

Pela
-
Posts
44 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Pela
-
-
第一张图的页面输入bash回车 试试
-
我理解的校验盘是通过计算阵列中所有数据盘相同位置扇区的数据,是直接读取底层磁盘的数据,与上层的文件系统无关,所以一个阵列中的硬盘的文件系统可以同时有btrfs和xfs,并且校验盘的大小要大于等于阵列中最大的磁盘
-
看了一下官方文档,看起来不是很建议移除硬盘时不重新计算校验数据
-
1.添加硬盘时,是不是先用preclear这个插件把要添加的硬盘全部写0,就可以避免重新计算奇偶校验数据嘛?
2.移除硬盘时,有没有办法不重新读取全部硬盘计算奇偶校验数据呢?
-
后面又想了一下,
如果按扇区来校验应该也能解释不会同时读取所有数据盘和校验盘,因为写入的数据只修改了目录所在的盘,如果写入导致位变化了修改校验数据就可以
-
27 minutes ago, xing said:
docker应该是没在更新,但是我是usb外接了一块一盘,那有什么方法解决这个问题吗?
你可以先打开ssh,下次web登陆不进去的时候ssh进去看看有没有明显有问题的进程
-
4 hours ago, xyzeratul said:
这东西这么热吗?我那个机箱本来散热都很勉强了。
如果不加风扇,待机状态下烫手
-
1.计划的奇偶校验是否可以暂停?
2.从网上看到,添加了奇偶校验的阵列在写入时只会读写校验盘和写入目录所在的数据盘,那这样看来奇偶校验是以目录为单位的?
3.本来我以为校验是根据扇区为单位,这样在写入时会读取所有的阵列数据盘,增量校验的时候就可以记录每次暂停前的扇区,下次再从这里开始,但好像不是这样,那Parity Check Tuning这个插件实现的增量校验原理是什么呢?
-
1.docker更新时如果网络有问题,会卡在后台
2.通过Unassigned Devices挂载别的设备,有时候web登不上,ssh登陆上会发现有很多脚本卡住
这是我使用中发现的问题
-
lsi9207-8i,增加功耗10w左右,需要风扇散热
ssu sa3316je pcie转16口sata
以上两款个人使用过
-
51 minutes ago, Vr2Io said:
輸入 dmidecode -t 16 就可看到 BIOS max memory info., 但因 memory 實際大於此, 所以會有 * 号.
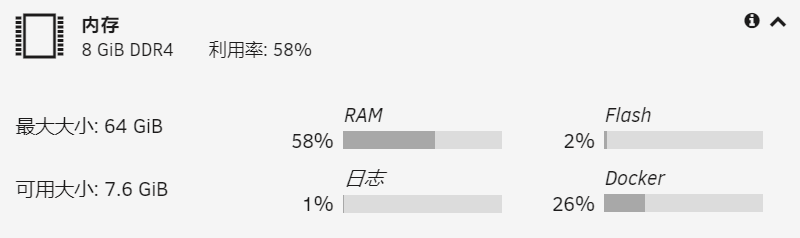
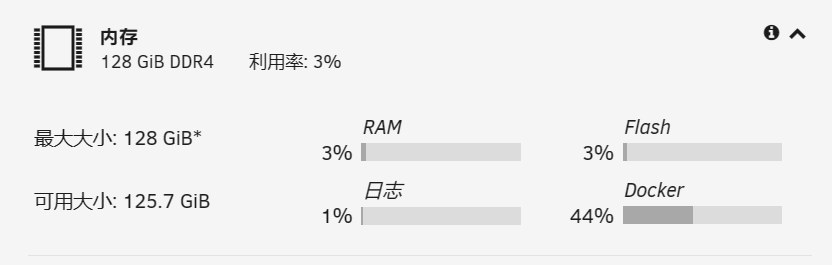
我的 J1900 BIOS max info. 是 8G, 因為有 16G 所以就有 * 号.
