

bonustreats
-
Posts
63 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by bonustreats
-
-
6 minutes ago, itimpi said:
Rebuilding parity writes every sector so at this point it should be correct (it is not a correcting check - but a rebuild). You can (optionally) now run a non-correcting check to ensure the rebuild was correct and I would expect 0 errors (a non-zero value would mean you have some issue that is probably hardware related).
Ah gotcha - wasn't sure if there was some distinction I was missing somewhere; thanks!
Better safe than sorry! Started a non-correcting check and will look for any sync errors. If there are, I'll report back (guessing that's a hard drive issue?); if not, on to step 2!
Thanks again!
-
On 5/5/2021 at 5:43 PM, jonathanm said:
Can you please clarify? In step 1 you talk about removing 2 drives, but it seems you are actually replacing (not removing) disk1 and disk4, and adding disk7?
If I've got that correct, then I think the more proper and safe way to go is
1. Physically replace parity 1 with new 8TB, set 4TB aside for now, let parity build on new 8TB, run correcting check to make sure everything is still happy.
I see no reason to move files around, but my process will take many many more hours and keep parity valid the entire time.
There is no reason to empty drives you are replacing if you let Unraid rebuild them with the content intact. The only time you need to empty files off a drive is if you are permanently reducing the number of occupied drive slots, and you aren't doing that.
I think step 1 is complete. I let parity rebuild on the 8TB and it just finished, but I just wanted to double check:
- after parity is rebuilt, are you saying to run another parity check? OR did you mean the data rebuild includes a correcting check?
Here's my homepage:

Which to me, looks like a correcting check was done during the rebuild. If that's NOT the case, then I'll run another parity check before moving on to step 2.
Sorry for the billion questions and thanks in advance!
-
In case anyone's reading this thread and is using shucked WD Easystore HDDs that don't show up in BIOS, please see this comment by @jonathanm. TL;DR - you need to disable the 3rd pin from the left on the power connection of the HDD by either using Kapton tape to cover that pin or use a Molex to Sata Power connector. I've had my own issues with some shitty connectors, so I'll be trying the tape method (should be arriving today).
E: tape arrived, first HDD installed and recognized! Rebuilding parity as we speak; ETA: 18.5 hours.
-
22 hours ago, jonathanm said:
The biggest advantage my method has is that each step is discrete per drive, so it's much less risk as you can take your time and verify that everything is still where it should be after each step. Once you are done the only difference you should see is more free space on each replaced drive slot, and a totally empty 4TB in slot 7. All data should remain available throughout, with no major interruptions.
I'd assign each line a new "job", and look for help and ask questions as needed, checking off before attempting to start the next item.
Looking back over what I wrote, step 2 may require additional parts, I can't remember if Unraid will allow you to drop a parity drive without setting a new config. You definitely can't remove a data slot. If not, then it's a simple matter of setting the new config with save all, then doing the unassigning of parity2, checking that parity is valid, starting the array and letting it check. After that's done you would add the old parity 2 disk to slot 7 and let it clear. The array would still be available throughout.
If you don't care to keep parity valid, you could combine step 1 and 2 for a considerable time savings, by simply doing the new config saving all data and cache, assigning the new single 8TB parity and old parity 2 to slot 7, DON'T check the parity is valid box, and let it build. Proceed from there.
@JorgeB would know for sure, he plays around with test arrays much more than I do.
It's fine, but it will be slow, and slow down the check more than the sum of the 2 tasks. Just to throw some random figures, if a parity check with no data access takes 12 hours, and copying a block of data would normally take 1 hour without the check running, it might take 2 hours to copy and extend the parity check to 16 hours. That's an example for effect, I haven't actually done hard benchmarks, but it feels pretty close based on observations.
In addition to the discrete steps, I think I like yours better since personal preference is to err on the side of caution by keeping parity valid at the expense of time; especially going from 2 parity drives to 1. I'll probably expand parity again at some point, but I'll need a bit more consolidation to open bays in my case.
Thanks @JorgeB for the good info!
I'll just keep my standard "don't add anything during the parity check" going, but good to know it won't break anything.
Thanks again for all the help and I'll update as necessary.
