




XceRpt
Members
-
Joined
-
Last visited
Everything posted by XceRpt
-
Having issues with reverse proxy as well after i just updated dockers& plugins. Same " stream" message in my log.
-
I think i've went thru that before, but will double check. As of right now i restarted parity and it's at 84% and still going. I was just curious if there was anyway to tell why it happened but theres not much info in the log.
-
I've ran fine for 2months no issues. parity was due to start on 3/1 . Came home from work and everything is unresponsive . I cant see anything in the log to pinpoint the problem other than a correction then it was offline apparently until i rebooted at 19:36. I've had issues in the past of crashing only during parity check and changed ram speed in bios and thought issues were resolved. Any help appreciated. Thanks. syslog-192.168.0.229.log tower-diagnostics-20220301-1951.zip
-
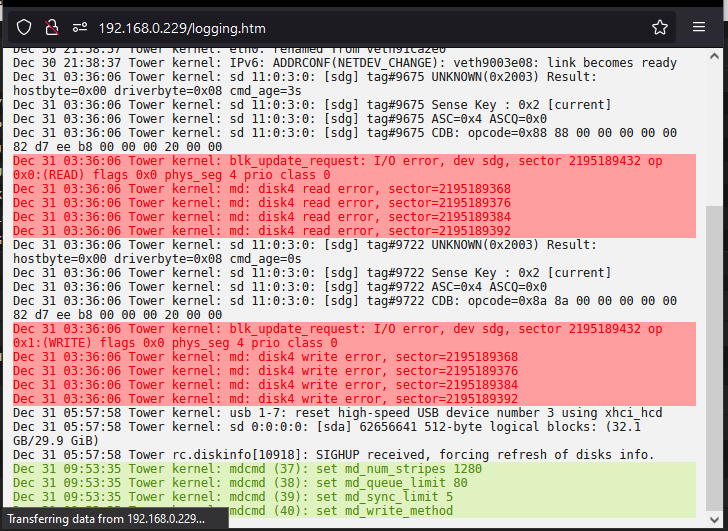
May be time to replace disk 4. I've rebuilt it twice and after each one it will last anywhere from a few days to a week then disables/ is emulated. Drive is only 3 months old but "shucked" I may be able to slip it back in case and return or just buy another if i have to. In the meantime running the extended smart test on drive 4 now
-
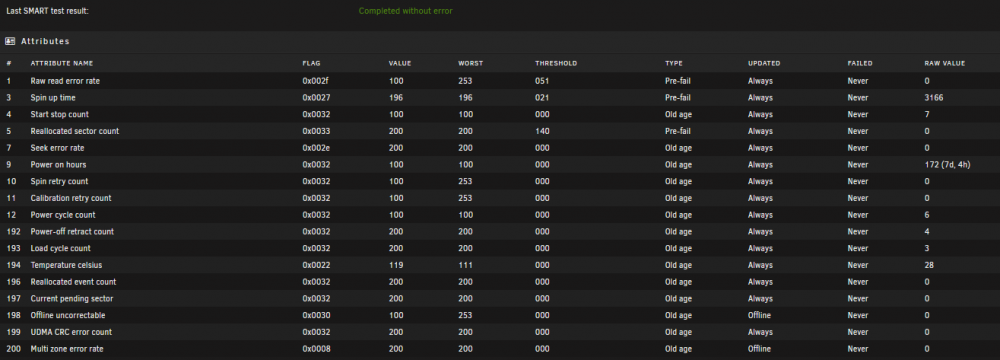
I have the disks set to never spin down. I dont see an option specifically for UA devices as far as spindown settings go. I don't see spindown being an issue as the drive/program was set to record 24/7 (cctv). I was actually reviewing footage this time when it just stopped. . I dont believe unraid would shut a disk down thats in use like that ? I've also just finished a smart extended self test, came back no errors. not sure if that helps pinpoint anything or not.
