

michael123
-
Posts
363 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by michael123
-
-
Hi
As it is impossible to work on 100 MBit/sec, I would like to downgrade back to 6.11.x, but how do I do it to preserve everything?
thanks
-
I have ethtool output for 6.11.5
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: Symmetric
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Auto-negotiation: on
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
MDI-X: on (auto)
Supports Wake-on: pumbg
Wake-on: g
Current message level: 0x00000007 (7)
drv probe link
Link detected: yesFor 6.12.x that's same except it is 100Mb/s
and driver info for 6.11 is
driver: igb
version: 5.19.17-Unraid
firmware-version: 3.25, 0x800005cc
expansion-rom-version:
bus-info: 0000:03:00.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: yes
supports-register-dump: yes
supports-priv-flags: yeswhile for 6.12 is
driver: igb
version: 6.1.36-Unraid
firmware-version: 3.25, 0x800005cc
expansion-rom-version:
bus-info: 0000:03:00.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: yes
supports-register-dump: yes
supports-priv-flags: yes
-
I upgraded from 6.12.1 to 6.12.2, but still same 100 MBit/sec
Question - how difficult is to go back to 6.11.xx ?
-
unrelated to the question, but I see on the syslog few following lines
Jun 30 16:40:21 Vault kernel: critical medium error, dev sda, sector 15589184 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 2
Also, this week the server once refused to recognize flash as boot device..
What should I do? Replace the flash drive? What is the procedure?
-
Hi
After upgrade to 6.12 network is running on 100 rather than 1000, noticed during backup..
Tried manually to change to 1000, used other network socket, did not help.
Other windows PC running on the same switch going well - 1000.
What could be wrong?
-
23 minutes ago, JorgeB said:
You just connect the disks to another computer, Unraid is mostly hardware agnostic, this might be a problem though:
If it's really a RAID controller disks might not work correctly on a different one, one of the reasons RAID controllers are not recommended.
Given there are no disk failure, I can connect the disks one by one right and copy its contents..?
Sijce current capacity of HD drives, I believe the new server will be much smaller
Re: Raid controller, that's Adaptec HBA SATA/SAS.. Sorry
-
Hi
is it quite straight forward to recover from simple disk failures and perform upgrades with unraid, and wiki exists.
My question is more about HW failure of the box itself. I have quite a monster server with 20 bays, raid controller, server motherboard and 64 GB RAM
However, today since most of movies and audio I stream from the Netflix and Spotify, I mostly use unRaid for home production and documents backup (I still have 36 TB of archive though)
Anyway, the question is what happens if I decide to scale down and move to a smaller box once the unraid server fails.
What do I with the disks?
I do have CrashPlan Pro for everything, but I never tried it for recovery, honestly I am thinking also to buy some external 18 TB HDD to backup the documents and the home works and keep it with the parents
thanks in advance,
Michael
-
Just now, gcolds said:
What is the drive standby issue?
-Greg
The bug is that the drive stays online, it should be switched off in idle after timeout
I rolled back to 6.9.1 as advised here on forum
-
Hello
Did you fix the drive standby issue?
-- Michael
-
1 minute ago, jonathanm said:
Sounds like you solved it.
hmm, it is part of the NerdTools, and seems like I enabled it, but I don't remember why 🙂
I think I was then tried to resolve that spin-up disk issue with 6.9.2
Would you suggest to disable it?
Or increase the RAM drive? but I don't know where do I define its size..
-
I found few files at /var/log/atop
-
tmpfs
-
it is /var/log which is limited to 100MB and it is full
-
Just now, ChatNoir said:
Your diagnostics will provide more information on what is filling your logs and possibly how to fix that.
Which logs? where are these located?
on bootable flash? there is nothing there
-
What is this thing?
All my drives including flash and SSD disk looks to me healthy with plenty of free space, what did I miss?
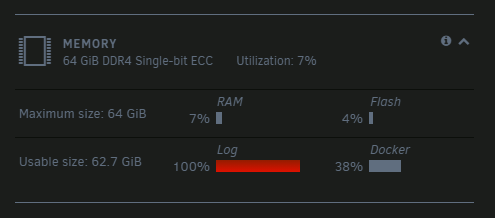
-
4 minutes ago, JorgeB said:
Try downgrading back to v6.9.1, there are some known spin down issues with 6.9.2
6.9.1 is working excellent!
Now I afraid to go with 6.9.10, did anyone take care of this (or these) bugs?
-
I started to get some errors on disk on top of the not spinning down, so I downgraded today to 6.9.1 and everything works perfectly again.
I wonder why there is no quickfix for this?
It is kind of breaking showstopper, isn't it?
Weird..
-
10 hours ago, superloopy1 said:
I 'fixed' mine by switching off SMB 'Enable WSD' settings temporarily. This prevents you from 'seeing' your server on the network whih may or may not be an issue for you. It was for me, i am used to dipping in and out of each individual disks contents on a windows pc. So, i re-enabled it and to date disks have spun down as expected. May be worth a go ...
