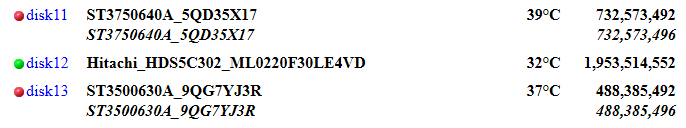eweitzman
-
Posts
82 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by eweitzman
-
That's fantastic. Thanks! I didn't know you could keep parity with new config/initconfig. I'll get the array back up this way and then do a parity check to see if anything has gone wrong on the data drives. Is there a way to identify which files may be affected if there are sync errors found? Since the data and parity are striped across all drives, I wouldn't think the disk with a bad file could be identified.
-
It doesn't seem like there are any real options. If I put the old 3TB parity drive back in, the array will think it's a new drive and will want to initialize it, since the array was last running with the 6TB drive for partiy. So if that's true, and the 3TB drive with valid parity is useless now to check the array, I'll have to rebuild parity on the 6TB drive and hope there's no corruption on any other drive.
-
A syslog of good/running system is attached. There were no logs saved to /boot/logs during the upgrade process even though clean shutdowns were done ever time. unRAID version is 5.0.5. 17 SATA drive array. Drives connected to MSI-7512 motherboard, SAS2LP-MV8, and a 2-port SATA card. 2GB ram. PATA cache drive. - Eric syslog.txt
-
Hi. I replaced a 3TB parity drive with a new 6TB WD red. After everything was done, I ran a parity check. Sometime between starting it in the morning and coming home from work in the evening, a few drives went offline and the parity check logged about 2 million sync errors per drive. The process I followed was: - ran a parity check with old 3TB parity drive - pre-cleared the new 6TB drive - replaced 3TB parity drive with 6TB drive - rebuilt parity on 6TB drive - ran a parity check with 6TB drive. This is where the drives went offline. I checked all connections and restarted the system. All drives and controllers seem okay, and the array comes on line okay with all green balls. Then I started a read-only parity check. About 20 minutes in, sync errors started to show up. I see two options after I check all the hardware. Option 1. Assume the parity is bad on the 6TB drive. Run a parity check to update the 6TB drive again. Option 2. Put the original 3TB parity drive back in. Run a read-only parity check and if all is well, pre-clear the 6TB drive and start over. If there are problems with the 3TB read-only parity check, some of data drives have been corrupted. Find a new course of action. Option 1 will be much faster. It took 60 hours to pre-clear the 6TB drive with speeds at 100-140Mb/s. But it doesn't tell me the state of the other drives in the array. Thanks for any advice, - Eric
-
unRAID Project Update, Core Features, Virtualization, and Thanks You's
eweitzman replied to jonp's topic in Announcements
I had to stop reading this thread at page three/post 42 (quoted above). Unraid is a NAS for me. My build is low powered hardware (circa 4 years ago, celeron-based M/B, a $20 video card) in a big case with lots of disk and a few SAS controllers. Under the heaviest NAS loads, it barely uses 5% of the CPU. It idles at about 60 watts when the disks spin down. I can't/don't need/want/won't run multiple VMs using video cards with GPUs -- this is a storage server after all, not a showplace for uber-videocard game play. Yet you claim that grumpy's list of NAS features is complicated and confusing. Compared to deciphering the feature set in your original post? And what it will take to use them? Ha. I'll tell you, if I have to spend more than a few minutes on figuring out how to disable/ignore/not install the VM-related features in unRaid v6 that you and Eric (2/3 of the development team) are building, and have to deal with any bugs and performance hits for VM support, I'll stick with version 5 until there's a good reason to move to another product. Maybe there's a business model for you guys going in this direction, but it excludes this customer. I sure hope you've done your market research. - Eric -
bonienl, If I may add my 2 cents, I would prefer to have the main page untabbed, since it requires an extra click to get to the shutdown button which is the only thing I regularly use the webgui for. Just one extra little click can be perceived as friction depending on my mood... Perhaps everyone could be accommodated by adding an option to make it tabbed (or not) like you've done in "Settings | Display Settings | Show settings page as tab view". I have a lot of drives and a big monitor, but with the table view setting set to narrow, everything should fit fine (for me) without scrolling as does the vanilla webgui. Thanks!
