

jackfalveyiv
-
Posts
104 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by jackfalveyiv
-
-
Looks like that's my nginx docker. Months back I needed to replace my flash drive, and I've had some weird problems around different dockers at different times. In most cases (Tdarr, Radarr/Sonarr, Plex) I had to build new dockers but plug in the old configs. I didn't do that with Nginx. Is it possible that I need to?
-
Noticed the alert firing around 12:58AM and between 4-5AM, turning off my Tdarr processes at those windows to see if that makes a difference before starting to disable dockers and plugins.
-
Looks like this happened again last night. Attaching a fresh diagnostic.
-
No, only if I'm working on something.
-
This popped up in the past few days, curious if I just need to reboot or if something else needs fixing here, thanks in advance.
-
I'm experiencing some really odd behavior in the past few days. My server (6.12.3, updated over a month ago) is crashing at random intervals. I haven't been able to find a common denominator yet and I'm hoping someone has a clue as to where I can begin looking. I have not tried to reformat the cache yet. At one server reboot cycle, the cache was unable to be found, yet another reboot and it came up just fine.
-
3 hours ago, jackfalveyiv said:
Some additional context in the attached screenshot. I see what looks like an IP address conflict, but I can't see one in my docker allocations, either for port or IP.
Just following up in case anyone has an issue like mine. I don't have an explanation for why this worked, but I wiped out the nginx docker and installed another instance, pointing to the same appdata directory, and things are working just as they had been before. If anyone has upgraded the OS, or downgraded, and runs into this, try my fix and see if that helps.
-
23 hours ago, jackfalveyiv said:
Ran into an issue after the Unraid upgrade to 6.12.4 with Nginx. When I try to browse to the local installation, I get 'ERR_CONNECTION_REFUSED' in all browsers. It's the only docker that's giving me this issue but I cannot get it to come back online. I tried restoring a backup but it was unsuccessful. I've attached a screenshot of my config, and a screenshot of the docker log. Any and all help would be appreciated.
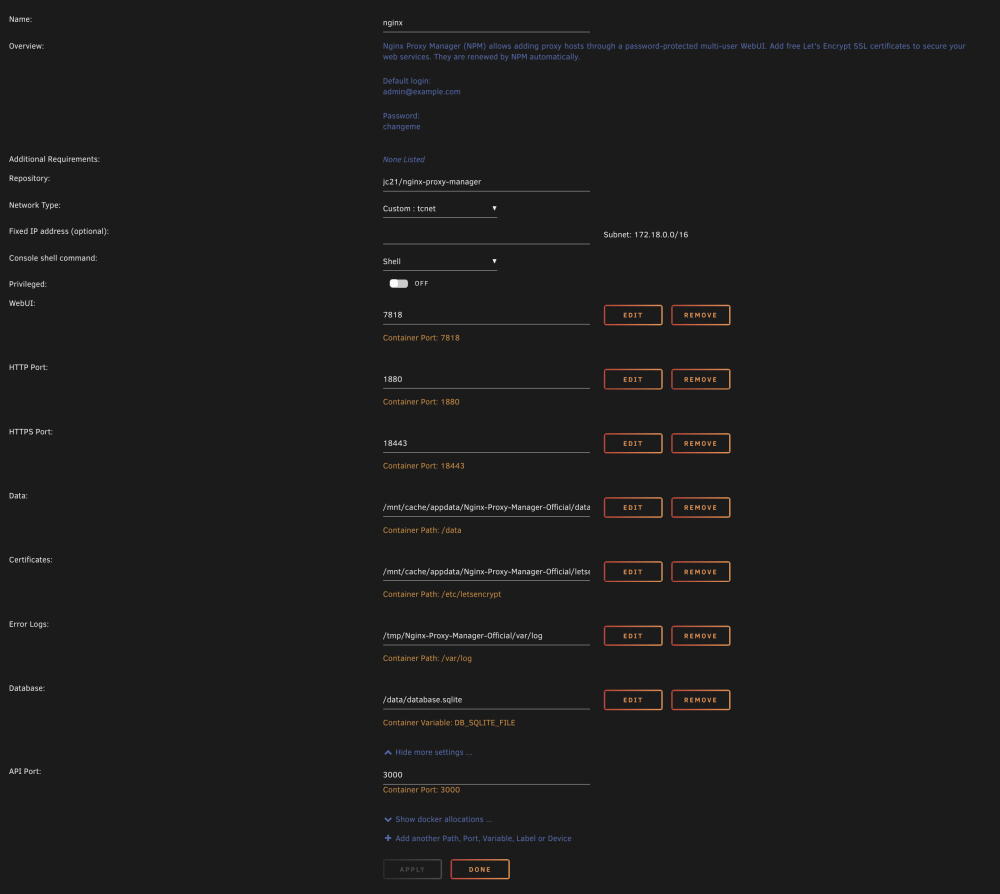
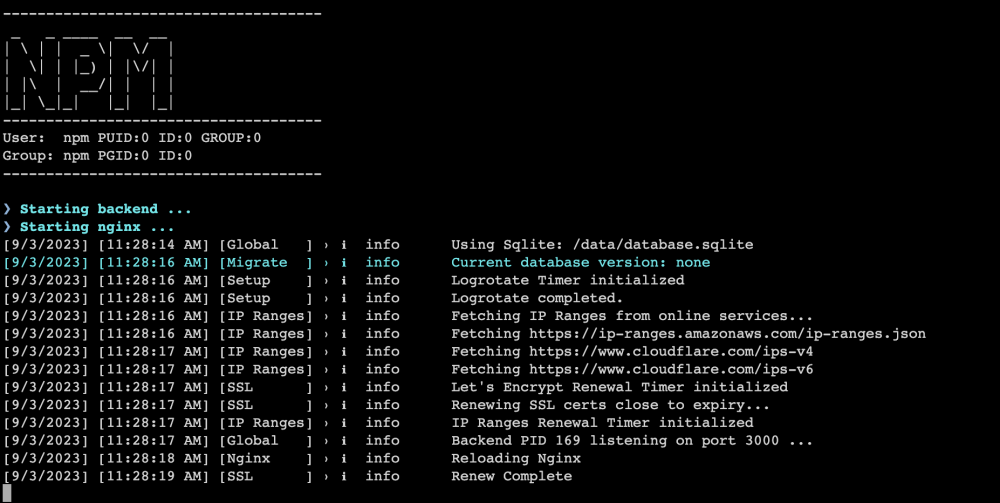
Some additional context in the attached screenshot. I see what looks like an IP address conflict, but I can't see one in my docker allocations, either for port or IP.
-
Ran into an issue after the Unraid upgrade to 6.12.4 with Nginx. When I try to browse to the local installation, I get 'ERR_CONNECTION_REFUSED' in all browsers. It's the only docker that's giving me this issue but I cannot get it to come back online. I tried restoring a backup but it was unsuccessful. I've attached a screenshot of my config, and a screenshot of the docker log. Any and all help would be appreciated.
-
22 minutes ago, blaine07 said:
The other day JC21 mentioned he was working on/considering making it a variable. I guess at some point the old certificates pileup and slow it down and it times out. It was discussed that using using very prune helped.
Maybe here: https://github.com/NginxProxyManager/nginx-proxy-manager/issues/2713
or here: https://github.com/NginxProxyManager/nginx-proxy-manager/issues/2708
poke around though; I know I just saw others Fussing about same thing recently 😀
Thanks for the tip, I'll see what I can see...
-
Is there a way to increase the timeout for host requests for all proxy hosts? I notice when I hit some Arr apps my manual search requests time out if there are too many results to load, I'm curious as to whether or not this is a timeout issue that I can increase the time interval for. Thanks in advance.
-
After the reboot the docker service is started, oddly though with all my apps back to normal. I would have thought deleting the docker image file would have hosed those. Most services are running as expected, but I'd still love to find out what happened here if anyone has a clue.