I disabled it, but it didn't help.
I still see disks spun down, and then awake again.
What did you mean by 'I re-enabled it' above?
-
5 minutes ago, JorgeB said:
LT is already working on v6.10 which should be out soon™, don't expect any more v6.9 releases unless there's some serious data or security related issue found.
Hm.. I remember somebody said we should expect now more frequent releases,
-
15 minutes ago, JorgeB said:
There are some known issues with v6.9.2 and spin down, for now you can downgrade to v6.9.1, it should help.
Thanks, any ETA for the fix? Is it expected in 6.9.3?
-
On 4/23/2021 at 11:46 AM, superloopy1 said:
This is still a problem for me, drives permanently in an 'up' state ... diagnostics attached as requested.
Update .... my drive spindown is being interrupted by SMART reads to each disk every hour which spins them back up. What controls this timing? I'm assuming i dont need SMART checks every hour on the hour but cant find a setting to adjust anywhere???
I have same issue since 6.9.2
drives spun down, and then up.
the only thing I see is smart access by the GUI layer
-
3 minutes ago, JorgeB said:
See if downgrading to v6.9.1 helps, there are some known issues with v6.9.2 and spin down.
this makes more sense to me, but I will wait then for the next version.
Should I open a bug, or there is already an open one?
-
I don't think this is folder caching.
-- I disabled it, did not help
- re-enabled, and enabled logs -- don't see the cache task running
but I do see this again
Jun 1 14:32:52 Vault emhttpd: read SMART /dev/sdb
Jun 1 14:32:52 Vault emhttpd: read SMART /dev/sdc
Jun 1 14:33:24 Vault emhttpd: read SMART /dev/sdd
Jun 1 14:33:24 Vault emhttpd: read SMART /dev/sde
Jun 1 14:33:24 Vault emhttpd: read SMART /dev/sdf
Jun 1 14:33:35 Vault emhttpd: read SMART /dev/sdh
Jun 1 14:33:45 Vault emhttpd: read SMART /dev/sdjdisks are spinning down.. and then immediately spinning up.
what is emhttpd? the GUI? Why does it access SMART? Does it spin up the disk?
-
9 hours ago, Squid said:
dynamix.cache.dirs.plg - 2020.08.03There's something in the support thread about not having it scan user shares (only disk shares) to prevent disk spinups incurring.
Did not help:
Jun 1 08:54:50 Vault cache_dirs: Stopping cache_dirs process 10494
Jun 1 08:54:51 Vault cache_dirs: cache_dirs service rc.cachedirs: Stopped
Jun 1 08:59:32 Vault emhttpd: spinning down /dev/sdf
Jun 1 08:59:43 Vault emhttpd: spinning down /dev/sdh
Jun 1 08:59:54 Vault emhttpd: spinning down /dev/sdj
Jun 1 09:02:41 Vault emhttpd: read SMART /dev/sdf
Jun 1 09:02:52 Vault emhttpd: read SMART /dev/sdh
Jun 1 09:03:02 Vault emhttpd: read SMART /dev/sdj
Jun 1 09:21:31 Vault emhttpd: spinning down /dev/sdb
Jun 1 09:21:31 Vault emhttpd: spinning down /dev/sdc
Jun 1 09:21:53 Vault emhttpd: spinning down /dev/sdd
Jun 1 09:21:53 Vault emhttpd: spinning down /dev/sde
Jun 1 09:22:14 Vault emhttpd: spinning down /dev/sdg
Jun 1 09:22:22 Vault emhttpd: spinning down /dev/sdi
Jun 1 09:24:51 Vault emhttpd: read SMART /dev/sdb
Jun 1 09:24:51 Vault emhttpd: read SMART /dev/sdc
Jun 1 09:25:12 Vault emhttpd: read SMART /dev/sdd
Jun 1 09:25:12 Vault emhttpd: read SMART /dev/sde
Jun 1 09:25:21 Vault emhttpd: read SMART /dev/sdg
Jun 1 09:25:31 Vault emhttpd: read SMART /dev/sdi
Jun 1 09:32:32 Vault emhttpd: spinning down /dev/sdf
Jun 1 09:32:43 Vault emhttpd: spinning down /dev/sdh
Jun 1 09:32:54 Vault emhttpd: spinning down /dev/sdj
Jun 1 09:35:42 Vault emhttpd: read SMART /dev/sdf
Jun 1 09:35:52 Vault emhttpd: read SMART /dev/sdh
Jun 1 09:36:03 Vault emhttpd: read SMART /dev/sdjFor some reason, file activity does not work for me. When I click on 'start', the service stays in 'Stopped' status

(SOLVED) Network running on 100 MBit/sec
in General Support
Posted
I played with the cables, probably I had a bad connection 🤡
Sorry