

lmanstl
-
Posts
10 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by lmanstl
-
-
52 minutes ago, JorgeB said:
Please post the diagnostics after a format attempt.
I can get the diagnostics in about 18 hours. The error message when trying to use fdisk to format in unraid terminal or Ubuntu is /dev/sdf: fsync device failed: Input/output error
When I try to format using the internal Cisco 12g SAS controller or the LSI 9300-8e SAS HBA I just get a message that says Failed. The cards also don’t seem to realize that the disk is an SSD like the others that are present instead listing it like a hard drive without self encrypting features.
My best guess is some sort of firmware issue but I don’t know what caused it or how to solve it. It happened on 3 drives at the same time but not the other 5 that were attached or the 17 that weren’t attached.
-
20 minutes ago, JorgeB said:
Unassign all cache devices, start array, stop array, re-assign all cache devices, start array, that should do it.
You are amazing. I can’t believe it was that easy, the only thing I haven’t tried. I have spent like 3 days trying to fix this among other issues.
Thank you.
I don’t suppose you know how to fix an SSD that shows up perfectly fine everywhere but refuses to be accessed through an OS and refuses to format through the HBA BIOS. It is an HGST HUSMR1650ASS210.
-
I am setting up a new unraid server and am still working through all the kinks. 3 of my SSDs refused to format no matter what HBA I attached it to so I just removed those.
I replaced them and then added them to the cache pool in place of the 3 broken ones. It worked correctly and I was able to format the pool. But the next time I rebooted, it says that the 3 drives are wrong and that it wants the 3 broken drives again. When I start the array it says that those 3 drives are disconnected and contents emulated. It also won’t let me reformat the pool.
I tried making the pool bigger and that didn’t work. I made the pool smaller and that worked but when I made it the right size again it pulled up the old config. I was able to format if I changed the file system to encrypted but a reboot still brings back the old config and then I converted back to regular and it let me format again but after a reboot it still has the old config. Deleting and remaking the pool also didn’t help. I can’t get unraid to forget the old broken drives.
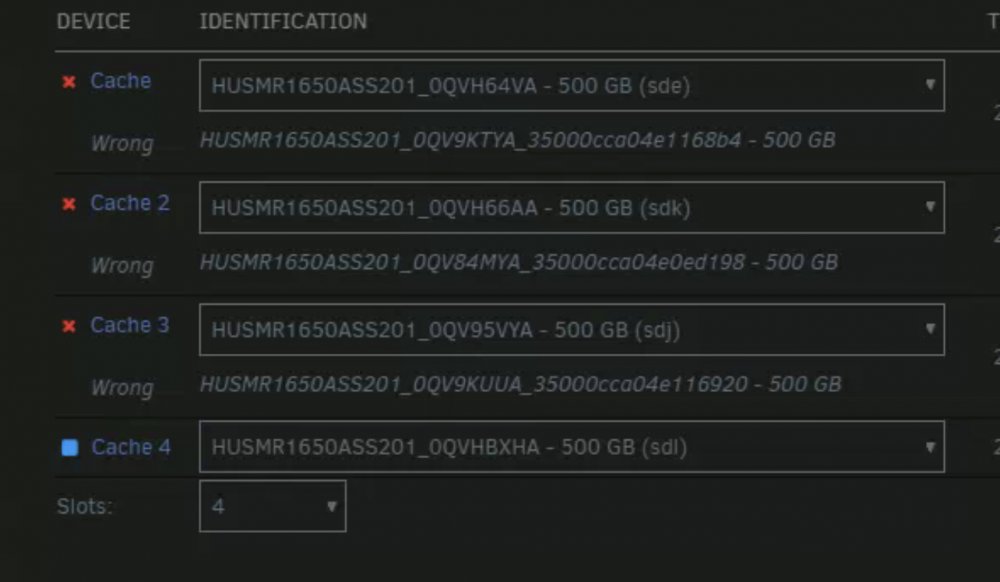
-
Ok, I think I found the issue. The plex pool was looking for the sdae drive, but that drive path was reassigned to another disk after the shuffle. That disk is located in the virtualmachine pool which is initialized first before the plex pool normally. The reason it was causing problems when starting the array is because plex is where my appdata and system shares are located. Disabling docker allowed the array to start fine and I was able to format the other pools with changes and begin clearing the new data disks in the array.
I do not currently have docker running and the plex pool is still read only. I am initiating a full back up of all files on the pool and then I will figure out what to do. I am considering just deleting the pool and recreating it and then restoring the backups since the mover isn't doing anything after I switch from prefer to yes for the cache option or to another cache pool. Unless you have any other ideas to make it work.
I will not have physical access to the machine for the next week and a half so any solutions would have to be software solutions.
