

SnickySnacks
-
Posts
105 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by SnickySnacks
-
If anyone was interesting and didn't already know this, I was wondering how they calculated the failure rate (since 5 drive failures out of 400 is obviously not 30%). Those are the annualized failure rates and are calculated this way: (Failures / DriveCount) /( (DriveDays / DriveCount) / 365) Or simplified: (Failures * 365) / DriveDays The more you know.
-
Some of the settings don't look right. Specifically "MINTIMEL" and " MAXTIME " should both be 0 in your screenshot, I think? That's possibly what is tripping the shutdown, since as soon as your UPS goes on battery, it will fail the MINTIMEL check and shut down. Also is the BATTDATE listed there correct? The battery is from 2004? or have you replaced it more recently then that? Can you telnet to your server and check what the output from cat /boot/config/plugins/dynamix.apcupsd/dynamix.apcupsd.cfg is?
-
[SOLVED] Copying Files/Folder from Disk to Disk
SnickySnacks replied to bombz's topic in General Support
cp -r /mnt/disk10/BLURAY/[-MOVIES-]/Bond.50.Box.Set.BluRay /mnt/disk3/[-BLURAY-]/Bond.50.Box.Set.BluRay -
[Solved] Unable to start array with a Parity-Check
SnickySnacks replied to Muff's topic in General Support
If the problem is with Intel VT-D, I'd be concerned about keeping it enabled as it may cause other issues later. The fact that the issue appeared during the rebuild doesn't mean that it's gone away now, just that whatever you're doing now isn't triggering it. At the very least, I'd keep it in mind if you run into similar issues down the line as it will likely be the culprit. -
Time Machine over SMB (Mac OS Sierra)
SnickySnacks replied to barakthecat's topic in Feature Requests
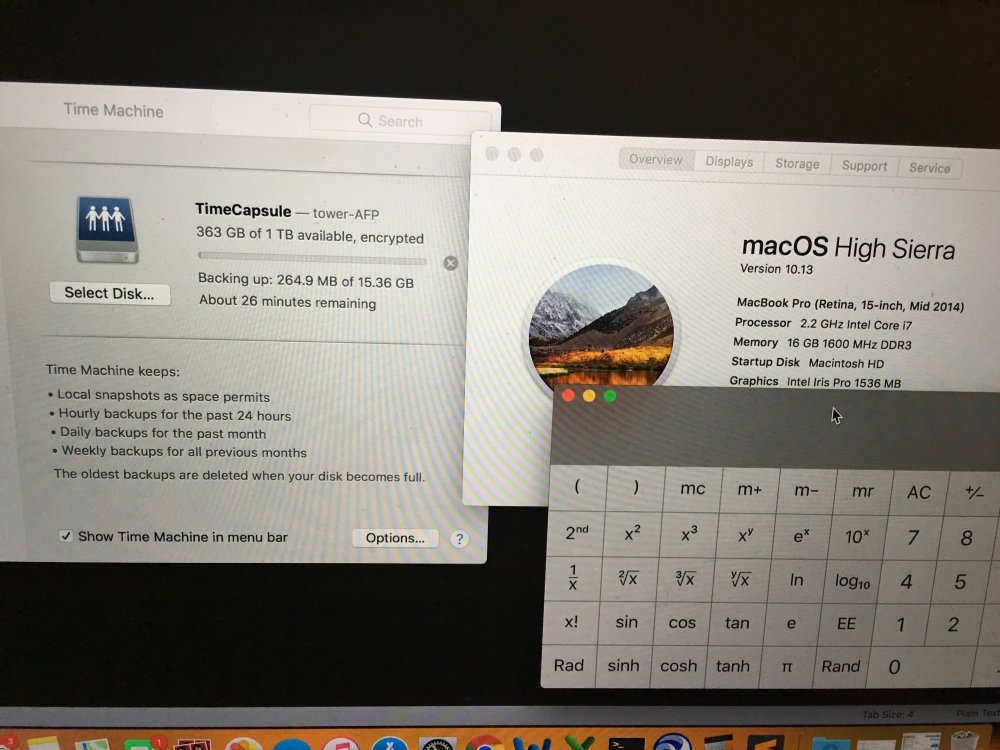
