

Meles Meles
-
Posts
54 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Meles Meles
-
-
diags attached
-
Hi All
I'm seeing a weird error in Docker Settings (6.11.5)
If the Docker service is stopped, but the array is still up then I get this error.
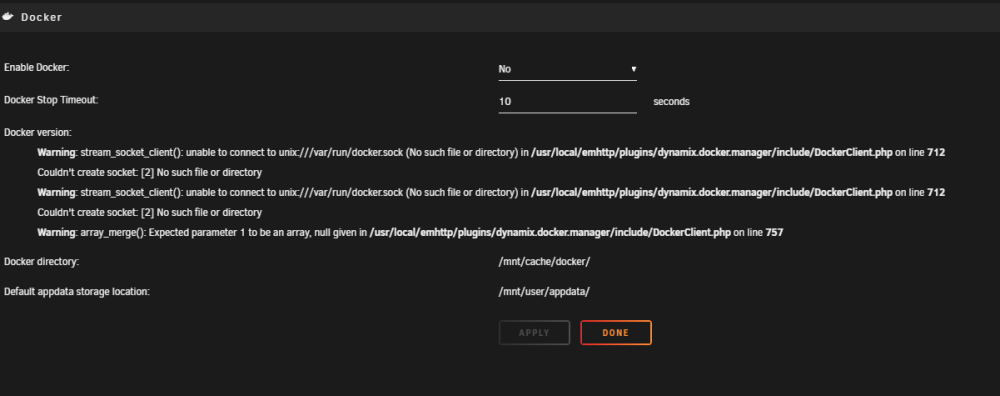
If I stop the array, then go back to docker settings, then all behaves fine..
Irritatingly, none of the other pages which need Docker to be stopped recognise it as being stopped while this error is in place. So i have to stop the array to change these settings (it's network this morning....)
I've checked the DockerClient.php file, and it's consistent with what was the current commit in GitHub as of the 6.11.5 release date, so I'm content that i've not borked anything at the UI level.
Any ideas on where to look next? Is there an extra unnecesary extra slash in "unix:///var/run/docker.sock" - and if so is that being retrieved from somewhere?
-
a bit of a necro-post, but I was having a play around with this earlier, and to get it working you just need to put
DOCKER_OPTS="-H tcp://0.0.0.0:2376 -H unix:///var/run/docker.sock"
into /boot/config/docker.cfg
of course, you then get the warning...
QuoteWARNING: API is accessible on http://0.0.0.0:2376 without encryption.
Access to the remote API is equivalent to root access on the host. Refer
to the 'Docker daemon attack surface' section in the documentation for
more information: https://docs.docker.com/go/attack-surface/And the Docker Start Stop page in the UI cracks the whoops a bit as well....
I'm actually now moving onto using a dockersocket proxy container instead (tecnativa/docker-socket-proxy)
-
3 hours ago, Sherk said:
Hello Everyone,
thanks for helping the community with great script.
however I have a small request, I have one docker container that always fail or crash for no reason,I tried to solve this issue by making a script that will start container every hour, some time it crash between that time and I lose container function so I need a script to monitor docker container and if it crash/stopped it will directly start again in anytime.
Thank you all in advance for your time and effort! -
Funny you should mention this, I actually *like* the fact that it tells me that it's Google Authenticator. Then I don't need to check my Microsoft one first!
😁
-
On 2/5/2022 at 8:11 PM, Bolagnaise said:
Can i ask why your using localhost:32400/identity and not localhost:32400/web/index.html as the website check. I get no response from that webpage when checking it using the curl command.
sorry, just noticed this!
No idea really... I just did, and it worked! My theory was that the /identify page returned less data so was less "work" for the server to do (for when 16 cores/32 threads isn't enough?)
-
On 1/15/2022 at 8:36 AM, Bolagnaise said:
I’m looking for a script that will restart my plex container using curl for those instances where it rarely goes down.