-
While upgrading a 750GB IDE drive to a 3TB SATA (UPGRADE_DISK) my SAS card went offline along with eight drives. A spontaneous parity CHECK then corrupted the parity drive. I'd like to rebuild parity, but with the data disks mounted read-only. Is this possible? -------------------------------------- The 3TB drive was precleared beforehand and it was on the SAS controller. The parity drive was not on the controller. My unraid version is 5.0-rc16c. It appears that the upgrade terminated way too early, possibly because unmenu restarted, and then a CHECK started and wrote what must be garbage to the parity drive. I wasn't watching the system or interacting with the web GUIs while these things occurred. unraid made about 17,000 writes to the parity drive, so it can't be trusted to rebuild the old data (750GB) onto the new drive (3TB). The rebuild log looks like this: Jan 21 18:45:53 Tower emhttp: Spinning up all drives... (Other emhttp) Jan 21 18:45:53 Tower kernel: mdcmd (46): spinup 0 (Routine) Jan 21 18:45:53 Tower kernel: mdcmd (47): spinup 1 (Routine) Jan 21 18:45:53 Tower kernel: mdcmd (48): spinup 2 (Routine) <snip> Jan 21 18:45:53 Tower kernel: mdcmd (62): spinup 16 (Routine) Jan 21 18:45:53 Tower kernel: mdcmd (63): spinup 17 (Routine) Jan 21 18:45:53 Tower emhttp: writing GPT on disk (sdo), with partition 1 offset 64, erased: 0 (Drive related) Jan 21 18:45:53 Tower emhttp: shcmd (75): sgdisk -Z /dev/sdo $stuff$> /dev/null (Drive related) Jan 21 18:45:54 Tower emhttp: shcmd (76): sgdisk -o -a 64 -n 1:64:0 /dev/sdo |$stuff$ logger (Drive related) Jan 21 18:45:54 Tower kernel: sdo: sdo1 (Drive related) Jan 21 18:45:56 Tower logger: Creating new GPT entries. Jan 21 18:45:56 Tower logger: The operation has completed successfully. Jan 21 18:45:56 Tower emhttp: shcmd (77): udevadm settle (Other emhttp) Jan 21 18:45:56 Tower kernel: sdo: sdo1 (Drive related) Jan 21 18:45:56 Tower emhttp: Start array... (Other emhttp) Jan 21 18:45:56 Tower kernel: mdcmd (64): start UPGRADE_DISK (unRAID engine) Jan 21 18:45:56 Tower kernel: unraid: allocating 95460K for 1280 stripes (18 disks) Jan 21 18:45:56 Tower kernel: md1: running, size: 1465138552 blocks (Drive related) Jan 21 18:45:56 Tower kernel: md2: running, size: 1465138552 blocks (Drive related) <snip> Jan 21 18:46:00 Tower kernel: REISERFS (device md17): journal params: device md17, size 8192, journal first block 18, max trans len 1024, max batch 900, max commit age 30, max trans age 30 (Routine) Jan 21 18:46:00 Tower kernel: REISERFS (device md17): checking transaction log (md17) (Routine) Jan 21 18:46:01 Tower kernel: REISERFS (device md17): Using r5 hash to sort names (Routine) Jan 21 18:53:22 Tower unmenu-status: Exiting unmenu web-server, exit status code = 141 Jan 21 18:53:22 Tower unmenu-status: Starting unmenu web-server Jan 21 18:54:42 Tower emhttp: resized: /mnt/disk17 (Other emhttp) Jan 21 18:54:42 Tower emhttp: shcmd (146): chmod 777 '/mnt/disk17' (Other emhttp) Jan 21 18:54:42 Tower emhttp: shcmd (147): chown nobody:users '/mnt/disk17' (Other emhttp) Jan 21 18:54:42 Tower emhttp: shcmd (148): mkdir /mnt/user (Other emhttp) Jan 21 18:54:42 Tower emhttp: shcmd (149): /usr/local/sbin/shfs /mnt/user -disks 16777214 -o noatime,big_writes,allow_other -o remember=0 |$stuff$ logger (Other emhttp) Jan 21 18:54:42 Tower emhttp: shcmd (150): crontab -c /etc/cron.d -d $stuff$> /dev/null (Other emhttp) Jan 21 18:54:42 Tower emhttp: shcmd (151): /usr/local/sbin/emhttp_event disks_mounted (Other emhttp) Jan 21 18:54:42 Tower emhttp_event: disks_mounted (Other emhttp) It can't possibly have rebuilt 750GB of data in under 9 minutes. Perhaps unmenu restarting about 1 minute before the rebuild ended caused the rebuild to stop prematurely. The next log entries show a parity check commencing, then an hour later the SAS card stops working and parity is trashed: Jan 21 18:54:42 Tower kernel: mdcmd (65): check CORRECT (unRAID engine) Jan 21 18:54:42 Tower kernel: md: recovery thread woken up ... (unRAID engine) Jan 21 18:54:42 Tower kernel: md: recovery thread rebuilding disk17 ... (unRAID engine) Jan 21 18:54:42 Tower kernel: md: using 1536k window, over a total of 2930266532 blocks. (unRAID engine) Jan 21 18:54:43 Tower emhttp: shcmd (152): :>/etc/samba/smb-shares.conf (Other emhttp) Jan 21 18:54:44 Tower emhttp: Restart SMB... (Other emhttp) Jan 21 18:54:44 Tower emhttp: shcmd (153): killall -HUP smbd (Minor Issues) Jan 21 18:54:44 Tower emhttp: shcmd (154): ps axc | grep -q rpc.mountd (Other emhttp) Jan 21 18:54:44 Tower emhttp: _shcmd: shcmd (154): exit status: 1 (Other emhttp) Jan 21 18:54:44 Tower emhttp: shcmd (155): /usr/local/sbin/emhttp_event svcs_restarted (Other emhttp) Jan 21 18:54:44 Tower emhttp_event: svcs_restarted (Other emhttp) Jan 21 19:42:01 Tower crond[1239]: failed parsing crontab for user root: cron="" (Minor Issues) Jan 21 19:55:45 Tower kernel: drivers/scsi/mvsas/mv_sas.c 1957:Release slot [2] tag[2], task [f746ee00]: (System) Jan 21 19:55:45 Tower kernel: sas: sas_ata_task_done: SAS error 8a (Errors) Jan 21 19:55:45 Tower kernel: sd 1:0:0:0: [sdl] command f7601cc0 timed out (Drive related) By the time I actually checked up on the rebuild progress, the log is full of errors such as this snippet: Jan 21 19:56:14 Tower kernel: sas: sas_eh_handle_sas_errors: task 0xf746e500 is aborted (Errors) Jan 21 19:56:14 Tower kernel: sas: ata11: end_device-1:0: cmd error handler (Errors) Jan 21 19:56:14 Tower kernel: sas: ata16: end_device-1:5: cmd error handler (Errors) Jan 21 19:56:14 Tower kernel: sas: ata18: end_device-1:7: cmd error handler (Errors) Jan 21 19:56:14 Tower kernel: sas: ata17: end_device-1:6: cmd error handler (Errors) Jan 21 19:56:14 Tower kernel: sas: ata14: end_device-1:3: cmd error handler (Errors) Jan 21 19:56:14 Tower kernel: sas: ata11: end_device-1:0: dev error handler (Drive related) Jan 21 19:56:14 Tower kernel: ata11.