

danioj
-
Posts
1530 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by danioj
-
-
Update:
After roughly 10 days of uptime, I started to get crashes. It seemed to coincide with allot traffic coming to and from the server - which doesn't happen all the time.
I have since, removed the need for Host Access to Custom Networks to be enabled. After disabling that option, I have stress tested the server with some serious traffic.
Now I have an uptime of 3 weeks with no call traces.
I am still doing the fix as per earlier in the thread. Not sure what is providing stability now. Im inclined to think its the disabling of HATCN but I really don't know. Still on macvlan.
-
-
Changed Status to Open
Changed Priority to Urgent
-
I thought I would report back that I was too hasty in reporting that the SMART issue had gone away.
Even with all Disk related Plugins removed and as per my actions above I noticed that I was still getting the array SMART data read at random times that was having the effect of spinning up my disks.
I downgraded to the latest Stable 6.9.2 and have been running for over a week and not a single unexpected SMART data read or array spin up to speak of.
I don't have the time to debug so I am sticking with the Stable.
I noticed a set of posts close to this yesterday - I will like this thread in that thread.
-
6 minutes ago, Bruceflix said:
There was this in the VM logs that may be the reason
2021-09-13T09:26:37.013298Z qemu-system-x86_64: -chardev tty,id=charserial1,path=/dev/serial/by-id/usb-dresden_elektronik_ingenieurtechnik_GmbH_ConBee_II_xxxxxxxxxx-if00: warning: The alias 'tty' is deprecated, use 'serial' instead
That makes sense now. At least we have a solution. Would be nice for unraid to allow to pass through as a serial via GUI. -
The default way to passthrough the device in unRAID doesn't have the device showing up as serial device in Hassio VM - the new auto discovery feature however in HA does still find the device though which makes it confusing as all looks well but you can't setup the ZHA integration or deCONZ add-on.
I was able to overcome this by editing the XML and forcing the USB to pass through to the VM as a Serial USB and not the default way unRAID does it.
I have my Conbee II passed through to a VM in 6.10.0-rc1 and working perfectly.
<serial type='dev'> <source path='/dev/serial/by-id/<yourusbid>'/> <target type='usb-serial' port='1'> <model name='usb-serial'/> </target> <alias name='serial1'/> <address type='usb' bus='0' port='4'/> </serial>
The new auto discovery in HA won't work with this method - which is odd - but the device is there in HA and you can setup the ZHA integration or deCONZ add-on just fine.
-
 2
2
-
-
Changed Status to Closed
Changed Priority to Other
-
Tested thoroughly. Not an issue with this release.
-
 2
2
-
-
30 minutes ago, ChatNoir said:
Do you have Turbo Mode / Recontruct Write activated ? or Squid's Auto Turbo Write Mode plugin ?
It might explain why all drive spin up ?
*Penny Drops*
Yes I do. I remember now back in 6.2 when this option was officially introduced.
I don’t have the plug-in *anymore* but I have reconstruct write enabled - and if I recall correctly that’s the mode that spins up the disks to calculate parity in a quicker way than the traditional to speed up writes.
*slaps forehead really hard*
This whole thread is a non event and has to do with my settings. God I’m pissed at myself.
To anyone who has invested / wasted any time at all as a result of this thread - I’m sorry!!
-
12 minutes ago, danioj said:
Feel like I am spamming - but is my thread so I'll go ahead.
I can now replicate what is happening. Here is what I did:
- I spun down the array manually.
- I opened my personal user share on my iMac.
- This share has files which are spread across 4 disks. As expected those 4 disks spun up so the share could be read.
- I copied a small 1MB picture to the share. The file was written to Cache as expected.
- I initiated mover manually.
- All disks spun up.
- SMART was read from each spun up disk (the initial reported problem).
- The file was written to one of the disks and each disk was read.
- Mover stopped.
I have done this 5 times now. Each with the same result.
Like I posted above. If indeed unRAID needs every disk spun up and read to make a write to a single disk (and I have missed this behaviour all these years) then there is no problem at all and this is completely on me for being ignorant. I didn't think that was the case though.
Downgraded to 6.9.2 and the behaviour is the same.
When mover initiates, all disks spin up to be read as part of the write operation irrespective of the number of disks being written to. When a disk spins up SMART data is read as designed. As I have mover initiating every hour (and mover logging is off) queue the endless cycles of SMART reads as disks are spun up.