I'm not sure. People online say that APFS target time machine disks will be converted to HFS because APFS can't be a Time Machine target. I did a quick test this morning and it seemed to work APFS -> Unraid but I didn't let it actually do the backup. The more I read today, the more worried I became that I was wrong so I took my work laptop back home and tried again. I can confirm that this *does* work. I suspect the restriction is backing up TO something running High Sierra requires SMB, but honestly I'm losing interest in verifying this.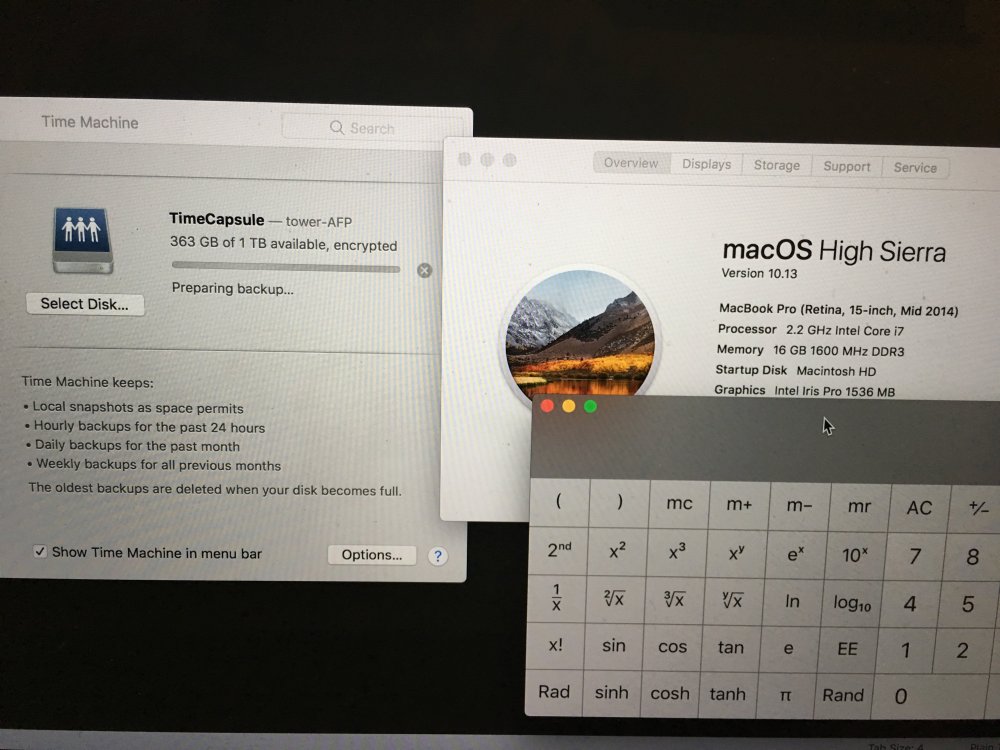
-
[Solved] Unable to start array with a Parity-Check
SnickySnacks replied to Muff's topic in General Support
Obvious question: Have you tried DISabling "Intel VT-D Tech"? -
Time Machine over SMB (Mac OS Sierra)
SnickySnacks replied to barakthecat's topic in Feature Requests
From what I see after upgrading to High Sierra, time machine backups *to* an APFS disk are not possible over AFP. However, I don't believe this affects backing up an APFS disk to Unraid (or other non-APFS disk). See here: https://support.apple.com/en-gb/HT208018 "Volumes formatted as APFS can't offer share points over the network using AFP. " "Any Time Machine share points must be shared over SMB instead of AFP." So the limitation isn't the source disk you are backing up, but rather the target disk you are backing up to. As far as I can tell, there's no issue continuing to use my existing Unraid backup target. -
How much RAM do you have installed in your unRAID server?
SnickySnacks replied to harmser's topic in Unraid Polls
It is being excluded but I still have problems. Part of it may just be cache_dirs itself. I mentioned a possibly related issue in the cache_dirs thread but never got a reply. -
How much RAM do you have installed in your unRAID server?
