

DoeBoye
-
Posts
1223 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by DoeBoye
-
-
On 2/16/2024 at 6:52 AM, Yivey_unraid said:
Has this release fixed the issues 6.12.6 had with Adaptec HBA cards? I’m still on 6.12.4 because of it.
I can confirm 6.12.8 no longer has the issue. I had to roll back 6.12.6 for the same reason, but this one looks good. I ended up having to do a full reboot because I was getting a bunch of nginx errors after just a restart, but a full shutdown and restart solved that (after closing all my browsers). Probably unhappy with multiple browser windows connected to the server. I've seen it before.
Thanks for the solid upgrade!
")
-
 2
2
-
-
Just noticed the same errors in my log (And I'm running an Adaptec 7 series controller) and the same issue with random read errors. I will be downgrading to 6.12.4 asap!
Thanks!
-
2 hours ago, guy.davis said:
Go into the shell of the `machinaris` Chia fullnode container and delete file:
/root/.chia/machinaris/config/cold_wallet_addresses.jsonThen add your address back, just for the Chia row, using the Machinaris WebUI's wallets page.
That did the trick! Thank you sir!!
-
 1
1
-
-
I'm having problems deleting a cold wallet address I mistakenly added to the Chinilla fork. On the wallet page, I open the edit wallet option, delete the key for the cold wallet, save and close. When I reopen the edit option, the wallet key is still there.
Am I doing something wrong, or is this a bug? Is there somewhere I can manually remove it?
-
31 minutes ago, guy.davis said:
Machinaris v2.0.0 is now available.
Thank you for the new version! Question: the notes state that deprecated blockchains are being hidden. Should we just uninstall the deprecated blockchain dockers?
-
On 3/7/2023 at 1:05 PM, jcarre said:
I am having exactly the same problem. Qbitorrent crashes with a:
When this happens web ui becomes unresponsive, docker kill makes the ui work again, but qbitorrent won't restart correctly.
The only fix is to restart docker, which will not start again for me until I fully restart.
I also have the umount error while turning off the array.The problem seemed to go away after last update, I got a couple days uptime. But it happened twice yesterday.
I'm having the same problem. I always notice when I can no longer load the unRaid webgui. All my other dockers but qbittorrent are running and accessible. I can ssh into the server without issue. When I try and stop docker, I get the error that it could not stop qbitorrent. Same for stopping nginx (unless I try and stop docker first). I usually end up rebooting.
-
1
-
-
[SOLVED - See Below]
So I decided this weekend to move my artwork from the associated movie/tv folder to one location on an Unassigned SSD that was added to a cache pool to speed up the thumbnail loading in the interface (Drives that were asleep take a moment to spin up). That has worked fine, and thumbnails load MUCH quicker now.
The problem I have, is no matter what I do, Emby seems to make duplicate/linked user shares called 'cache' and 'metadata'. So even though the path I have set to my drive is: '/mnt/emby-assets/', and the folders 'cache' and 'metadata' are created in the '/mnt/emby-assets' drive as expected, Emby also creates linked user shares ('cache' and 'metadata'). By linked I mean if I delete files in one location, they are deleted in the other as well.
So, what can I do to stop Emby from creating the mirrored user shares? And is this a bug? Why would it do that?
EDIT: Clarification: When I say linked, I mean the folder '/mnt/emby-assets/cache' is linked/mirrored to the user share that was created (/mnt/user/cache).
SOLUTION: So looks like it was user error. I'm going to leave this up for anyone else that might do the same thing. Basically, though I have used cache pools since they were available, I never realized there was an option to "Enable user share assignment". I had that set to yes, so top level folders in my emby-assets pool were automatically added to /mnt/user. Sigh.
-
1
-
-
Hi guy.davis!
Not sure if this is a known bug, new bug, or an issue with my own installation, but Sorting on the 'balance $' column, as well as the "Wallet Summary' are no longer accurate since I moved my Chia into a cold wallet last night. My assumption is the balance column is not including the cold wallet value in the total (As the position my Chia is in reflects the remnants of Chia that I left in the 'hot' wallet), while the Summary is showing about half the total value...
Also, as an aside, my issue with my paused flora wallet resolved itself after following all the recommendations in your wiki page.
Finally, I just realized today about the issue of missing 7/8 coin rewards from all my forks because I am using pooled plots! I always wondered what the new 'Claim Rewards' button does. Unfortunately, when I clicked on it, it did not see any of my missing coins, but going to alltheblocks seems to have found them. I know it's still experimental, but thought I would provide the data point, in case it helped!
Thanks Again for all your hard work! You've built a truly remarkable Docker here!!
EDIT: So Wallet Summary is now displaying correctly!.... It's possible that the transferred Chia to my cold wallet hadn't been captured yet (Even though it showed in the cold wallet column)... Sorting is still an issue though...
-
1
-
-
Any ideas how to restart a wallet? My flora blockchain shows as synced, but the wallet shows as paused. I've tried to restart it in the wallet page, and the popup claims it is trying, but it never unpauses... I've tried several times over the last few weeks without success.
-
On 9/22/2022 at 12:43 PM, Hoopster said:
I am not sure how this may be impacted by the Docker Folder plugin as I do not use it, but, in the Docker tab Advanced view, you can set a delay AFTER a docker container starts. The wait value will delay the next docker container start by that amount. I believe it is in seconds.
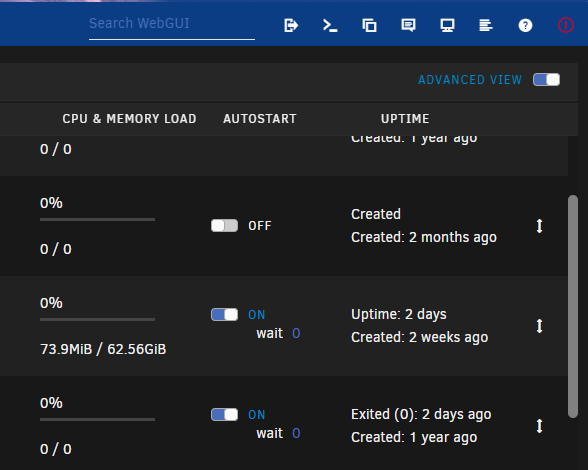
Hmmm... Good suggestion! Sadly, I just tried, but it seems to only apply on first boot. If I stop my docker, set the delay and started the docker, it just starts as normal...
-
Is there an option to stagger the startup of the dockers inside a folder? Maybe the ability to add a delay between dockers so a folder with many dockers inside does not overwhelm your system? I've looked around, but nothing jumped out at me :).
-
Sounds great! I'll install it tonight!
-
1
-
-
1 hour ago, Snowman said:
Wish it was so but my rebuild were not clean and had lost and found items. 1 Disk won't emulate or mount so have to backup in separate computer and try to put info back after format. Been a long road trying to recovery data correctly.
My cache drives/pools are the same mess and some info is not recognizable when copied over and try to open.
This was a major blow up despite UPS etc. Not sure if it was me, power spike, trying to add new drive which was not working, or other that corrupted things but main not a fun one. Hard to pinpoint what happened.
For sure I'll take screen shot configs for reference. I had no problems up to this point with my card.
Uggh :(. I feel your pain. I had a system crash 5 or 6 years ago where several drives corrupted and could not be rebuilt from parity. It was a long slow process to recover the missing data, but I eventually got almost everything back. Good luck in recovering your system and getting UnRaid back up and running!
I will reboot my system later on and get you some pics of my settings. No guarantees that they are what you should set, but they have been working solidly for the last 3 years and might at least point you in the right direction!.
-
Hey! Oh no! I'm so sorry to hear you're having issues with your 71605 card
 .
.
The key for me when using my Adaptec 72405 was to confirm if the drive I was going to rebuild showed up normally when emulated by UnRaid, as per JorgeB's comment in this thread:
On 2/2/2019 at 2:39 AM, JorgeB said:One of the reason RAID controllers are not recommended, though would't expect it would write to the disks without you telling it to initialize them or similar.
Partition info is outside parity, so if you rebuild one disk at a time Unraid should recreate the partitions, to confirm, stop the array, unassign one of the unmountable disks, start the array, check that the emulated disk mounts correctly and data looks OK, also good to check filesystem, if all is well rebuild, you can rebuild on top of the original disks, though using new ones would be safer in case something goes wrong, when rebuild is done repeat for the other disk.
In my case, emulated drives showed up as expected, and I confirmed that the data appeared normally and without issue. Also, during the process, I confirmed correct emulation of drive and contents before every single drive was rebuilt. Once the rebuild process was done, drive appeared normally, no data was moved to lost and found, and no XFS repair was required.
Also, I can confirm that it is continuing to perform normally in 6.10.3, and I have since added a 36-port Expander card as well as a 4-port NVMe card to my array.
Not that that information helps you much at this point 😢, but I just wanted you to know that 3 years later I am still running this card without issue.
If you plan to continue to use your 71605 after you have recovered and have any questions on config settings for it, let me know and I can take some screenshots of mine. Though not the same card, they're from the same family, so my config settings might help you.
-
18 hours ago, guy.davis said:
Good day! Machinaris v0.8.3 is now available. Changes include:
- Additional blockchain pricing from Vayamos and Posat exchanges on the Blockchains, Wallets, and Summary pages.
- New blockchains: Apple, Chinilla, Gold, LittleLamboCoin, Mint, Tad, Wheat
- Update: BPX to v2.0.0, BTCGreen to v1.5.0, Maize to v1.5.0, Petroleum to v1.0.16, Shibgreen to v1.5.0
- Update: Chia to v1.5.1, Bladebit to v2.0.0 (beta-1) with diskplot mode (beta only in `:develop` and `:test` images)
- Fixes: Avoid timeout/slowness encountered by those with many drives, also many cold wallet transactions
Links:
Updated without issue! Thanks very much!
Do all the new blockchains use the regular plot size that Chia uses, or do some of them require different sized plots?
-
Farming going really well! Profit coin syncing up a bit slower than the rest, but I'm patient!