I feel a bit stupid here. Years and years of unRAID use and I never noticed this is how things work.
-
Feel like I am spamming - but is my thread so I'll go ahead.
I can now replicate what is happening. Here is what I did:
- I spun down the array manually.
- I opened my personal user share on my iMac.
- This share has files which are spread across 4 disks. As expected those 4 disks spun up so the share could be read.
- I copied a small 1MB picture to the share. The file was written to Cache as expected.
- I initiated mover manually.
- All disks spun up.
- SMART was read from each spun up disk (the initial reported problem).
- The file was written to one of the disks and each disk was read.
- Mover stopped.
I have done this 5 times now. Each with the same result.
Like I posted above. If indeed unRAID needs every disk spun up and read to make a write to a single disk (and I have missed this behaviour all these years) then there is no problem at all and this is completely on me for being ignorant. I didn't think that was the case though.
-
The mover has now stopped. In total there was about ~100GB of data to move at a guess.
The picture below shows the effect on the array after moving that 100GB. All those reads in addition to the writes to the single disk and parity.
I imagine all the disks will down spin down, until mover initiates again in an hour. At which time, if the disks are spun down and it has to something to move, it will spin up the whole array to do so and at the same time read SMART values of each disk and read each drive will it writes.
This is starting to come together.
Unless I am completely missing something fundamental in how unRAID works here, this shouldn't be happening right?
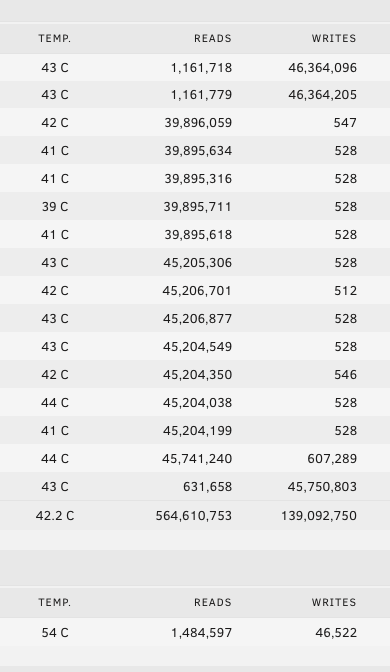
-
1 hour ago, danioj said:
Done. Just rebooted into safe mode now and manually spun the array down. Ill just leave it alone now.
I can get a good 5 hours of safe mode in before the family sit down for the night and wan their media server back.
OK, this has taken a new turn for me. As part of this test I also disabled Plex (as this the only Docker I could think could have the potential to read disks and cause them to spin up).
What I have observed now seems to be related to mover. I have mover set to run every hour. Mostly this captures the odd changed file I want protected or my daily camera feed backup.
Well, it just so happens the daily camera feed backup conceded with this test.
Now I have my camera feed share isolated to one drive. This to me should mean, that when mover moves these files, that single disk spins up along with the parity disks and they are written. As I understand it, not every drive needs to be spun up even when data is being written.
What I am observing here is that the whole array spun up when the mover operation started and in addition to the single disk and parity drives being written to - ALL my array disks are getting significant reads at the same time!!
The SMART entries in the log coincide with this and it seems to explain the regularity of the SMART events. My question is, why does mover need to read all my disks at the same time it is writing to a single array disk and parity?
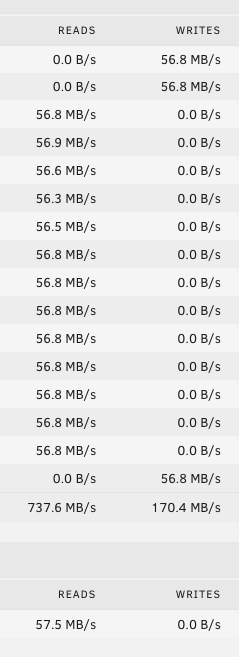
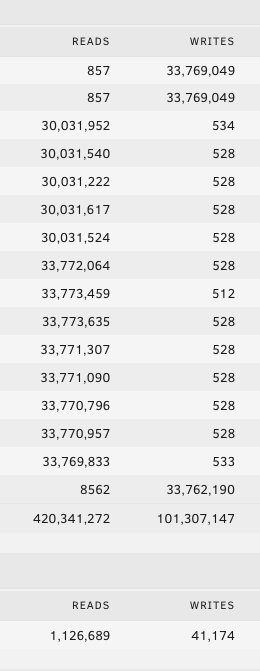
-
1 hour ago, ljm42 said:
The log snippet you posted shows that something is asking emhttpd for smart values but I'm not sure how to tell what it is. It probably isn't a VM or docker container, I'd guess either a plugin, the webgui, or emhttpd itself. Any chance you could run in safe mode for a little while to see if you can reproduce it there?
