

Vatoe
-
Posts
19 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Vatoe
-
-
Okay, I have managed to fix this issue. Anyone who has this issue this should help.
1. Make a current backup of your flash drive (for the just in case scenario)
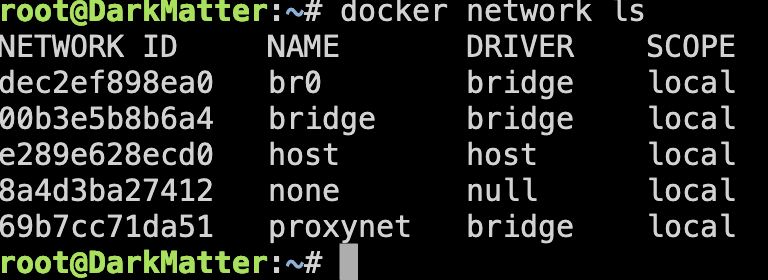
2. In unraid console remove the docker network database : rm /var/lib/docker/network/files/local-kv.db
3. Then restart the docker network: rm /var/lib/docker/network/files/local-kv.db
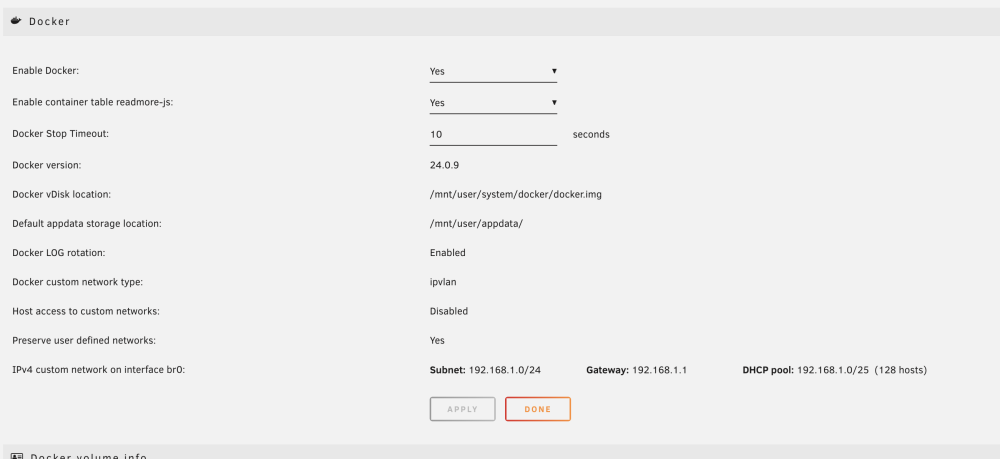
After the restart br0 should now point to ipvlan. I am once again able to use a fixed ip address on br0 network for docker containers.
Thanks to bmartino1 for chimming in.
edit: you will need to re-create any custom networks and get your docker containers pointing to the relevant recreated networks. Some of my docker containers didnt restart so I had to reinstall the container with the 'newly' recreated network.

-
 1
1
-
-
6 hours ago, bmartino1 said:
I Would recommend enabling host access to custom networks.
it also appears you set a dhcp pool and the dhcp pool's subnet may be wrong preventing network traffic.
https://docs.netgate.com/pfsense/en/latest/network/cidr.html
/25 is for a class a or b subnet to help set a number of ip address.
per your ipv4 br0 "custom network" your router dhcp is a cl;ass c subnet /24
you may have a out-of-scope netwrok issue with subnet issues when setting static ip to dockers. Please remove the dhcp pool or fix the /25 to /24Good catch didn't notice that. I have unchecked the DHCP pool, and allowed custom network access, but the network still points to bridge (after server restart) unfortuntely. I check with the relevant docker container still the same error. I though there would have been some command line that could force or remap br0 to ipvlan. No luck on googling this point/issue so far.
-
I 'll watch the video when I get a chance, but to answer your question:
-
Long story short made changes to the cache drives on one of my unraid boxes. After the upgrade something happened and my br0 network and it now points to bridge rather than ipvlan. I have tried restarting the docker service etc, but it persists to pointing to this network. As a result there are 2 docker containers (the only two that require static ip, nearly everything else is on proxynet) I cannot set a static IP for via the Br0 as I get "Error response from daemon: Invalid address 192.168.1.17: It does not belong to any of this network's subnets." This used to work without issue. I have checked my other box and br0 does indeed point to ipvlan. Also while trying to research this issue, all the screenshots seem to point to the ipvlan for br0.
Any help would be appreciated.