SnickySnacks replied to harmser's topic in Unraid Polls
I had 4GB but I've been running into some spinup issues that I think are due to cache pressure so I expanded to 16GB. 26TB, dual parity, not running VMs or dockers. But I *do* have a time machine backup which makes approximately 3 billion tiny files. -
It doesn't seem to be related to file access or time machine. It happened again when I haven't used time machine in weeks. Looks like it may be stuck waiting for a timeout or something. I'm not really sure. root@tower:/usr/local/emhttp/plugins/dynamix.cache.dirs/scripts# lsof | grep cache_dir cache_dir 19058 root cwd DIR 0,2 220 7660 /usr/local/emhttp cache_dir 19058 root rtd DIR 0,2 400 2 / cache_dir 19058 root txt REG 0,2 1094752 3371 /bin/bash cache_dir 19058 root mem REG 0,2 174816 4468 /lib64/ld-2.24.so cache_dir 19058 root mem REG 0,2 18436 4425 /lib64/libtermcap.so.2.0.8 cache_dir 19058 root mem REG 0,2 18808 4480 /lib64/libdl-2.24.so cache_dir 19058 root mem REG 0,2 2067512 4474 /lib64/libc-2.24.so cache_dir 19058 root 0r FIFO 0,8 0t0 105856711 pipe cache_dir 19058 root 1w CHR 1,3 0t0 2051 /dev/null cache_dir 19058 root 2w CHR 1,3 0t0 2051 /dev/null cache_dir 19058 root 10r CHR 1,3 0t0 2051 /dev/null cache_dir 19058 root 63r FIFO 0,8 0t0 105856711 pipe root@tower:/usr/local/emhttp/plugins/dynamix.cache.dirs/scripts# lsof | grep find root@tower:/usr/local/emhttp/plugins/dynamix.cache.dirs/scripts# pstree -pl 19058 cache_dirs(19058)───timeout(6371) root@tower:/usr/local/emhttp/plugins/dynamix.cache.dirs/scripts# ps awx | grep timeout 6371 ? Z 0:00 [timeout] <defunct> 9118 pts/0 S+ 0:00 grep timeout
-
I've been having an issue since the 6.x release series where cache_dirs will report 100% CPU usage after I use my time machine share (via AFP). This share is explicitly excluded from cache_dirs since it contains a billion little files. cache_dirs sits at 100% in top and uses one full cpu core 3241 root 20 0 10244 2824 2100 R 100.0 0.1 80291:02 cache_dirs the disks are not spinning up, as far as I can tell. lsof doesn't report what it's actually doing (it's apparently not disk accesses as the numbers don't increase. Edit: Duh. Should have been looking for the "find" process, but still...): cache_dir 3241 root cwd DIR 0,2 400 2 / cache_dir 3241 root rtd DIR 0,2 400 2 / cache_dir 3241 root txt REG 0,2 1094752 3371 /bin/bash cache_dir 3241 root mem REG 0,2 174816 4468 /lib64/ld-2.24.so cache_dir 3241 root mem REG 0,2 18436 4425 /lib64/libtermcap.so.2.0.8 cache_dir 3241 root mem REG 0,2 18808 4480 /lib64/libdl-2.24.so cache_dir 3241 root mem REG 0,2 2067512 4474 /lib64/libc-2.24.so cache_dir 3241 root 0r CHR 1,3 0t0 2051 /dev/null cache_dir 3241 root 1w CHR 1,3 0t0 2051 /dev/null cache_dir 3241 root 2w CHR 1,3 0t0 2051 /dev/null cache_dir 3241 root 6r REG 0,2 2727 8292 /usr/local/emhttp/update.htm I thought it may be related to internal linux file caching of the files on the AFP share, but if there was an issue with cache_dirs needing to recache drives, I'd think it would show disk accesses/spin up the disks. restarting cache_dirs seems to fix it, but any idea how to debug what causes it so I don't need to manually do this every time? I've attached diagnostics, any ideas? tower-diagnostics-20170811-0212.zip
-
I'd be surprised if he wasn't running the whole server off the M1015+expander since that will cover the whole set of 24 slots on the norco. Aside from the obvious "post your diagnostics", is your old server also running an M1015? Is the firmware the same? Are they both flashed to IT?
-
I haven't tried this as we back up to the CrashPlan servers, but... For the backup, I might suggest that using the CrashPlan docker is probably the easiest since you should be able to have the clients just backup directly to your server and it should function the same as backing up to the CrashPlan servers, except free. The backups are still encrypted and all that on the NAS. https://support.code42.com/CrashPlan/4/Backup/Backing_Up_To_Another_Computer_You_Own They don't mention it, but presumably you'd want to go to Settings –> General –> Configure, and switch the Default backup archive location to something that makes sense for your array.
-
Save a couple steps and just do a parity swap? https://lime-technology.com/wiki/index.php/The_parity_swap_procedure I've never tried it before, but it's basically what you're trying to do.
-
Take this with a grain of salt, as I don't have any first hand knowledge on the subject. But my understanding is that flash memory itself doesn't degrade over time, only based on writes and unraid very rarely writes to the usb drive so the flash should last quite a while, barring physical/electrical damage to the drive or filesystem corruption caused by power outages and such. As jonathanm says, now that we have automatic key replacements as long as you have your config backed up there's no real harm in using the drive until it dies.
-
Can you: a) Check if there is a difference in the paths to the files on Disk 6 vs Disk 20 (/mnt/disk6/Multimedia/Audio vs /mnt/disk20/Multimedia/Audio)? b) See if there is some other common connection on the files that are visible (in the partial screenshot, it looks like the folders on Drive 3 and 6 are visible, but not 8, 16, 18, and 20. Does this hold true for the rest of the files?)
