




Doggeh
Members
-
Joined
-
Last visited
-
Hi folks, I've got a remote server that I administer and I have a script running on a raspberry pi at the same location which logs into the server using ssh every 5 mins and copies the array encryption keyfile over (if not already there) and starts the array (if not already started). This is a bit convoluted but it's been working fine. The remote location has quite a lot of power cuts hence the janky setup. The pi holds the keyfile on a ramdisk and fetches it from a different remote server on boot. For the last several weeks I don't seem to be able to start the array via the script, it just hangs at "starting services". This is the command in the script to start the array: ssh -i $ssh_key root@$server_adress 'emcmd cmdStart=Start' And this is the only weird thing I can see in the syslogs: Dec 17 16:30:04 TOWER kernel: emhttpd[9208]: segfault at 0 ip 000014d7971cc9c7 sp 000014d796a1ce78 error 4 in libc-2.37.so[14d79708a000+169000] likely on CPU 5 (core 6, socket 0) Dec 17 16:30:04 TOWER kernel: Code: 48 01 d0 c5 f8 77 c3 66 2e 0f 1f 84 00 00 00 00 00 66 90 c4 41 01 ef ff 89 f8 09 f0 c1 e0 14 3d 00 00 00 f8 0f 87 29 03 00 00 <c5> fe 6f 07 c5 fd 74 0e c5 > The array starts aboslutely fine if I port forward to the web interface via the raspberry pi and start it using the gui. The server is very minimal with a simple array and 3 docker images. Any ideas? Cheers!
-
Ugh that's a pain. The only other thing I can think of is that i think it was working fine until I did a bit of maintennance and moved the rack (the timeline is a bit blurry in this point). As part of that process I'm pretty sure I plugged the disk shelf into my UPS whereas previously it was just plugged into the wall. I'm not having power outages or anything like that so it's probably still just the cable though I do wonder if the UPS isn't quite handling a power surge (or something like that). Probably still just the cable. Maybe I'll plug the disk shelf directly back into the mains for a week and see if that fixes it before ordering a new QSPF to miniSAS cable. Thanks for taking a look.
-
Right, it happened again this afternoon. Diagnostics attached. Would greatly appreciate any help or insights. Thanks! zeus-diagnostics-20221129-1643.zip I believe the problem occurred at "Nov 29 15:07:22"
-
The problem hasn't happened for a few days now and I've done a couple of OS updates since then. Is it still useful to attach the diagnostics now or wait for the problem to happen again and then grab them before rebooting? The syslog file in this current diagnostic dump doesn't look like it goes back far enough to be useful. Thanks.
-
Hi folks, I'm running a NetApp DS4246 disk shelf, currently with 14 drives installed. This is connected to my server by means of a Broadcom / LSI SAS2308 PCI-E controller. The drives are all mounted as Unassigned Devices outside of the array. This was all working fine until the last couple of months where, roughly once a week, I'd log in and find that the drives are missing, sort of... They all say "Reboot" next to them and I can't find any information as to what this means or why it is happening. They are inaccessible in this state. Once I reboot everything is fine again. See the screenshot attached. My hypothesis is that the server is losing connection to the disk shelf for some reason but nothing seems to be obviously faulty and the server logs don't highlight anything that I can see. Has anyone experienced anything like this? Thanks.
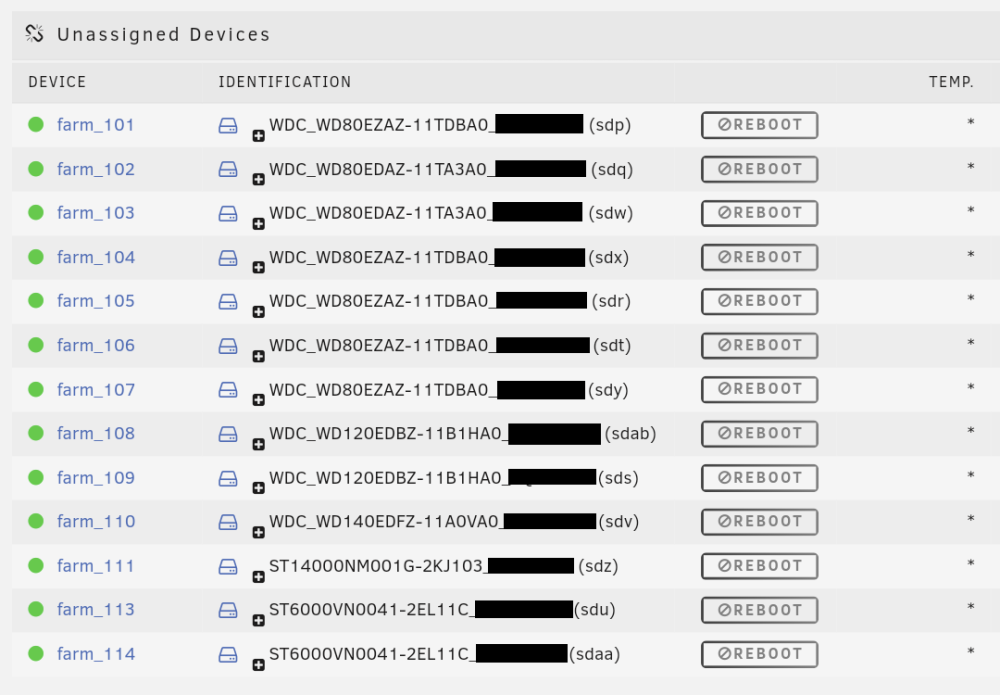
-
I've noticed since I started getting this error that my docker management is incredibly slow (the containers themselves seem fine though). It takes ages to check for updates and downloading new images takes absolutely forever... Do you think this could be related? EDIT - okay ignore this, it looks like I've also got some cache disk btrfs corruption to deal with 🤦♂️
-
Ah excellent, thanks. I'm glad it's not just my system
-
Hey folks, I've just started getting the following error showing in my syslog (and at the very bottom of the web gui). As far as I can tell everything still seems to be working correctly, including the GUI, the array, shares, docker, etc. Sep 13 16:07:12 Olympus emhttpd: <script>if (typeof _ != 'function') function _(t) {return t;}</script> Sep 13 16:07:12 Olympus emhttpd: Fatal error: Cannot redeclare _() (previously declared in /usr/local/emhttp/plugins/parity.check.tuning/Legacy.php:6) in /usr/local/emhttp/plugins/dynamix/include/Translations.php on line 19 I've rebooted a few times and it keep happening... I'm not aware that I've made any configuration changes that might have caused this. I don't think I've installed any new plugins or anything recently. I'm running Unraid 6.9.2 from a 32gb DTSE9 USB drive as recommended. Please let me know if you need any more details. Would really appreciate your thoughts. Thanks!