-
Still helping to this date with the fix!
On 6/5/2022 at 9:37 PM, zer0.de said:Hi,
first Post and an than a solution
if any one have this error like me:
update_known_hosts: hostfile_replace_entries failed for /root/.ssh/known_hosts: Operation not permitted
I found this work for me:
ssh-keyscan -H TARGET_HOST >> ~/.ssh/known_hosts
on both systems and the error is gone.
Still helping to this day. Thanks!
-
You're not alone. After working flawlessIy for months, I started get this error from time to time - there appears to be no rhyme or reason to it popping up. When it does appear it appears to hang around for weeks (the on battery message) - where I finally end up pulling out the cable. I have tried removing and reinstalling NUT drivers etc. Just this morning I popped the USB cable back in, and it now states that I'm 'online' rather than 'on battery'. I did try ignoring the on battery message, but my server randomly shut down (gracefully) a few times so I suspect the it was initiated as result of this on battery message.
-
Thanks for this container.
Works a treat with 2 different Nvidia GPU cards. I swapped recently from Trex-Miner as it stopped working after the latest update. Gave this a try, and I am back up and running. Anyone here scratching their heads regarding the GPU settings when you have two installed, just put the ID of one only and both will be picked up and used. However, m just not sure of the path where it installed, as it not found in the appdata share and it doesnt seem to provide the option to instal in this share via the configuation settings - unless Im missing something...
-
On 2/9/2022 at 5:46 AM, qw3r7yju4n said:
I have the trex mining container. Sometime in the last week the damn thing went down and now i get the error
ERROR: Can't start T-Rex, can't initialize CUDA engine, cuda exception: CUDA_ERROR_SYSTEM_DRIVER_MISMATCH. Is NVIDIA driver installed?
