




randommonth
Members
-
Joined
-
Last visited
Everything posted by randommonth
-
Thanks for your response. That's odd as I have my Unmanic cache location set to my Unraid cache SSD, not RAM.

-
I mapped the cache location for the Frigate docker to a location on my SSD cache (per above suggestion), but I'm still getting out of memory errors. Could anyone inspect my diagnostics and gimme a hint as to what's going on? Thanks bigdaddy-diagnostics-20241213-1613.zip
-
Thanks - so all I have to do is just map a disk location to this setting? Do I have to change any other settings within the Frigate docker, such as those described at the following thread?
-
Thanks, I've reset the server but not sure on whether the Frigate container is writing to RAM. The "Cache to RAM" setting is set to "/tmp/frigate"
-
Hi guys, My server just started throwing the Out of Memory error through the Fix Common Problems plugin. Could somebody look at my diagnostics and suggest what might be the culprit? Thanks bigdaddy-diagnostics-20241119-1522.zip
-
Hi everyone, My binhex-plex docker instance is about 3 years old and has developed several glitches I've been unable to resolve. My Live Tv experience with Homerun HD frequently drops out, the DVR guide refuses to accept my paid guide xml and I cannot access the PMS logs. I've tried repairing the database but nothing has changed. I think I want to start my server over from scratch but i'm not sure how to do it and not totally clear on what I would lose. 1. What is the correct way to 'delete' my PMS docker and start from scratch? 2. What would I lose by doing this? - Watch histories? Can I reload them from Tautulli? - Collections? I assume they're linked to the Libraries wihch would be lost. - Connections to other users? Or is this linked to my username (Plexweb) - Server name? Can I reuse my old server name? If not, i assume I'll have to reshare new libraries with all friends - Friends' watch histories? Are they stored on my server or their clients? 3. Is there a smarter way of resetting a plex server without taking the nuclear option of starting from scratch? Thanks
-
Hi guys, I have Handbrake 1.8 Docker container. When I login to Handbrake's WebUI on my android phone I get a very limited experience in the browser. Finger presses move a cursor around the screen and I can't rotate or zoom in. Is there an Android app that can act as a go-between?
-
Hi everyone, this issue had popped up recently in that my Plex server appears to refuse to transcode. Many users and clients are reporting getting the 'Not enough CPU' error message or files just aren't working. I've got an Unraid server running an i7 8770 with 16 GB of RAM. PMS is the Binhex docker container. I have had hardware acceleration working perfectly for several years, until now. Server logs attached Thanks in advance. Plex Media Server Logs_2023-12-30_17-28-51.zip
-
Thanks @JorgeB
-
Hi guys, my server just logged an out of memory error... diagnostics attached. Thanks bigdaddy-diagnostics-20230924-0839.zip
-
Thanks again @JorgeB! It's taken me a few days to backup my cache but then when I performed the process this morning, I found the process didn't wipe my cache after all. I'll give it a few weeks to monitor for success before marking this as the solution.
-
Hi guys, I have had issues with cache drive stability in the past when I was running dual SSDs in a pool. I reduced the cache down to a single drive and have experienced excellent stability for the last 6-9 months. I could not pin point the root cause but I suspect some of the SATA ports on my motherboard are loose or faulty. I upgraded to 6.12.3 about a week ago and have seen consistent re-occurrence of the cache instability. Every morning I'm waking to find the cache has degraded somehow overnight, either completely disappearing or simply being unreadable. I have managed to resolve quickly each time by shutting down and rebooting, sometimes needing to stop the array and reassign the cache to pool. Each time the cache has reappeared and worked fine. Find diagnostics attached. Thanks bigdaddy-diagnostics-20230816-0641.zip
-
I followed the guide here without any issues. Didn't bother with the mover.
-
Thanks but I'm a bit confused now. I have two cache drives in a pool. I want to remove one. Is it as simple as stopping the array, removing the drive then restarting the array? Or do I have to go through the process of changing the cache preferences on applicable shares and running the mover?
-
Thanks. I'm fed up with this and I'm pretty sure the culprit is a dodgy SATA port on the MB. I can't afford to upgrade MB and CPU, so I'm just going to remove this drive from the pool. Can you advise the right way to remove the drive from the pool?
-
Thanks. Does it specify which drive has the bad link? I don't see any reference to SDB or SDD. All the cables are new too. Are the MB sata ports the only other potential source?
-
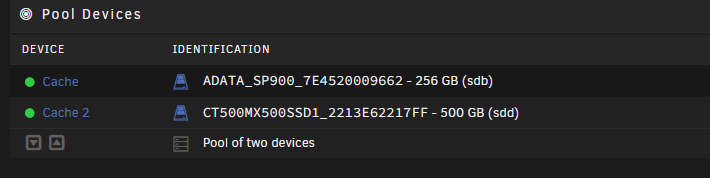
Hi guys, following on from months of errors in my cache pool, I recently nuked the pool and started over with some great help from @JorgeB. This morning my syslog was full and I found many errors coming from one of my cache drives (SDB1). I assume this is the 256 GB ADATA drive in my pool, see below. Before I go and replace this drive I just wanted to make absolutely certain this was the problematic drive in my pool? bigdaddy-diagnostics-20221124-1219.zip
-
Thanks again man!
-
Attached. Thanks. bigdaddy-diagnostics-20221114-0841.zip
-
Thanks again @JorgeB bigdaddy-diagnostics-20221113-2204.zip
-
Hi everyone, Over the last few months I've had numerous problems with my cache pool, with @JorgeB providing a lot of very helpful advice. A few weeks back I nuked the pool and started afresh, or at least I thought I had started with a clean new cache pool. The pool has performed flawlessly ever since then, however I've noticed that the second drive 'Cache 2' appears to have been on standby the entire time since starting over. The fact that the second drive being on standby coincides with the absence of all the earlier issues may be confirmation that the second drive was the source of all my earlier issues, however I want to know why it's on standby and if it can be fixed? What are the next steps I should take in root causing the problem?

