

ds123
-
Posts
47 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by ds123
-
-
2 hours ago, JorgeB said:
If there's nothing relevant logged it usually points to a hardware issue, one thing you can try is to boot the server in safe mode with all docker/VMs disabled, let it run as a basic NAS for a few days, if it still crashes it's likely a hardware problem, if it doesn't start turning on the other services one by one.
What capabilities are affected by switching to safe mode? will the array be inactive?
If it's a hardware issue, how to identify the faulty hardware?
-
5 hours ago, JorgeB said:
It usual works fine, make sure it's correctly configured, a lot of users misread the instructions and don't fill in the remote server IP.
You can stop it for now but good to run one once this issue is resolved.
It configured correctly, there is a syslog file in the share and logs are written, it just don't have any log from the crash
-
Hi,
I enabled the syslog server logging to a local cache share (to avoid a lot of writes to the flash drive).
Today, a week after, the server crashed again and started a parity checl again. However, the local syslog file doesn't have logs prior to the crash (the last log before the crash was written an hour earlier).
Two questions-
1. Is using a local file for the syslog server problematic to catch crash issues? If so, will writing to the flash drive help?
2. Is it safe to stop the parity check? it's the third time over the past 3 weeks the system runs a parity check due to this issue.
-
Hi,
My server crashes randomly every once in a while (twice already this month) causing multiple parity checks.
This started happening recently even though no new containers or plugins were installed.
Attaching diagnostics taken after the last crash.
What could be the issue and what is the best way to find the root cause?
-
Thanks.
Changed to ipvlan, so far no issues.
-
 1
1
-
-
8 minutes ago, JorgeB said:
Yes.
Usually none.
Thanks for the quick reponse.
Will I be able to keep the same network settings in each of my docker containers? including my user-defined network, br0 and host? Or should something change?
-
Hi,
After upgrading from 6.11.5 to 6.12.1 I received the following error from the Fix Common Problem plugin -
Quotemacvlan call traces found -
For the most stable system, you should switch the network driver in Settings - Docker (With the service stopped) from macvlan to instead be ipvlan
I never had this error before 6.12.x. For now, the server is working properly so there is currently no impact.
Can someone please help in understanding this error? Should I change to ipvlan? What are the implications of doing this?
In terms of my docker network types - I created a custom network for most of my containers. In addition to that, I have one container that uses br0 (pi hole) with fixed ip address and another containers that use host network (plex and duckdns). Wanted to make sure nothing breaks if I change the docker custom network type to ipvlan.
Thanks,
-
So after about a year that this problem occured relatively rarely, in the last few weeks Disk 1 (the same disk) disappears every few days and even several times a day (until restart), so now I'm worried and looking into it more deeply.
I switched both the SATA and power cables of Disk 1 with another disk in the array to see if the problem recurs with another disk. To my surprise, today the problem occurred again with the exact same disk - Disk 1.The log is the similiar to the log JorgeB referred above (this time with ata6) -
QuoteFeb 27 12:01:15 Tower kernel: ata6: SATA link down (SStatus 4 SControl 300)
Since it always happens with the disk, even with different SATA and power connectors, does that mean there is a problem with the disk itself?
or maybe 7 disks are too much for the MB/PSU (still unclear why it's always the same disk).
should I replace it and activate warranty in this case? other than disappearing, the disk is healthy.
-
-
2 hours ago, ChatNoir said:
Could be an issue with the controller, the DATA or POWER cable, the PSU.
Difficult to say without the diagnostics of your system or ideally the diagnostics when the problem occurred.
I have attached the diagnostics of my system after rebooting. I currently don't have the diagnostics when the problem occurs, but I will try to download next time it happens.
-
Over the past few weeks, in two different cases Disk 1 was missing and the array was stopped. Restarting the system solved the problem.
The SMART test is ok, and parity check has passed without issues.
What could be the problem? this is a new disk (about 5 months old). -
19 hours ago, nukeman said:
No, not with MariaDB. I installed a MySQL docker and everything is back to working like it should.
Could you please elaborate how you migrated to MySQL? I have thousands of records and I don't want to rebuild the DB from scrtach.