This seems to be localized to only this container. I am using the NVENC portion of the card to transcode so passthrough works for video atleast. Rebooted, reinstalled nvidia drivers. And finally upgraded the drivers. still the same error. Any help is appreciated. I have checked with the trex guys and they said theyve seen this when the drivers arent installed correctly.
nvidia-smi on the host returns positive results. what could this be
Is the 3D engine dead? Dead card?
Did you ever figure this out? I recently upgrade TREX and now have the same issue, after it working for 5 months without issue prior to the update.
-
Not sure how as I tried many things, but my issue seems to be resolved. I now suspect that my problems revolved around my internet service connecting out to the Community App store, not an unraid configuration issue.
-
9 minutes ago, bonienl said:
It looks like the container can not be found on dockerhub, which explains the unavalibility status.
Have you tried to completely uninstall and then re-install the container?
I tried with with nginxproxymanager. I uninstalled it, but cant reinstall as I am getting the same error when trying reinstalling dockers from CA.
-
hey thanks for wading in.
Force updates dont work.
Some dockers showing that they are up to date and other not available status. See image. The majority have unavailable status though.
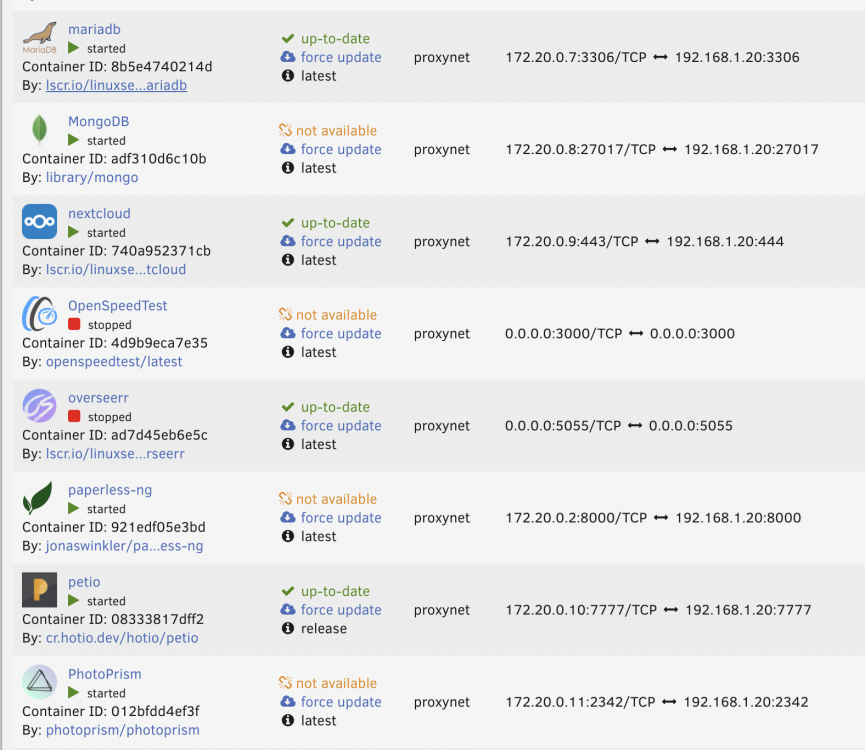
When I try an update an 'available' one - it doesn't pull any data down but goes through the process quickly and then states;
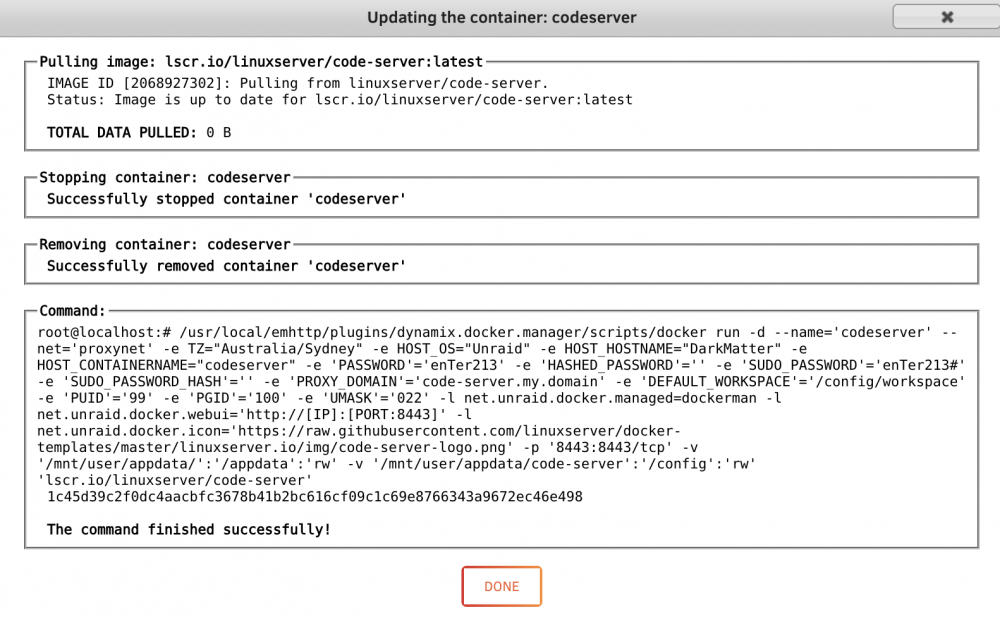
On the containers that are marked unavailable, the update process stalls for a while then it states;
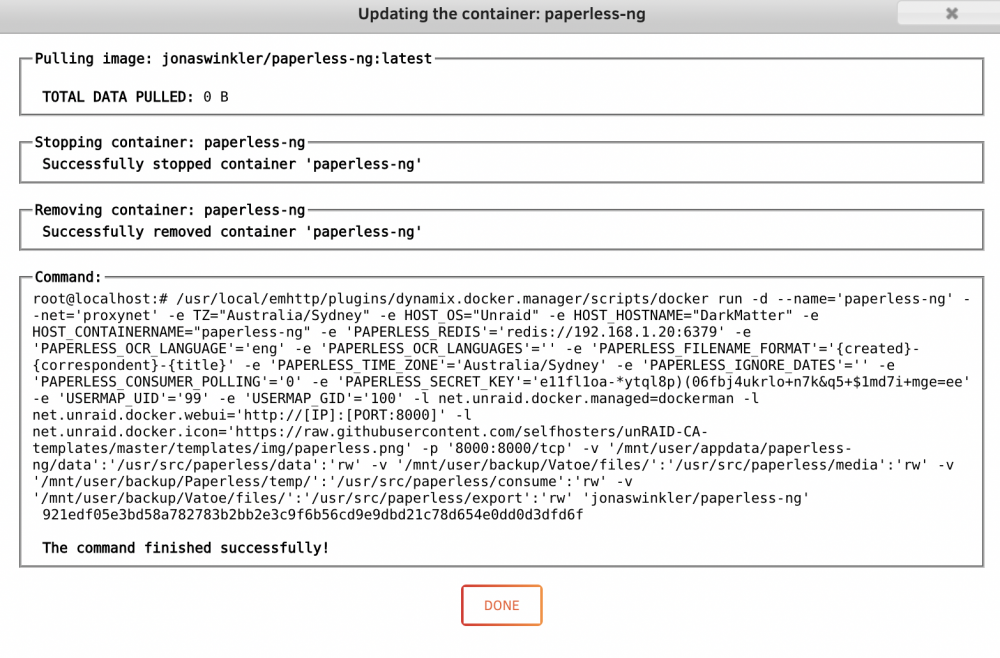
but remains unavailable after the 'force update'.
cheers
-
6 hours ago, Squid said:
Try disabling bonding in settings - network settings. With only a single NIC it's pointless to have it enabled and it only adds another layer of complexity to the system.