-
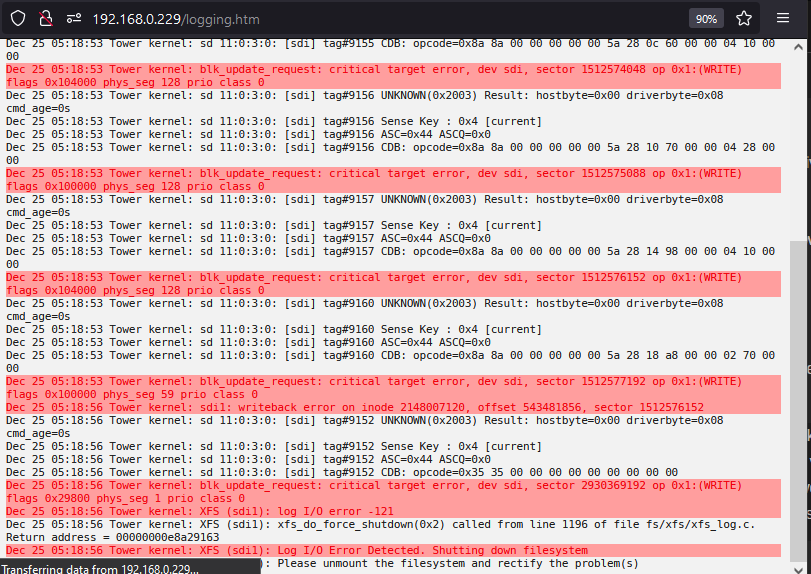
So I've double checked the connections are good and tight. Swapped to a new breakout cable rebooted. Drive comes back but seems to only last a few days before it just "disappears" and errors again, happened to be this morning. This a is new wd purple not an ssd as you mentioned you've had issues with before. I guess i need to get it back "online" and try to run some smart test maybe?/ Change to a diff hotswap bay? (not sure why that would matter). any other suggestions or ya think the drive could just be bad and run for a few days at a time? May end up trying to send back and see if its really just a faulty drive.

-
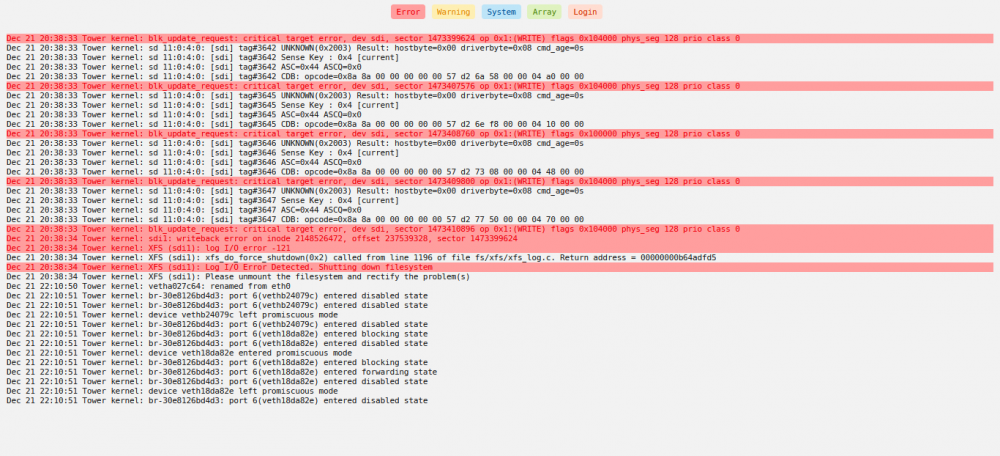
Well the drive lasted for a few days , now back to this. I may end up having to try a different hot swap bay just for heck of it. I'd just like to be able to rule out if it's the drive being bad (it's less than a week old) or if it's something else.

-
Unplugged sata and replugged. now showing for the time being (i've done this before as well) just didnt last long but i'll keep an eye on it and see what happens.
