Ulf Thomas Johansen
-
Posts
52 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Ulf Thomas Johansen
-
Help troubleshoot M.2 performance
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
Aha ... Makes sense. -
Help troubleshoot M.2 performance
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
A more structured test using a 128 GB file: I am not sure I follow your argument that the cpu is the bottle neck because when I run two pv's in parallell I am getting an average of 3 GiB/s throughput? Watching htop I can see that the system is hitting 4 GB/s in disk R/W pr pv job. Wouldn't this suggest something else is capping?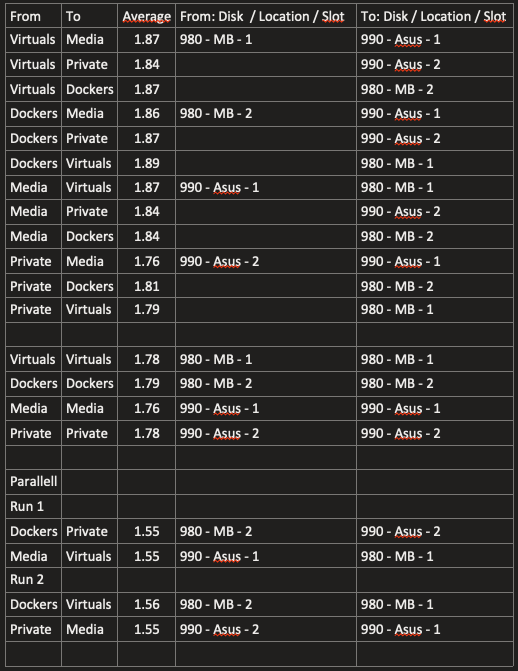
-
Help troubleshoot M.2 performance
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
Good point on rsync, and I've redone with pv as suggested. Giving the following observations: 1.79 GiB/s between the 990's (on the asus card) 1.19 GiB/s between the 980's (on the mb, one of which will be capped at gen3) 1.86 GiB/s from one 980 to one 990 Better then rsync, but I am not getting much more effect from the Asus and the 990's.


-
ZFS, Unbalanced and shares
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
Thanks, and a some what embarrassing question. I got my head arround understanding this -
Hi. I have a rig with multiple M.2's and I must admit I was expecting a better throughput than what I am seeing now. I have the following rig: ASRock X570 Pro4 Ryzen 5800X 64 GB ram (out of which 50% is allocated to zfs via zfs.conf override) Graphics in Slot 3 Asus Hyper M.2 x16 Gen 4 in slot 1 (bifurcated 4x4) 2 x Samsung 990 Pro (in slot 1 and 2 on Asus) Samsung 980 Pro (in slot 1 on mb) Samsung 980 Pro (in slot 2 on mb) Now the response I'm getting from the system is very good, but when I tested the rig just now I belive I should be seeing better speeds. The following screenshot shows the following rsync jobs: 980-Slot-1 to 990-Slot-1 980-Slot-1 to 990-Slot-2 980-Slot-1 to 980-Slot-2 When testing all combinations of copying between the M.2 the numbers are almost identical (to within 1%). The screenshot shows a test with disks formated with zfs-encrypted (with compression), but I have mirrored the tests using xfs with the same results. Are there any hardware limitations I'm hitting or is this the expected level? //Thomas
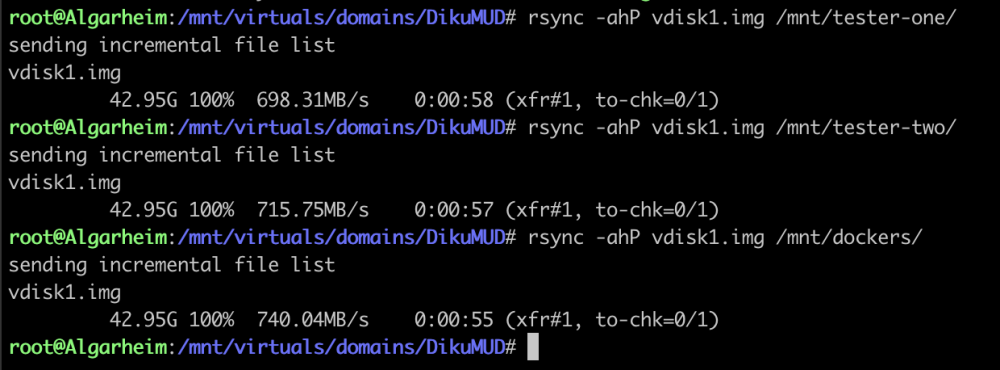
-
The keyfile present in /root is identical to the one stored on my desktop. Loading from /root/ it fails, but when given the file from my desktop it starts. I have copied the contents from my desktop file and echo'ed into the keyfile - still the same.
-
Hi people. I stumbled over Spaceinvader One's latest videos on ZFS last week and I have now switch to ZFS on both my cache pools and I have updated one of my array drives to ZFS. It all works soooo smoothly and with snapshotting it gets real easy to make blunders I do have one issue atm: I have created a raidz of two drives (for longterm keeping of photos and documents) and yesterday I ran Unbalanced on the Photos share and copied (or moved?) all my photos from the array to the new raidz pool. I have not yet converted this folder on the raidz to a dataset. I then switched the primary storage on the share to the new raidz location and no secondary - and now it seems I have files both on the array and in the new raidz pool. Is this correct? I want to ask before I do anything else because I have lost data in these situations before Can I delete the data in /mnt/user/Photos?
-
Sorry for necro'ing this, but I have this exact problem. Could you share your solution?