-
15 hours ago, jonathanm said:
Yes. The 2 parity drives have no connection, totally separate math equations are used. The only rule is no data drive can be larger than either parity slot.
The data is continuously available through the rebuild process, you don't have to wait during a rebuild.
The array is fully available during parity checks, but some systems don't have enough resources to keep playback seamless during checks. Any access is shared, so using the array while things are processing will slow down all the things.
Man, so many things I didn't know!
- I assumed both parity drives needed to be the same size
- Wasn't sure about rebuild data availability and was definitely trying to play it safe
- knew that the array was available during a check, but wasn't sure about when it's building parity. Also, is writing to the array during a parity check okay? I've always avoided that just to be safe.
Based on this, looks like your solution will work better than mine (parity maintained, almost constant data availability), albeit take a bit longer (which is fine with me!). Thanks so much for the inputs! I have one more drive to preclear and I'll probably start early next week. I'll try to update with progress or any tidbits, but will report back once it's done to mark this solved.
Thanks so much for the quick responses and good information!
-
1 hour ago, jonathanm said:
Can you please clarify? In step 1 you talk about removing 2 drives, but it seems you are actually replacing (not removing) disk1 and disk4, and adding disk7?
If I've got that correct, then I think the more proper and safe way to go is
1. Physically replace parity 1 with new 8TB, set 4TB aside for now, let parity build on new 8TB, run correcting check to make sure everything is still happy.
2. Unassign parity2, start array, stop array, assign old parity2 disk to data slot 7, let Unraid clear the disk then format it.
3. Physically replace 2TB disk1 with new 8TB, let unraid rebuild it, do a non-correcting check again.
4. Physically replace 2TB disk4 with new 8TB, let unraid rebuild it, do a non-correcting check again.
5. Optionally replace 2TB disk2 with original parity1 4TB, etc.
I see no reason to move files around, but my process will take many many more hours and keep parity valid the entire time.
There is no reason to empty drives you are replacing if you let Unraid rebuild them with the content intact. The only time you need to empty files off a drive is if you are permanently reducing the number of occupied drive slots, and you aren't doing that.
You're right - bad verbiage on my part. Removing and replacing is what I should have said - sorry.
I was planning on moving files for 2 reasons:
- being able to 'clean' the 2x 2TB that are being replaced. That way if I ever need them again, they're ready to rock. And,
- consolidating shares that have been spread across multiple disks. SIO mentioned that it was way less wear on the whole array to pull data from just one disk (Plex, etc.) when needed. I'm planning on having one of the 8TB specifically for movies and the other specifically for TV series, with room for expansion.
Just a couple questions:
1. Will unRAID allow for 2 dissimilarly-sized parity drives? The 8TB can be building parity and the other 4TB will be parity 2 during that operation? If so, awesome!
2. gotcha
3/4. This is where having all the data on the remaining 4 data drives comes in. With the fresh 8TBs, I could use unBalance to move ALL the Movie and TV shares onto each of those new disks and not wait for unRAID to rebuild them. Is this a bad idea?
5. Yep - sorry, I think I forgot to include this step.
1 hour ago, jonathanm said:Why?
Just to reduce downtime, I guess. I do have some plex users, but also don't want to put data at risk.
-
1 hour ago, itimpi said:
The moment you do New Config you invalidate parity and thus have to rebuild parity from the remaining disks. On that basis you might as well immediately after the New Config put all the disks into the configuration you want to end up with and then build parity based on that configuration.
Oh, goootcha - didn't realize that parity would be invalidated. Crap. Thanks!
-
Hi Everyone,
Based on SpaceInvaderOne's latest video regarding properly set up shares, I'm looking to upgrade my current configuration to keep media shares confined to one disk (if possible). In that vein, I picked up 3 WD Easystore 8TB drives that are currently preclearing. Here's my current configuration:
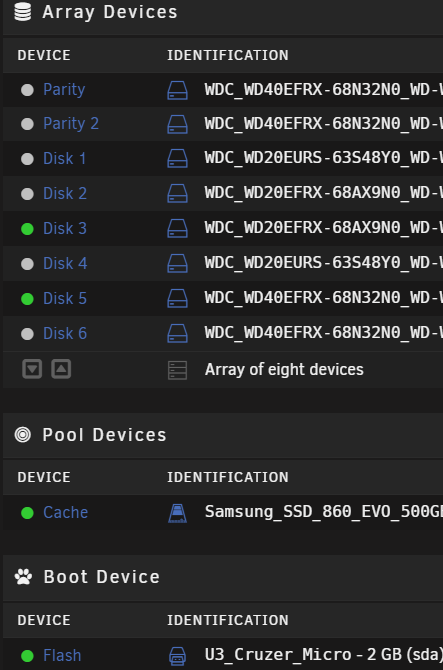
What I'm hoping to do:
Total number of disks stays the same; array size increases by 4TB.