I run a docker container called "autoheal" (willfarrell/autoheal:1.2.0 is the version you want to use as the "latest" one is regenerated daily which is a PITA)
just give each container you want it to monitor a label of "autoheal=true"
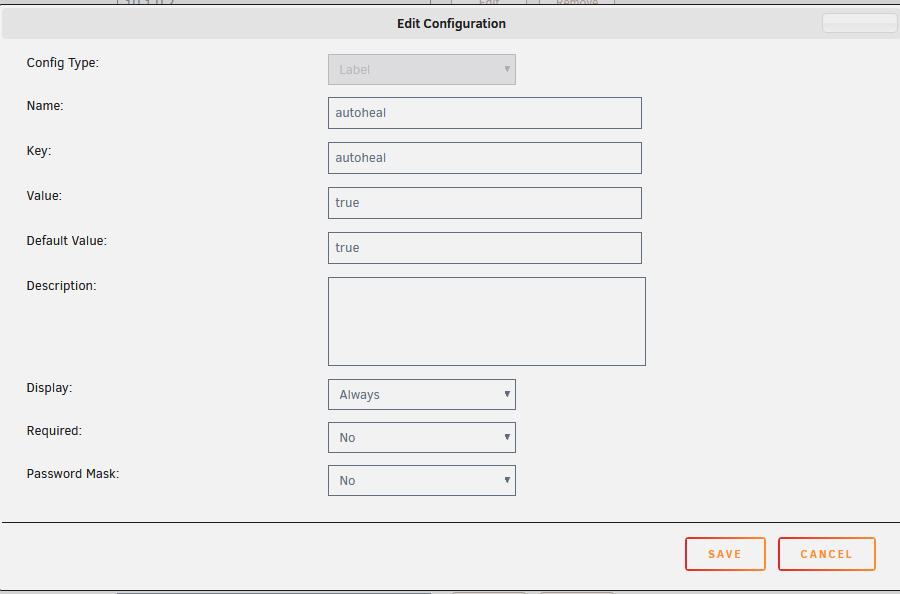
it also needs some sort of healthcheck command (if there's not one included in the image itself) - here's my plex one (goes in "extra parameters" on the advanced view
--health-cmd 'curl --connect-timeout 15 --silent --show-error --fail http://localhost:32400/identity'
*Remember - the port in this URL is the one from INSIDE the container, not where it's mapped to on the server *
you can do similar for most containers, although a trap for young players is that some of the images don't have curl, so you need to use wget (and alter parameters to suit)
I've attached my template for autoheal (from /boot/config/plugins/dockerMan/templates-user)
-
 1
1
-
-
It appears that running your browser using 2 seperate profiles is enough to fool it. I've got it working here with 2 instances of firefox
-
1 minute ago, Squid said:
However I also tried doing an install on Chrome, and then browsing around and doing something else with Firefox / Brave. And that worked perfectly. This *implies* that it's a browser issue somewhere along the line. Either way, this is a known issue
huh.... I'll give that a blast then....
-
I'm hoping it's just me, but the webUI doesn't seem to want to perform multiple tasks concurrently (in seperate tabs/browsers).
For instance, if i'm adding a docker container (doing the pull etc) in one tab - another window with something else in it will just hang (and eventually give me a timeout) when i try to refresh/navigate.
Is there some nginx setting I need to tweak, or is this by design?
-
On 1/22/2022 at 6:08 AM, Shaboobala said:
Thanks @Meles Meles I am trying to use the consld8 script and earlier in the thread it says to execute it by using this comand
if i were to bash would I put it before find? Sprry for my ignorance is its and obvious answer just trying to learn.
you'd put it just before consold8
find "/mnt/user/Media/Movies" -mindepth 1 -maxdepth 1 -type d -print0 | xargs -0 -n 1 bash consld8 -f -
On 1/12/2022 at 4:18 PM, itimpi said:
I suspect the instructions are no longer accurate as in the last few Unraid releases security has been tightened so that files on the flash drive are not allowed to have execute permission.
instead of using a link as suggested you need to copy the files elsewhere (such as /user/local/bin) and give them execute permission.
