

coppit
-
Posts
498 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by coppit
-
-
Just to follow up on this, in case anyone else has similar problems. mprime would warn about hardware errors within 5 seconds of starting. (The memtest ran a complete test without any errors.)
I did two things that helped:
1) I saw a video where Intel CPUs would become unstable if the cooler was tightened too much on an Asrock Tai Chi motherboard. I removed my cooler and reinstalled, tightening just until I felt resistance. That stopped mprime from failing quickly. However after about 5 minutes I still got another error. The parity check after doing this found about 60 errors...
2) I increased my CPU voltage by two steps. (.10 V I think.) That seems to have removed that last of the instability.
-
 1
1
-
-
Okay, finally a breakthrough. The server hanged in the BIOS bootup screen.
My theory is that there is a problem with my hyperthreaded CPU cores 0-15. 16-31 are allocated to my VMs. The lower cores are used by docker and UNRAID. Disabling docker basically idles those cores since UNRAID doesn't use much CPU, which is why things are stable in that configuration.
I'm going to try disabling hyperthreading to see if that helps. I might have to replace the CPU. Or maybe the motherboard. Ugh.
Since my CPU temps never go above 41C even under load, I don't think it's overheating.
-
It's been another 5 days without a crash. This time I changed my NPM to use bridge networking instead of br0.
Now I'm going to enable PiHole, which uses br0. If it crashes again then we'll know it's related to br0.
-
I woke up to a hung server. It seems Docker related. Next I'll try enabling specific containers, starting with Plex due to popular demand.
Any other suggestions on how to debug this would be welcome.
-
On 1/18/2024 at 4:07 AM, JorgeB said:
It could, hence why I mentioned:
Oops. I missed that. Sorry. I disabled the Docker service, and the server ran for 5 days without any crashes. Before this, the longest it ran was about 2.5 days before a crash. Now I'm going to re-enable Docker, but only use containers with bridge or host networking. I suspect it's related to br0, so I've disabled NGINX Proxy manager and two PiHole containers. I'll let this soak for another 5 days.
One reason I suspect br0 is that I've had trouble with NPM being able to route requests to my bridge mode containers. When I hopped into one of the containers, it couldn't ping the server. I figured I would debug this later, but I mention it in case it might be relevant.
-
Okay, I ran it in safe mode for several days. After 53 hours it crashed. Syslog attached.
I noticed that docker was running. Could it be related to that?
I'm getting intermittent warnings about errors on one of my pooled cache drives. Could that cause kernel crashes?
I replaced my power supply, increased all my fans to max, and passed Memtest86. CPU temp is 29°C, and the motherboard is 37°C. Should I try replacing the CPU? Motherboard? Is there a way to isolate the cause?
-
Here's another from last night. Instead of a null pointer dereference, this time there was a page fault for an invalid address.
-
I'm looking for some help with my server hanging up. When it happens while I'm using it, things start failing one by one. Maybe the internet fails, but I can still ssh into the server from my VM. Then the VM hangs. Then I can't reach the web UI from my phone. At that point nothing responds. I have to power cycle the server.
But more often I come to the server and it's just frozen.
This was happening 1-2 times per day. My memory passes memcheck86+, and I replaced the power supply with no effect. I installed the driver for my RTL8125 NIC (even though my crashes don't seem exactly the same), and it had no effect.
I upgraded to 6.12.6 pretty much as soon as it came out. The crashes started happening mid-December. I don't recall making any server changes around that time, but perhaps I did.
I changed my VMs from br0 to virbr0 as an experiment, and my crashes seem to happen only once every 2-3 days now. (But now the VMs can't use PiHole DNS because they can't reach docker.) So maybe the crashes are still related to my NIC?
Attached is a syslog with a couple of call traces in it, as well as my system diagnostics. Any ideas would be appreciated.
-
@Craig Dennis did you resolve this? How?
-
Maybe someone on 6.12.4 who set up a VM with vhost0 networking as per the release notes could post their routing table? That way I could compare. This seems very suspicious to me:
IPv4 10.22.33.0/24 vhost0 0 IPv4 10.22.33.0/24 eth0 1003
-
Hi all,
I recently upgraded to 6.12.4, and am trying to sort out networking of my server, VMs, WireGuard, and docker containers.
