


RodWorks
-
Posts
55 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by RodWorks
-
-
Your flash drive has possible corruption on /boot/config/unraid_notify.cfg. Post your diagnostics in the forum for more assistance.
Checking to see if this is legit corruption....Thanks for the help.
-
8 minutes ago, JorgeB said:
It means one of the devices dropped offline in the past, not necessarily that it's failing, most often it's a power/connection problem.
Copy that, thank you for your time and advice. Everything is up and running again!
-
 1
1
-
-
root@Unraid:~# btrfs dev stats /mnt/cache
[/dev/sdd1].write_io_errs 0
[/dev/sdd1].read_io_errs 0
[/dev/sdd1].flush_io_errs 0
[/dev/sdd1].corruption_errs 0
[/dev/sdd1].generation_errs 0
[/dev/sde1].write_io_errs 6575101
[/dev/sde1].read_io_errs 13546
[/dev/sde1].flush_io_errs 121230
[/dev/sde1].corruption_errs 0
[/dev/sde1].generation_errs 0so is this a pool cache failing? Or just do the delete and recreate and check after that?
-
Good morning, getting this error which has kept my docker from loading. Appreciate any help.
-
Thank you, sir!
-
1
-
-
Recently upgraded both cache drives and restored app data and all seemed to be working fine until a recent restart. After boot the array didn't automatically mount and was looking for the old cache drives. I selected the new ones, but it says emulated/disabled for both new drives.
-
Anyone have a link to the prior version until this one gets worked out? Checked the docker hub and there's no archive.
Edit: Moved to the Selfhosters Shinobi container. No issues any more.
-
 1
1
-
-
On 4/19/2022 at 10:23 AM, ax77 said:
I deleted the storage drive manually again and set it to delete after 2 days just to see if it would start deleting again. Appears that it isn't still. Also, restarted Maria DB and made sure it's connected in the logs.
What's interesting is the Shinobi UI shows a different storage capacity than the drive itself shows. The Shinobi capacity is consistent with 2 days of recordings at 250 gb, while the drive is actually at 1.72 tb and growing consistent with the time since I wiped it last.
Edit: Just checked the files on the drive and they go back to 4/19 even though my settings say to delete after 2 days. However, I can't access them in the Shinobi UI even though they're visible files on the drive.
-
Ever since I updated the container 2 months ago, Shinobi has been running out of space and not deleting old files. I thought I had something messed up so I deleted all the recordings and double checked the settings to delete after 30 days. Now it's run over again and locked up at max storage. Only thing I changed was updating the container. Not sure what's going on. Anyone else with the issue?
-
17 hours ago, chrispcrust said:
I updated earlier today, no issues doing so with my camera streams, recordings, or reverse proxy set up.
I can't notice too much - my sense is this update is just bringing this docker up to speed with the latest "official" development versions of Shinobi. Prior to today, this hadn't been updated in years.
Thanks, appreciate the feedback.
-
1
-
-
I see there's an update on the docker container, just making sure there's no issues before updating?
What are the changes?
-
20 minutes ago, skois said:
Well, nextcloud is not aware if you run the docker in unraid or how you have setup your cache and disks.
Solution would be to have nextcloud share to prefer cache, that means files will stay in cache until is full.
With this you loose parity.
Or just fix the installation to not produce errors, not writing to log would be very rare.
Sent from my Mi 10 Pro using Tapatalk
This is what's getting written to the log repeatedly.
,"message":"/appinfo/app.php is deprecated, use \\OCP\\AppFramework\\Bootstrap\\IBootstrap on the application class instead."
-
3 minutes ago, skois said:
Well, nextcloud is not aware if you run the docker in unraid or how you have setup your cache and disks.
Solution would be to have nextcloud share to prefer cache, that means files will stay in cache until is full.
With this you loose parity.
Or just fix the installation to not produce errors, not writing to log would be very rare.
Sent from my Mi 10 Pro using Tapatalk
Ok, prefer is not an option.. I'll see if I can sort the errors out, otherwise it's gotta go.
-
1
-
-
1 minute ago, skois said:
The nextcloud.log is existing file so after its moved one time in the array it stays there.
Updates on files don't move them to cache.
If you delete the file, the new one will be created automatically and will be on cache. Until mover is run again
Sent from my Mi 10 Pro using Tapatalk
Ok, I guess that makes sense. What's a solution to this issue? Why doesn't Nextcloud write logs to the appdata share?
-
3 minutes ago, skois said:
New files will go to cache, not existing

