

Timbiotic
-
Posts
208 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Timbiotic
-
[SOLVED] Hung gui during parity swap/upgrade
Timbiotic replied to Timbiotic's topic in General Support
was hoping the format might clear it, but i also figured rebuilding a blank disk wouldn't take as long. Is that wrong? Does it not matter if its blank or full for rebuild? -
I got array started using new config and preserve all disks. I then unassigned the parity I then used itimpi's suggestion to format the old parity with XFS I am now copying all of the remaining 1tb drives to the formatted old parity drive. When this is finished i will shut down and swap out the 1tb for the larger drives Before i add back the parity drive and resync, is there something i should do first to make sure the copied data is good? Or does unbalance include this? I will have the old drives on a shelf in case I guess. Thanks for all of the assistance, i LOVE this community.
-
Good to know! Do they stick with the disk smart history permanently? Because I havent seen any new ones in the life of that disk. Either way i replaced a SATA with a SAS so all new cables.
-
[SOLVED] Hung gui during parity swap/upgrade
Timbiotic replied to Timbiotic's topic in General Support
copy/move seems faster than rebuild. That is why i usually go with unbalance and preferred the swap method. It took me 9 hours to copy the parity, rebuild / resync usually takes longer. Might be different in different setups but that is my experience. -
I cannot fit all the disk in the case. So I am replacing disks. I guess i could rsync to the current other 3tb disks first, but unbalance seems easier and checks permissions etc.. for potential issues. I have backups of my critical stuff, but if I am curious about this. If i copy using unbalance how does that work with the shares? With duplication on disks? I mean I will remove the old disks eventually but while there is a copy wont that cause issues? I have uploaded diagnostics. The only issues i know of is the data disk i already pulled had 3 CRC errors. Hence me getting rid of it first. Also since upgrading to 6.4.1 and using the new ip docker feature i have had call traces and kernel panics. It seems a few others have had the same issue. I have opened a bug report on it. lillis.69.mu-diagnostics-20180219-1039.zip
-
This sounds good, but i cannot wrap my mind around it. Are you saying unbalance all of the 1tb drives now, then remove them? Currently my array will not start unless i run the parity copy again, or set a new config. So in your scenario: 1. Run New config and choose "preserve all drives" 2. Start Array 3. Unbalance all 1tb drives 4. stop array and shut down 5. replace 1tb drives with new drives 6. Start array and do a new config? Would it make sense to disable parity completely when unbalancing for speed since it will need to be rebuilt?
-
So doing a new config wouldn't save time? Is copy faster than rebuilding parity? I also have two other 4tb disk, and a 3tb disk, i want to swap another three 1tb disks with. I also responded in the other thread i did have a disk i removed. I am in process of swapping out my 1tb drives. I just wanted as little array downtime as possible. Hence unbalance. It lets me clear disks and keep the array up. Am I going about this wrong? Basically i want little downtime, I also want to upgrade 4 x 1tb drives (already pulled one in the parity swap procedure). My plan was to add, unbalance, add, unbalance, etc... But when i unbalance i never move the data to the 1tb drives. Is there a more efficient way of doing this?
-
[SOLVED] Hung gui during parity swap/upgrade
Timbiotic replied to Timbiotic's topic in General Support
Maybe we arent connecting. I started with 3tb Parity 1tb Data Disk 4tb New disk. I have an 8 disk array. I dont have room in my case to keep the 1tb disk. So i followed the parity swap procedure to get rid of the 1tb data disk, move the 3tb parity to its spot, and make the 4tb the new parity. I unbalanced first because i am paranoid and didnt want to lose data. -
I am glad you responded cause I have my finger on the new config using "preserve all disks" hoping it would make it so it can start again and use the newly copied 4tb as parity. I wanted to format the old parity with no data because I want to convert from reiser to xfs. I thought just unassigning would allow me to do this. I should have started the array first i guess. I wanted to do the parity swap so my new parity doesn't need to be rebuilt from scratch
-
I got done with the parity swap procedure but wanted to format the old parity drive so i unassigned it before starting the array. Now the array wont start because of missing disks, but if i put the disk back in, it wants to run the copy again. Even though it is complete. Is there a way I can force it to start and not copy again?
-
[SOLVED] Hung gui during parity swap/upgrade
Timbiotic replied to Timbiotic's topic in General Support
It finished just now. But i realized this from another post saying to check the syslog. For future wanders you can check completion there using "cat /var/log/syslog" Feb 18 22:29:37 lillis emhttpd: copy: disk7 to disk0 running Feb 19 00:00:01 lillis Plugin Auto Update: Checking for available plugin updates Feb 19 00:00:03 lillis Plugin Auto Update: Auto Updating community.applications.plg Feb 19 00:00:03 lillis root: plugin: running: anonymous Feb 19 00:00:03 lillis root: plugin: running: anonymous Feb 19 00:00:04 lillis root: plugin: creating: /boot/config/plugins/community.applications/community.applications-2018.02.16.txz - downloading from URL https://raw.github.com/Squidly271/community.applications/master/archive/community.applications-2018.02.16.txz Feb 19 00:00:04 lillis root: plugin: checking: /boot/config/plugins/community.applications/community.applications-2018.02.16.txz - MD5 Feb 19 00:00:04 lillis root: plugin: running: /boot/config/plugins/community.applications/community.applications-2018.02.16.txz Feb 19 00:00:04 lillis root: plugin: running: anonymous Feb 19 00:00:04 lillis Plugin Auto Update: fix.common.problems.plg version 2018.02.18 does not meet age requirements to update Feb 19 00:00:04 lillis Plugin Auto Update: NerdPack.plg version 2018.02.17 does not meet age requirements to update Feb 19 00:00:05 lillis Plugin Auto Update: user.scripts.plg version 2018.02.16 does not meet age requirements to update Feb 19 00:00:05 lillis Plugin Auto Update: Community Applications Plugin Auto Update finished Feb 19 07:42:50 lillis login[4320]: ROOT LOGIN on '/dev/tty1' Feb 19 07:44:41 lillis emhttpd: copy: disk7 to disk0 completed Feb 19 07:46:15 lillis kernel: usb 3-2: USB disconnect, device number 4 -
Version 6.4.1: I have followed the procedure to upgrade/swap the parity drive. Basically upgrading from 3tb parity and 1tb drive to 4tb parity and moving current parity to other spot. Everything went well until I hit the "copy" spot. It started copying but now is no longer responsive via gui. I can SSH or console and ping it still fine. Should I wait or fat finger it and let it just build parity from scratch? Thankfully i unbalanced all data of the data drive first. Is there a way i can check the progress or even if it is still running via terminal?
-
Default go script for unraid v5?
Timbiotic replied to bigup's topic in General Support (V5 and Older)
Is this still true for v6? I want to cleanup my go script -
The link to the manual is offline, did you ever get this going and can you post an example of your config script for multiple UPS?
-
Bump first time since I’ve had this server I had a crash today. Pretty sure it has something to do with the new 6.4.1 kernel. “kernel panic not syncing fatal exception in interrupt” was the error I saw when it froze. Any ideas? Do I open a ticket? The only change I’ve done was to enable AMD cool and quiet and that was just so a CPU driver would load as 6.4.1 didn’t seem to be loading my CPU driver.
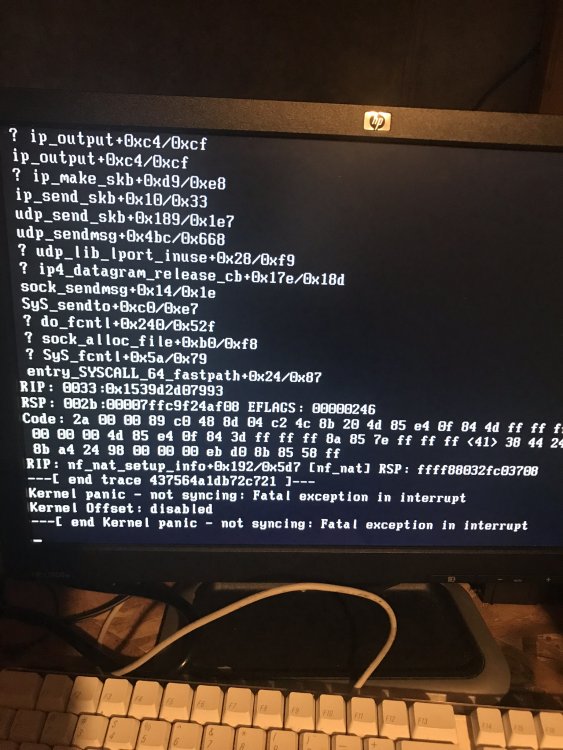
-
Ok so how do I tell why it was flagged? I see a couple memory comments in log as well as a ton of issues with the preclear plugin which I’ve removed
-
Can you post your xml? Did you use virtual box or the built in VM in unRAID?
-
I deleted the plugin preclear that had all the errors but i dont really see any out of memory errors in the logs. Could something else have caused it or should i go ahead and lower the " vm.dirty_background_ratio and vm.dirty_ratio, "?
-
i see elsewhere call traces mean memeory errors but i am only showing 37% used
-
Recently upgraded to 6.4 then to 6.4.1-rc1. Got the call traces error so posting my diagnosis to see why. lillis.69.mu-diagnostics-20180202-1331.zip
-
Manually install container? Smartthings MQTT Bridge
Timbiotic replied to digiblur's topic in Docker Engine
I am trying this too but dont know how to get rid of what i did in the cli. You said yours was "orphaned" how did you find that even? I ran the following and cannot find it now. root@lillis:~# docker pull stjohnjohnson/smartthings-mqtt-bridge Using default tag: latest latest: Pulling from stjohnjohnson/smartthings-mqtt-bridge f49cf87b52c1: Already exists 7b491c575b06: Already exists b313b08bab3b: Already exists 51d6678c3f0e: Already exists da59faba155b: Pull complete 7f84ea62c1fd: Pull complete 2b2a141f66aa: Pull complete d4999905d7b7: Pull complete b42269c6111f: Pull complete 8ee70ab0ef58: Pull complete 74de94518ed1: Pull complete 485911022287: Pull complete Digest: sha256:7a4a002c7fe76c7de32b35106b5e9264e59b08dd68c91c6a4d960dd694690002 Status: Downloaded newer image for stjohnjohnson/smartthings-mqtt-bridge:latest -
Is there any plugin or docker that is similar to the iOS app FING or other network analyzer tool? Basically identifies hosts on your network via dns/MAC address/IP? thanks, timbiotic
-
/bump anyone settle on a solution yet? I still have some time left on crashplan but am getting nervous.
-
Unable to run DNS server as dnsmasq is listening on port 53
Timbiotic replied to tuxbass's topic in VM Engine (KVM)
Where is the config file for the unraid one? -
I have milight/limitlessled bulbs that I would love to get working with Alexa. The eynio skill in Alexa claims it does it. Can someone port the app as a plugin or docker? I'd be really appreciative. Link to downloads/manual https://eynio.com/wp/downloads/