My server can't ping 8.8.8.8, which I'm guessing is due to a broken routing table. My home network is 10.22.33.X, and my wireguard network is 10.253.0.X.
Can someone with more networking experience help me debug this routing issue for 8.8.8.8?
Also, I may have added the 10.253.0.3, .5, .6, .7, .8 while trying to get Wireguard to be able to see the VMs. Can I remove them?
PROTOCOL ROUTE GATEWAY METRIC IPv4 default 10.22.33.1 via eth0 1003 IPv4 10.22.33.0/24 vhost0 0 IPv4 10.22.33.0/24 eth0 1003 IPv4 10.253.0.3 wg0 0 IPv4 10.253.0.5 wg0 0 IPv4 10.253.0.6 wg0 0 IPv4 10.253.0.7 wg0 0 IPv4 10.253.0.8 wg0 0 IPv4 172.17.0.0/16 docker0 0 IPv4 172.31.200.0/24 br-e5184ce4c231 0 IPv4 192.168.122.0/24 virbr0 0
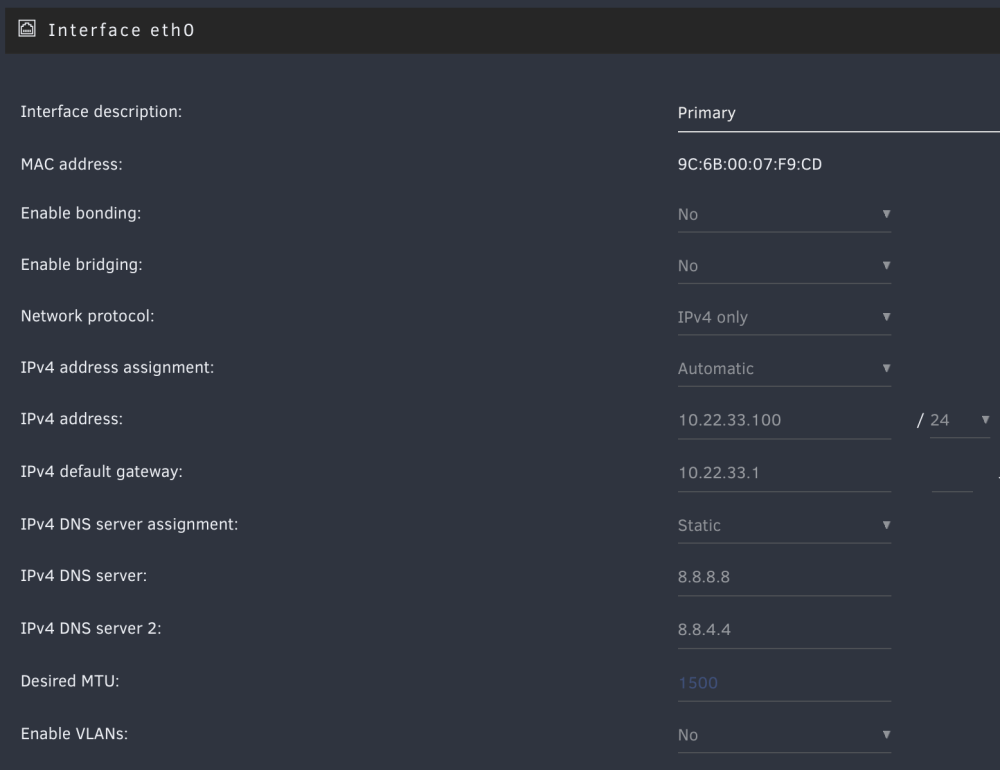
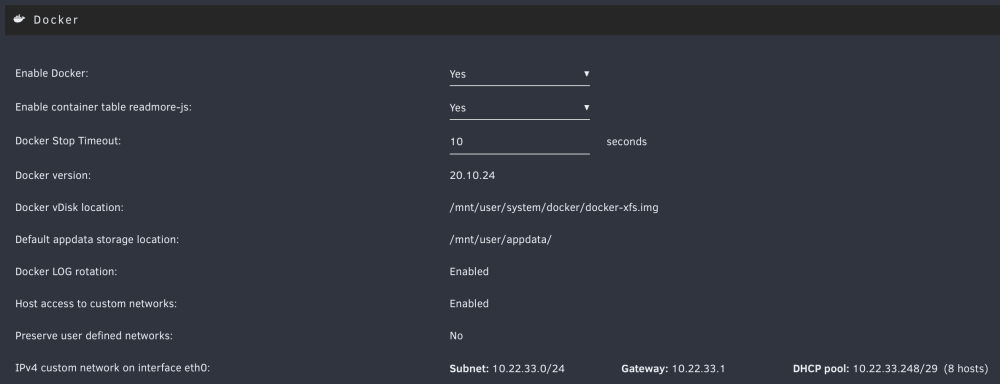

System diagnostics attached.