dmidecode -t 16 # dmidecode 3.4 Getting SMBIOS data from sysfs. SMBIOS 2.8 present. Handle 0x0028, DMI type 16, 23 bytes Physical Memory Array Location: System Board Or Motherboard Use: System Memory Error Correction Type: None Maximum Capacity: 8 GB Error Information Handle: Not Provided Number Of Devices: 2
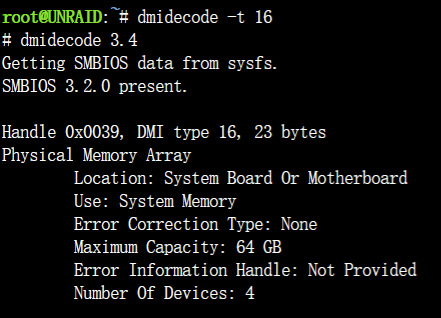

msi 这款b460 官网上说是支持128g的,为什么查出来64g max呢
-
23 hours ago, winglam said:
不可能,看你用什么硬件吧了!你的系统可以支援256的话,上256都没问题!
我的x570s aorus master就插满128, 完全没有问题。
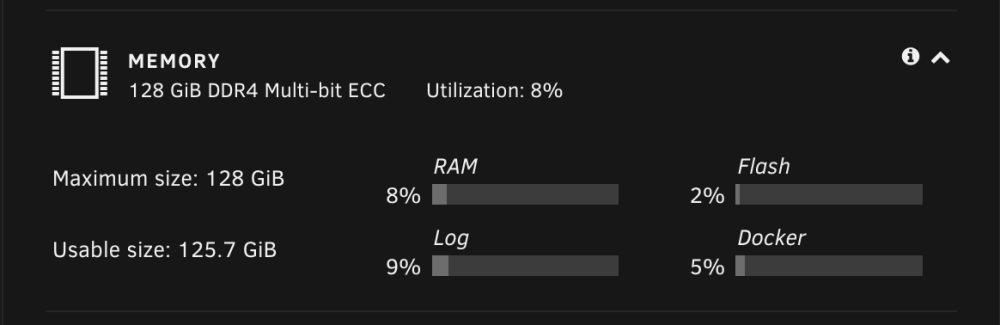
我的b460主板,插满后不知道为什么是128*,这个*不知道什么意思
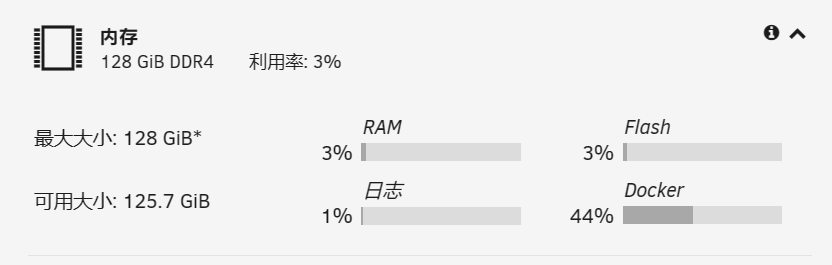
-
On 2/23/2023 at 2:04 PM, 程世平 said:
插满确实可以看到128g,但是不知道为什么128g右上角有个*
-
我不理解为什么docker pull的时候网速慢 会导致网页服务崩溃,而且如果反向代理了web页面直接reconnect了
-
On 2/13/2023 at 11:52 PM, nzzz said:
我是通过APP页面安装docker 如果docker下载的特别慢或者超时 网页会一直加载 然后卡死 然后网页就再也进不去了 只有重启nas网页才会恢复
看起来是这样的,也太操蛋了,因为docker更新或者下载网速慢就导致网页崩,以前版本应该是没有这个问题的
-
不通过apps页面,手动创建docker容器,填写好模板以后点创建web界面就卡住
之前打开的main界面还能看到cpu占用率,网口速率这些刷新,但是网页一刷新就进不去了,等待一段时间后这个页面也503(也可能是其他的,记不太清了)了
之前打开的终端网页也能下发指令 ,比如reboot
自定义的docker是甜糖的docker,网络类型host 只添加了一个路径
不知道大家有没有遇到过相似的问题
-
根据你的需求:
两个ssd做raid1,存放system文件夹,并将策略设置为“仅”
这样一块硬盘坏了系统还能运行
-
On 1/28/2023 at 9:35 AM, lagunapata said:
缓存池的raid1的替换我印象里是以小容量的那个为准的
如果是raid1扩容 或者损坏 正确的顺序是这样的
准备:
如果你是的SATA固态,直接插入先识别,如果是M2的就要先关机插入机器让系统识别
1、停止阵列
2、把你坏掉的或是想要替换掉的盘从缓存池里拿掉,替换成新的盘,新盘的容量必须大于等于旧盘
3、启动阵列,这个时候会格式化和同步新盘
如果你原本的俩M2都满了要扩容就要关机一次
1、停止阵列
2、电源关机 换掉坏的M2
3、开机,把新盘选到坏盘的缓存位置上
4、启动阵列,等格式化和同步
如果你是向raid1里去掉一个 变成普通的缓存盘 顺序(应该)差不多 我没这么搞过
1、停止阵列
2、把缓存raid1里的一个盘去掉
3、把去掉这个盘选到阵列里去 或者创建一个新的cache(