Or you can just "bash" them into submission.....
so instead of just doing
diskmv blah blah2(which will fail as no execute permission on diskmv)
do
bash diskmv blah blah2 -
On 1/7/2022 at 8:42 AM, mgutt said:
This happens because /root/.ssh is linked to the flash drive and the flash drive does not support hardlinks (as it uses FAT):
ls -lah | grep .ssh lrwxrwxrwx 1 root root 21 Apr 7 2021 .ssh -> /boot/config/ssh/root/
It is produced by OpenSSH and is patched in various projects:
https://github.com/termux/termux-packages/issues/2909
https://github.com/haikuports/haikuports/issues/6018
I don't know if it is patched in OpenSSH itself?! As Unraid 6.9.3 uses a relatively OpenSSH version, it does not seem so:
ssh -V OpenSSH_8.4p1, OpenSSL 1.1.1j 16 Feb 2021
One solution would be to remove the link and copy the file from the usb flash drive:
The downside of this solution is that any changes to /root/.ssh are not permanently saved in your unraid configuration and are lost on reboot. So you maybe should add an daily check as a script which copies the file back to your flash drive if the timestamp differs.
For posterity here's what i've done to fix it...
at the bottom of /boot/config/go i added
rm /root/.ssh cp -R /boot/config/ssh/root/ /root/.ssh
and then i've done a User Script (scheduled hourly) to sync the data back to the flash drive
rsync -au /root/.ssh/ /boot/config/ssh/root/
-
Because I am going unRAID -> unRAID via SSH i'm getting the issue with the "hostfile_replace_entries" error (notwithstanding the workaround you suggested above).
As such the setting of "last_backup" is not working properly (as the errors are coming out in the rsync listing.
# obtain last backup if last_backup=$(rsync --dry-run --recursive --itemize-changes --exclude="*/*/" --include="[0-9]*/" --exclude="*" "$dst_path/" "$empty_dir" 2>&1); then last_backup=$(echo "$last_backup" | grep -v Operation | grep -oP "[0-9_/]*" | sort -r | head -n1)
putting the "| grep -v Operation " in there cures this. Can you incorporate this into your next version please. Cheers!
-
Also...
i'm backing up from one unRAID server to another (via ssh), and for some reason I get errors pop up every time it makes a SSH connection.
Quotehostfile_replace_entries: link /root/.ssh/known_hosts to /root/.ssh/known_hosts.old: Operation not permitted
update_known_hosts: hostfile_replace_entries failed for /root/.ssh/known_hosts: Operation not permittedso that I can get rid of these in the (final) log files, i'm "sed"ding them out just before I move the log to the destination
# hostfile_replace_entries: link /root/.ssh/known_hosts to /root/.ssh/known_hosts.old: Operation not permitted # update_known_hosts: hostfile_replace_entries failed for /root/.ssh/known_hosts: Operation not permitted sed -i '/hostfile_replace_entries/d' "$log_file" sed -i '/update_known_hosts/d' "$log_file" # move log file to destination rsync --remove-source-files "$log_file" "$dst_path/$new_backup/" || rsync --remove-source-files "$log_file" "$dst_path/.$new_backup/"
could you either
a) pop this into your code
or
b) give me some sort of clue as to why the blazes i'm getting this message!