If it doesn't happen in safe mode that would imply a plugin. If it does happen in safe mode that would imply the webgui or emhttpd itself is triggering it.
Done. Just rebooted into safe mode now and manually spun the array down. Ill just leave it alone now.
I can get a good 5 hours of safe mode in before the family sit down for the night and wan their media server back.
-
1
-
-
-
On 9/6/2021 at 7:58 AM, danioj said:
@ljm42 what are your / LT initial thoughts on this report!?
I am happy to stay on the RC and help debug but I think we need a pragmatic and consistent approach that multiple users can follow.
@ljm42 any thoughts on my suggestion? Is there any feedback from the team on this?
-
4 hours ago, ljm42 said:
I'm still confused. If you see a log entry that shows flash backup spinning up the array drives, please show me
")
Somewhat detracting from the conversation guys but what is meant by that statement is that while @nuhll was posting about one issue I saw in the logs similar entries to the ones I had.
Unrelated conversations.
-
1
-
-
Job 1 for you I think is to enable your server to capture the logs prior to a crash. The diagnostics you have posted only show the log after the hard reset - as designed - as the log doesn't persist after a reboot.
Follow the instructions here to enable mirror of syslog to /boot
Then the next time you recover after a crash you can go to /boot/logs/syslog and see what happened immediatly prior to the crash.
Note - don't post the whole file - it won't have sensitive information removed like diagnostics do (if you click that option).
-
I decided to do a bit of an investigative test.
I amended all my nightly activities (backups etc) so that they were more consistent and completed at ~5am. This would prompt the array to spin down due to inactivity shortly after (there was no-one up using data on the disks at the time).
As expected, the array spun down. Then, for some reason I cannot fathom, unRAID started reading SMART data from the disks about an hour later.
Sep 6 05:47:17 unraid emhttpd: spinning down /dev/sdg Sep 6 05:47:17 unraid emhttpd: spinning down /dev/sdd Sep 6 05:47:17 unraid emhttpd: spinning down /dev/sde Sep 6 05:47:17 unraid emhttpd: spinning down /dev/sdf Sep 6 05:47:19 unraid emhttpd: spinning down /dev/sdh Sep 6 05:47:19 unraid emhttpd: spinning down /dev/sdn Sep 6 05:47:19 unraid emhttpd: spinning down /dev/sdp Sep 6 05:48:18 unraid emhttpd: spinning down /dev/sdj Sep 6 05:48:18 unraid emhttpd: spinning down /dev/sdc Sep 6 05:48:18 unraid emhttpd: spinning down /dev/sdi Sep 6 05:54:22 unraid emhttpd: spinning down /dev/sdl Sep 6 06:00:02 unraid emhttpd: spinning down /dev/sdo Sep 6 06:00:05 unraid emhttpd: spinning down /dev/sdm Sep 6 06:00:05 unraid emhttpd: spinning down /dev/sdr Sep 6 06:00:07 unraid emhttpd: spinning down /dev/sds Sep 6 06:00:09 unraid emhttpd: spinning down /dev/sdq Sep 6 07:37:02 unraid emhttpd: read SMART /dev/sdi Sep 6 07:37:23 unraid emhttpd: read SMART /dev/sdn Sep 6 07:37:43 unraid emhttpd: read SMART /dev/sdp Sep 6 07:37:56 unraid emhttpd: read SMART /dev/sdq Sep 6 07:38:11 unraid emhttpd: read SMART /dev/sdr Sep 6 07:38:33 unraid emhttpd: read SMART /dev/sdm Sep 6 07:38:45 unraid emhttpd: read SMART /dev/sds Sep 6 07:38:57 unraid emhttpd: read SMART /dev/sdo Sep 6 07:39:11 unraid emhttpd: read SMART /dev/sdd Sep 6 07:39:48 unraid emhttpd: read SMART /dev/sde Sep 6 07:40:03 unraid emhttpd: read SMART /dev/sdf Sep 6 08:00:04 unraid emhttpd: read SMART /dev/sdj Sep 6 08:00:04 unraid emhttpd: read SMART /dev/sdh Sep 6 08:00:04 unraid emhttpd: read SMART /dev/sdg Sep 6 08:00:04 unraid emhttpd: read SMART /dev/sdc Sep 6 08:00:04 unraid emhttpd: read SMART /dev/sdlThis is weird because it's not just one disk, it's all of them.