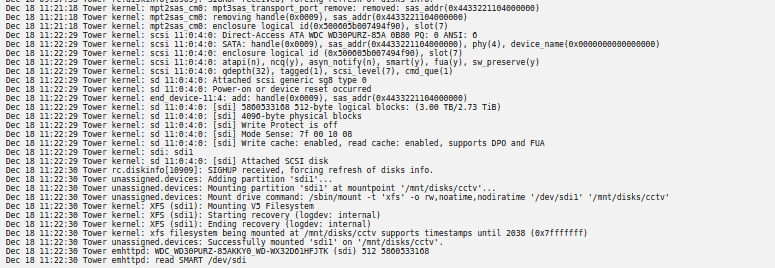

-
It's in a rosewill 12bay hotswap server case> It is connected to the lsi card using the sas to sata breakout cable Along with 3 of the other drives that are running fine. I was following a spaceinvader vid going through his steps of adding as an UA to use with shinobi. I'll dbl check the sata connection and if that don't work swap out the breakout cable that goes to the 4
-
Not sure what happened to be honest. i ended up canceling the process, sliding drives out and back into the server ( hotswap bays) and rebooted ran rebuild. finished with no errors.
-
running unraid 6.9.2, recently intalled a new wd purple in hopes of using for cctv footage. it keeps shutting down and showing in historical devices. Ive tried to attach my sys log showing the problem but i keep getting a server error 200 on the forum post here. Hopefully someone can point me in the right direction. Also note i havent recorded or even written to the drive yet. only formatted and mounted/ added to docker to be used
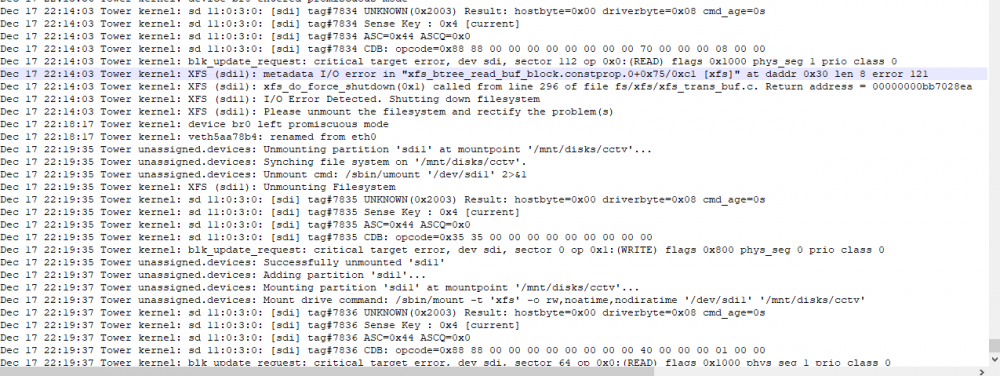
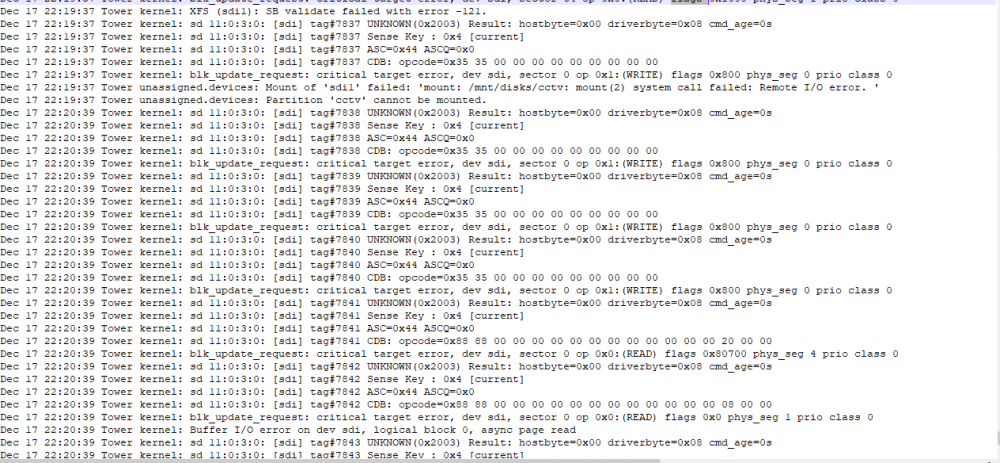
-
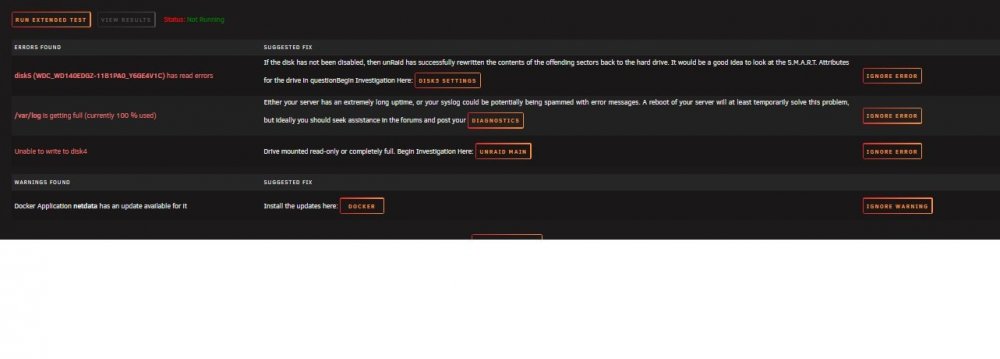
So I recently added a wd purple to unassigned devices to run with some cctv recently purchased . It added fine. Shortly after I started getting messages that disk 4 (in array) was disabled and emulated. And also noticed my wd purple is now under historical devices not unassigned. I thought I could stop array, unassign disk 4, start array, stop array re assign and start and let it rebuild. That didnt