ta

-
I got myself moderately tangled up changing my parameters when copying over your latest version (user stupidity on my half), so do you fancy making these changes so that it can be config based (on a yaml file)
if you call the script with no parameters then it uses whatever values are hardcoded in the script. Otherwise it'll parse the YAML file you specify and use those values. It also allows you to more easily have multiple backup sets running in parallel with a single backup script
# ##################################### # Settings # ##################################### # rsync options which are used while creating the full and incremental backup rsync_options=( # --dry-run --archive # same as --recursive --links --perms --times --group --owner --devices --specials --human-readable # output numbers in a human-readable format --itemize-changes # output a change-summary for all updates --exclude="[Tt][Ee][Mm][Pp]/" # exclude dirs with the name "temp" or "Temp" or "TEMP" --exclude="[Tt][Mm][Pp]/" # exclude dirs with the name "tmp" or "Tmp" or "TMP" --exclude="[Cc][Aa][Cc][Hh][Ee]/" # exclude dirs with the name "Cache" or "cache" ) # set empty dir empty_dir="/tmp/${0//\//_}" if [ "${1}" == "" ]; then backupBase="[email protected]:/mnt/user/backup/beast" # backup source to destination backup_jobs=( # source # destination "/boot" "$backupBase/boot" "/mnt/user/scan" "$backupBase/scan" ) # keep backups of the last X days keep_days=14 # keep multiple backups of one day for X days keep_days_multiple=1 # keep backups of the last X months keep_months=12 # keep backups of the last X years keep_years=3 # keep the most recent X failed backups keep_fails=3 # notify if the backup was successful (1 = notify) notification_success=0 # notify if last backup is older than X days notification_backup_older_days=30 # create destination if it does not exist create_destination=1 # backup does not fail if files vanished during transfer https://linux.die.net/man/1/rsync#:~:text=vanished skip_error_vanished_source_files=1 # backup does not fail if source path returns "host is down". # This could happen if the source is a mounted SMB share, which is offline. skip_error_host_is_down=1 # backup does not fail if file transfers return "host is down" # This could happen if the source is a mounted SMB share, which went offline during transfer skip_error_host_went_down=1 # backup does not fail, if source path does not exist, which for example happens if the source is an unmounted SMB share skip_error_no_such_file_or_directory=1 # a backup fails if it contains less than X files backup_must_contain_files=2 # a backup fails if more than X % of the files couldn't be transfered because of "Permission denied" errors permission_error_treshold=20 else if ! [ -f yaml.sh ]; then wget https://raw.githubusercontent.com/jasperes/bash-yaml/master/script/yaml.sh fi if ! [ -f "${1}" ]; then echo "File \"${1}\" not found" exit 1 fi source yaml.sh create_variables "${1}" empty_dir+="." empty_dir+=$(basename "${1}") fimy YAML file
backup_jobs: -/boot [email protected]:/mnt/user/backup/beast/boot -/mnt/user/scan [email protected]:/mnt/user/backup/beast/scan keep: days: 14 days_multiple: 14 months: 12 years: 3 fails: 3 notification: # notify if the backup was successful (1 = notify) success: 0 # notify if last backup is older than X days backup_older_days: 30 # create destination if it does not exist create_destination: 1 # a backup fails if it contains less than X files backup_must_contain_files: 2 # a backup fails if more than X % of the files couldn't be transfered because of "Permission denied" errors permission_error_treshold: 20 skip_error: # backup does not fail if files vanished during transfer https://linux.die.net/man/1/rsync#:~:text=vanished vanished_source_files: 1 # backup does not fail, if source path does not exist, which for example happens if the source is an unmounted SMB share no_such_file_or_directory: 1 host: # backup does not fail if source path returns "host is down". # This could happen if the source is a mounted SMB share, which is offline. is_down: 1 # backup does not fail if file transfers return "host is down". # This could happen if the source is a mounted SMB share, which went offline during transfer went_down: 1
also
# make script race condition safe if [[ -d "${empty_dir}" ]] || ! mkdir "${empty_dir}"; then echo "Script is already running!" && exit 1; fi; trap 'rmdir "${empty_dir}"' EXIT;and obv remove the setting of "empty_dir" just above the loop
-
whilst i'm on a roll...
rsync cracks the poops if you ask it to create more than one folder deep at once (at least when operating via ssh), so i've made it work by putting the following in (just above "# obtain most recent backup")
if [[ $dst_path == *"@"*":"* ]]; then # this is a remote destination mkdirDir=$(cut -d ":" -f2 <<< $dst_path) sshDest=$(cut -d ":" -f1 <<< $dst_path) ssh $sshDest -f "mkdir -p '$mkdirDir' && exit" else mkdir -p $dst_path fi
-
Also...
surely the "shortening" of dst_path "if" statement needs an else (for when you're backing up somewhere other than "/mnt/..../" (i.e. /boot)
else dst_path="$backup_path${source_path}" -
Why does it add "Shares" into the destination path?
dst_path="$backup_path/Shares${source_path#'/mnt/user'}"
-
On 11/17/2021 at 6:20 PM, hernandito said:
Hi Meles.... in my case, my pool only contains "cache"... I have a single cache drive. What can I change on your script to reflect this?