-
Hi, I'm trying to pass the "UHD Graphics 770" from my "13th Gen Intel(R) Core(TM) i9-13900K" to a Windows 10 VM. At first I tried passing the physical GPU directly to the VM, but I got the Code 43 error.
I don't know if it's relevant, but I've been running two gaming VMs with discrete GPUs for a while now. I'm trying to set up a headless VM with the integrated GPU.
Then I found this thread, and thought I'd try passing a virtualized iGPU. I've unbound the VFIO from 00:02.0, and installed this plugin. But it looks like the driver says my iGPU is not supported?
$ dmesg | grep i915 [ 48.309332] i915 0000:00:02.0: enabling device (0006 -> 0007) [ 48.310076] i915 0000:00:02.0: [drm] VT-d active for gfx access [ 48.310102] i915 0000:00:02.0: [drm] Using Transparent Hugepages [ 48.311491] mei_hdcp 0000:00:16.0-b638ab7e-94e2-4ea2-a552-d1c54b627f04: bound 0000:00:02.0 (ops i915_hdcp_component_ops [i915]) [ 48.312329] i915 0000:00:02.0: [drm] Finished loading DMC firmware i915/adls_dmc_ver2_01.bin (v2.1) [ 48.978485] i915 0000:00:02.0: [drm] failed to retrieve link info, disabling eDP [ 49.067476] i915 0000:00:02.0: [drm] GuC firmware i915/tgl_guc_70.bin version 70.5.1 [ 49.067481] i915 0000:00:02.0: [drm] HuC firmware i915/tgl_huc.bin version 7.9.3 [ 49.070461] i915 0000:00:02.0: [drm] HuC authenticated [ 49.070910] i915 0000:00:02.0: [drm] GuC submission enabled [ 49.070911] i915 0000:00:02.0: [drm] GuC SLPC enabled [ 49.071369] i915 0000:00:02.0: [drm] GuC RC: enabled [ 49.071980] mei_pxp 0000:00:16.0-fbf6fcf1-96cf-4e2e-a6a6-1bab8cbe36b1: bound 0000:00:02.0 (ops i915_pxp_tee_component_ops [i915]) [ 49.072029] i915 0000:00:02.0: [drm] Protected Xe Path (PXP) protected content support initialized [ 49.073624] [drm] Initialized i915 1.6.0 20201103 for 0000:00:02.0 on minor 0 [ 49.137484] i915 0000:00:02.0: [drm] fb0: i915drmfb frame buffer device [ 49.154410] i915 0000:00:02.0: [drm] Unsupported device. GVT-g is disabledThanks for any help!
-
Thanks @strend. I already had "allow access to custom networks" enabled, but NPM required privileged as well.
-
Updating to 6.12.1 brought br0 back. I guess I'll chalk this up to 6.12.0 RC weirdness.
-
Hi all, recently I noticed my docker containers weren't auto-starting. I figured it might be a glitch in the 6.12.0 RCs, and didn't think much about it. But yesterday I noticed that my PiHole containers aren't starting even after I click "start all". Digging a little more, I found that they had lost their IP addresses, and that br0 wasn't listed in the available networks:
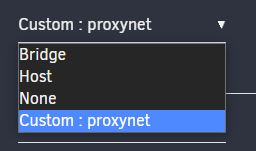
I tried rebooting, and also following the docker network rebuild instructions in this thread, but neither helped.
I'll attach my system diagnostics. I'll also attach my docker and network settings. Any help would be appreciated.