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 (Errors) Jan 21 19:56:14 Tower kernel: ata11.00: failed command: READ DMA EXT (Minor Issues) Jan 21 19:56:14 Tower kernel: ata11.00: cmd 25/00:00:78:e8:17/00:02:17:00:00/e0 tag 0 dma 262144 in (Drive related) Jan 21 19:56:14 Tower kernel: res 01/04:00:77:e8:17/00:00:17:00:00/e0 Emask 0x12 (ATA bus error) (Errors) Jan 21 19:56:14 Tower kernel: ata11.00: status: { ERR } (Drive related) Jan 21 19:56:14 Tower kernel: ata11.00: error: { ABRT } (Errors) Jan 21 19:56:14 Tower kernel: sas: ata12: end_device-1:1: dev error handler (Drive related) Jan 21 19:56:14 Tower kernel: ata11: hard resetting link (Minor Issues) Jan 21 19:56:14 Tower kernel: sas: ata13: end_device-1:2: dev error handler (Drive related) Jan 21 19:56:14 Tower kernel: sas: ata14: end_device-1:3: dev error handler (Drive related) Jan 21 19:56:14 Tower kernel: ata14.00: exception Emask 0x0 SAct 0xf SErr 0x0 action 0x6 frozen (Errors) Jan 21 19:56:14 Tower kernel: ata14.00: failed command: WRITE FPDMA QUEUED (Minor Issues) Jan 21 19:56:14 Tower kernel: ata14.00: cmd 61/00:00:d0:de:17/02:00:17:00:00/40 tag 0 ncq 262144 out (Drive related) Jan 21 19:56:14 Tower kernel: res 40/00:10:10:27:11/00:00:17:00:00/40 Emask 0x4 (timeout) (Errors) Jan 21 19:56:14 Tower kernel: ata14.00: status: { DRDY } (Drive related) Jan 21 19:56:14 Tower kernel: ata14.00: failed command: WRITE FPDMA QUEUED (Minor Issues) Jan 21 19:56:14 Tower kernel: ata14.00: cmd 61/00:00:d0:e0:17/02:00:17:00:00/40 tag 1 ncq 262144 out (Drive related) Jan 21 19:56:14 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) (Errors) Jan 21 19:56:14 Tower kernel: ata14.00: status: { DRDY } (Drive related) Jan 21 19:56:14 Tower kernel: ata14.00: failed command: WRITE FPDMA QUEUED (Minor Issues) Jan 21 19:56:14 Tower kernel: ata14.00: cmd 61/00:00:d0:e2:17/02:00:17:00:00/40 tag 2 ncq 262144 out (Drive related) Jan 21 19:56:14 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) (Errors) Jan 21 19:56:14 Tower kernel: ata14.00: status: { DRDY } (Drive related) Jan 21 19:56:14 Tower kernel: ata14.00: failed command: WRITE FPDMA QUEUED (Minor Issues) Jan 21 19:56:14 Tower kernel: ata14.00: cmd 61/a8:00:d0:e4:17/01:00:17:00:00/40 tag 3 ncq 217088 out (Drive related) Jan 21 19:56:14 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) (Errors) Jan 21 19:56:14 Tower kernel: ata14.00: status: { DRDY } (Drive related) Jan 21 19:56:14 Tower kernel: ata14: hard resetting link (Minor Issues) Jan 21 19:56:16 Tower kernel: sas: ata15: end_device-1:4: dev error handler (Drive related) Jan 21 19:56:16 Tower kernel: sas: ata16: end_device-1:5: dev error handler (Drive related) Jan 21 19:56:16 Tower kernel: ata16.00: exception Emask 0x0 SAct 0x6 SErr 0x0 action 0x6 frozen (Errors) Jan 21 19:56:16 Tower kernel: ata16.00: failed command: READ FPDMA QUEUED (Minor Issues) Jan 21 19:56:16 Tower kernel: ata16.00: cmd 60/00:00:77:e8:17/02:00:17:00:00/40 tag 1 ncq 262144 in (Drive related) Jan 21 19:56:16 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) (Errors) Jan 21 19:56:16 Tower kernel: ata16.00: status: { DRDY } (Drive related) Jan 21 19:56:16 Tower kernel: ata16.00: failed command: READ FPDMA QUEUED (Minor Issues) Jan 21 19:56:16 Tower kernel: ata16.00: cmd 60/58:00:77:ea:17/00:00:17:00:00/40 tag 2 ncq 45056 in (Drive related) Jan 21 19:56:16 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) (Errors) Jan 21 19:56:16 Tower kernel: ata16.00: status: { DRDY } (Drive related) Jan 21 19:56:16 Tower kernel: ata16: hard resetting link (Minor Issues) Jan 21 19:56:16 Tower kernel: sas: ata17: end_device-1:6: dev error handler (Drive related) Jan 21 19:56:16 Tower kernel: ata17.00: exception Emask 0x0 SAct 0x6 SErr 0x0 action 0x6 frozen (Errors) Jan 21 19:56:16 Tower kernel: ata17.00: failed command: READ FPDMA QUEUED (Minor Issues) Jan 21 19:56:16 Tower kernel: ata17.00: cmd 60/00:00:77:e8:17/02:00:17:00:00/40 tag 1 ncq 262144 in (Drive related) Jan 21 19:56:16 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) (Errors) Jan 21 19:56:16 Tower kernel: ata17.00: status: { DRDY } (Drive related) Jan 21 19:56:16 Tower kernel: ata17.00: failed command: READ FPDMA QUEUED (Minor Issues) Jan 21 19:56:16 Tower kernel: ata17.00: cmd 60/58:00:77:ea:17/00:00:17:00:00/40 tag 2 ncq 45056 in (Drive related) Jan 21 19:56:16 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) (Errors) Jan 21 19:56:16 Tower kernel: ata17.00: status: { DRDY } (Drive related) Jan 21 19:56:16 Tower kernel: ata17: hard resetting link (Minor Issues) Jan 21 19:56:17 Tower kernel: drivers/scsi/mvsas/mv_sas.c 1527:mvs_I_T_nexus_reset for device[3]:rc= 0 (System) Jan 21 19:56:17 Tower kernel: mvsas 0000:02:00.0: Phy3 : No sig fis (Drive related) Jan 21 19:56:17 Tower kernel: sas: ata18: end_device-1:7: dev error handler (Drive related) Jan 21 19:56:17 Tower kernel: ata18.