not in the 'assumptions' part, i cannot say with certainty).
-
So... its been a while. but i'm attempting to gain acces to the files and stats of the servers externally, without using an reverse proxy.
Friends are able to connect to the panel, can see the servers. They can see the files, but when it comes to editting or viewing the console page, there is an error.
I have tried to open the ports for the deamon externally to no avail.
My thinking is that it won't work, because external users cannot use the internal docker network. Could this cause the issues where the deamon bits of the panel are not accesible?
If so, how would i go about 'fixing' this?
-
Well, whaddaya know...
Updated to 6.12 stable. And had the same issue.
I had to reboot my router, as my static route wouldn't take hold.
This allowed me to acces LAN, but nothing outside of it.
Maybe that is the issue on your end too?
-
On 6/11/2023 at 6:07 PM, Lecso said:
I will try to explain it better!
I tried two android phones with mobile data, their settings are Remote Connect to LAN. Both worked as they should, I reached everything like I was on my home network. I could reach my 3D printer, Unraid, my router, everything on their usual address.
However, the Ipad, connected to one of these android phone's hotspot could only reach my router on its default 192.168.1.1 address and my Unraid server login page via this address (in Remote connect to LAN mode too): (but not on the 192.168.1.121, Unraid's address on my home network)
(but not on the 192.168.1.121, Unraid's address on my home network)
Alright, i do not know exactly what an hotspot does... (i know its function, but not its technical details).
It sounds like the android phone creates a virtual network. Kind of like a WAN port. Creating a different subnet for the ipad.
Can you check if the ipad gets an ip in the same range of your local network, and if it is the same. if that ip address is reserved from your own dhcp?
-
18 hours ago, Lecso said:
My laptop was on a wifi hotspot created on my phone. On the phone that works. I also have problem with an ipad. Remote access to server and remote access to LAN has internet, I can reach the Unraid login page and my routers login page, but nothing else on my local network. I tested this on the hotspot shared from my phone too.
Allright.
Can you connect to the unraid server via its DNS address, or only via its ip address? If the latter. its likely something in your DNS settings.
-
On 6/9/2023 at 6:40 PM, Lecso said:
Hey.
I have set up the VPN in Settings>VPN Manager. It works on my android phone but not on my other Windows laptop. Has anybody encounter this problem? When I connect to the VPN from my phone and ping it from Unraid it replies, but the windows laptop does not.My best guess is that your windows is on the same if not similar subnet, and the phone is not.
-
Good day all,
I've been using wireguard for a while, and always had the issue that i cannot acces the internet while connected to the VPN. Previously this was an non issue, as i didn't actually needed it, it recently however has become an issue.
Now, i'm geussing since i used the quickstart guide, i should post here. So let me start with explaining the layout of my network. Starting from the ISP going in.
From the ISP side, i have a WAN box (Ubiquiti EdgeRouter-12).
- I use this to connect my optical connection directly to my network. This ER also serves as my firewall / DHCP server.
- It runs the DHCP for 4 Vlan's (something with not wanting CCTV and IoT mixed in a network)
The ER has a static route to my ICX 6450-48P, which serves as my router.
- Primary reason for this is because the routing capacity of the ER is lacking
- secondary reason, i need PoE ports more than the ER can supply, and i already had the ER
- Third reason, the ICX has no WAN ability
From the ICX, i connect to another ICX via a single 10gb fiber connection. Which has the unraid box behind it. The 2nd ICX is in switch mode.
Firewall ruling disables acces between the different subnet, and the CCTV camera's have 1 hour of acces to the internet a week for only time synchronisation.
On unraid i run dockers for pihole and lancache. Which effectively are my internal DNS servers. This should be a nice to know, but not a requirement as i don't need these for DNS purposes when using Wireguard.
Troubleshooting steps:
Changed connection types, which didn't yield any results (logical, but worth a shot)
Changed DNS from local to 8.8.8.8, no notable results
Added allowed ip's equal to the subnets of my Vlan's with the /24 notation, no notable results.
When doing a tracert to a (both DNS and IP), i get a result only from my unraid box, everything after that times out.
So my understanding is that the internet requests do not leave the unraid server. Which leads me to believe i'm missing a link between the server and the router. Am i assuming correctly? (NAT issue?)
--- Solved ---
After adding the static route not only to the ICX router but also to the ER (WAN), it works.
So maybe one could adjust the write up, that the static routing needs to be in other places as well when there is a split configuration?