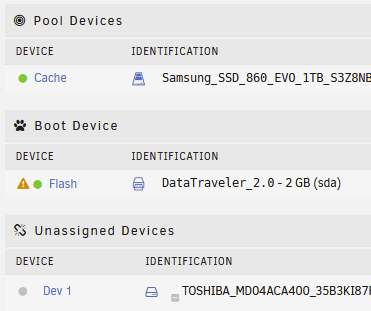
Thank you.
I think i've worked out what the issue you're having is...
I'm guessing that your array is encrypted?
Therefore your disks are named like this
/dev/mapper/md1 12T 119G 12T 1% /mnt/disk1 /dev/mapper/md2 12T 84G 12T 1% /mnt/disk2 /dev/mapper/md3 12T 84G 12T 1% /mnt/disk3
the script was originally written on my other unRAID server which doesn't have encrypted disks, therefore the disks are like this...
/dev/md1 12T 7.3T 4.8T 61% /mnt/disk1 /dev/md2 8.0T 5.2T 2.9T 64% /mnt/disk2 /dev/md3 8.0T 56G 8.0T 1% /mnt/disk3 /dev/md4 8.0T 5.5T 2.6T 68% /mnt/disk4 /dev/md5 12T 6.4T 5.7T 54% /mnt/disk5
the line in the script which does the "work out what disk has most space on" was just looking for /dev/md originally...
here's a modified version of the script (also tarted up somewhat)
move_it.sh Moves all non-hardlinked files from pool onto the array disk with the most free space Usage ----- move_it.sh -f SUBFOLDER [OPTIONS] Options -f, --folder= the name of the subfolder (of the share) (default '.') -s, --share= the name of the unRaid share (default 'data') -n,--nohup use nohup, runs the mv in a job -d,--dotfiles also move files which are named .blah (or in a folder named as such) --mvg use mvg rather than mv so a status bar can display for each file -h,--help,-? this usage
-
If the Media share uses a pool disk, then there should be a /mnt/myPOOL/Media folder which has the Movies folder in there.
-
-
50 minutes ago, wgstarks said:
What script did you run?
preclear_binhex.sh -A
-
Am doing something wrong - or is this behaving as desired?
I ran a preclear on a disk (it's a 12TB Ironwolf Pro which has just been "retired" from being my Parity drive).
60hrs later (!), it's all done. Excellent...
Tried to add the disk to the array, but it didn't appear in the dropdown. so i did a reboot.
Added to the array and started it up
*BUT* unraid is now running it's own clearing on the disk, so i've got about another 14 hrs to wait.
I thought this PreClear meant that the disk could just add straight into the array?




[Plugin] Mover Tuning
in Plugin Support
Posted · Edited by Meles Meles
Update...
I'm getting an error when mover is running (caused by dodgy data, but whatever...)
I have a folder in my cache which ends with a trailing space
"/mnt/cache/transcode/thumbs/Thumbs/2012-08-02 - "
the value is being written correctly into the list (/tmp/Mover/Mover_Tuning_2023-11-10T105025.list), but when it gets read back in (for the purpose of checking for hardlinks) the script is being helpful and trimming that space off the end for me..
mvlogger: Hard File Path: .."/mnt/cache/transcode/thumbs/Thumbs/2012-08-02 -"..
stat: cannot statx '/mnt/cache/transcode/thumbs/Thumbs/2012-08-02 -': No such file or directory
downstream it's also causing failures in here...
totalsizeFilelist() { #Loop throug the custom mover filelist and add up all the sizes for each entry. #echo "Grabbing total filesize" #start looping while read CUSTOMLINE; do #PULL out file size mvlogger "..$CUSTOMLINE.." CUSTOMLINESIZE=$(echo "$CUSTOMLINE" | sed -n 's/.*;\(.*\)/\1/p') mvlogger "Custom Size: ..${CUSTOMLINESIZE}.." ((TOTALCACHESIZE+=$CUSTOMLINESIZE)) done <$CUSTOM_MOVER_FILELIST }Changing all (9) occurances of
in /usr/local/emhttp/plugins/ca.mover.tuning/age_mover to
appears to fix this issue, but is this going to break anything else?