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen (Errors) Jan 21 19:56:17 Tower kernel: ata18.00: failed command: READ DMA EXT (Minor Issues) Jan 21 19:56:17 Tower kernel: ata18.00: cmd 25/00:00:77:e6:17/00:02:17:00:00/e0 tag 0 dma 262144 in (Drive related) Jan 21 19:56:17 Tower kernel: res 40/00:00:0f:29:11/00:00:17:00:00/e0 Emask 0x4 (timeout) (Errors) J <snip> Jan 21 19:56:41 Tower kernel: program smartctl is using a deprecated SCSI ioctl, please convert it to SG_IO Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441888 (Errors) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441896 (Errors) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441904 (Errors) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441912 (Errors) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441920 (Errors) Jan 21 19:56:41 Tower kernel: sd 1:0:3:0: [sdo] READ CAPACITY failed (Drive related) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441928 (Errors) Jan 21 19:56:41 Tower kernel: sd 1:0:3:0: [sdo] (Drive related) Jan 21 19:56:41 Tower kernel: Result: hostbyte=0x04 driverbyte=0x00 (System) Jan 21 19:56:41 Tower kernel: sd 1:0:3:0: [sdo] Sense not available. (Drive related) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441936 (Errors) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441944 (Errors) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441952 (Errors) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441960 (Errors) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441968 (Errors) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441976 (Errors) Jan 21 19:56:41 Tower kernel: md: disk17 write error, sector=387441984 (Errors) The new 3TB drive shows used space that's about the same as the full 750GB drive it replaced, but the file system has only a few directories and files. Both it and the other seven drives on the SAS card are red-balled. Since the old 750GB drive and its data is still fine, I can put it back into the system and rebuild the parity drive, then try to upgrade to the 3TB again. The system is current turned off, and before I try this again, I'll see if there are any seating or cabling problems with the SAS card. I would like to ensure that if I try to rebuild parity from the data drives and the SAS card goes offline again, unraid doesn't corrupt the data drives. Is it possible to mount them read-only before rebuilding parity? Thanks, - Eric syslog-2014-01-21.zip
-
topic deleted
-
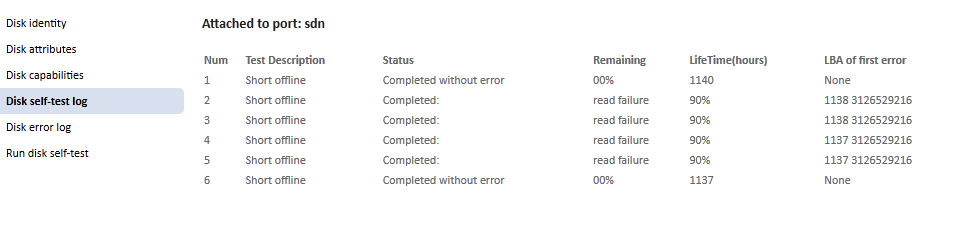
The Disk self-test log displayed in the Disk Health page of the webGui displays information in the wrong columns if the Status message contains a colon. See screenshot attached. The unraid version is 5.0-rc6-r8168-test. - Eric
-
parity drive failure after moving to SASLP-MV8
eweitzman replied to eweitzman's topic in General Support (V5 and Older)
I just moved the parity drive back to the SAS board. It was on the motherboard where I ran the final test shown in my initial post. Another short test, this time run from the webGui instead of unMenu, completed without error. Any ideas? Thanks, - Eric SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0 3 Spin_Up_Time 0x0027 148 143 021 Pre-fail Always - 9566 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 310 5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0 7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0 9 Power_On_Hours 0x0032 099 099 000 Old_age Always - 1141 10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0 11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 115 192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 14 193 Load_Cycle_Count 0x0032 198 198 000 Old_age Always - 7715 194 Temperature_Celsius 0x0022 119 108 000 Old_age Always - 33 196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0 197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 3 198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0 200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed without error 00% 1140 - # 2 Short offline Completed: read failure 90% 1138 3126529216 # 3 Short offline Completed: read failure 90% 1138 3126529216 # 4 Short offline Completed: read failure 90% 1137 3126529216 # 5 Short offline Completed: read failure 90% 1137 3126529216 # 6 Short offline Completed without error 00% 1137 - -