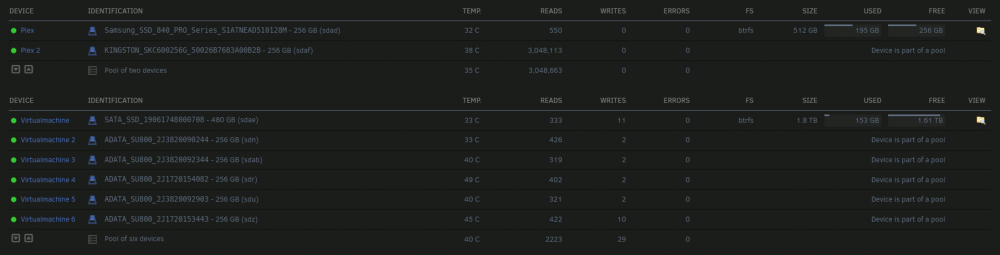
-
 1
1
-
-
root@My-NAS:~# btrfs fi usage -T /mnt/plex Overall: Device size: 476.95GiB Device allocated: 238.47GiB Device unallocated: 238.47GiB Device missing: 0.00B Used: 181.44GiB Free (estimated): 294.00GiB (min: 294.00GiB) Free (statfs, df): 238.47GiB Data ratio: 1.00 Metadata ratio: 1.00 Global reserve: 512.00MiB (used: 0.00B) Multiple profiles: no Data Metadata System Id Path single single single Unallocated -- ---------- --------- -------- -------- ----------- 2 /dev/sdae1 235.44GiB 3.00GiB 32.00MiB 1.02MiB 3 /dev/sdw1 - - - 238.47GiB -- ---------- --------- -------- -------- ----------- Total 235.44GiB 3.00GiB 32.00MiB 238.47GiB Used 179.91GiB 1.53GiB 48.00KiB
The reason the cache pool may be devices is because that was one of the pools I was altering. It was empty and I was trying to remove a failing drive (only 1 so I am not sure why there are 3 missing devices). However, all the drives that were there before are still present and they all show up in the RAID controller configuration utility. I am not sure why plex seems to be set to single mode. I remember setting it to RAID1 when I made it.
-
6 hours ago, JorgeB said:
Get the syslog and post it here:
cp /var/log/syslog /boot/syslog.txtAttached
-
I was in the process of reconfiguring the array to consolidate pools and add some new drives to the array when some of my cache drives spontaneously disconnected and that prevented the array from starting (this happens sometimes when I try to start the array normally and a reboot fixes it, I traced the problem to some iffy connectors in my JBOD but they usually work so I deal with it). I attempted to soft reboot using the UI button, but nothing happened. After letting it sit for 30 minutes with nothing visible happening, I hard rebooted.
On the next boot there were some BTRFS errors:
BTRFS: error (device sdaf1) in cleanup_transaction:1942: errno=-28 No space left
BTRFS: error (device sdaf1) in reset_balance_state:3327: errno=-13 Readonly file system
These errors occurred immediately after the login prompt shows and the web UI does not start or is not accessible. The integrated graphics on the motherboard of the server do not support the local booting of the web UI so I can't check that. The command line still works though.
Soft rebooting after these errors causes it to get stuck on "Starting diagnostics collections..." for more than 20 minutes (I hard rebooted after that).
Searching for these errors led me to this link: https://www.suse.com/support/kb/doc/?id=000019843 but, the extent of my BTRFS knowledge ends at using the unraid gui and I have no idea what the mountpoint would be if that solution would even work in this case.
Any assistance in the issue would be appreciated, Thanks.
-
7 hours ago, RiDDiX said:
Nah, you dont messed up your server. You should just enable "expert view" within editing the VM and empty your xml completely.
Than you should be able to remove your VM (without the vdisk!). The vdisk can you manually remove within the domains folder on your server.That is a much easier method to remove the old VM.
7 hours ago, RiDDiX said:I fixed my problem myself. I got a bad OpenCore Config.plist. I just redid my OpenCore and then I was able to update just fine from Big Sur 11.2.3 to 11.3.
I was under the impression that this configuration was supposed to be automatic. If this is the only solution to my issue, then I will probably wait to see if an update solves my problem. I looked into this but it looks like a multi hour plist altering process and messing around in MacOS is not worth that much more of my time.
-
I tried to set this up. Initially I forgot to switch from Catalina to Big sur. After it finished downloading Catalina, I did that and restarted macinabox but the helper script still created the Catalina VM. I managed to delete that VM after some trouble and having to run the command virsh undefine --nvram "Macinabox Catalina" to allow me circumvent the error saying that there is nvram allocated to the domain preventing me from removing the VM in the webUI (this is probably the wrong way to do this but it was the solution that popped up on google), then remove the iso files, the custom_ovmf folder, the disk image, and the macinabox appdata folder and restart macinabox with the correct settings.
After doing all that, I got Big Sur loaded and booting. however after selecting MacOS base system for the initial install the apple logo shows up and then a loading bar for a few seconds and then it reboots with the message "your computer restarted because of a problem" on the following install attempt and I am completely unable to advance any farther.
I repeated the reset steps listed above and went back to Catalina and had the same issue. (still currently installed and not working)
I have no idea if I messed up or if my server just doesn't want to work. Any assistance would be appreciated.



Unraid loads old config on reboot
in General Support
Posted
Here are the diagnostics.
This line in the syslog marks the start of the format operation on the bad SSD: Jul 26 15:36:23 Artemis emhttpd: shcmd (152): mkdir -p /mnt/test
I am not really expecting a fix, but if you recognize something that could cause this let me know so I can avoid breaking the rest of my drives.
Thanks again for helping.
artemis-diagnostics-20220726-1743.zip