4、启动阵列
可以参考一下https://wiki.unraid.net/Manual/Storage_Management#Why_use_a_Pool.3F
这个手册
最安全的方案是 关闭所有的 docker VM
把所有cache里的内容mover到阵列里
然后再去碰cache
(cache raid1掉过盘的路过 还好没有丢数据
我是想把raid1的两块硬盘拆分出来用,不过去掉一个硬盘启动的话生成新配置的时候如果pool是一个slot会报文件系统警告文件挂不出来,如果新配置是两个slot的话,启动的时候会有大量读取写入,btrfs系统在修复的时候还停不了阵列,看起来像是在一块硬盘里面做了raid1
-
原本是两个相同容量ssd做缓存池,自动做了raid1 btrfs,现在想拆一个ssd换一个更大容量的,分开做两个缓存池使用
结果换了以后阵列无法启动,生成新配置启动后说原来做raid1的ssd 显示无法挂载
有没有解决办法呢?不然raid1做了有什么用呢,一块盘坏了就读不出数据了
-
求助,unraid也可以自己ping自己
unraid还有一个zerotier分配的ip,这个使用没有问题
-
张大妈上看到一篇文章 unraid安装clash 及启用http代理
有几个疑问:
1.按照文章的设置好了unraid http代理, 以后unraid需要访问国外网站下载的时候(例如商店插件这些)都走代理了
2.如果clash 挂了,由于设置了代理,unraid还能正常访问吗(zerotier这种穿透方式)
-
请问我现在阵列中只有一块ssd,里面有appdata,domains,isos,systems这些默认文件夹,现在需要把一块hdd作为数据盘,原有的ssd和一块新的ssd组raid1做缓存盘,之前的文件都移动到缓存盘中该如何操作?
我目前想到的是先往阵列中加hdd,数据移动到hdd中,然后新配置删掉ssd,在新建raid1缓存,用mover把文件夹移动到缓存中,但是这样hdd是不是就固定在第二个插槽中,如何更换硬盘插槽位置但不影响数据?
-
systemctl restart docker
在云服务器上我是这么重启服务的,unraid没试过
-
#!/bin/bash sleep 5m # auto mount mkdir -p /mnt/remotes/Downloads mount -t cifs -o uid=99,gid=100,iocharset=utf8,username=*****,password=***** //群晖目录 /mnt/remotes/Downloads mkdir -p /mnt/remotes/DiskStation mount -t cifs -o uid=99,gid=100,iocharset=utf8,username=*****,password=***** //群晖目录 /mnt/remotes/DiskStation # auto start docker restart Jellyfin docker restart syncthing docker restart transmission







Array to cache問題
in Chinese / 简体中文
Posted
这样的pool中两块硬盘做了raid1,我曾经这样配置过并且手动移除掉一块硬盘再启动阵列,数据还在,你可以再试试
另外system文件夹中默认只是存放docker镜像和虚拟机的libvirt.img文件,似乎没有必要做备份
针对文件夹的备份,rclone和rsync都是不错的工具