parity drive failure after moving to SASLP-MV8 [The unraid version is 5.0-rc6-r8168-test, running without incident for many months. The SASLP-MV8 firmware is 3.1.0.15N.] In the process of updating my server, a parity check failed when the parity disk went offline. I'm uncertain whether to attribute the problem to the new SAS card, cabling, a disk failure, or if everything is ok and I should follow the "trust my parity drive" procedure. SMART indicates it's a drive problem though. The plan was to update the server by replacing two old four-port PCI and PCIe Sil SATA cards with a SASLP-MV8, and adding a new 3TB drive. The steps I followed were Verify SAS board and new drive 1. Install SAS board 2. Connect new 3TB to SAS board 3. Preclear the drive The drive precleared, verifying that the SAS card is okay. It also precleared in about 1/2 the time the other 3TB drive took. Change drive connections 5. Disconnect drives from SATA cards, remove SATA cards 6. Reconnect drives to motherboard and SAS card so 2TB and 3TB drives are on SAS card, including the parity drive 7. Start server, check drive/disk assignments 8. Perform read-only parity check Step 7 succeeded. Step 8 failed after around 8 hours. There were some device errors in the log an hour into the parity check but it seemed to have recovered until the parity drive went offline. Note that the new, precleared 3TB drive has not been added to the array yet. After the checking proceeded past the ends of the smaller drives and they spun down, the parity check failed. The parity drive turned blue, unMenu says the parity drive status is DISK_DSBL. After checking all connectors and SAS card seating and restarting the server, the parity drive status is DISK_DSBL_NEW. I reviewed the smartctl status and ran several short tests. Each short test had a read failure at LBA 3126529216. The short test fails at the same point even with the parity drive moved to a motherboard SATA port. unraid reports sync errors starting just past this LBA. There are 3 unstable sectors needing to be remapped (Current_Pending_Sector). Since the short test was run several times and had the read error at the same LBA, I assume that the data there is lost and the sector will get remapped when the firmware decides to. So at a minimum, I will have to rebuild parity. It seems to me that the drive failure is independent of any issue with the SAS card. But I'm uncertain, as this seems rather coincidental, and would appreciate it if someone could point out anything I may have missed. Could the drive's error timeout of this consumer drive come into play now that it's connected to a server controller instead of a consumer controller? Can the SAS controller be flashed or configured to work better with longer drive timeouts? Thanks, - Eric smartctl output (via unMenu) smartctl -a -d ata /dev/sdn smartctl 5.40 2010-10-16 r3189 [i486-slackware-linux-gnu] (local build) Copyright (C) 2002-10 by Bruce Allen, http://smartmontools.sourceforge.net === START OF INFORMATION SECTION === Device Model: WDC WD30EZRX-00MMMB0 Serial Number: WD-WCAWZ2391051 Firmware Version: 80.00A80 User Capacity: 3,000,592,982,016 bytes Device is: Not in smartctl database [for details use: -P showall] ATA Version is: 8 ATA Standard is: Exact ATA specification draft version not indicated Local Time is: Mon Jan 14 12:14:40 2013 PST SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x85) Offline data collection activity was aborted by an interrupting command from host. Auto Offline Data Collection: Enabled. Self-test execution status: ( 121) The previous self-test completed having the read element of the test failed. Total time to complete Offline data collection: (51180) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: ( 2) minutes. Extended self-test routine recommended polling time: ( 255) minutes. Conveyance self-test routine recommended polling time: ( 5) minutes. SCT capabilities: (0x3035) SCT Status supported. SCT Feature Control supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0 3 Spin_Up_Time 0x0027 148 143 021 Pre-fail Always - 9575 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 309 5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0 7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0 9 Power_On_Hours 0x0032 099 099 000 Old_age Always - 1138 10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0 11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 114 192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 14 193 Load_Cycle_Count 0x0032 198 198 000 Old_age Always - 7704 194 Temperature_Celsius 0x0022 120 108 000 Old_age Always - 32 196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0 197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 3 198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0 200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed: read failure 90% 1138 3126529216 # 2 Short offline Completed: read failure 90% 1137 3126529216 # 3 Short offline Completed: read failure 90% 1137 3126529216 # 4 Short offline Completed without error 00% 1137 - SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay. partial log file: Jan 14 01:05:07 Tower kernel: mdcmd (61): check NOCORRECT Jan 14 01:05:07 Tower kernel: md: recovery thread woken up ... Jan 14 01:05:07 Tower kernel: md: recovery thread checking parity... Jan 14 01:05:07 Tower kernel: md: using 1536k window, over a total of 2930266532 blocks. Jan 14 02:01:01 Tower crond[1221]: failed parsing crontab for user root: cron="" Jan 14 02:05:33 Tower kernel: ata8.00: exception Emask 0x10 SAct 0x0 SErr 