New Config
Parity: WD 8TB
Parity 2:RemovedDisk 1: WD 8TB
Disk 2: Same
Disk 3: Same
Disk 4: WD 8TB
Disk 5: Same
Disk 6: Same
Disk 7: Previous 4TB parity disk
I saw the wiki articles about array shrinking and reducing parity drives but wasn't sure if there was a best practice for doing both at the same time.
Here's my plan to (hopefully) keep everything safe, as well as minimizing things like parity checks:
1. Move data (using unBalance) from the 2 drives I plan to remove onto the other 4 data drives (exclude them from all shares)
2. Run new config utility
3. Remove extraneous drives
4. Run a parity check
5. Remove parity 1x 4TB drive 2 (ensure parity is still valid)
6. Replace 1x 4TB parity with 1x 8TB parity
7. Add 2x 8TB drives and re-designate old 1x 4TB as a data disk for the array
8. Move data (using unBalance)
*9. Final parity check
Does that seem like a reasonable order of operations? How do you guys feel about dropping from 2 parity disks to 1? Please feel free to poke holes if I missed something or I'm being dumb.
Thanks so much!
-
18 minutes ago, ich777 said:
Can you connect to Github?
This seems like a network related problem since even Plugin the fails to download, have you got PiHole running somewhere in your network, if so eventually try to disable it.
@Squid do you know that message on a Plugin installation? Never saw that before.
Hooooly crap, you're right! I added github.com to the whitelist, but that didn't make any difference, so I just disabled pihole and github loaded right up. WOW, that didn't even cross my mind.
I disabled it and installed the plugin. Thanks so much for the answer AND the quick turnaround - it's most appreciated!

-
 1
1
-
-
Hi @ich777,
After all the help to get stuff setup on 6.8.3 (thanks again), I updated to 6.9 stable and ran into an issue (I'm very sorry). I removed all the extra parameters/variables from the Plex container after upgrading and started to follow the directions in the first post. However, I ran into this error trying to install the NVIDIA driver:
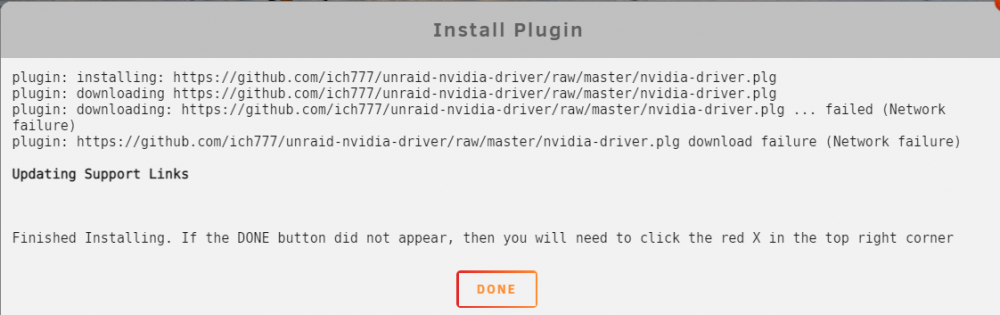
I just assumed something was wrong with my system, so I tried these things:
- pinged the server (success)
- removed the previous unraid-kernal helper plugin (success) and tried redownloading the NVIDIA drivers (failure)
- tried to install manually via the plugin page/link (failure)
- downloaded another docker - your unraid kernel helper (success)
- streaming via Plex both on and off the network (success)
I'm not quite sure why it won't download, but I'm just wondering if maybe I missed turning off a setting or something. Diagnostics are attached in case they're needed.
Thanks very much!