-
Two accounts of lock ups (diags included
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
Well that didn't take long: These are the last lines of the syslog: Dec 13 20:06:11 Algarheim emhttpd: spinning down /dev/sdi Dec 13 20:12:59 Algarheim kernel: docker0: port 1(vethd91a85e) entered disabled state Dec 13 20:12:59 Algarheim kernel: veth8207b51: renamed from eth0 Dec 13 20:12:59 Algarheim kernel: docker0: port 1(vethd91a85e) entered disabled state Dec 13 20:12:59 Algarheim kernel: device vethd91a85e left promiscuous mode Dec 13 20:12:59 Algarheim kernel: docker0: port 1(vethd91a85e) entered disabled state Dec 13 20:12:59 Algarheim kernel: docker0: port 1(vethee0e3aa) entered blocking state Dec 13 20:12:59 Algarheim kernel: docker0: port 1(vethee0e3aa) entered disabled state Dec 13 20:12:59 Algarheim kernel: device vethee0e3aa entered promiscuous mode Dec 13 20:12:59 Algarheim kernel: docker0: port 1(vethee0e3aa) entered blocking state Dec 13 20:12:59 Algarheim kernel: docker0: port 1(vethee0e3aa) entered forwarding state Dec 13 20:12:59 Algarheim kernel: eth0: renamed from veth52ba7c3 Dec 13 20:12:59 Algarheim kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethee0e3aa: link becomes ready -
Two accounts of lock ups (diags included
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
Thanks. -
Two accounts of lock ups (diags included
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
Thanks. I have changed the ssh config (some remnants of an old debug session I presume) - and will patiently await the next failure. Is there anyway to extend the log? -
Hi. System has been running stable for many months now, and over the last two weeks I've had two lock ups. As I am running headless I cannot see any core messages on the screen, but after last lock-up I mirrored syslog to the usb drive. I do fear a hardware issue and would appreciate any help in nailing it down. Regards //Thomas algarheim-diagnostics-20231213-1938.zip
-
Will you be implementing a feature that will update all images within a folder?
-
You were indeed correct. Rearranged one and the folders popped up! Thank you so much.
-
Thank you so much for picking up this project. I think many rely heavily on this plugin. I am running 6.12.3 and I have an issue when creating a new folder. This is what I've done: Remove old plugin Installed yours Created a new folder an added MariaDB to it When I refresh my Docker-page the folder is not visible (I have rebooted Unraid, cleared my cache and tried a different browser) If I try to create a new one MariaDB is not available to be added (as I assume it is already in a folder). Is there something on my system that is failing since I cannot see folders?
-
Lost my dockers and unable to reinstall
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
Recreated docker image. Could not install any image (same error on all), and yes - those were running. But - the issue has been found : I run a couple of docker images on two pi's and I have set them up as contexts. Last week I changed some settings on them and I forgot to reset the context to "default". Hence everything I was trying to do from the dashboard was executed on one of my pi's. Lessons learned to remember to reset context!!! -
Lost my dockers and unable to reinstall
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support

-
Lost my dockers and unable to reinstall
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
None of these images are showing in the dashboard, and "zwave-js-ui" was removed many months ago. There seem to be disconnect between the Unraid docker service and "some other" docker service.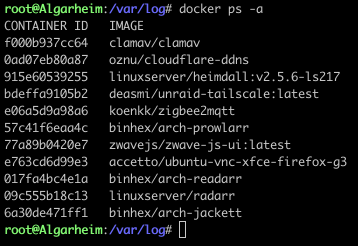
-
Lost my dockers and unable to reinstall
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
Executed docker stop on them all and recreated docker.img, then rebooted. Still getting "Error response from daemon: No such container" when installing a previous image. Please advise as I am unable to restore any of my services. -
Lost my dockers and unable to reinstall
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
Can someone explain how these can be running?
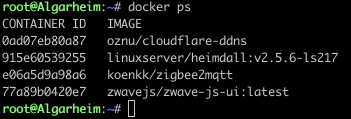
-
Lost my dockers and unable to reinstall
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
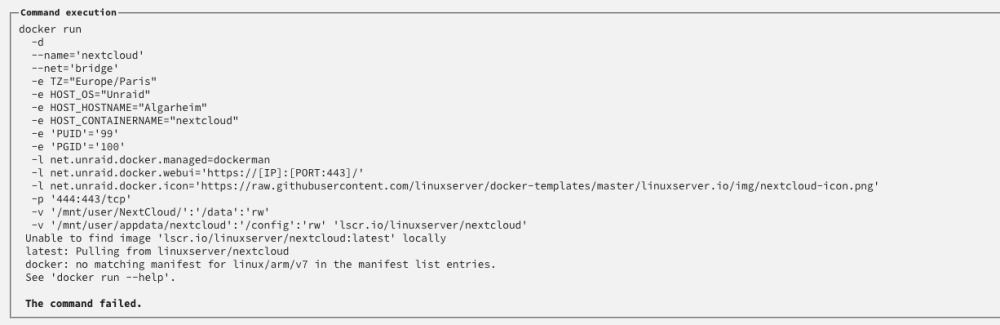
Deleted the docker.img, recreated it and when selecting just one app to be reinstalled (pihole) the first screen shows it downloading the image, and the text below it states "cannot find local image". Then this image pops up.
-
Lost my dockers and unable to reinstall
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
Good point, but no changes to the file since February and copies properly to other places, so no read errors. (Same for many of the other images also missing) -
Lost my dockers and unable to reinstall
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
Good. But how do we explain i.e. Tailscale image already running but not being present on the dashboard? -
Lost my dockers and unable to reinstall
Ulf Thomas Johansen replied to Ulf Thomas Johansen's topic in General Support
algarheim-diagnostics-20230601-1337.zip -
Woke up today and found that many of my dockers had been removed. When trying to reinstall I am getting the following error: No changes done on my side running 6.12.rc6 so any insights would be appreciated. This happens for multiple images. I am also seeing this error: