

TDD
-
Posts
75 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by TDD
-

Upgrade from 6.19 -> 6.20/6.21 Causing XFS Disk Problems
TDD replied to TDD's topic in General Support
This is what I have been thinking. So...the fix is to run xfs_check and attempt a repair under 6.21? Odd that when I run it under 6.19 it is fine so things obviously have changed. Is there a way to boot UnRAID into maintenance mode so I can check the disks rather than via the GUI? I guess if I am quick I can stop the array and bring it back up via maintenance and let the check go. The safest plan is to have a backup of all the files I imagine prior to the upgrade and attempted repair I am thinking. Kev. -
Hello all! My system has been very smoothly running 6.19 and made the plunge some weeks ago to 6.20. All went well but after a few hours I noticed the system was down and XFS was noting errors on one of the drives repeatedly. Rebooted and tried again. Same thing later. On the third reboot, the drive was no longer mountable... Did a xfs_repair, clearing the log and thankfully the drive was back and the files all seemed to be there. This drive is especially important as it houses all my Plex metadata, among other goods. Back to 6.19 and all well again. Got the idea that perhaps a fix in 6.21 was implemented (I did not see one via the changelog...) so did the upgrade again. Same thing...XFS complaining. This time I have a screenshot. I just want to confirm that this is XFS having a physical issue with one of the drives. If so, why does this not appear under 6.19? I also need to know which drive this actually is (md1). I did not capture a syslog or dump from the system as I did not want any further corruption like the last time. Has something been tweaked that a marginal drive is now getting flagged? Kev.
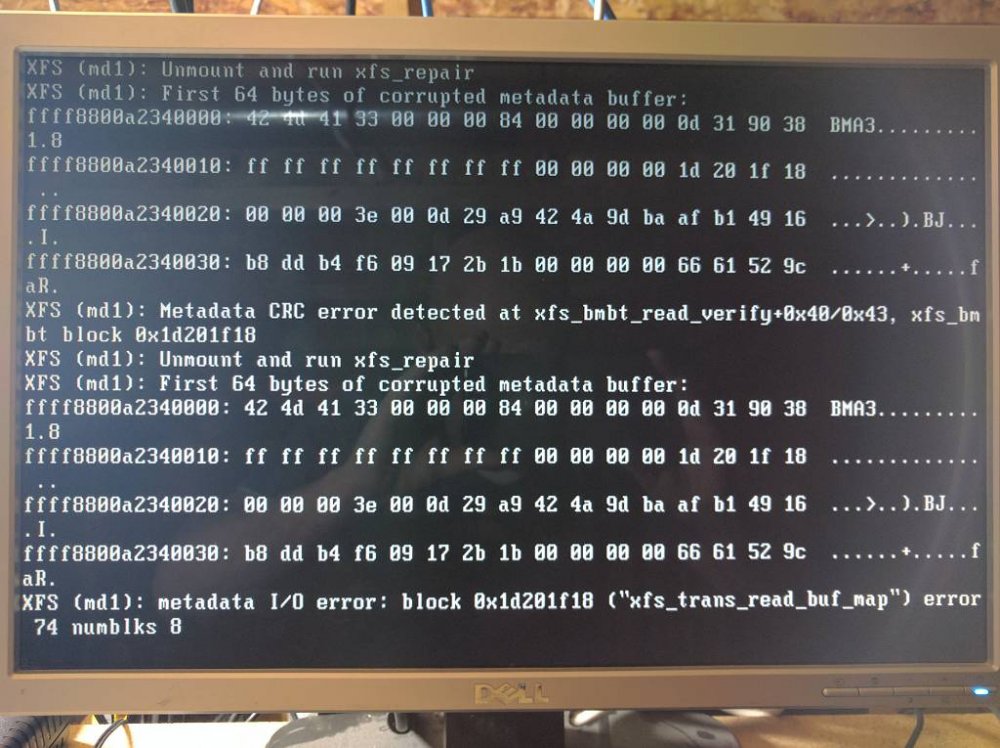
-
I should add that this is recent behavior and not sure if it is tied to my processor upgrade (Core 2 Duo -> Quad) and in the last week or so, very heavy inter-server transfers as I move from Reiser to XFS. I moved the USB stick to another port (motherboard port to external) and rebooted. Awaiting now... Kev.
-
Well, I removed the system status plugin. Finally failed w/o plugin, so we can assume it is safe. It did it right in front of me so I got a look at the log. From the attached, it looks the like server is resetting the USB. A quick attempt to access the USB via the network shows that it in fact is dismounted, hence all the plugins trying perhaps to permanently log things to the flash and failing...so I would assume. Next question - is this a symptom of failing hardware/usb port or the usb drive itself coming to an end? It is the original one that I have been using since day one...perhaps 6 years now. I will pull it and try another USB port. If it goes away, then I guess the port is wonky. Further fails and I guess we can move the key over to a new USB stick and see what that does? If still, then perhaps my MB is slowly fading away... Thoughts? Kev.
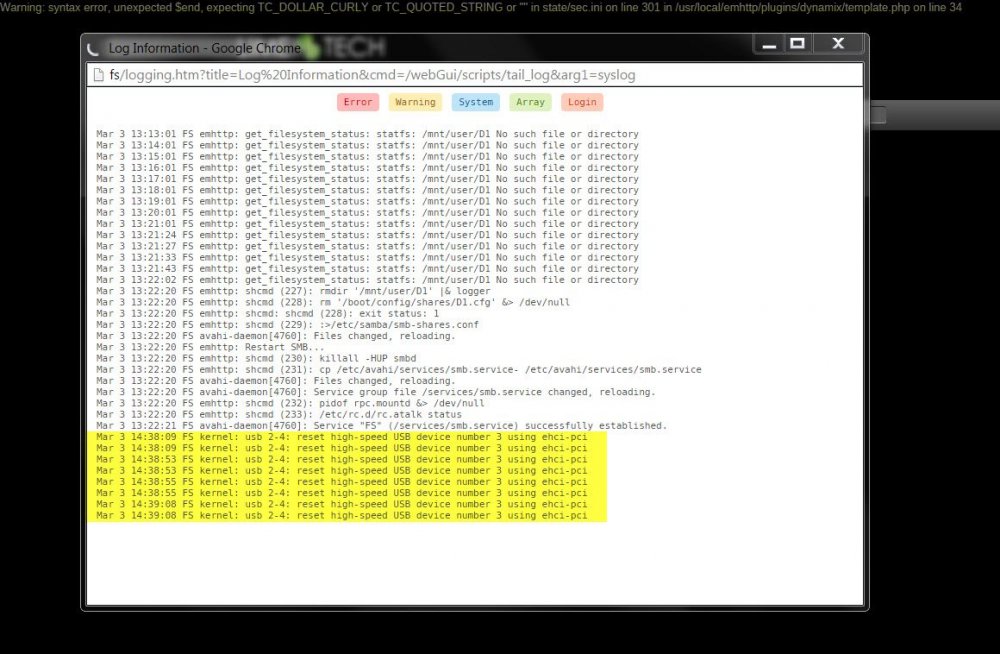
-
Well, I removed the hotfix plugin and it still failed this morning. Same thing as my last post. This time I could not capture a syslog or diagnostic; the browser just came up with a "404 file not found" upon retrieval of each log. I did manage to at least get the syslog from the system and copy it to a drive prior to reboot. Attached. Ugh! Kev. syslog.zip
-
I will do this right away. Results to follow. Kev.
-
Attached. This is now after a reboot so hopefully nothing has vanished. If it happens again, I will post the log right after fail. Kev. fs-diagnostics-20160301-0757.zip
-
Hello. I let the server sit and come back after some time to see nothing coming up but script errors. It looks like the dynamix stats script fails out and then everything follows? Have a look at the log and screenshots. This is recent behavior in the last few days. A reboot corrects the problem. Help?
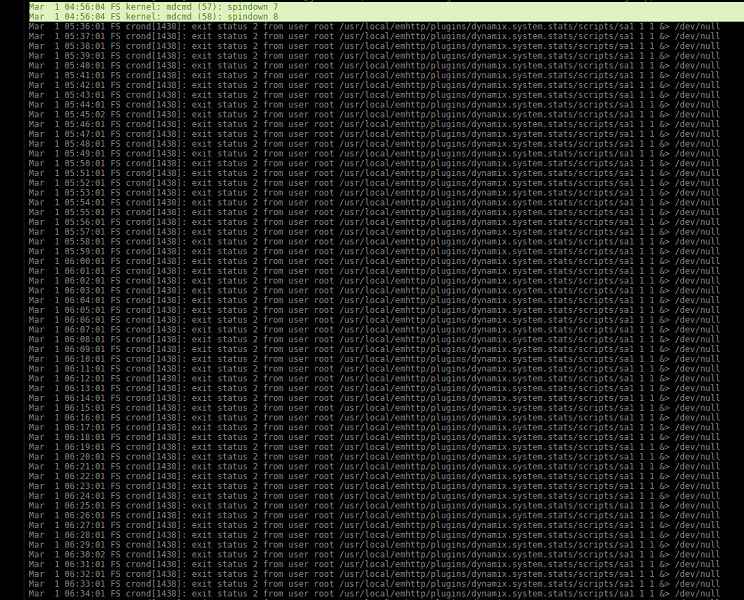
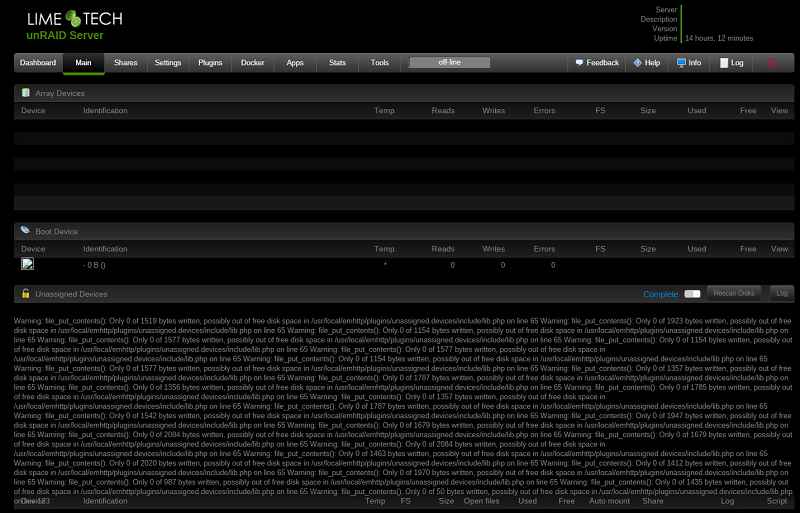
-
"shfs/user: shfs_fallocate: fallocate: (95) Operation not supported" and Plex
TDD replied to TDD's topic in General Support
I do have a lot of top-level shares, and had considered cleaning them up by burying them in one folder at the top instead. My docker runs on a normal drive, 20GB in size. I have been going through each drive and noting spurious folders, going back to the shares area to ensure that all shares are defined explicitly as include or exclude as needed to ensure nothing ends up elsewhere. I am in the midst of Reiser to XFS migration as well so it might cure itself as the folders are recreated? I am watching for this to see what happens. Many of the shares are set to either non-export or hidden so it is not so zany when I pull up a list of shares from the server... Kev. -
Hi all! I have been busy moving things around in my array as I leave ReiserFS for XFS. No problems. I have noticed that I still have a mix of 4k-aligned and unaligned MBRs. My solo 4TB is 4k; the others (a mix of 2, 1, and 0.75TB drives) are showing a mix of 4k aligned and not. I perhaps erroneously assumed that the reformat to XFS would by default 4k align things but it appears not. Questions are... 1) Any benefit to having them 4k or not? Peformance? I am more than sure my older 2TBs and before are non-AF drives. 2) To make them all 4k, I must emtpy them, preclear them, format again as XFS and it will force 4k? Is there a tool to run that shows conclusively which drives are AF and which are not? Thx! Kev.
-
"shfs/user: shfs_fallocate: fallocate: (95) Operation not supported" and Plex
TDD replied to TDD's topic in General Support
Well...I guess I do, including the disk shares. Only about half are exported to SMB. Just a lot of folders and breakdown therein. Music, for example under my SONOS is broken out into different folders based on content. Many folders are just for storage and hence get created in the shares (but again, not exported). Does the number of shares have any bearing? Again, it is only upon Plex access this particular directory structure. Kev. -
Hi all. I have seen a few posts about this in the forums but nothing has pointed me to a solution. I can reproduce these log entries every time. It happens when, via Plex (docker) accesses my "TV" share across two disks. Plex is set to access "/mnt/user/TV" and the share itself is set just fine to the disks in question and the two folders (both "TV"). Everything comes up as it should via Plex. It doesn't do this for other Plex libraries that are similarly configured across disks (movies, etc.) and through the /mnt/user side of things. Both disks that house the two folders have clean SMART reporting. It doesn't log this issue if I access /mnt/user/TV from the console, or via Windows, or any other way. Strictly a Plex thing. Nothing shows in the Plex logs either. I haven't moved all the shows to a single drive (and folder) and checked to see if it reproduces under this condition. Might be my next step. It doesn't seem to be interfering but I just don't like spurious log errors... Help? Diagnostic attached too. Kev. Feb 19 21:24:05 FS shfs/user: shfs_fallocate: fallocate: (95) Operation not supported Feb 19 21:24:05 FS shfs/user: shfs_fallocate: fallocate: (95) Operation not supported Feb 19 21:32:18 FS shfs/user: shfs_fallocate: fallocate: (95) Operation not supported Feb 19 21:32:18 FS shfs/user: shfs_fallocate: fallocate: (95) Operation not supported fs-diagnostics-20160219-2154.zip
-
I have seen many older DIMMs on ebay that are 16 chip...I assume they would be safe to use then? Steer away from anything 8 chip...? Kev.
-
Hi All. Still running my C2SEA - it just goes and goes so it says a lot about its stability. With it now seeing the latest 6.1.7 unraid and a few dockers, the original memory is getting a bit thin (4GB). Tried adding a couple more sticks of 2GB RAM and they don't work. My older DDR3 2GB ram from another machine does work. I suspect it has to do with the chip counts now...my older DIMMs are 16 chips total while the new ones are denser at 8 chips. The memory controller in the C2SEA must not like the new stuff. Is it as simple as sourcing out older DIMMs that have 16 chips vs the 8 now for the same speed, timings, etc. to get the upgrade? RAM descriptions are not too precise out in the marketplace I have discovered. Kev.
-
Plex and Folder Access (Individual Disk Folders vs. /user)
TDD replied to TDD's topic in General Support
I moved to 6 some time ago and set up dockers...love it. Makes 5 seem very archaic! For some reason, I completed overlooked the convenience of user shares from Plex. In fact, everything that I set up that was accessing data (Sonarr, etc.) with /diskX shares. Even all my directory setups for Docker are in /diskX format. Old habits die hard. I will move all references towards the /user space and hence manage all real folders within unRAID. I agree that it makes *much* more sense...I won't forget to keep editing the applications and their paths. So...all positives here and no negatives at all? Also, how do I shell into a Docker to see just what filesystem it is seeing? I have mappings in my Dockers for /mnt <-> /mnt/ but are they needed with this setup? Kev. -
Hi all. Question for those in the know. Many of my Plex libraries and spread across multiple disks. For TV shows for example, I have Plex set to access each folder separately from the disk level shares: /disk1/TV /disk3/TV /disk4/TV etc. One can access the entire structure from the /user/TV folder as well, presenting one listing of everything of course. My question is: With Plex knowing the exact location of every show in situation 1 above, specifically which disk any show resides in, I imagine it doesn't need to spin up any of the other disks to access it. If I remove the disk level paths and replace it with the /user/TV path, will Plex (and unRAID) spin up *all* the drives to access any particular show on one disk? The /user paths are great in that any future additions/edits are done in the unRAID domain so one never needs to touch Plex by editing paths. The disadvantage would appear to be unnecessarily spinning up disks. Is there a better way? Should one always use the /user area? Kev.