0x780100 action 0x6 Jan 14 02:05:33 Tower kernel: ata8.00: irq_stat 0x08000000 Jan 14 02:05:33 Tower kernel: ata8: SError: { UnrecovData 10B8B Dispar BadCRC Handshk } Jan 14 02:05:33 Tower kernel: ata8.00: failed command: READ DMA EXT Jan 14 02:05:33 Tower kernel: ata8.00: cmd 25/00:00:5f:ca:db/00:04:11:00:00/e0 tag 0 dma 524288 in Jan 14 02:05:33 Tower kernel: res 50/00:00:5e:ca:db/00:00:11:00:00/e0 Emask 0x10 (ATA bus error) Jan 14 02:05:33 Tower kernel: ata8.00: status: { DRDY } Jan 14 02:05:33 Tower kernel: ata8: hard resetting link Jan 14 02:05:33 Tower kernel: ata8: SATA link up 3.0 Gbps (SStatus 123 SControl 300) Jan 14 02:05:33 Tower kernel: ata8.00: configured for UDMA/133 Jan 14 02:05:33 Tower kernel: ata8: EH complete Jan 14 02:06:03 Tower kernel: ata7.00: exception Emask 0x0 SAct 0x0 SErr 0x180000 action 0x6 frozen Jan 14 02:06:03 Tower kernel: ata7: SError: { 10B8B Dispar } Jan 14 02:06:03 Tower kernel: ata7.00: failed command: READ DMA EXT Jan 14 02:06:03 Tower kernel: ata7.00: cmd 25/00:40:1f:cf:db/00:03:11:00:00/e0 tag 0 dma 425984 in Jan 14 02:06:03 Tower kernel: res 40/00:00:01:4f:c2/00:00:00:00:00/00 Emask 0x4 (timeout) Jan 14 02:06:03 Tower kernel: ata7.00: status: { DRDY } Jan 14 02:06:03 Tower kernel: ata7: hard resetting link Jan 14 02:06:03 Tower kernel: ata7: SATA link up 3.0 Gbps (SStatus 123 SControl 300) Jan 14 02:06:03 Tower kernel: ata7.00: configured for UDMA/133 Jan 14 02:06:03 Tower kernel: ata7: EH complete Jan 14 03:01:01 Tower crond[1221]: failed parsing crontab for user root: cron="" Jan 14 04:01:01 Tower crond[1221]: failed parsing crontab for user root: cron="" Jan 14 05:00:01 Tower crond[1221]: failed parsing crontab for user root: cron="" Jan 14 06:00:01 Tower crond[1221]: failed parsing crontab for user root: cron="" Jan 14 06:27:57 Tower kernel: mdcmd (62): spindown 15 Jan 14 07:00:01 Tower crond[1221]: failed parsing crontab for user root: cron="" Jan 14 07:45:26 Tower kernel: mdcmd (63): spindown 4 Jan 14 07:45:26 Tower kernel: mdcmd (64): spindown 7 Jan 14 08:00:01 Tower crond[1221]: failed parsing crontab for user root: cron="" Jan 14 09:00:01 Tower crond[1221]: failed parsing crontab for user root: cron="" problem with parity drive sdn starts here: Jan 14 09:24:17 Tower kernel: sd 0:0:4:0: [sdn] command f4530240 timed out Jan 14 09:24:17 Tower kernel: sd 0:0:4:0: [sdn] command f3eaee40 timed out Jan 14 09:24:17 Tower kernel: sd 0:0:4:0: [sdn] command f3eae480 timed out Jan 14 09:24:17 Tower kernel: sd 0:0:4:0: [sdn] command f7407d80 timed out Jan 14 09:24:17 Tower kernel: sd 0:0:4:0: [sdn] command f76660c0 timed out Jan 14 09:24:17 Tower kernel: sd 0:0:4:0: [sdn] command f76e1540 timed out Jan 14 09:24:17 Tower kernel: sas: Enter sas_scsi_recover_host busy: 6 failed: 6 Jan 14 09:24:17 Tower kernel: sas: trying to find task 0xf3efb7c0 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: aborting task 0xf3efb7c0 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: task 0xf3efb7c0 is aborted Jan 14 09:24:17 Tower kernel: sas: sas_eh_handle_sas_errors: task 0xf3efb7c0 is aborted Jan 14 09:24:17 Tower kernel: sas: trying to find task 0xf3efbb80 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: aborting task 0xf3efbb80 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: task 0xf3efbb80 is aborted Jan 14 09:24:17 Tower kernel: sas: sas_eh_handle_sas_errors: task 0xf3efbb80 is aborted Jan 14 09:24:17 Tower kernel: sas: trying to find task 0xf3efa500 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: aborting task 0xf3efa500 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: task 0xf3efa500 is aborted Jan 14 09:24:17 Tower kernel: sas: sas_eh_handle_sas_errors: task 0xf3efa500 is aborted Jan 14 09:24:17 Tower kernel: sas: trying to find task 0xf3efa140 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: aborting task 0xf3efa140 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: task 0xf3efa140 is aborted Jan 14 09:24:17 Tower kernel: sas: sas_eh_handle_sas_errors: task 0xf3efa140 is aborted Jan 14 09:24:17 Tower kernel: sas: trying to find task 0xf3efa3c0 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: aborting task 0xf3efa3c0 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: task 0xf3efa3c0 is aborted Jan 14 09:24:17 Tower kernel: sas: sas_eh_handle_sas_errors: task 0xf3efa3c0 is aborted Jan 14 09:24:17 Tower kernel: sas: trying to find task 0xf3efb040 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: aborting task 0xf3efb040 Jan 14 09:24:17 Tower kernel: sas: sas_scsi_find_task: task 0xf3efb040 is aborted Jan 14 09:24:17 Tower kernel: sas: sas_eh_handle_sas_errors: task 0xf3efb040 is aborted Jan 14 09:24:17 Tower kernel: sas: ata13: end_device-0:4: cmd error handler Jan 14 09:24:17 Tower kernel: sas: ata9: end_device-0:0: dev error handler Jan 14 09:24:17 Tower kernel: sas: ata10: end_device-0:1: dev error handler Jan 14 09:24:17 Tower kernel: sas: ata11: end_device-0:2: dev error handler Jan 14 09:24:17 Tower kernel: sas: ata12: end_device-0:3: dev error handler Jan 14 09:24:17 Tower kernel: sas: ata13: end_device-0:4: dev error handler Jan 14 09:24:17 Tower kernel: sas: ata14: end_device-0:5: dev error handler Jan 14 09:24:17 Tower kernel: ata13.00: exception Emask 0x0 SAct 0x3f SErr 0x0 action 0x6 frozen Jan 14 09:24:17 Tower kernel: sas: ata15: end_device-0:6: dev error handler Jan 14 09:24:17 Tower kernel: ata13.00: failed command: READ FPDMA QUEUED Jan 14 09:24:17 Tower kernel: sas: ata16: end_device-0:7: dev error handler Jan 14 09:24:17 Tower kernel: ata13.00: cmd 60/00:00:b0:0b:5b/02:00:ba:00:00/40 tag 0 ncq 262144 in Jan 14 09:24:17 Tower kernel: res 40/00:04:40:c4:5a/00:00:ba:00:00/40 Emask 0x4 (timeout) Jan 14 09:24:17 Tower kernel: ata13.00: status: { DRDY } Jan 14 09:24:17 Tower kernel: ata13.00: failed command: READ FPDMA QUEUED Jan 14 09:24:17 Tower kernel: ata13.00: cmd 60/00:00:b0:0d:5b/02:00:ba:00:00/40 tag 1 ncq 262144 in Jan 14 09:24:17 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) Jan 14 09:24:17 Tower kernel: ata13.00: status: { DRDY } Jan 14 09:24:17 Tower kernel: ata13.00: failed command: READ FPDMA QUEUED Jan 14 09:24:17 Tower kernel: ata13.00: cmd 60/00:00:b0:0f:5b/02:00:ba:00:00/40 tag 2 ncq 262144 in Jan 14 09:24:17 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) Jan 14 09:24:17 Tower kernel: ata13.00: status: { DRDY } Jan 14 09:24:17 Tower kernel: ata13.00: failed command: READ FPDMA QUEUED Jan 14 09:24:17 Tower kernel: ata13.00: cmd 60/00:00:b0:11:5b/02:00:ba:00:00/40 tag 3 ncq 262144 in Jan 14 09:24:17 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) Jan 14 09:24:17 Tower kernel: ata13.00: status: { DRDY } Jan 14 09:24:17 Tower kernel: ata13.00: failed command: READ FPDMA QUEUED Jan 14 09:24:17 Tower kernel: ata13.00: cmd 60/00:00:b0:13:5b/02:00:ba:00:00/40 tag 4 ncq 262144 in Jan 14 09:24:17 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) Jan 14 09:24:17 Tower kernel: ata13.00: status: { DRDY } Jan 14 09:24:17 Tower kernel: ata13.00: failed command: READ FPDMA QUEUED Jan 14 09:24:17 Tower kernel: ata13.00: cmd 60/00:00:b0:15:5b/02:00:ba:00:00/40 tag 5 ncq 262144 in Jan 14 09:24:17 Tower kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) Jan 14 09:24:17 Tower kernel: ata13.00: status: { DRDY } Jan 14 09:24:17 Tower kernel: ata13: hard resetting link Jan 14 09:24:19 Tower kernel: drivers/scsi/mvsas/mv_sas.c 1522:mvs_I_T_nexus_reset for device[4]:rc= 0 Jan 14 09:24:19 Tower kernel: sas: sas_ata_task_done: SAS error 8a Jan 14 09:24:19 Tower kernel: sas: sas_ata_task_done: SAS error 8a Jan 14 09:24:19 Tower kernel: ata13.00: both IDENTIFYs aborted, assuming NODEV Jan 14 09:24:19 Tower kernel: ata13.00: revalidation failed (errno=-2) Jan 14 09:24:19 Tower kernel: mvsas 0000:02:00.0: Phy4 : No sig fis Jan 14 09:24:23 Tower kernel: sas: sas_form_port: phy4 belongs to port4 already(1)! Jan 14 09:24:24 Tower kernel: ata13: hard resetting link Jan 14 09:24:25 Tower kernel: ata13.00: configured for UDMA/133 Jan 14 09:24:25 Tower kernel: ata13.00: device reported invalid CHS sector 0 Jan 14 09:24:25 Tower last message repeated 4 times Jan 14 09:24:25 Tower kernel: ata13: EH complete Jan 14 09:24:25 Tower kernel: sas: --- Exit sas_scsi_recover_host: busy: 0 failed: 0 Jan 14 09:24:25 Tower kernel: md: parity incorrect: 3126529904 Jan 14 09:24:25 Tower kernel: md: parity incorrect: 3126529912 Jan 14 09:24:25 Tower kernel: md: parity incorrect: 3126529920 Jan 14 09:24:25 Tower kernel: md: parity incorrect: 3126529928 Jan 14 09:24:25 Tower kernel: md: parity incorrect: 3126529936
-
You have to look really hard at page 5 of the PDF version of this ad preview to see it, but there's a 3TB Seagate going on sale on black friday at TigerDirect for $89 http://www.fatwallet.com/black-friday/ads/Tiger-Direct/?page=5#siteContentWrap I think it's the ST3000DM001 with a 24 month warranty: http://www.tigerdirect.com/applications/SearchTools/item-details.asp?EdpNo=1310560&CatId=4357 - Eric
-
That special is over now, but Amazon has them for $149: http://www.amazon.com/Western-Digital-Red-Hard-Drive/dp/B008JJLW4M/ref=sr_1_1?ie=UTF8&qid=1352922829 - Eric
-
After starting up the server, I'd like to go straight to the Main page when connecting to unRAID via the web interface. But regardless of the URL (http://tower or http://tower/Main) it goes to the Welcome page the first time after booting up. Is there a configuration parameter to turn off this behavior? OS version is 5.0-rc6-r8168-test - Eric
-
After installing a new parity disk and running a parity sync to completion around 4-5 hours earlier, and after being refreshed, the Main page on the web interface said that no parity check had been done*. I started a non-correcting parity check and decided to stop it about one minute later. The web interface then said: Last checked on Sat Aug 11 09:02:20 2012 PDT (today), finding 0 errors. * Duration: 18 hours, 25 minutes, 1 second. Average speed: 45.3 MB/sec This is incorrect, since the check was not done. I think the duration and speed are *not* from the previous parity sync, but are extrapolated from the short time the parity check was running. After rebooting the server, the first line of this message is still displayed. - Eric * This implies that a parity check is always necessary after a parity sync. Is that necessarily true?