Things I've done recently: installed various 6.12.0 RCs, installed a gluetun container to experiment with (which created a proxynet I think), booted the computer with the network cable unplugged.
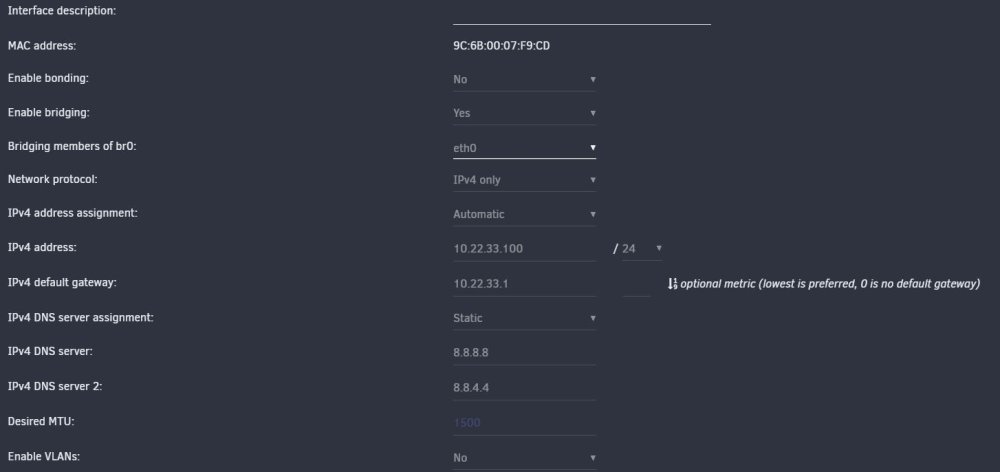
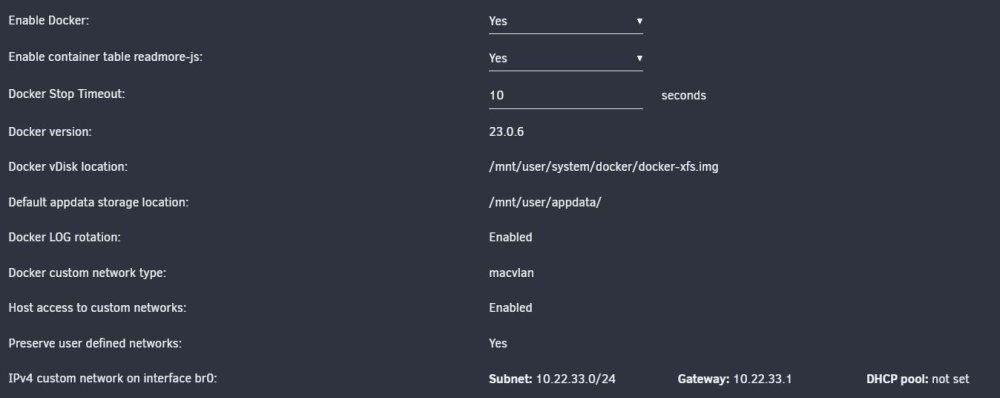
-
Despite doing all the tweaks for VM performance, I was still having intermittent issues with latency spikes. Most of the time I could play games in Windows 10 without any issues, but occasionally there would be a hiccup that would knock my audio out. I had to switch audio devices back and forth to re-initialize it.
Here's a list of all the things I can remember doing that helped:
- Use the isolcpus kernel option to prevent processes from running on my VM CPUs
- Pin the CPUs to the VMs in the XML config
- Make sure all Windows devices were using MSI interrupts
I tried a bunch of other things that didn't help at all.
Then I ran across /proc/interrupts. It showed that even with CPUs isolated and no VMs running, Linux was still putting IRQs on my so-called "isolated" CPUs. I wrote a tool (attached) to reformat the output to show the total count of interrupts on each CPU, and their names and relative contributions. Here's the output of the tool after running my VMs. I separated CPUs 15-22 and 23-31, as those are the ones allocated to my two Windows VMs.