-
+1 for me.
I'd love this so i have 1 place to manage all!
-
On 10/4/2022 at 8:53 PM, SimonF said:
Do you know which device was trying to be mapped when the system was crashing.
I do not know which it was trying to map at the time, as i fail to see the logic of the allocation.
The only thing i found is that the TPU was allocated on bus 00, while it was trying to allocate it at 03.
If anything was connected / assigned to 03 at the time i do not know. If it was... it was connecting to either of the folowing:
LSI HBA, Adaptec HBA, Dual 10GB SFP NIC or GT710
-
Makes sence in a way. Still i believe there should be a way to turn off auto start of VM's when starting VM manager. Specifically for issues like the one i experienced.
We shall see, maybe i should log a bug report. or a feature request to add a toggle to the VM manager menu with something like 'Disable VM auto start'
-
Thanks for the reply.
The thing is, i couldn't start the VM manager without making unraid unresponsive. That is why i was looking for a way to at least disable the auto starting off the VM's within the manager.
The reason i wanted to turn it off, is because 1 VM is non default. I had added the below line to the XML to load up the Coral TPU, which wasn't a passable pci-e device.
Since i moved hardware around, or rather removed, it seemed that the Id of the coral TPU was different, and it was.
<hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </source> <alias name='hostdev0'/> <address type='pci' domain='0x0000' bus='0x06' slot='0x00' function='0x0'/> </hostdev>
The bus in question changed from 0x03 to 0x01. And i had no way to edit this.
And that seemed the most logical cause of unraid becomming unstable.
-
update2:
after re-arranging hardware in pci-e slots, i've managed to get the TPU its 'configured' ID again.System now boots, VM manager boots.
Would love to know if someone knows how to change this ID if added manually to the XML of VM's.
Because this isn't particularly user friendly.
-
update:
Puling the disk with the VM's on it. Also causes the system to crash.
Can't pull logs from unraid, but ipmi now shows an MCE i haven't had before...
CPU 2: Machine Check: 0 Bank 17: dc2040000000011b
TSC 0 ADDR 28b880 SYND 149901000a800500 IPID 9600450f00
PROCESSOR 2:830f10 TIME 1664694930 SOCKET 0 APIC 4 microcode 8301055
-
After reading some on the forum with similar issues, i haven't been able to find a resolution yet other than perhaps renaming the images.
Luckily i don't have the images on the disk that is part off the array (only their backups) so if needed i could just pull that disk and edit the xml's from the gui.
Would still prefer an more near solution tho.
-
Gday all,
Recently i've set up a Virtual machine using a coral TPU on Unraid.
This TPU i had to passthrough to the VM by editting the xml, as it wouldn't be listed as a passable device.
This all worked fine and dandy, set up my new VM with the TPU, installed shinobi tested that for a while, works great.
So time to dismantle the old VM, which was using GPU acceleration for object detection.
Removing the GPU from the system however seems to have a fairly big impact i didn't anticipate.
When booting the unraid machine, everything seems to work just fine. except that the VM's do not actually boot.
Trying to analyse what is happening, i notice the GUI is freezing. Also SSH'ing into the system fails, and the command line interface on the physical machine doubles nearly every keystroke, making it impossible to do anything. The system becomes unresponsive.
After a couple of reboots. i manage to catch the logs. It seems its trying to find the TPU. Which makes sence.
But probably due to the hardware swapping, it has changed Id's....
So... i turn the system off. Disable automatically loading the array (via disk.cfg on the usb), so that i can boot. start the array manually without the VM's starting automatically after the array comes up.... this does not seem to be the case...
So the questions are...
Is there a way to edit the VM file to temporarily remove the TPU till i know the new id, so i can re-add it?
Is there a way to actually stop the VM's from auto starting? (would be nice to know in general, if this can be done via CLI or editting files)
And before you ask.
With an system that is almost unresponsive, adding logs will be a challenge.
Unraid version: i'm on RC4.
-
I'm sorry if it was mentioned before, but after reading 6 pages i gave up...
Has there been a solution yet to passing through the Coral TPU to an VM?