-
@ljm42 what are your / LT initial thoughts on this report!?
I am happy to stay on the RC and help debug but I think we need a pragmatic and consistent approach that multiple users can follow.
-
11 hours ago, itimpi said:
I thought that the idea was UnRaid would only try and read SMART data from drives that it thinks are spun up. If this is correct the real problem could be in how UnRaid decides drives are spun down not working as expected.
My sentiments exactly.Something like this, there has to be more people impacted by it if it is related to unRAiD itself.
I actually saw @nuhll post some logs regarding the USB backup feature of MyServers that appeared to have similar regular disk spin up events.
Open of course to the fact that it could be something else causing it - just not sure what.
-
Just checking in.
Uptime is now 3 days 13 hours 9 minutes since I last issued the netfilter fix command.
Not one call trace in the log or hard lock up / crash since.
-
2
-
-
7 hours ago, danioj said:
Thanks. Since I posted earlier this morning (well for me it is in Australia) that I spun my array down this has been my log:
Sep 3 09:09:48 unraid emhttpd: spinning down /dev/sdc Sep 3 09:09:49 unraid emhttpd: spinning down /dev/sdf Sep 3 09:09:49 unraid emhttpd: spinning down /dev/sdd Sep 3 09:09:50 unraid emhttpd: spinning down /dev/sdg Sep 3 09:09:50 unraid emhttpd: spinning down /dev/sdl Sep 3 09:09:51 unraid emhttpd: spinning down /dev/sde Sep 3 09:09:51 unraid emhttpd: spinning down /dev/sdq Sep 3 09:09:52 unraid emhttpd: spinning down /dev/sdr Sep 3 09:09:52 unraid emhttpd: spinning down /dev/sdm Sep 3 09:09:53 unraid emhttpd: spinning down /dev/sds Sep 3 09:09:53 unraid emhttpd: spinning down /dev/sdo Sep 3 09:09:54 unraid emhttpd: spinning down /dev/sdn Sep 3 09:09:55 unraid emhttpd: spinning down /dev/sdp Sep 3 09:09:55 unraid emhttpd: spinning down /dev/sdi Sep 3 09:09:56 unraid emhttpd: spinning down /dev/sdh Sep 3 09:09:57 unraid emhttpd: spinning down /dev/sdj Sep 3 09:23:24 unraid webGUI: Successful login user root from 10.9.69.31 Sep 3 09:29:01 unraid kernel: resource sanity check: requesting [mem 0x000c0000-0x000fffff], which spans more than PCI Bus 0000:00 [mem 0x000dc000-0x000dffff window] Sep 3 09:29:01 unraid kernel: caller _nv000722rm+0x1ad/0x200 [nvidia] mapping multiple BARs Sep 3 09:59:41 unraid webGUI: Successful login user root from 10.9.69.31 Sep 3 10:06:42 unraid emhttpd: read SMART /dev/sdm Sep 3 10:06:52 unraid emhttpd: read SMART /dev/sdi Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdh Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdr Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sds Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdn Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdq Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdo Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdp Sep 3 10:07:41 unraid emhttpd: read SMART /dev/sdj Sep 3 10:07:41 unraid emhttpd: read SMART /dev/sdc Sep 3 10:28:30 unraid emhttpd: read SMART /dev/sdg Sep 3 10:28:42 unraid emhttpd: read SMART /dev/sdl Sep 3 10:28:49 unraid emhttpd: read SMART /dev/sde Sep 3 10:28:56 unraid emhttpd: read SMART /dev/sdd Sep 3 10:34:43 unraid emhttpd: read SMART /dev/sdf Sep 3 11:17:57 unraid