CPU0: 213497575 [132 (nvme0q0 32), 156 (vfio-msix[5](0000:03:00.0) 2), LOC (interrupts 198826728), RES (interrupts 233396), CAL (interrupts 14133666), TLB (shootdowns 303665), MCP (polls 86)] CPU1: 230485540 [128 (xhci_hcd 1033), LOC (interrupts 207630475), RES (interrupts 9997854), CAL (interrupts 12680386), TLB (shootdowns 175705), MCP (polls 87)] CPU2: 57069471 [133 (nvme0q1 1534), 152 (vfio-msix[1](0000:03:00.0) 4), LOC (interrupts 24404918), RES (interrupts 47193), CAL (interrupts 32449829), TLB (shootdowns 165906), MCP (polls 87)] CPU3: 12970342 [130 (ahci[0000:00:17.0] 2189433), LOC (interrupts 7598861), RES (interrupts 49447), CAL (interrupts 3119447), TLB (shootdowns 13067), MCP (polls 87)] CPU4: 42690394 [128 (xhci_hcd 85262), 157 (vfio-msix[6](0000:03:00.0) 4), LOC (interrupts 20370578), IWI (interrupts 2), RES (interrupts 42767), CAL (interrupts 22032259), TLB (shootdowns 159435), MCP (polls 87)] CPU5: 3718224 [16 (vfio-intx(0000:06:00.0) 64833), 130 (ahci[0000:00:17.0] 43065), 134 (nvme0q2 1295), LOC (interrupts 2378827), RES (interrupts 26167), CAL (interrupts 1195047), TLB (shootdowns 8903), MCP (polls 87)] CPU6: 38643823 [LOC (interrupts 21176519), IWI (interrupts 1), RES (interrupts 44285), CAL (interrupts 17282585), TLB (shootdowns 140346), MCP (polls 87)] CPU7: 3080525 [16 (vfio-intx(0000:06:00.0) 8258), 130 (ahci[0000:00:17.0] 13116), 135 (nvme0q3 837), LOC (interrupts 2152493), RES (interrupts 24560), CAL (interrupts 873251), TLB (shootdowns 7923), MCP (polls 87)] CPU8: 29710513 [129 (mei_me 49), 153 (vfio-msix[2](0000:03:00.0) 4), LOC (interrupts 12704086), IWI (interrupts 11), RES (interrupts 29275), CAL (interrupts 16728509), TLB (shootdowns 248492), MCP (polls 87)] CPU9: 3580425 [128 (xhci_hcd 26139), 136 (nvme0q4 678), 159 (vfio-msi[0](0000:01:00.0) 42180), LOC (interrupts 952215), RES (interrupts 23191), CAL (interrupts 2528085), TLB (shootdowns 7850), MCP (polls 87)] CPU10: 30773164 [130 (ahci[0000:00:17.0] 501096), LOC (interrupts 11560706), IWI (interrupts 7), RES (interrupts 31580), CAL (interrupts 18427101), TLB (shootdowns 252587), MCP (polls 87)] CPU11: 5620428 [131 (eth0 615637), 132 (nvme0q0 38), 137 (nvme0q5 4155), LOC (interrupts 1188584), RES (interrupts 24245), CAL (interrupts 3779950), TLB (shootdowns 7732), MCP (polls 87)] CPU12: 70693705 [148 (i915 185), LOC (interrupts 13170345), IWI (interrupts 5), RES (interrupts 35803), CAL (interrupts 57299597), TLB (shootdowns 187683), MCP (polls 87)] CPU13: 7612080 [131 (eth0 10553), 132 (nvme0q0 21870), 138 (nvme0q6 820), LOC (interrupts 1542426), RES (interrupts 22332), CAL (interrupts 6004952), TLB (shootdowns 9040), MCP (polls 87)] CPU14: 99064221 [128 (xhci_hcd 293), 154 (vfio-msix[3](0000:03:00.0) 2), LOC (interrupts 15491637), RES (interrupts 36128), CAL (interrupts 83350964), TLB (shootdowns 185110), MCP (polls 87)] CPU15: 8032905 [132 (nvme0q0 24), 139 (nvme0q7 368), LOC (interrupts 2738775), RES (interrupts 26176), CAL (interrupts 5258001), TLB (shootdowns 9474), MCP (polls 87)] CPU16: 95549070 [163 (vfio-msi[0](0000:01:00.1) 67), LOC (interrupts 81796090), RES (interrupts 20017), CAL (interrupts 13732327), TLB (shootdowns 482), MCP (polls 87)] CPU17: 18215426 [140 (nvme0q8 329811), 151 (vfio-msix[0](0000:03:00.0) 22), LOC (interrupts 16768877), RES (interrupts 746), CAL (interrupts 1002437), TLB (shootdowns 1106), MCP (polls 87), PIN (event 112340)] CPU18: 2578003 [152 (vfio-msix[1](0000:03:00.0) 26), 159 (vfio-msi[0](0000:01:00.0) 1608), LOC (interrupts 2267997), RES (interrupts 93), CAL (interrupts 250481), TLB (shootdowns 252), MCP (polls 87), PIN (event 57459)] CPU19: 7969434 [153 (vfio-msix[2](0000:03:00.0) 3), LOC (interrupts 3254584), RES (interrupts 94), CAL (interrupts 4017610), TLB (shootdowns 471), MCP (polls 87), PIN (event 696585)] CPU20: 3768833 [8 (rtc0 1), 154 (vfio-msix[3](0000:03:00.0) 12), 162 (vfio-msi[0](0000:00:1f.3) 761), LOC (interrupts 2876639), RES (interrupts 33), CAL (interrupts 598201), TLB (shootdowns 284), MCP (polls 87), PIN (event 292815)] CPU21: 8077829 [155 (vfio-msix[4](0000:03:00.0) 2), LOC (interrupts 3893519), RES (interrupts 84), CAL (interrupts 2024219), TLB (shootdowns 485), MCP (polls 87), PIN (event 2159433)] CPU22: 3475586 [156 (vfio-msix[5](0000:03:00.0) 7), LOC (interrupts 2781680), RES (interrupts 78), CAL (interrupts 450941), TLB (shootdowns 250), MCP (polls 87), PIN (event 242543)] CPU23: 83357830 [143 (nvme0q11 124217), 157 (vfio-msix[6](0000:03:00.0) 18), LOC (interrupts 81715105), RES (interrupts 608), CAL (interrupts 1517439), TLB (shootdowns 356), MCP (polls 87)] CPU24: 15859395 [LOC (interrupts 15703633), RES (interrupts 99), CAL (interrupts 140581), TLB (shootdowns 705), MCP (polls 87), PIN (event 14290)] CPU25: 5490743 [LOC (interrupts 5456928), RES (interrupts 103), CAL (interrupts 27299), TLB (shootdowns 235), MCP (polls 87), PIN (event 6091)] CPU26: 5389008 [LOC (interrupts 5132122), RES (interrupts 57), CAL (interrupts 233201), TLB (shootdowns 99), MCP (polls 87), PIN (event 23442)] CPU27: 5716421 [LOC (interrupts 5644566), RES (interrupts 62), CAL (interrupts 59173), TLB (shootdowns 98), MCP (polls 87), PIN (event 12435)] CPU28: 6081679 [LOC (interrupts 5993507), RES (interrupts 104), CAL (interrupts 66777), TLB (shootdowns 291), MCP (polls 87), PIN (event 20913)] CPU29: 6120828 [LOC (interrupts 6063599), RES (interrupts 109), CAL (interrupts 46776), TLB (shootdowns 310), MCP (polls 87), PIN (event 9947)] CPU30: 11159 [LOC (interrupts 1070), CAL (interrupts 10002), MCP (polls 87)] CPU31: 11116 [LOC (interrupts 1068), CAL (interrupts 9961), MCP (polls 87)]Researching this issue led me to this bug report about the unsuitability of Linux for running realtime workloads on isolated CPUs, because the interrupts would introduce unpredictable jitter. (Sound familiar?) That bug report has a lot of things that don't apply to UNRAID, since they're running a realtime kernel. (kthread_cpus sounds great for helping with isolation, as does the managed_irq parameter to the isolcpus option.)
But one thing that we can do is enable nohz_full. This tells the kernel to use less aggressive scheduling-clock interrupts to certain CPUs, provided that they aren't running more than one process. (This is the case with our pinned CPUs.) For more information, see here.