-
On 2/20/2021 at 12:37 AM, ich777 said:
Please note that I also created a plugin for Unraid 6.9.0RC2 and that you don't need to build custom images and you can simply install it from the CA App.
No I don't think so, is the fan speed higher?
I also have that 'issue' when I'm on the Dashborad page, this has something to do how the plugin gets it's data from...
Please also male sure that you turn off the advanced view on the Docker page since this also can take up to 10% of CPU usage no mather if you are on the Docker page or even logged in to the Unraid WebGUI.
Try to go to the dashboard, I bet you might see this behavior again but as said above this is because of the GPU Statistics plugin but only if you are on the Dasboard page.
I don't think the fan speed was higher, but honestly can't remember. If it happens again, I'll make sure to take a look to compare.
I didn't know that about the docker page, but I do have (and have had preivously) kept it in basic view - thanks for the info! I'll keep my eye on CPU usage when I go to the dashboard page, but I don't think I'll be visiting as frequently until it's resolved.
Thanks again!
-
1
-
-
21 hours ago, ich777 said:
The first thing that I've found was this on reddit: Click
What do you mean exactly with hanging? Is the system unresponsive?
From your syslog I see you are having the custom build installed, do you experience any other problems?
Can you try to turn on persistance mode (but I think that wouldn't really solve the issue and is just a workaround).
Thanks for the link! Apologies - I didn't mean for you to have to Google something for me; just thought it might have been a prominent issue or something. I was looking into persistence mode and found this - it seems like pulling the GPU out of P8 (deep sleep) may invoke some RAM usage. However, does forcing it out of deep sleep cause any extra 'wear' on the card? Maybe just increases the likelihood of fan failure? Sorry, these aren't direct questions (unless you know the answer, haha), so I'll keep digging. Maybe this is related to the CPU load increasing? While googling that error, I came across someone in a previous thread mentioning something very similar to what I was seeing with the CPU issue. They seemed to think it was related to @b3rs3rk's plug-in, but there's no direct proof of that.
Sorry - bad phrasing. I just meant that the CPU load increased to 4-7% and stayed there for no apparent reason until I started/stopped the Plex stream; everything else behaved normally (GUI/system was fully responsive, though I didn't do any sort of testing for all functionality).
All that to say, I haven't seen this happen again, so maybe it was just a fluke?
Edit - and I'm not seeing any other problems; sorry, forgot to answer
-
On 2/15/2021 at 11:39 AM, bonustreats said:
Apologies for the delay in response, but I just had a chance to implement the changes. They went flawlessly!
Thanks so much @ich777 for all your hard work, it's most appreciated! Also thanks to @yogy for writing out the steps for dummies like me!
I also installed @b3rs3rk's plugin and it's working great, too!
I've been using unRAID since...2013 (2012?) and I've been consistently impressed by the patience, knowledge, and overwhelming amount of support that the community provides. You guys are the best - thanks!
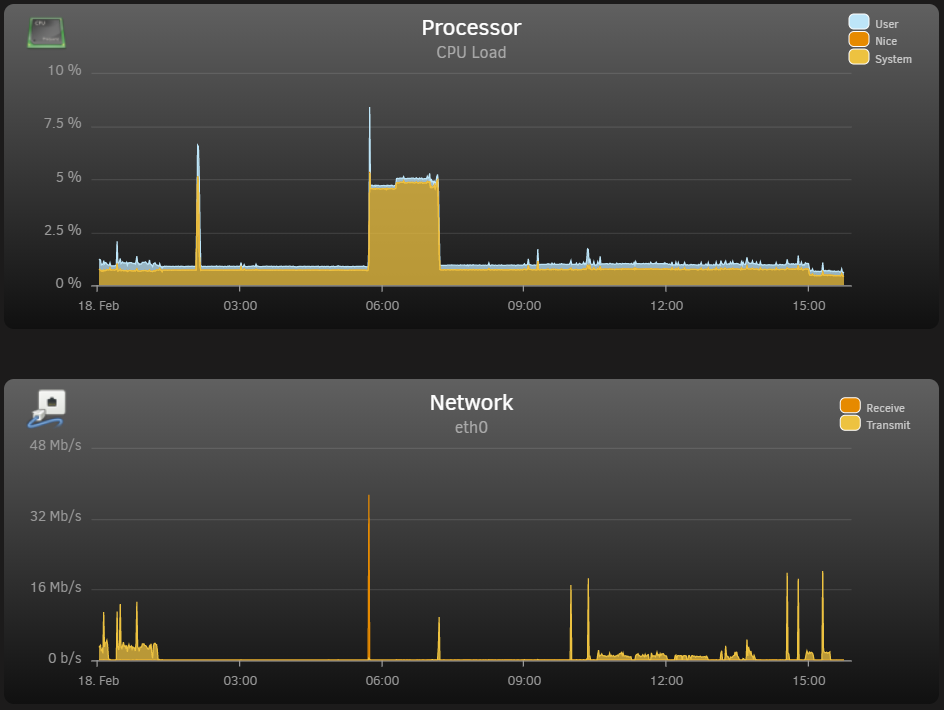