emhttpd: spinning down /dev/sdh Sep 3 11:18:58 unraid emhttpd: spinning down /dev/sdj Sep 3 11:18:58 unraid emhttpd: spinning down /dev/sdc Sep 3 11:34:04 unraid emhttpd: spinning down /dev/sdd Sep 3 11:34:35 unraid emhttpd: spinning down /dev/sde Sep 3 11:59:54 unraid emhttpd: spinning down /dev/sdf Sep 3 11:59:54 unraid emhttpd: spinning down /dev/sdn Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdm Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdg Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdq Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdo Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdl Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdi Sep 3 11:59:58 unraid emhttpd: spinning down /dev/sdr Sep 3 11:59:58 unraid emhttpd: spinning down /dev/sds Sep 3 11:59:58 unraid emhttpd: spinning down /dev/sdp Sep 3 12:00:36 unraid emhttpd: read SMART /dev/sdf Sep 3 12:03:02 unraid kernel: resource sanity check: requesting [mem 0x000c0000-0x000fffff], which spans more than PCI Bus 0000:00 [mem 0x000dc000-0x000dffff window] Sep 3 12:03:02 unraid kernel: caller _nv000722rm+0x1ad/0x200 [nvidia] mapping multiple BARs Sep 3 12:03:04 unraid emhttpd: read SMART /dev/sdm Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdh Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdr Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sds Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdn Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdq Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdo Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdi Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdp Sep 3 12:03:49 unraid emhttpd: read SMART /dev/sdj Sep 3 12:03:49 unraid emhttpd: read SMART /dev/sdc Sep 3 12:03:59 unraid emhttpd: read SMART /dev/sdg Sep 3 12:03:59 unraid emhttpd: read SMART /dev/sdd Sep 3 12:03:59 unraid emhttpd: read SMART /dev/sde Sep 3 12:03:59 unraid emhttpd: read SMART /dev/sdlSomething appears (to me) to be causing unRAID to keep reading SMART of inactive devices and spinning them up. Not sure what it is.
I think I will just raise this as a bug and we can track it separately from this announcement thread. Ill summarise these posts into one opening post. Happy to work with you closely on this @Mathervius
P.S. My array is spinning down quicker too but that is to be expected I think this is an effect of the Turbo Write Plugin.
Bug report raised as discussed.
-
1 hour ago, Mathervius said:
I am not using a Marvel controller.
My plugins:
CA Auto Turbo Write Mode
CA Auto Update Applications
CA Backup / Restore Appdata
CA Config Editor
CA Mover Tuning
Community Applications
Custom Tab
Dynamix Active Streams
Dynamix Local Master
Dynamix SSD TRIM
Dynamix System Statistics
Dynamix System Temperature
Fix Common Problems
GUI Links
GUI Search
Nerd Tools
Network UPS Tools (NUT)
Parity Check Tuning
Recycle Bin
Speedtest Command Line Tool
Theme Engine
Tips and Tweaks
Unassigned Devices
Unassigned Devices Plus
User Scripts
I uninstalled my CA Auto Turbo Write Mode plugin and it didn't seem to help.
What's really strange is that today my drives have started spinning down again. The only change I made was to uninstall the CA Auto Turbo Write Mode plugin and then reinstalled it later.