It also looks like you may have had issues in the past with the docker image filling up (you've set a 100G image file, which is extreme overkill for the vast majority of use cases -> you're only utilizing 14G of it). Have these issues been resolved?
Thanks for the suggestion. I hadn't noticed the bond setting. I have changed it, but unfortunately I still have the same issues. No issues with the docker image file. i think that setting was something I did a long time ago, as I don't even recall changing it to be honest. What is really weird that there is only one container that seems to download ( budge ) which was a random one I picked from CA. Every other docker I have tried will not download?
-
I can see from searches that this issue has come up from time to time, where the docker containers in Unraid show they are unavailable.
My setup previous to last night (Sydney Australia time) has been working without issue for many months in its current form. I woke up to find that many of the dockers status were change to unavailable this morning.
I have attempted all the cures in the previous threads and none of those worked.
So I have;
1. changed the DNS settings to 1.1.1.1 and 1.0.0.1 (cloudflare dns servers)
2. I can ping an external ip address eg google.com
3. I have checked the status of the various services docker hub etc
4. SABnzb can download files
5. I cannot force update any of the containers, they just time out
6. I have restarted Unraid a number of times
7. The plugins page in Unraid seems to be ok - as they show the status of up-to-date
(edit 1) I cannot install any new containers - managed to get a random contianer (budge) down but no others?
(edit 2) this is the error reported when i try to reinstall nginxproxymanager " Error response from daemon: error parsing HTTP 408 response body: invalid character '<' looking for beginning of value: "<html><body><h1>408 Request Time-out</h1> Your browser didn't send a complete request in time. </body></html> ".See 'docker run --help'."
(edit 3). Diagnostics attached as requested. Also during my attempting to diagnose the issue, I uninstalled nginxproxymanager with a view to reinstalling it. This is when I found out I coudnt download any further containers from CA.
(edit 4) Also tried to remove the docker networks and restart the service, then recreate the networks I had (br0 and proxynet) via console using:
rm /var/lib/docker/network/files/local-kv.db
/etc/rc.d/rc.docker restart
docker network create *****
Any help would be appreciated. This has me stumped.
cheers
-
Anyone who was having problems, ge the th GPU's to transcode? I tried a 1660 super and a 2060 super with no luck. All the settings/parameters were correct - tdarr continued to use CPU.
edit: My issue was from it being mis-configured in the codec selection. I think maybe an update or something had the changed the settings as everything was working previously. The container had transcoded 8TB worth of files previously without issue.
-
2 hours ago, PTRFRLL said:
I believe you add the -i flag to the command to specify the id or index of the GPU you want. Use nvidia-smi to print all cards and grab the GPU ID:
nvidia-smi -i 0 -pl 125 #assuming card 0 is the one you want
Awesome that did the trick.! Thanks for our help.
-
Can anyone tell me how to set power level for a specific GPU, via unraid console? I have two gf cards - a 2060 super - which I managed to get to 125 watts, but I would like to set the power level of the 1660 super I have, and Im not sure how to get the command to work against/for this card - I thinking I need to select/nominate it somehow first?
-
On 1/24/2018 at 4:59 AM, bonienl said:
Do the following to let docker rebuild the networks
rm /var/lib/docker/network/files/local-kv.db /etc/rc.d/rc.docker restartThanks mate. An old post, but helped me out with docker network issue.
-
On 4/20/2021 at 6:27 AM, Bleak said:
Is is one of the config files that it comes with thr cloudflared config file is for DOH (DNS over https) and the stubby config file is for DOT (DNS over TLS). I am having issues eith DOH so I set The DOT as the first dns server. Since then no issues.
Thanks for this. I just installed this docker and had issues with the failed to connect to backend error as the others have described and this seemed to remove the error at this stage.







[6.12.10] Unraid Server unresponsive after ~21 hours everytime
in General Support
Posted
No expert here, but I would be eliminating that it is a hardware issue like faulty ram.