-
On 11/16/2021 at 4:48 AM, nukeman said:
I'm experiencing a weird issue with kodi and a shared mariadb . Right now my setup contains a windows laptop, android tablet, shieldtv, and chromebook that all share the same video and music database. I think I've isolated the behavior to the following: if I open kodi on the windows laptop, I can no longer open kodi on the android devices. If I reset the mariadb docker container, android starts working again. I've been running a shared database for years without seeing this issue. It seems to be similar to what's mentioned here but there's no solution.
I don't know if this has to do with the issues from that started popping up here around in August. These seemed to be related with the update from ubuntu to alpine. The fix was to downgrade mariadb then upgrade to latest. If this is the issue referenced above, would someone summarize the steps required to fix it? The steps are mentioned in this thread but it's kind of scattered and hard to follow.
The relevant section of the chromebook's kodi log after the windows laptop launched kodi:
2021-11-15 19:07:18.664 T:5323 INFO <general>: MYSQL: Connected to version 10.5.13-MariaDB-log 2021-11-15 19:07:18.761 T:5323 ERROR <general>: SQL: [music-adults82] An unknown error occurred Query: SELECT idVersion FROM version 2021-11-15 19:07:18.763 T:5323 ERROR <general>: Process error processing job
I realize "An unknown error occurred" isn't very helpful and I'd be happy to post more relevant logs from kodi and mariadb once we confirm what the problem is. Anybody else experience this?
have you managed to solve the problem?
-
On 10/6/2021 at 11:57 AM, pengrus said:
Hi,
At some point coincident with the latest update to the MariaDB container, I've had an issue where the container will not allow multiple clients to connect to the Kodi databases. I've attached the log, but basically if one client is accessing the database, it will refuse to let another connect until I restart the container. I've made no configuration changes other than attempting the downgrade/upgrade to latest procedure on page 17.
Any ideas?
Thanks!
-P
I have the same issue.
-
18 hours ago, whipdancer said:
IMO WD <Color> <anything> is currently overpriced. The exception probably being Blue drives which have slower RPM and smaller cache and don't come in a size I'd consider for data storage - but otherwise, attributes that make very little difference in Unraid in my limited, strictly anecdotal, experience.
I'm curious if those price trends are recent and/or more indicative of Toshiba, than of general pricing strategies. I know that 12TB Iron Wolf, RED Pro, Exos, Iron Wolf Pro, Red+, Toshiba NAS were all over $360-ish when I was looking last summer. Technically, each of those models is targeted toward a different market, but that does not factor in to my purchases (which is why I bought the enterprise drives I did, when i did - strictly $/TB).
Nostalgically speaking, what I wouldn't give for some WD Green 18TB drives. My green drives all gave me better than 40k hours of service before I retired them. 4 of them now live in a friends QNAP (or whatever) NAS.So if pricing is not a factor, are you saying it doesn't really matter whether it's an enterprise drive or not?
I'm mainly concerned about the noise level and temperatures, because enerprise drives are designed for use in data centers, where noise is less important and where there are massive cooling systems.
-
19 minutes ago, whipdancer said:
I'm using WD Ultrastars which are enterprise drives. No issues so far. I got them because of the deal at the time, not because I care that they are enterprise drives.
The Backblaze data is rather eye opening if you've never seen it. There does not appear to be a compelling reason to use enterprise drives, when focused purely on costs (warranty/support associated with enterprise relationships are an entirely different consideration).
They actually seem to be sold at a much lower price, for example -
WD RED Plus 14TB - 410$ https://www.amazon.com/Western-Digital-14TB-Internal-Drive/dp/B08V13TGP4
Toshiba MG Series Enterprise 14TB - 330$ https://www.amazon.com/Toshiba-14TB-SATA-7200RPM-Enterprise/dp/B07DHY61JP
-
Perhaps the question is more general, whether enterprise drives are suitable for a home unraid system.
Does anyone have any experience with such drives?
-
Hi,
Toshiba Enterprise hard drives seem to be sold at a much lower price than traditional NAS hard drives like WD RED.