seem to work for me. i I now not only get that disk 4 is disabled but disk 5 is throwing tonsss and i mean tons of errors. I cannot access the log via webui. I had a syslog setup in one of my shares and i dont even see it anymore. Kinda lost on where to start. i've attached what i could think of . let me know if i can provide more. Thanks. tower-diagnostics-20211215-1925.zip tower-smart-20211215-1919.zip
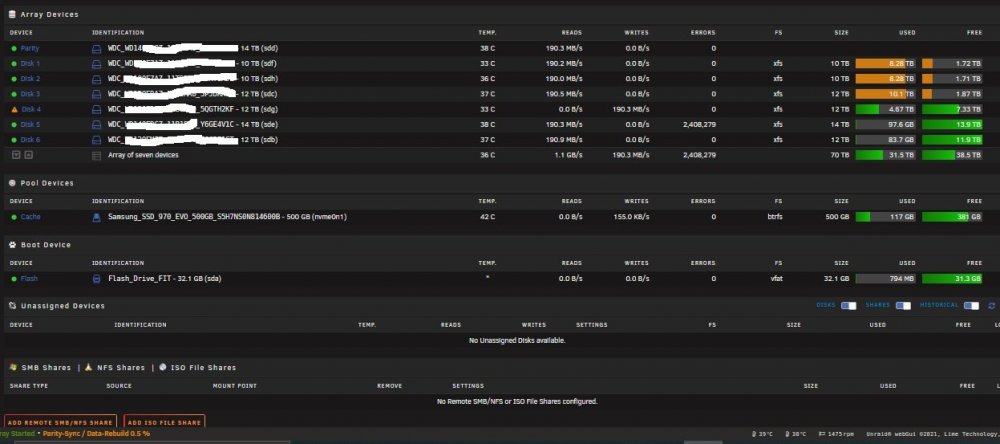
-
a long shot but always worth checking as far as random crashes are concerned. Dbl check your ram speed settings. I ran for nearly a year then suddenly started having crashes. changing the speed to the stock non oc speed of 2133 instead of 3200 stopped the crashes for me.
-
After removing 2 sticks my server crashed even faster than having 4 sticks, dont make lotta sense. I noticed before bios had my ram at 3200. i made sure to turn off the xmp? and not use any of the profiles in the bios. after i put the two removed sticks back in bios showed 2133. server hasnt crashed since. This thread can be closed if needed. Thanks for the insight on how the ram is advertised compared to what it's actual speeds are non oc.
-
update: I cant say 100% why it's not crashing anymore. I tinkered with bios settings etc. at first bios was showing ram at 3200 . i took a couple sticks out booted back up crashed even faster. i put all 4 back in then bios showed ram running at 2133 which was the true speed non oc speed. It's been fine every since so i'll go out on a limb and saying that was more likely the problem than not.