Quick thought: It would be handy if we could adjust the timeline of the displayed info in the charts. For example, total wallet value seems to be hard-coded to a week. If we had more control over the timeline for each chart, that would be pretty handy (For example, I might want to see the value of my wallet since the beginning, or maybe Year-to-date...).
-
53 minutes ago, guy.davis said:
Sorry for the trouble. Typo in the Cactus launch file and I've been in the woods a few days. Just fixed now, so please check for an update to Machinaris-Cactus (all release streams v0.8.2+). Note: I had to remove all from ~/machinaris-cactus directory except the blockchain DB file at: ~/.machinaris-cactus/cactus/mainnet/db/blockchain_v2_mainnet.sqlite to get things running again after the Cactus blockchain SSL certificate expiry. Now fully synced.
No worries! Once I deleted the typo, everything was good to go! Glad you had time to disconnect!! 😁
-
3 hours ago, MortenSchmidt said:
I had the same problem and the vi edit solved the syntax error unexpected end of file. But now I have the problem I get 0 connections. Never had this problem before, but "docker exec -it machinaris-cactus cactus show -c" shows no connections at all. Anyone else had this and found a solution?
Push the new add node peers button on the connection page for cactus. It might take a few minutes to show up, but works great!
-
1
-
-
1 hour ago, mdrodge said:
A couple of us where working out the same issue on discord today. (I'll tell you what they told me)
in the cactus image console type : vi /machinaris/scripts/forks/cactus_launch.sh
this should bring up a file, there seems to be an extra If command... delete it ( a line with if and nothing else )
then move to the bottom of the page and type :wq (to save)
That's it! It comes right after the loop over completed plot directories (which is exactly where the error occurred for me).
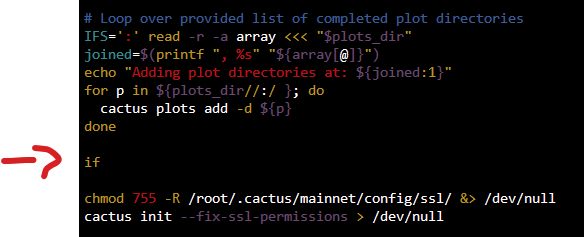
Much appreciated!
-
I'm trying to get cactus up and running again. I've updated to v0.8.2, and deleted the mainnet directory inside the 'cactus' folder, but when I restart the chia docker, it starts rebuilding the missing folder, but then stops and gives me this error:

Thanks!
-
30 minutes ago, guy.davis said:
This morning N-Chain is Synced for me. Please try adding some peers from AllTheBlocks, currently manual steps. In next version of Machinaris v0.8.1, adding 10 new peers from ATB is a single button click on the Connections page.
As always, you have the solution!!! :). I added some peers, and N-Chain has started syncing again.
Thanks again!
-
Hello!
Is anyone else having issues with nchain? Ever since last Friday (the 8th), my nchain blockchain has stopped updating. I thought it might be related to upgrading to 6.10.3, but when I did the math, I did the upgrade several days before it stopped working...
Though, when looking at the nchain dbs, some of them stopped updating around the same time as my upgrade...
When a blockchain has stalled like this in the past, a reboot of Machinaris and the individual coins would usually fix it, but that doesn't seem to be helping. Any ideas?
Note: I'm farming almost all the other coins, and this is the only one I am having issues with.
-
On 4/2/2022 at 6:46 PM, guy.davis said:
Good day! Machinaris v0.7.1 is now available. Changes include:
- Drive monitoring using Smartctl (WebUI status currently, alerting to come soon)
- Dutch translations (nl_NL) provided by @bdeprez. Thanks!
- Updates to various fork blockchains and tools including BTCGreen, Flax, HDDCoin, Madmax, MMX and Shibgreen
- Chia - v1.3.1 patch release
- Chia - v1.3.2 patch release
Notes:
- Drive monitoring not supported on Windows hosts unfortunately due to Docker device pass-thru.
- Migration to new Flax database format requires manual step: `flax db upgrade`Do we need to upgrade all the alt coin DBs as well to v2? I've done the main Chia one, and am currently doing the Flax one (as per instructions above), but what about the rest? They all seem to have v1 dbs in their mainnet/db folders...
-
On 3/5/2022 at 7:56 AM, Squid said:
Due to various continual issues with this plugin, it has now been marked as being incompatible with Unraid versions 6.9.0+
It is highly advised to uninstall this plugin (and Statistics Sender if installed) and switch to the Unassigned Devices Preclear plugin (or Binhex-Preclear if you prefer a command line interface)

I only noticed this warning after I had completed a full 3 cycle pre clear on one drive and started a new 3 cycle preclear on the next. The first one passed without issue, and the second one is chugging along.
I'm seeing people comment with random errors/failures, but if my preclear finishes normally, should I be concerned? Do I need to rerun preclear with the UD Preclear on the first drive and cancel the preclear running on the second one, or if it finishes without error, I'm ok? (But will be removing and replacing script once the process is done).-
1
-







Unraid OS version 6.12.8 available
in Announcements
Posted
Yup. Fixed. I had to roll back as well, but no issues with this one.