-
I found the relevant post. Makes sense and I agree that the wording could be tweaked. Thx for heads up. Going to proceed and get the array going! Reference: http://lime-technology.com/forum/index.php?topic=27961.msg247998#msg247998 Kev.
-
Syslog attached as zip... TDD. syslog.zip
-
Hello all! Just did the upgrade from my very stable 4.7 to 5.0. Followed instructions to the letter...backed up old install, reformatted, copied 5.0 over with relevant config files. All boots well and all drives are in correct positions - green balls abound. I check each drive before start the array and each says that the MBR: is unaligned and the file system type is unknown. All my drives are <2TB and were formatted long ago so I can accept the unaligned portion. What is up with it not recognizing ReiserFS? Am I safe to start the array? Just for note...assuming I want all to be 4k aligned, I will have to copy all data off each drive, reformat that drive, and copy back per drive? Thx for help in this! Kevin.
-
I thought as much, so thanks for the verification. The parity-swap worked as expected and I am back online again. Kev.
-
Hello! In the absence of posting screen shots, i'll do my best to explain my goal here. I have a 9 disk array. Disk 2 has recently become suspect with errors as reported on the status screen. This unit is a Seagate 750G. I now have a replacement Seagate 2TB drive ready for the swap. The data on the suspect drive has been moved to another location just to be safe so it does not matter if it really rebuilds or not. Anyways...my parity disk, a WD 2TB EADS is, from what I can tell spec-wise, slower than the new 2TB drive coming into the array...a Seagate 5900 RPM unit. Believing that one should have their fastest drive as parity, I would like to: 1) Make the WD 2TB parity disk the replacement for the failed Seagate 750G, and 2) Place the new Seagate 2TB drive into the parity position. Said new Seagate 2TB is getting a torture test now via the preclear script. I don't believe I can do both at once, so my steps would be... a) Disconnect dead drive b) "Restore" and redo parity, effectively removing the disk from the array c) Connect new 2TB drive and reassign parity to this unit d) Redo parity e) Add what was the old 2TB parity disk back into the logical slot that was the dead 750G f) Redo parity...and done. Is there a shorter way? Am I overdoing this? Thx! Kevin.
-
Removing a user share but keeping data/directory present?
TDD replied to TDD's topic in General Support (V5 and Older)
I suppose that works but it is a poor band-aid. It should be a simple fix. Perhaps I will be better off to use samba-config only shares as others have done successfully... Kev. -
Removing a user share but keeping data/directory present?
TDD replied to TDD's topic in General Support (V5 and Older)
Joe: I see how the mechanism works...it follows the directory around, even if I make a copy and place it on another drive in the array. Handy I suppose as it ensures the share is always valid within unraid...but... I still need to make the user share disappear and keep the data behind. Is this impossible? Kev. -
Removing a user share but keeping data/directory present?
TDD replied to TDD's topic in General Support (V5 and Older)
Nope - same deal. Tried that. There has to be an easy fix here. Windows even allows for this behavior Kev. -
Hello all! I am pretty sure this has been addressed prior but I didn't seem to find an answer. Let's try again... I made some directories within my unraid pool. Most of the time I just reference them by jumping into "disk1", "disk2", etc., and going from there. For convenience, I made a couple of user shares named the same as the existing directories already, so that they will show up as a valid share. Works fine. I now cannot eliminate those shares. The directories are not empty so the trick of erasing the name from the shares screen and applying that does not work...of course, as by design. If I rename the folder then try the above at the share screen, unraid updates the name of the share. Folder "A1" on disk and user share "A1" to start. Rename A1 on disk to A2. Erase A1 from share screen and apply...poof! Now shows as A2. By design I suspect. Tried making another folder and copying the data into that, making the first one now empty. Delete the share name. Unraid then comes back with the new folder name. What am I missing here? For note, these are all on the same physical disk if that makes a difference. Kevin.