Just wanted to follow up with some (slightly) odd behavior, though I'm not quite sure where the issue may be coming from. I've noticed my CPU spooling up to 4-7% usage and just kind of hanging out there while nothing's going on - no Plex stream or VM running. At the same time, my GPU comes out of P8 (idle) to P0 and also just kind of hangs out for a while. I then initiate a transcoded Plex stream and terminate it after a few minutes and the system returns to normal (1-2% CPU load). This morning, I was able to catch the cycle: I checked to make sure my dockers were running and updated Plex. The CPU/GPU load stayed elevated until I started, then terminated a Plex transcode and it went back to 'normal.'
I don't think I've seen this behavior (at least with the CPU) before upgrading, but I honestly can't say that for certain. Image of the CPU load and ethernet traffic is attached, as well as the diagnostics file. I was looking through the system log and saw this repeated a couple thousand times:
Feb 18 05:43:11 Radagast kernel: resource sanity check: requesting [mem 0x000c0000-0x000fffff], which spans more than PCI Bus 0000:00 [mem 0x000c0000-0x000dffff window]
Feb 18 05:43:11 Radagast kernel: caller _nv000709rm+0x1af/0x200 [nvidia] mapping multiple BARsAnd thought maybe my GPU got stuck in a loop or something? Wasn't sure if I should post here, so if it isn't related to the plug-ins, I'd be glad to start a separate thread.
Thanks very much!
Edit: just wanted to further point out the CPU and network spikes at ~05:45 (that was me downloading Plex update) and the other at ~07:30 initiating the Plex transcode.
-
On 2/14/2021 at 12:24 AM, ich777 said:
Exactly.
Eventually install the GPU Statistics plugin from @b3rs3rk so you see the utilistion in your dashboard.
And yes you only need the Nvidia build.
Apologies for the delay in response, but I just had a chance to implement the changes. They went flawlessly!
Thanks so much @ich777 for all your hard work, it's most appreciated! Also thanks to @yogy for writing out the steps for dummies like me!
I also installed @b3rs3rk's plugin and it's working great, too!
I've been using unRAID since...2013 (2012?) and I've been consistently impressed by the patience, knowledge, and overwhelming amount of support that the community provides. You guys are the best - thanks!
-
2
-
-
Hey everyone,
Just had a question and wanted to run through the steps @yogy wrote on page 23 to make sure I wasn't going to mess anything up (sorry for all the noob-y stuff).
1 - I'm not quite sure what the differences are in the pre-built images and which one I would need. Here's my sitch: I recently acquired an RTX 4000 and would like to use it for plex streaming on the current (stable) 6.8.3 OS. I've watched SIO's excellent video about h/w transcoding and have been catching up with the ongoing situation regarding plugins and removals. My question: I am using ZFS as the file system in my server, so does that mean I would need the "custom NVIDIA&ZFS" download or would the "custom NVIDIA" suffice?
Here are the steps that I would take to upgrade:
1. backup my flash drive
2. replace all bz* files on the flash with the ones from the download
3. reboot server and install unraid-nvidia-kernel-helper plugin from CA
4. follow SIO's passthrough steps (passing parameters, etc.)
5. turn on hardware encoding within plex
6. double check that watch nvidia-smi shows the GPU and utilization during playback
7. celebrate
Is that correct? Again, apologies for the noob questions, just nervous about messing with my mostly rock-solid setup. I appreciate all the hard work @ich777 has done to make this a possibility - thanks very much!