-
Appreciate the reply. I'm not trying to run anything overclocked just trying to narrow down whats causing the crashes. i've tried the c state things mentioned and typical idle etc. to no avail. i ran for 7 months or so on all 4 with no problems. I removed 2 and I'm trying those to see what happens.
-
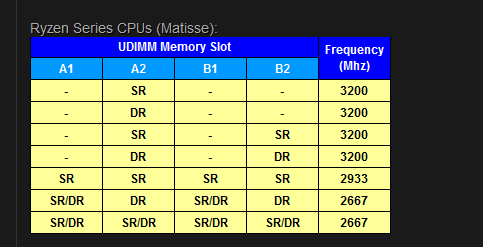
Just a question about RAM and understanding the correct settings. I have an ryzen 5 3600 with an ASrock b450 pro 4 I have 2 sets (4 sticks ) of VENGEANCE® LPX 16GB (2 x 8GB) DDR4 DRAM 3200MHz C16 Memory I dont see anywhere online if it's "single" or "dual" nor do i know much about ram in general. I've ran memtest to try and see whats "crashing" / "hanging" my system . After like 5 hours with no errors i stopped it. Here is a pic from my mobo's site. Is it okay to have 4 of these sticks filling all four slots without issues? ( it ran with all 4 for probably 7 months without issues)
-
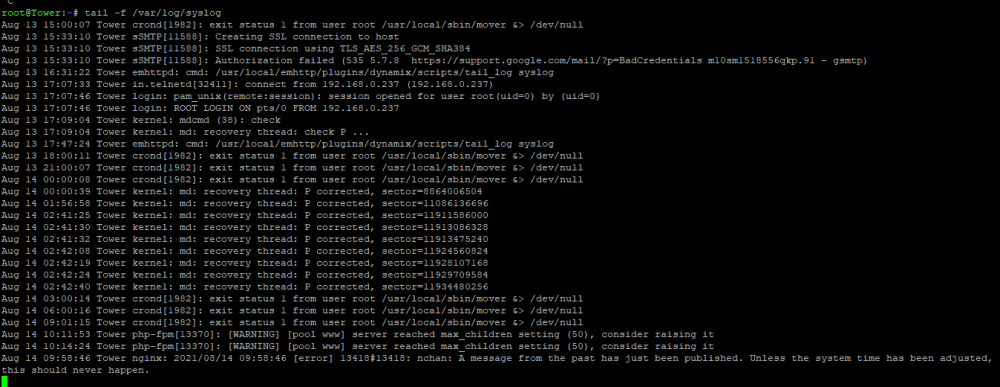
through putty i've tried tailing the log but still not seeing what's causing the issue/crash. Whats weird is right now it's like the parity is stuck but "most" the webui tabs are accessible though nothing works.
-
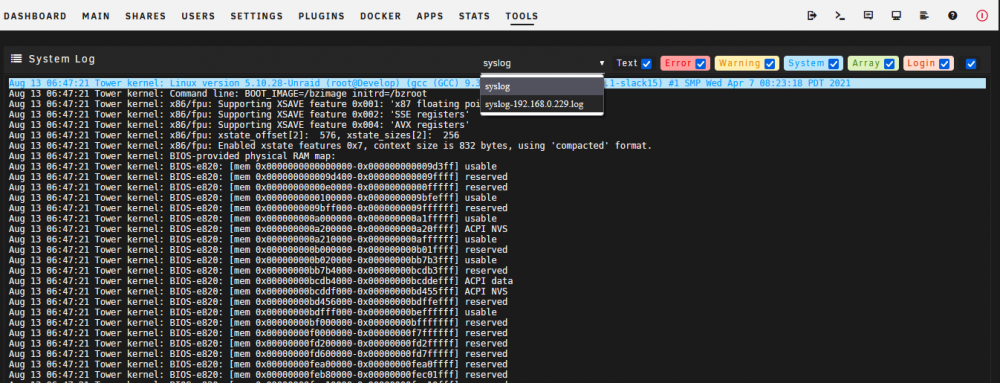
I may have things backwards I'm honestly pretty new at this. But theres also this "syslog' if thats the one you're referring to.