Using this feature is simple. Just use the same isolcpus in the nohz and nohz_full kernel options:
isolcpus=16-31 nohz=on nohz_full=16-31I set my VMs to not auto-start, and rebooted UNRAID. This is the result:
CPU0: 211326 [LOC (interrupts 159770), RES (interrupts 14287), CAL (interrupts 31688), TLB (shootdowns 5580), MCP (polls 1)] CPU1: 263785 [LOC (interrupts 227258), RES (interrupts 14634), CAL (interrupts 18335), TLB (shootdowns 3556), MCP (polls 2)] CPU2: 133637 [LOC (interrupts 92213), RES (interrupts 1351), CAL (interrupts 33165), TLB (shootdowns 6906), MCP (polls 2)] CPU3: 44003 [LOC (interrupts 24973), RES (interrupts 867), CAL (interrupts 15688), TLB (shootdowns 2473), MCP (polls 2)] CPU4: 101902 [LOC (interrupts 72210), RES (interrupts 1493), CAL (interrupts 20602), TLB (shootdowns 7595), MCP (polls 2)] CPU5: 37533 [134 (nvme0q2 31), LOC (interrupts 22811), RES (interrupts 790), CAL (interrupts 11852), TLB (shootdowns 2047), MCP (polls 2)] CPU6: 105059 [LOC (interrupts 77821), RES (interrupts 1387), CAL (interrupts 18969), TLB (shootdowns 6880), MCP (polls 2)] CPU7: 30248 [135 (nvme0q3 33), LOC (interrupts 15473), RES (interrupts 766), CAL (interrupts 11855), TLB (shootdowns 2119), MCP (polls 2)] CPU8: 111403 [129 (mei_me 49), LOC (interrupts 85072), IWI (interrupts 5), RES (interrupts 1151), CAL (interrupts 17624), TLB (shootdowns 7500), MCP (polls 2)] CPU9: 56114 [128 (xhci_hcd 25604), 136 (nvme0q4 1), LOC (interrupts 16371), RES (interrupts 868), CAL (interrupts 11570), TLB (shootdowns 1698), MCP (polls 2)] CPU10: 543178 [130 (ahci[0000:00:17.0] 416220), LOC (interrupts 95483), IWI (interrupts 1), RES (interrupts 1234), CAL (interrupts 23381), TLB (shootdowns 6857), MCP (polls 2)] CPU11: 35243 [132 (nvme0q0 38), 137 (nvme0q5 130), LOC (interrupts 20704), RES (interrupts 1063), CAL (interrupts 11712), TLB (shootdowns 1594), MCP (polls 2)] CPU12: 112279 [148 (i915 185), LOC (interrupts 78004), IWI (interrupts 5), RES (interrupts 1469), CAL (interrupts 25689), TLB (shootdowns 6925), MCP (polls 2)] CPU13: 55567 [131 (eth0 7971), 138 (nvme0q6 28), LOC (interrupts 33595), RES (interrupts 759), CAL (interrupts 11584), TLB (shootdowns 1628), MCP (polls 2)] CPU14: 110571 [LOC (interrupts 83220), RES (interrupts 1279), CAL (interrupts 19440), TLB (shootdowns 6630), MCP (polls 2)] CPU15: 31638 [139 (nvme0q7 39), LOC (interrupts 17238), RES (interrupts 829), CAL (interrupts 11571), TLB (shootdowns 1959), MCP (polls 2)] CPU16: 9986 [LOC (interrupts 985), CAL (interrupts 8999), MCP (polls 2)] CPU17: 9979 [LOC (interrupts 984), CAL (interrupts 8993), MCP (polls 2)] CPU18: 9980 [LOC (interrupts 983), CAL (interrupts 8995), MCP (polls 2)] CPU19: 9974 [LOC (interrupts 979), CAL (interrupts 8993), MCP (polls 2)] CPU20: 9984 [8 (rtc0 1), LOC (interrupts 977), CAL (interrupts 9004), MCP (polls 2)] CPU21: 9975 [LOC (interrupts 974), CAL (interrupts 8999), MCP (polls 2)] CPU22: 9972 [LOC (interrupts 975), CAL (interrupts 8995), MCP (polls 2)] CPU23: 9953 [LOC (interrupts 959), CAL (interrupts 8992), MCP (polls 2)] CPU24: 9965 [LOC (interrupts 959), CAL (interrupts 9004), MCP (polls 2)] CPU25: 9944 [LOC (interrupts 948), CAL (interrupts 8994), MCP (polls 2)] CPU26: 9945 [LOC (interrupts 948), CAL (interrupts 8995), MCP (polls 2)] CPU27: 9942 [LOC (interrupts 942), CAL (interrupts 8998), MCP (polls 2)] CPU28: 9940 [LOC (interrupts 938), CAL (interrupts 9000), MCP (polls 2)] CPU29: 9929 [LOC (interrupts 926), CAL (interrupts 9001), MCP (polls 2)] CPU30: 9923 [LOC (interrupts 923), CAL (interrupts 8998), MCP (polls 2)] CPU31: 9923 [LOC (interrupts 926), CAL (interrupts 8995), MCP (polls 2)]
As you can see, interrupts on my isolated cores are way down. Interestingly, once you start the VMs, interrupts start to climb on those cores, but remain well below that of cores 0-14. The first report I showed was actually what it looks like with nohz_full, after rebooting and running my two VMs overnight.