-
My array is running 5.0-rc6-r8168-test and SimpleFeatures. I replaced the parity drive with a larger one, restarted the array, and assigned the new drive as the parity drive. I didn't take note of the exact message, but the first line in the Array Status area of the Main page said that the Start button would bring the array online and start a parity sync. (There may have been an "are you sure?" checkbox.) I brought the array online. The parity sync did not start as indicated in the message. I started the sync by pressing the parity sync button and it is running. Of course, this is a minor bug. Consider it reported. Over and out. - Eric
-
This old bug is still around in 5.0-rc6-r8168-test. http://lime-technology.com/forum/index.php?topic=1021.0. Teracopy fails randomly with this error while copying files from Windows 7 to the array when the unRAID disks are exported using samba and mounted in Windows. Over the last week, my server has been upgraded from 4.5.4 to 4.7 then 5.0-rc6-r8168-test, with parity checks before/after each step. HPA's were removed to enable the OS upgrades and one drive was replaced with a bigger one. I wiped my flash before putting 5.0-rc6-r6168-test on it. SimpleFeatures is installed. Otherwise, this is a vanilla upgrade. No user shares, no users other than root. The embedded network controller is identified as "eth0: Identified chip type is 'RTL8168C/8111C'". Don't know if this chipset is subject to the problems that r8168 is meant to work around. There are no eth0: messages after start-up, when the network "disappears" during copies. I was going to try to see if this was just a samba problem by turning on NFS but I can't find any instructions for doing this with the new webgui. I enabled NFS in Settings and exported one disk but I can't mount it from Windows 7. Any pointers in the right direction would be appreciated. I have no qualms using NFS if this problem goes away and it performs. C:\>mount \\tower\disk1 x: Network Error - 53 (The network path was not found) Thanks, - Eric log.txt
-
Thanks, Joe. I'll see if I can set in for AHCI in the bios. Yes, I really have two old IDE drives in the system, 500GB and 750GB. I feel like a dunce for not finding the posts here about banishing the HPA with SeaTools and HDDGuru when this came up in the winter, so I'll put the drives in a windows machine and try them if AHCI doesn't improve the situation. - Eric
-
Can anybody say if the 5.0-rc4 kernel has what it takes for hdparm to remove the HPA from my IDE drives? - Eric
-
Thanks. Booting up under 4.7 confirms that HPA is the trouble. But there's nothing to be done to fix it, at least under this OS, because hdparm says: # hdparm -N /dev/hda /dev/hda: The running kernel lacks CONFIG_IDE_TASK_IOCTL support for this device. READ_NATIVE_MAX_ADDRESS_EXT failed: Invalid argument I guess I'll just stick to 4.5.4 until I need to replace these drives. - Eric
-
I have two IDE drives in a mostly SATA system. After upgrading from 4.5.4 to 4.7, these two disks are reported as DISK_WRONG. The main web page reports that the drives are 4 bytes smaller than the recorded (or expected) size. See the attached screenshot for the Main menu report which shows the correct disk serial numbers but different sizes. - Eric Mar 8 19:42:38 Tower kernel: md: import disk11: [3,0] (hda) ST3750640A 5QD35X17 size: 732573492 Mar 8 19:42:38 Tower kernel: md: disk11 wrong Mar 8 19:42:38 Tower kernel: md: import disk12: [8,80] (sdf) Hitachi HDS5C302 ML0220F30LE4VD size: 1953514552 Mar 8 19:42:38 Tower kernel: md: import disk13: [3,64] (hdb) ST3500630A 9QG7YJ3R size: 488385492 Mar 8 19:42:38 Tower kernel: md: disk13 wrong
-
I've taken a stab at getting squeezeserver 7.5.1 running on unraid. Installed perl 5.10 via unmenu. Installed squeezeserver on /mnt/disk1. Worked through the password and file protection and ownership issues and nothing worked, running into same roadblocks as others have reported. That is, I got the server running after protection/ownership was dealt with but couldn't get it to catalog files on unraid drives. Added a cache drive and reinstalled slimserver there, hoping that a file system not managed by unraid would make slimserver happy. It was happier (ie, it *could* find UUID/tiny.pm when installed on the cache drive) but still had lots of problems. It's easiest to troubleshoot startup problems by omitting the --daemon switch when starting the server. This way, errors can be seen in the console as they occur without having to find and tail the log file. Sitting at a windows machine, I have four putty windows to the unraid box like the good old days. Hopefully of interest to others, I discovered several things. 1. When changing the file ownership in the slimserver tree, set the group too: chown -R slimserver.users . Without this, the group remains "root" (or whatever) and things cannot be found by the server/perl. 2. Once group ownership was correct, it wasn't necessary to change file permissions. 3. When run the first few times, slimserver creates new directories (log, prefs, plugins, etc). Even though I'm running slimserver with the --user slimserver switch, these new directories are owned by root! Because of this, slimserver fails when it tries to write to these directories. I changed the ownership of these new directories to slimserver.users as they were created and broke the running serverr. The next server run would get farther. 4. No matter how I try, I cannot get slimserver to scan files on unraid disks that are symlinked into slimserver's music directory. I've given ownership to slimserver for the symlink, the directory linked to, and the files in the directory. Interestingly, the unraid disks (/mnt/disk1, /mnt/disk2, etc) do not show up in the folder trees in the configuration dialogs in the web pages for configuring the server, yet /mnt/cache does. Directories outside of /mnt/cache/music on /mnt/cache when linked into /mnt/cache/music do get scanned. However, if I *move* music into the music directory, slimserver functions properly. Partial win, yes! Now if I could only figure out how to move all my unraid protected data onto the cache drive.......... Being stuck here, with the alternative of running another machine just for slimserver when the unraid box is sitting idle really sucks. Any suggestions? - Eric
-
Yeah, I got what you were saying about how tuning will change performance one way or the other for different scenarios. I will try some of these once the array is loaded. My (waning?) interest is still about the 2xR+2xW thing. unraid.c's header talks about two state transitions specifically for computing parity, but I haven't read into the code to see if they perform first time parity calcs differently. I will find out in a few days how it performs when I add a parity drive to my parity-less array with data disks that are being loaded now. The disks will run at near full bandwidth during parity calc or a lot lower depending. I've search the forum and other documentation for info about these and came up with nothing. Do you know of any references? I'd appreciate it if you could tell me which (if any) of the earlier settings you suggested tweaking is controlled by the "Force NCQ disabled" setting on the unRAID Settings page? Thanks, - Eric
-
That really changes things... My ignorance of the big picture shows. One could hope that if md batches small, apparently sequential requests and asks for one large transfer down the chain, it would be more efficient. That would need to be tested before spending time on serious coding. - Eric
-
With modern drives, you can't GET physical drive geometry. It is translated by the drive. Okay, that was sloppy. Let me rephrase it: ...if the requested stripes have some sort of addressing that can be used to order and group them so they can be retrieved sequentially in batches... A cursory glance shows a large buffer (unsigned int memory) allocated for an array of MD_NUM_STRIPE stripe_head structs. stripe_head has sector and state members. state could be used to prepare a list of stripes waiting to be read and written (ie, that are in the same state), while sector could be used to order them into batches that could be read or written sequentially. At this point, of course, I don't understand the pattern of calls to the driver nor how such batching would be set up. One strategy could be to wait after the first IO request for a bit -- perhaps the approximate time of one drive rotation? -- and then processing the first and subsequent calls in a single read/write request if the sectors are numbered sequentially. Overhead and delay like this may be verboten in a driver, though. I dunno. - Eric