-
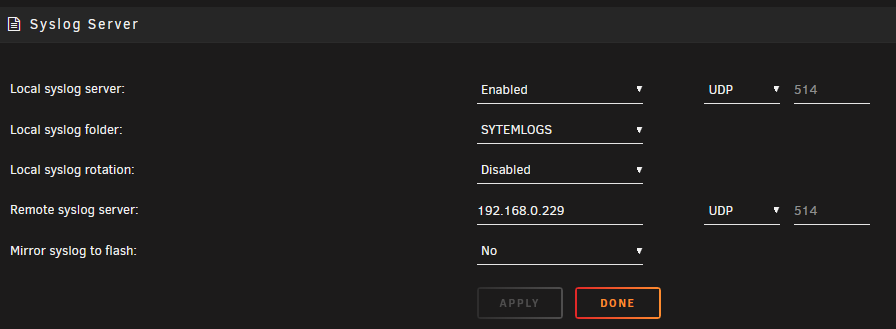
I'm a bit confused as the one i provided was from a share on the system thats crashing. That'd the log you would want in this case correct? taken from the troubleshooting page> Persistent Logs (Syslog server) Logging to file local to Unraid server Using a bit of trickery we can use the Unraid server with the problem as the Local syslog server.
-
For the past week or so Unraid becomes unresponsive only during parity checks. When i go to the server it still seems to have power to the server itself. The only way to get it to come back is to hard reset the server. I have updated bios to latest version (asrock b450 pro 4 bios v 5.0) I have updated unraid to 6.9.2 I have changed sas to sata cables and ran test again(failed) lsi 9207-8i i have hooked directly to motherboard sata ports (failed) I have seen mention of c-state issues. I have changed Power Supply Idle Current to Typical I'll try to be as specific as i can on what components are in system in case diag doesnt show everything. Rosewill 4U Server Chassis/Server Case/Rackmount Case, Metal Rack Mount Computer Case with 12 Hot Swap Bays & 5 Fans Pre-Installed (RSV-L4412) asrock b450 pro 4 ryzen 5 3600 CORSAIR - Vengeance LPX 16GB (4 x 8GB) 3.2 GHz DDR4 DRAM Model:CMK16GX4M2B3200C16 Samsung (MZ-V7E500BW) 970 EVO SSD 500GB - M.2 NVMe Interface Internal Solid State Drive with V-NAND Technology, 2x12tb drives 2x10tb drives LSI 9207-8i 6Gbs SAS PCI-E 3.0 HBA IT Mode For ZFS FreeNAS unRAID US Cooler Master MWE Gold 750 Watt Fully Modular, Compact, Silent Fan 80 PLUS Gold Power Supply, MPY-7501-AFAAG-US CyberPower CP1000AVRLCD Intelligent LCD UPS System, 1000VA/600W, 9 Outlets, AVR, Mini-Tower 1060 (6gb) gpu. No vm's Looking for any and all suggestions on where to possibly start. I also included the syslog(not sure if needed with diag) but it's the one i have mirrored to a share to try to find the culprit after reboots. From what i can tell from syslog it went down around the Aug 13th 6:02 area, I manually rebooted around the 6:50 time. Aug 13 06:02:29 Tower kernel: md: recovery thread: P corrected, sector=11929709584 Aug 13 06:50:14 Tower root: Delaying execution of fix common problems scan for 10 minutes Aug 13 06:50:14 Tower unassigned.devices: Mounting 'Auto Mount' Devices... Aug 13 06:50:14 Tower emhttpd: /usr/local/emhttp/plugins/user.scripts/backgroundScript.sh "/tmp/user.scripts/tmpScripts/nvidia.patch/script" >/dev/null 2>&1 Aug 13 06:50:14 Tower emhttpd: Starting services... Have not done memtest as of yet. Not sure if that could be an issue if it's only happening durity parity checks. tower-diagnostics-20210813-1533.zip syslog-192.168.0.229(1).log

