Inside Windows, using the DPC latency checker, my graph went from averaging around 2000 microseconds to 1000 microseconds. As shown in the image below, I still get nasty latency spikes every now and then (that one killed my USB audio), but overall latency is much better. That image was captured while running Overwatch in the background and watching a YouTube video in the foreground. When idling the latency hovers around 600 microseconds, hitting 1000 microseconds about 20% of the time.

-
 1
1
-
Any luck figuring this out?
-
A couple of things I noticed...
I got this working, but both my keyboard and my mouse seem to go to "sleep" after 3 seconds. I have to mash a bunch of keys or frantically move the mouse to wake the device up. After that the mouse and keyboard work fine, until I don't use them for 3 seconds. It looks like "powertop --auto-tune" was to blame. FYI, in case anyone else is running into this.
I have two identical keyboards for two different VMs. Sadly, /dev/input/by-name only lists one of them. I'm using by-path, but I don't think that's any better than using the raw /dev/input/event.
I wasn't sure how this would interact with USB Manager, where I had bound root hubs to the VMs. I unmapped those and instead mapped only the audio devices, leaving the keyboard and mouse to the XML config.
Edit: Forget the comment below. I needed to use the one ending with "event-mouse" rather than just "mouse".
I'm having trouble with one of my mice... I get this error:internal error: qemu unexpectedly closed the monitor: 2023-04-18T05:26:01.673092Z qemu-system-x86_64: /dev/input/by-id/usb-Gaming_Mouse_Gaming_Mouse-if01-mouse: is not an evdev deviceI tried with "/dev/input/by-id/usb-Gaming_Mouse_Gaming_Mouse-if01-event-mouse" as well and got the same error. Is there any hope for this mouse? -
@byb I think you want to remove the 2nd "<qemu:arg value="-object"/>" if you're not doing a mouse as well as the keyboard.
-
18 hours ago, SimonF said:
Did you get usb c working?
No. Using the Oculus Quest with wireless instead.
-
On 11/30/2021 at 3:19 PM, Willybum said:
Anyone having issues launching a 1.18 server??
<snip>
On PC, I had to upgrade to Java 17 for the server to even launch, would this be causing the issue for MineOS?Precisely. The version of Java inside the current container is 16. We need an updated container.
-
2
-
-
Does anyone know how things change for USB Type C ports? I see the device under usb1, but after I pass that through, the VM doesn't recognize the device on that port. (An Oculus Quest.) I'm ordering a Type C -> USB A cable in the meantime to try a USB3 port.
-
Did you ever figure this out? Did disabling ACPI fix it?
-
This container stopped working a bit ago due to an API change. In updating it, I realized that FileBot went to a paid model, and that there's another better supported container available. I'm removing this container. Please use the other one. Personally, I'm switching to Sonarr.









[Solved] Some Containers Work, Others Don't
in Docker Engine
Posted
I've been dealing with frequent sqlite DB errors in Sonarr. I'm hopeful this was the cause. Thanks for posting the disk I/O errors. That helped me find this solution.