-
Hi everyone, I was having the same problems with the same setup and found a solution that others may appreciate. With the change of the Organizr app name to organizrv2, the "set $upstream_app" line should have organizrv2 in it. I think the SWAG sample conf files need updating to reflect the change in app name.
-
Thanks but I got impatient yesterday and tried to recover the remaining drive using your guide here - When I mounted the remaining drive I saw that I wasn't going to be able to recover all the data, which confused me because I thought the data in a RAID 1 cache pool was mirrored? So I formatted the drive then recovered my Appdata and both drives appear to have come back online ok. Until this morning, when my Docker server appears to have failed. I took the attached diagnostics before rebooting. I'm getting sick of the abysmal reliability of my cache. My efforts yesterday were intended on removing the troublesome SSD but just caused more drama than I expected. How can I safely reduce my cache to a single drive so I can eliminate variable sources of issues? bigdaddy-diagnostics-20220924-0804.zip
-
Hi @JorgeB, I've got a two drive cache pool and just tried to remove the first of my cache drives following the guide in the FAQ and I'm seeing some strange behaviour. I stopped the array and unassigned the first cache drive, then restarted the array. I couldn't see any cache activity, but there was a notification that the cache had returned to normal operation. However, under Pool Devices it says "Unmountable: No File System", my Appdata folder is empty and none of my Dockers are there. I then tried to reallocate the first cache drive into the first slot, but the system warned me that all data would be removed from this drive if I started the array, so I chose not to. I then reallocated the second cache drive to first cache drive's slot and restarted the array, but I'm still getting the "Unmountable: no file system" error and when I click on the cache web gui, the Balance function is unavailable, saying it is only available when the array has started. Any help appreciated!! bigdaddy-diagnostics-20220923-1159.zip
-
That's interesting - my mover is scheduled to run each morning at 3:40 am and my cache usually fails one hour later at 4:40 am.