-
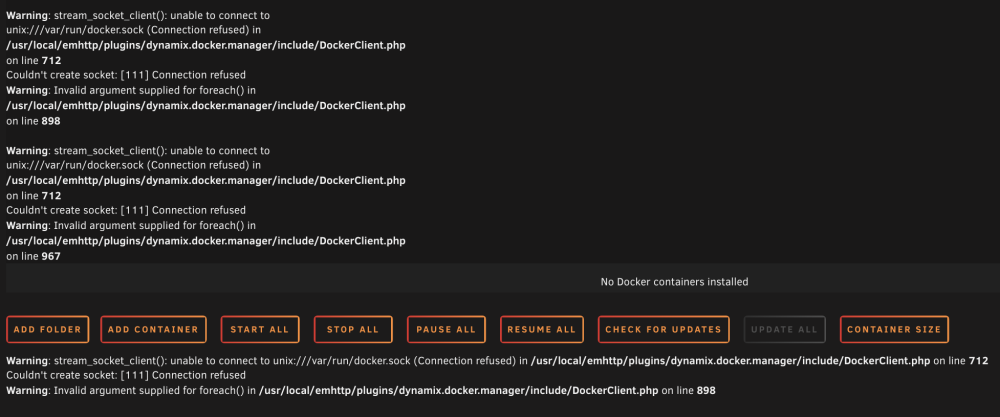
I was just made aware that my server wasn't accessible by a user, I went and took a look and found the attached screenshot of my Docker tab. I immediately deleted, then recreated my docker image, but that has not changed the status of this page. I'm currently rebooting my machine to see if that makes a difference, but I'm not sure where to start on this. I did have a queue of files processing but was using the server less than an hour ago without any indication of a problem. Diagnostic also attached, any help appreciated.
-
Quite a week...replaced the cache, then ended up with read errors on one of my array disks. Had to eventually start in Maint Mode, run a check filesystem with -L parameter to get things up and running again. Mods have recommended that my cables might be an issue, so I've got replacement SATA and power cables arriving tomorrow to hook up. I have the system back up now, and I'm seeing more nginx related errors, curious what these are indicating.
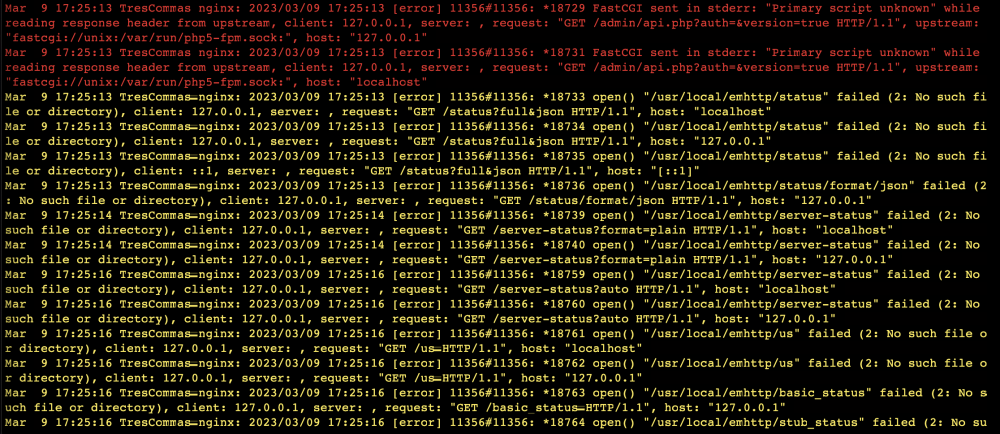
-
Understood, thank you.
-
Question: if I have the system turned on but the array unmounted, am I safe to unplug/plug-in a drive? I'm realizing I need to label my drives somehow so that I know which is which the next time I need to do some troubleshooting. Thanks in advance.
-
Ok, new cables arrive tomorrow and everything will get swapped then. Will update at that point. Thanks.
-
Noted. Replacing the cables in the coming day or two, and I received a read error this morning, fresh diagnostic posted below. Is this the beginning of a full hd failure?
-
My system is back up and running. To summarize, when migrating data off the cache for an upgrade, then back again, it looks like my System share was still on disk3 when I started up the docker service. This looks like it caused the btrfs errors that eventually crashed the disk and made it unmountable. Thanks JorgeB and itimpi for your suggestions and getting me the correct solution.
-
It did startup and mount. I'm about to rebuild the docker image and I'll report back.
-
I'll give that a try. The disk is still displaying as unmountable in the Main screen, but I'll report back after the next startup attempt.
-
Thank you. Here's the output from running with the -L option:
Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... clearing needsrepair flag and regenerating metadata - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - agno = 16 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 5 - agno = 8 - agno = 13 - agno = 6 - agno = 7 - agno = 1 - agno = 10 - agno = 11 - agno = 14 - agno = 12 - agno = 16 - agno = 15 - agno = 3 - agno = 4 - agno = 9 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (4:1198044) is ahead of log (1:2). Format log to cycle 7. done -
Booted to maint mode, tried a Check Filesystem Status -nv and got the following:
Phase 1 - find and verify superblock... - block cache size set to 1404320 entries Phase 2 - using internal log - zero log... zero_log: head block 1197993 tail block 1197987 ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - agno = 16 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 1 - agno = 2 - agno = 5 - agno = 3 - agno = 9 - agno = 15 - agno = 4 - agno = 13 - agno = 7 - agno = 10 - agno = 11 - agno = 12 - agno = 0 - agno = 14 - agno = 16 - agno = 6 - agno = 8 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - agno = 16 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... Maximum metadata LSN (4:1198031) is ahead of log (4:1197993). Would format log to cycle 7. No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Wed Mar 8 15:27:15 2023 Phase Start End Duration Phase 1: 03/08 15:27:06 03/08 15:27:06 Phase 2: 03/08 15:27:06 03/08 15:27:07 1 second Phase 3: 03/08 15:27:07 03/08 15:27:11 4 seconds Phase 4: 03/08 15:27:11 03/08 15:27:11 Phase 5: Skipped Phase 6: 03/08 15:27:11 03/08 15:27:15 4 seconds Phase 7: 03/08 15:27:15 03/08 15:27:15 Total run time: 9 seconds -
Fresh diagnostic posted below





[Support] Nginx Proxy Manager (NPM) Official
in Docker Containers
Posted
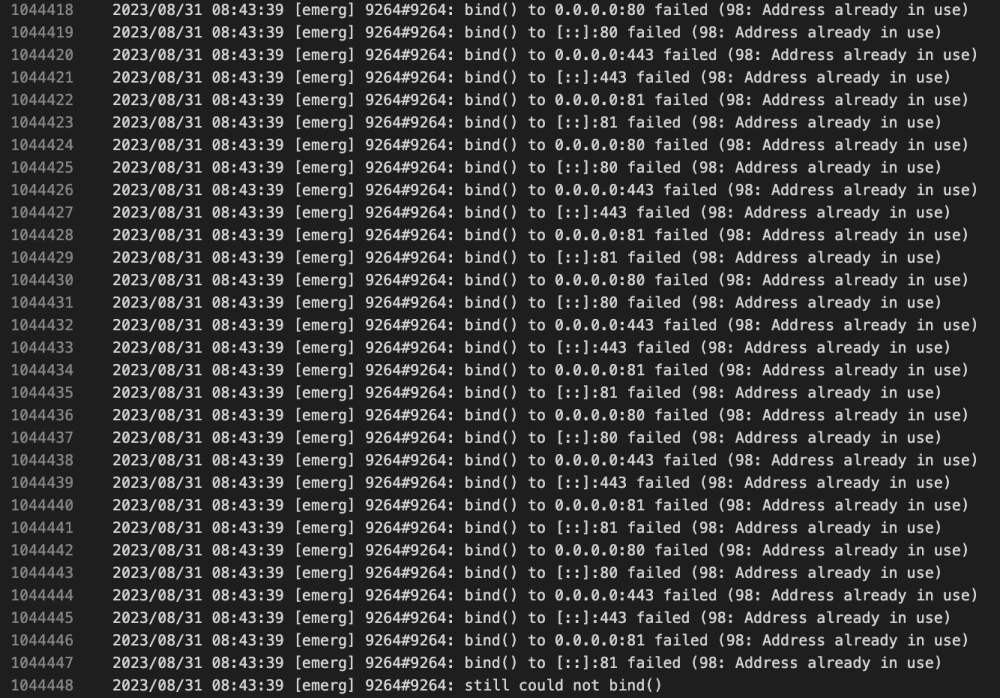
Getting some strange errors that I can't parse out in the logs. My Unraid Fix Common Problems plugin has alerted me over teh past few days that I was getting Out of Memory errors. AFter looking into that on the forums, a user helped me figure out that Nginx was the culprit. My proxy host entries look normal, and I haven't made any changes to the app in over a year. When I took a quick look at the logs, I see a ton of '[emerg] bind() to ...failed (98: Address already in use)' messages. I'm not sure where to start on this, hoping for some guidance, thanks.fallback_error.log
proxy-host-11_access.log proxy-host-19_access.log fallback_access.log