Are they suitable for home use in an Unraid system? In terms of reliability, noise, temperatures. Specifically asking about MG08 14TB with helium inside - https://www.newegg.com/toshiba-mg08aca14te-14tb/p/N82E16822149785
My current setup:
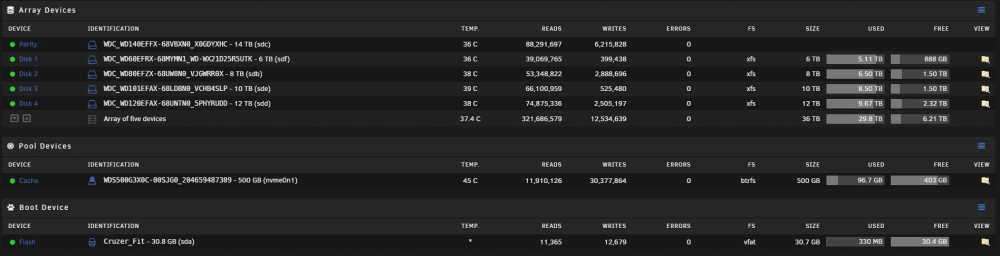
Wanted to replace the 6TB data HDD (which is more than 5 years old) with 14TB.
Thanks
-
13 hours ago, ich777 said:
Well that's the Integrated Memory Controller... Hope that makes it a little bit clearer what it is and what it does.
That's a bug in the intel_gpu_top executable and nothing that could be easily solved for now...
Can you share your diagnostics so that I can send it to the developers from the intel_gpu_tools so that they can take a look at it?
Sure, thanks.
-
1
-
-
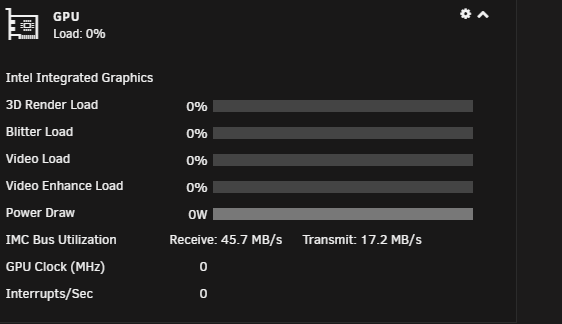
IMC Bus Utilization is always active, is this normal? Also, the Power Draw also seems to be "full" even though 0W is consumed
-
11 minutes ago, mason said:
there was a bugfix release today 2.8.12. .. no issue of the container.
image is updated.
Thanks
-
@mason MediaElch continues to crash also in 2.8.10
-
I think there is a bug in the latest release.
Sometimes when clicking on "reload all concerts", the containr crashes and stops. Didn't happen in the previous version.
My settings -

Logs -
MediaElch 2021-05-03 19:07:43.092 DEBUG : [ConcertFileSearcher] Adding concert directory "/concerts"
MediaElch 2021-05-03 19:07:43.094 DEBUG : Index is invalid
[services.d] stopping services
[services.d] stopping app...
[services.d] stopping x11vnc...
caught signal: 15
03/05/2021 19:07:43 deleted 50 tile_row polling images.
03/05/2021 19:07:43 Restored X server key autorepeat to: 1
[services.d] stopping openbox...
[services.d] stopping statusmonitor...
[services.d] stopping logmonitor...
[services.d] stopping xvfb...
[services.d] stopping nginx...
[services.d] stopping certsmonitor...
[services.d] stopping s6-fdholderd...
[cont-finish.d] executing container finish scripts...
[cont-finish.d] done.
[s6-finish] syncing disks.
[s6-finish] sending all processes the TERM signal.
[s6-finish] sending all processes the KILL signal and exiting. -
9 hours ago, mDrewitt said:
I'm seeing the same thing on a new install. Can't seem to figure out at all what's going on, no other logs seem to be displaying any errors.
https://github.com/qbittorrent/qBittorrent/issues/11150
It fails because qbittorrent doesn't have access to private trackers.
I found a workaround - install the Jackett docker, then configure an indexer for the private tracker, then enable the Jackett search plugin in qbittorrent, search and download from there.




Server crashes occasionally causing many parity checks
in General Support
Posted · Edited by ds123
Hi,
I switched to safe mode lasy friday and disabled all docker containers and VMs.
About 5 days later, the server crashed. This time the server didn't restart by itself - I found the server off and had to press the power button to start it again.
Nothing relevant was logged to the local syslog file, in fact there are no logs from the day the crash occurred.
Does this mean it's a hardware problem? What is the next step?