-
To expand on what kizer said: Unraid, being that it is not raid, does not have any interdependence between your data drives. Thus if you have some number of data drives (let's say 10) and 1 or 2 parity drives, when you write data the system will (generally) spin up the drive being written to and the 1 or 2 parity drives. When you read data, the system will only spin up the one drive being accessed. Depending on your usage pattern, this could mean that the whole system spends most of its time with all drives spun down and, even when being used, with only 1-3 drives spun up. (again, depending on what you are actually doing with the system, dockers and VMS, etc)
-
Probably, but who needs the headache? Better to use a solution that prevents the problem in the first place.
-
The one problem with setting the IP static locally (without using the router) is that the router may try to assign the address via DHCP to another computer and you end up with two devices with the same IP. I believe this might happen if non-static computer A came up, got the IP address, then static computer B came up and tried to use the same address. Option 1: Set the static IP to an address outside the pool of addresses the router uses Option 2: Set the static IP on the router Personally, I tend to prefer option 2, since it lets me keep track of all my static IP devices from one location (the router) rather than needing to keep track of what has been assigned where, externally. Of course, if your router has a pool that starts at like 192.168.1.1, setting unraid to .250 or something is usually pretty safe as it would be rare for enough clients to be on the network to request that high.
-
Can you go from a JBOD to Parity-Protected Array
SnickySnacks replied to needslipo's topic in General Support
Yes, this is possible. Unraid, since it is not a conventional raid, has no inter-dependency between drives for the data so one drive failing/being upgraded/added does not affect the other data drives. However, keep in mind that unraid does not recognize NTFS formatted disks, so you will need at least one empty drive to format into one of the 3 formats unraid uses (RFS, XFS, BTRFS) to copy at least one drive's worth of data to, then format the empty NTFS disk and copy the next one, etc. Once all the drives have been added to the array in an unraid-readable format, you're pretty much set after that. -
Not sure you can take that at face value. I definitely have an older 4224, but mine are labeled "01 12Gb V2.0" (but dated 2013 26). Yours look like 2015 47 maybe? Reading on the 'net it looks like there were the older V1.0 backplanes that had 2 molex connectors, then the V2.0 12Gb with single connectors, then they went back to V1.0 with single connectors? My original thread about this: https://lime-technology.com/forum/index.php?topic=29274.0
-
[6.3.0] Shares no longer responding SMBD pegged at 100% in top
SnickySnacks replied to mrdally204's topic in General Support
My main concern about migrating off of ReiserFS is that, traditionally, when people have had filesystem issues the response on the forums has been that ReiserFS's recovery tools were better than say XFS's recovery tools. It's anecdotal, but.... http://lime-technology.com/forum/index.php?topic=55845.msg533055#msg533055 http://lime-technology.com/forum/index.php?topic=53553.msg514049#msg514049 http://lime-technology.com/forum/index.php?topic=49774.msg477405#msg477405 Sure it's been mentionioned that as of 6.2 xfs_repair is a lot better, but many of us have a lot of inertia and hate to take the chance with changing something that's always worked. -
unRAID OS version 6.3.0 Stable Release Available
SnickySnacks replied to limetech's topic in Announcements
I'm sure this isn't, as a rule, true. When I was doing my original testing on the ntlm issue, I did verify that my Windows 10 machine could access the private shares on my unraid machine without the modified samba config (even when my DuneHD could not). NTLMv2 is really old (2001-ish) so it's unlikely that there's some blanket problem with it. It was suggested that the Windows 10 issue may be a result of people fiddling with the samba settings on win 10 due to an older unraid issue that was causing authentication failures. (specifically, there was some old advice that suggested disabling SMB2 and SMB3 which will end up defaulting you to NTLM authentication) See posts such as: http://lime-technology.com/forum/index.php?topic=45778.msg437288#msg437288 http://lime-technology.com/forum/index.php?topic=44118.msg434525#msg434525 http://lime-technology.com/forum/index.php?topic=48820.msg468322#msg468322 At this point, though, the only way to really check would be to have someone with the Win10 issue turn up the samba logging and see why it's failing on 6.3.0. I suspect that the answer will be that they have NTLMv2 turned off as above, rather than some incompatibility. -
upgraded to 6.3 now can't access private shares ?!? HELP!
SnickySnacks replied to craigr's topic in General Support
Feel free to enable the syslog/log level settings and see what the syslog says about why your connection is failing. It may give some insight. -
unRAID OS version 6.3.0 Stable Release Available
SnickySnacks replied to limetech's topic in Announcements
Note that you only need the ntlm auth=yes line. the log level and syslog lines are only useful for debugging