NM... figured it out, by editting the XML using this guide. https://www.smsprojects.co.uk/video-unraid-pass-through-hardware-3-ways-to-do-it/
-
 1
1
-
-
Sorry, as you can notice i'm not a frequent visitor of the forums, thus the slow reply

Yeah, myself i run a pretty pro-sumer network myself. Vlan's for this, and that, just to keep everything secure and what not. But most users simply use a modem supplied by their ISP. And most of them, even tho they come with advertisements of 1GbE for internet, can't actually switch / route that simultaneously. Matter of fact, that is why i moved all my routing from my ER-12 to my Brocade. (with the upside that unraid now has dual 10gb connections)
Oh, and i totally get you on the wife agro. It's probably the worst, 2nd is kid agro when their downloads are trailing behind because lancache is overtaxxing the network ;).
Honestly, the networking part is the most fun part to figure out i have found. Once you get the basics under control that is. Like... why can't i acces my unraid shares from one Vlan while i can from the other. Simple stuff like that, dig into it, figure it out. Apply your study to your usecase so it actually benefits you while you learn.
Aye i seen that post too. On that too the tax on the cpu is hefty. Its something i'm not quite getting. Maybe ill have to start streaming just to figure that out. Too bad on that one is tho, even when nvenc is described, it doesn't show the effects off using it to en/decode, in terms of CPU tax.
-
@spxlabs Thanks for the reply!
- Totally agree that blog posts like this push other idea's, and makes people think further than their comfort zone. So for that, defo kudo's!
- Nvenc is not always great, totally agree. But its better than consuming 60% off a CPU. It would indeed be better to do the en/decoding through an GPU. But i geuss, if you don't have that option, it is a valid point.
- networking. It is a shame really that this subject isn't touched. In a typical homelab networking is basically key. I do agree it is a rabbit hole. But there-in also lays the problem. If this is not performed right and for say, you're streaming raw data to the server, it can actually tax the resources on your gaming rig more than when streaming locally. So i geuss this is more a followup advice for any1 seriously thinking about a solution like this. Please take networking seriously. Read up on it, before you crash your network and maybe even worse, the wife aggro when it goes down!
-
Gday,
Since it was hightlighted in the newsletter under usecases, i figured i'd read up on this.
The only question i really have is, why would i want to do this for just streaming?
With Nvenc encoding (only applicable for nvidia gpu's) the load on the gaming system is near to none (compared to 60% cpu utilization of your server with 16 cores / 32 threads?).
Instead, this will load up your local network, which could cause issues with bandwidth depending on the network setup, as you will 'upload' the stream to the server, then 'upload' it to twitch. Causing it to require 2x the bandwidth compared to directly streaming, not to mention priority QoS settings.
Next to this, since everything is virtualized, you (generally) do not have direct acces to the virtual machine. (docker is a virtual machine afterall). If your gaming system crashes, you have no more control over the stream since you have no more access. But the stream still goes on till and if you regain control?
There are a couple more reasons i can think off why i don't think this is a good idea. But i'd love to hear some pro's (aside of offloading recording of the footage)
-
Gday all,
Since i recently lost a whole lot of my data. (after investigation, it was eventually all user error) I now have a big lost+found folder.
In this folder are a ton of filers and folders that have limited / no attributes.
I have however found that many of them still contain data that can be read. For some reason GIMP seems to be able to detect a whole lot of them and is able to view their original content.
Now i have also found DROID (Digital Record Object IDentification), which seems to do the same. But can only create a list and not actually restore the file type en-masse. Same with Gimp.
So i was wondering. Is there perhaps any app available to the community app or perhaps in development that could perhaps use the XML generated by the DROID scan, to atleast 'rename' the file type extension to the files in the lost and found folder? Wondering what i can recover. But its too much to do by hand, and i'm not handy enough to write me a script.
-
Gday all,
Since i'm battling some hardware related issues (suspecting my 'new' HBA, and ECC errors caused by improper contact of my EPYC cpu...... yes its the cpu or board, as swapping memory around, the errors stay with the slot. reseating the cpu moves the errors to another slot...), i been rebooting my system and swapping some PCI devices around.
What i've noticed is tho, that unraid assigns my 10G network nics to random VM's. While they should be part of the bond, configured as active backup. After this happens, i have to shut down docker and VM manager. start them up again, and restart the system not to have the interface down message.
Is this expected behaviour?
p.s.
i can attach logs, but due to hard disk dissappearing (HBA or cable issue) and the ECC error issue, its rather large and hard to read.



Disable nuisance banner notifications
in General Support
Posted
Maybe i'm necro'ing an old thread but since it was one of the first ones google found for me:
Settings > Notification settings > Uncheck 'Browser' for the ones you want off your wall.