Thanks. Since I posted earlier this morning (well for me it is in Australia) that I spun my array down this has been my log:
Sep 3 09:09:48 unraid emhttpd: spinning down /dev/sdc Sep 3 09:09:49 unraid emhttpd: spinning down /dev/sdf Sep 3 09:09:49 unraid emhttpd: spinning down /dev/sdd Sep 3 09:09:50 unraid emhttpd: spinning down /dev/sdg Sep 3 09:09:50 unraid emhttpd: spinning down /dev/sdl Sep 3 09:09:51 unraid emhttpd: spinning down /dev/sde Sep 3 09:09:51 unraid emhttpd: spinning down /dev/sdq Sep 3 09:09:52 unraid emhttpd: spinning down /dev/sdr Sep 3 09:09:52 unraid emhttpd: spinning down /dev/sdm Sep 3 09:09:53 unraid emhttpd: spinning down /dev/sds Sep 3 09:09:53 unraid emhttpd: spinning down /dev/sdo Sep 3 09:09:54 unraid emhttpd: spinning down /dev/sdn Sep 3 09:09:55 unraid emhttpd: spinning down /dev/sdp Sep 3 09:09:55 unraid emhttpd: spinning down /dev/sdi Sep 3 09:09:56 unraid emhttpd: spinning down /dev/sdh Sep 3 09:09:57 unraid emhttpd: spinning down /dev/sdj Sep 3 09:23:24 unraid webGUI: Successful login user root from 10.9.69.31 Sep 3 09:29:01 unraid kernel: resource sanity check: requesting [mem 0x000c0000-0x000fffff], which spans more than PCI Bus 0000:00 [mem 0x000dc000-0x000dffff window] Sep 3 09:29:01 unraid kernel: caller _nv000722rm+0x1ad/0x200 [nvidia] mapping multiple BARs Sep 3 09:59:41 unraid webGUI: Successful login user root from 10.9.69.31 Sep 3 10:06:42 unraid emhttpd: read SMART /dev/sdm Sep 3 10:06:52 unraid emhttpd: read SMART /dev/sdi Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdh Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdr Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sds Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdn Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdq Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdo Sep 3 10:07:21 unraid emhttpd: read SMART /dev/sdp Sep 3 10:07:41 unraid emhttpd: read SMART /dev/sdj Sep 3 10:07:41 unraid emhttpd: read SMART /dev/sdc Sep 3 10:28:30 unraid emhttpd: read SMART /dev/sdg Sep 3 10:28:42 unraid emhttpd: read SMART /dev/sdl Sep 3 10:28:49 unraid emhttpd: read SMART /dev/sde Sep 3 10:28:56 unraid emhttpd: read SMART /dev/sdd Sep 3 10:34:43 unraid emhttpd: read SMART /dev/sdf Sep 3 11:17:57 unraid emhttpd: spinning down /dev/sdh Sep 3 11:18:58 unraid emhttpd: spinning down /dev/sdj Sep 3 11:18:58 unraid emhttpd: spinning down /dev/sdc Sep 3 11:34:04 unraid emhttpd: spinning down /dev/sdd Sep 3 11:34:35 unraid emhttpd: spinning down /dev/sde Sep 3 11:59:54 unraid emhttpd: spinning down /dev/sdf Sep 3 11:59:54 unraid emhttpd: spinning down /dev/sdn Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdm Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdg Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdq Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdo Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdl Sep 3 11:59:56 unraid emhttpd: spinning down /dev/sdi Sep 3 11:59:58 unraid emhttpd: spinning down /dev/sdr Sep 3 11:59:58 unraid emhttpd: spinning down /dev/sds Sep 3 11:59:58 unraid emhttpd: spinning down /dev/sdp Sep 3 12:00:36 unraid emhttpd: read SMART /dev/sdf Sep 3 12:03:02 unraid kernel: resource sanity check: requesting [mem 0x000c0000-0x000fffff], which spans more than PCI Bus 0000:00 [mem 0x000dc000-0x000dffff window] Sep 3 12:03:02 unraid kernel: caller _nv000722rm+0x1ad/0x200 [nvidia] mapping multiple BARs Sep 3 12:03:04 unraid emhttpd: read SMART /dev/sdm Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdh Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdr Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sds Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdn Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdq Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdo Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdi Sep 3 12:03:29 unraid emhttpd: read SMART /dev/sdp Sep 3 12:03:49 unraid emhttpd: read SMART /dev/sdj Sep 3 12:03:49 unraid emhttpd: read SMART /dev/sdc Sep 3 12:03:59 unraid emhttpd: read SMART /dev/sdg Sep 3 12:03:59 unraid emhttpd: read SMART /dev/sdd Sep 3 12:03:59 unraid emhttpd: read SMART /dev/sde Sep 3 12:03:59 unraid emhttpd: read SMART /dev/sdlSomething appears (to me) to be causing unRAID to keep reading SMART of inactive devices and spinning them up. Not sure what it is.
I think I will just raise this as a bug and we can track it separately from this announcement thread. Ill summarise these posts into one opening post. Happy to work with you closely on this @Mathervius
P.S. My array is spinning down quicker too but that is to be expected I think this is an effect of the Turbo Write Plugin.





[6.10.0-rc5] Boot to GUI not working
-
-
-
-
-
in Prereleases
Posted
Nice video. I’ve captured the moment it moves from a normal boot to the blank screen.