Sent from my Mi 10 Pro using Tapatalk
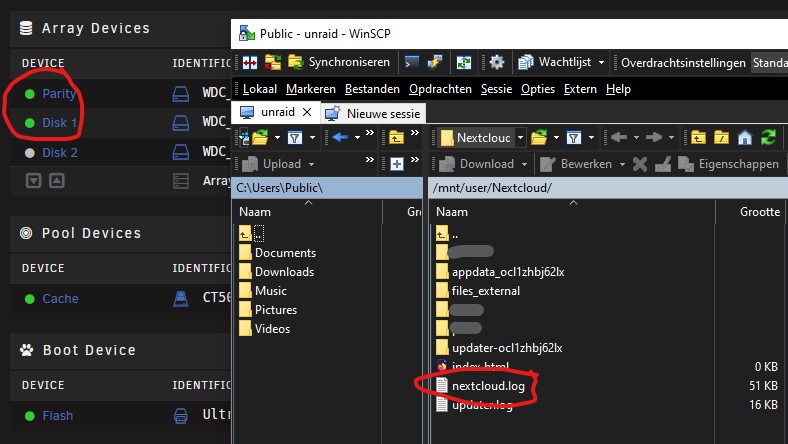
Not on my Nextcloud data share, keeps one of my drives and parity spun up 24/7 even though mover only runs at 0200. Nextcloud.log updates every minute. If I stop the container the drives spin down normally.
-
17 hours ago, Aran said:
Looks like i have the same problem:
I deleted the nextcloud.log (+5MB) file yesterday and my disks went idle. Today a new log file popped up in the data share. The info inside the log-file is about 'mail, smtp settings error'. I forgot to copy before i deleted the file...
I just want to understand how Nextcloud can write directly to a share that is set to write to a cache drive first....
-
4 hours ago, saarg said:
Even if you use cache: yes, the files will be moved to the array.
What exactly is it that is written in your /data mount that you mean should go in /config?
The more info you provide, the easier it is to help. And also post the docker run command.
I realize this, but only when the mover runs correct? There's a nextcloud.log inside the data folder that's being written to constantly which seems to be the issue.
The finder screenshot is what's inside the data share of Nextcloud. You can see the .log file there along with appdata files.


-
Can someone explain why this container is all the sudden constantly writing log files to my array data share /mnt/user/Nextcloud/ even though the share is set to "yes" use cache pool? I have the container configured to use /mnt/user/appdata/nextcloud for everything config related, but I'm finding all kinds of appdata/config related files on the data share.
This has just started in the past few months (keeps my disk 9 and parity always spun up).
-
Update:
System booted and ran perfect with each CPU running solo in socket 0. After that I put a CPU back in socket 1 (reversed the order now) and the system is running fine again. I do still have 32 gb (4 x 8gb) pulled from the system. Hoping one is the problem.
Still lost.
-
Had the first issue about a month ago, when I randomly found Unraid crashed, upon restart I got this error.

I recreated my USB drive and it booted up normally and worked fine until yesterday. Now, I'm getting the crashes and errors more often, but was able to get unraid to boot in Web GUI mode. I'm also seeing this error on boot sometimes.

I removed half of my 64 GB of ram to try and isolate a bad ram module. However, I'm still seeing the errors booting with either half of the ram removed.
Also, on the last boot, the system booted up running on only one processor and half the ram.
So, any ideas on where to start troubleshooting this issue?
-
I'm having an issue with all my camera feeds constantly dying and reconnecting. This Reddit post talks about this issue. Has anyone fixed this issue with the space invader container?
-
7 hours ago, hotio said:
What did the app developer had to say? Did you file a bug report?
Where do I send the bug report?
-
2020/03/05 19:49:00.742649 apps.go:51: [Sonarr] Updated (http://192.168.1.50:8989/): 1 Items Queued
2020/03/05 19:49:00.742895 apps.go:71: [Radarr] Updated (http://192.168.1.50:7878/): 0 Items Queued
2020/03/05 19:49:00.743181 apps.go:89: [DEBUG] Sonarr (http://192.168.1.50:8989/): Item Waiting for Import: Star.Trek.Picard.S01E07.iNTERNAL.1080p.WEB.H264-AMRAP
2020/03/05 19:49:00.743378 pollers.go:121: [DEBUG] Sonarr: Status: Star.Trek.Picard.S01E07.iNTERNAL.1080p.WEB.H264-AMRAP (Extracted, Awaiting Import, elapsed: 16h7m36s, found: true)
2020/03/05 19:49:00.743527 logs.go:57: [Unpackerr] Queue: [0 waiting] [0 queued] [0 extracting] [1 extracted] [0 imported] [0 failed] [0 deleted], Totals: [0 restarts] [1 finished]Was working for a week or so, no changes except for the docker updates. Seems to be unpacking and Sonarr is importing, but then unpackerr doesn't know it's been imported and it sits. Same issue is happening with Radarr also.

-
16 hours ago, hotio said:
What exactly is so confusing besides the most basic docker concepts of volumes and environment variables? It's almost the same steps as you had to do for sonarr, radarr, etc. Feel free to make suggestions on how to make this even easier...
Well, I'd make the "host path" a mandatory field at the top of the template not a hidden section at the bottom. Then. if "/torrents" is all that needs to be in the *arr path fields they don't seem to be necessary and could just be default values. I think most people are going to assume that the path is the completed directory which doesn't seem to be the case in the template.







[Plugin] CA Fix Common Problems
in Plugin Support
Posted
File? Not sure what you're referring to. It's nothing that I put there intentionally. Just posted looking for some help as FCP suggested.