Thanks in advance!
E: welp, I am a dumb dumb. I'm using XFS not ZFS as my file system - my apologies. Guess I would just need the custom NVIDIA download. Don't drink and post, folks, haha.
-
Update: I ordered a PCI NIC to tide me over until stable 6.9 drops. Everything seems to be working well with the current setup.
Thanks everyone for the responses; they're most appreciated!
-
Hey Jorge,
Thanks for the link! I wasn't sure if manual was still a preferred (possible) update method.
I've been reading through some other threads about some issues 6.9 beta (as well as some of the fixes) and I miiiight not be ready to live on the bleeding edge with my current unraid novice status, haha. Might just grab a PCI NIC and call it a day until 6.9 stable releases.
Thanks again!
-
Oh man, really? WOW - thanks! How in the hell did I miss that? Is that in some release notes that I missed?
I'm guessing the steps are: putting the old hardware back in, upgrade to the beta, then swap the hardware again?
Thanks so much for such a quick response!
-
Hi Everyone,
This morning I replaced all the guts of my server with upgraded hardware:
Gigabyte Aorus Pro B550
Ryzen 7 3700
Trident Z Neo DDR4-3200 - 16GB
But left all the HDD/Cache stuff there. I then upgraded the BIOS to the latest release, change the boot order to my flash drive, and voila! Upgraded server!
Except... I can't see it on my network. It will boot and start regularly when using GUI mode, but it won't be seen on the network. Things I've tried:
- resetting the network (no change)
- changed the IP address from static (no change)
- new cable (no change)
- looking through the BIOS to see if there was some setting that I missed (didn't see anything)
Observations:
- I do get the 'network lights' on the port when I plug the cable in
- there are 2 drives from which I can boot in the BIOS (one says 'partition 1'); maybe I have them in the wrong order?
This may not be unraid related (maybe more hardware related), but I wasn't sure if anyone's seen/had any issues like this using my particular board OR if maybe I'm just being an idiot and missed something easy.
Thanks so much for your time (diagnostics attached)!
-
So I found out why my cache drive failed! Looks like a cheap molex to SATA connector melted and caught on fire!
If any other folks see this, please learn from my mistake and use better connectors - crimped connectors or the SATA power cables are better. I posted on Reddit and a couple people gave some really great information, including a youtube review of another situation eerily similar to mine.



-
Thanks a lot - I appreciate all the help! I'll mark this one as solved.
-
Wow - thanks so much for the quick reply! Just out of curiosity, were you able to tell that from the server diagnostics or from the SMART report? If from the SMART report, was it because all the attribute VALUES were 100? OR was it because there were P's in the prefailure warning column?
From this post it indicates that V-NAND or 3D TLC are the preferred types of SSD - is that correct? I was also looking and couldn't find a size recommendation for the cache - would 500GB be enough for...pretty much only Plex? This drive looked okay, if that's the case.
Thanks so much for all the help and sorry for the billion questions!
-
Hi Everyone,
Yesterday, I noticed Plex was down and went to investigate. I tried rebooting the server, but I saw that the cache drive was unmountable. I found a couple forum posts about how to erase/rebuild the cache drive, but I'm not sure if the drive itself is bad. I ran a SMART report, but I'm not sure if the drive is dead or if it's just behaving weird because it doesn't have a proper file system associated with it.
If the drive is okay and I just need to rebuild it, just wanted to confirm that this link would work for this situation.
Thanks very much for your time!
radagast-diagnostics-20190911-1534.zip radagast-smart-20190911-1130.zip
-
I've had some issues before with call traces
However, I got some new hardware and I'm getting them again. I looked through the log file and didn't see anything that I recognized; at least from previous posts. Are these call trace errors something to be concerned about or is it possible to ignore them?
Thanks for your time!









Increase Array Size AND Reduce Number of Parity Drives: Order of Operations - [SOLVED]
in General Support
Posted
Just wanted to update: all steps are complete, parity AND resources were available consistently (other than downtime for physically replacing HDDs).
Waaaaay simpler and easier than I was expecting it to be. Thanks so much @jonathanm and @itimpi for all the help - it's definitely most appreciated!