




theone
Community Developer
-
Joined
-
Last visited
Everything posted by theone
-
I don't want to know if the backup server is connected to network I want to now that the actual array pool is on so I can backup to it.
-
I am also looking into this and plan to use FreeFileSync. I wake up my remote unraid (doing it over IPMI - working OK) Wait until remote unraid is up and running - How do I get the remote unRAID server status (Array On)? Start backup from local to remote backup server (FreeFileSync) Powerdown the remote unraid (doing it over IPMI - working OK) How do I do the wait part without a wait for X minutes command but with some sort of polling or notification?
-
I tried installing Immich on a test/backup server I just built that is on the same network (ip 192.168.1.113 vs 192.168.1.104 of the main server) and it downloaded in <30 seconds !!! So I think it is something server related. All other dockers not updating from ghcr.io or lscr.io update without issues. I did a clean installation of all my dockers lately from image to folder configuration but it is still slow (as before the change) Any additional help would be appreciated.
-
So I got around to rebooting my routers but it didn't help. Downloading immich update now from ghcr.io/imagegenius/immich:latest at ~300-600Kbps (<75KB/s) 😪 For a 416MB package it will take me ~50 minutes.
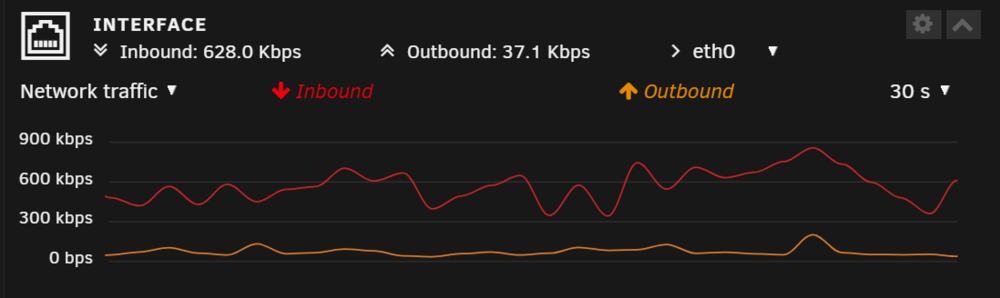
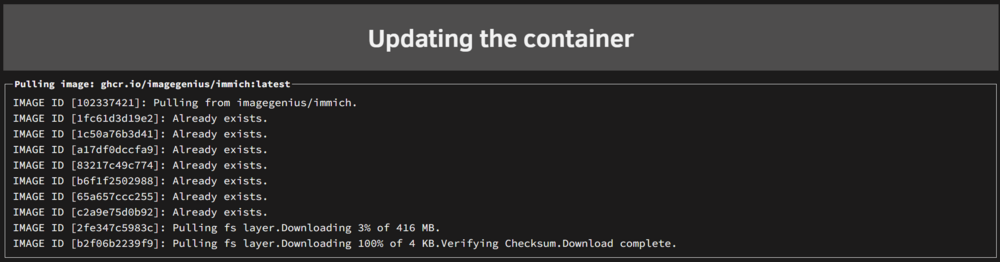
-
I have setup Duplicati in a test environment (simulated files on temporary cache drive fodler) as following and each time I try to run a backup I get the same error messages: "MessagesActualLength": 3, "WarningsActualLength": 0, "ErrorsActualLength": 2, "Messages": [ "2024-06-14 22:13:16 +03 - [Information-Duplicati.Library.Main.Controller-StartingOperation]: The operation Backup has started", "2024-06-14 22:13:16 +03 - [Information-Duplicati.Library.Main.BasicResults-BackendEvent]: Backend event: List - Started: ()", "2024-06-14 22:13:16 +03 - [Information-Duplicati.Library.Main.BasicResults-BackendEvent]: Backend event: List - Completed: ()" ], "Warnings": [], "Errors": [ "2024-06-14 22:13:16 +03 - [Error-Duplicati.Library.Main.Operation.BackupHandler-FatalError]: Fatal error\nFileNotFoundException: Could not find file \"\"", "2024-06-14 22:13:16 +03 - [Error-Duplicati.Library.Main.Controller-FailedOperation]: The operation Backup has failed with error: Could not find file \"\"\nFileNotFoundException: Could not find file \"\"" ], /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker create --name='duplicati' --net='bridge' --cpuset-cpus='1,2,15,16' -e HOST_OS="Unraid" -e HOST_HOSTNAME="Tower" -e HOST_CONTAINERNAME="duplicati" -e 'CLI_ARGS'='' -e 'PUID'='99' -e 'PGID'='100' -e 'UMASK'='022' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:8200]' -l net.unraid.docker.icon='https://raw.githubusercontent.com/linuxserver/docker-templates/master/linuxserver.io/img/duplicati-logo.png' -p '8200:8200/tcp' -v '/mnt/cache/temp/duplicati_destination/':'/backups':'rw' -v '/mnt/cache/temp/Noga'\''s Documents/':'/source':'rw' -v '/mnt/cache/temp/duplicati_tmp':'/tmp':'rw' -v '/mnt/cache/unRAID_Apps/Docker/appdata/duplicati':'/config':'rw' 'linuxserver/duplicati' I added the tmp path (although it ins' in the template) but fails with and without it. When doing a cp from the docker console from /source to /backups it works - so no permissions problem. What could be the problem?
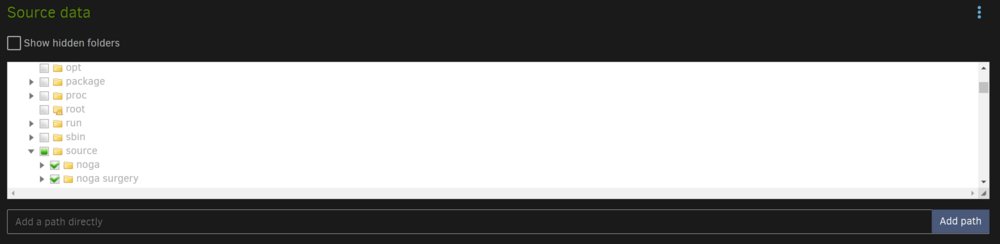
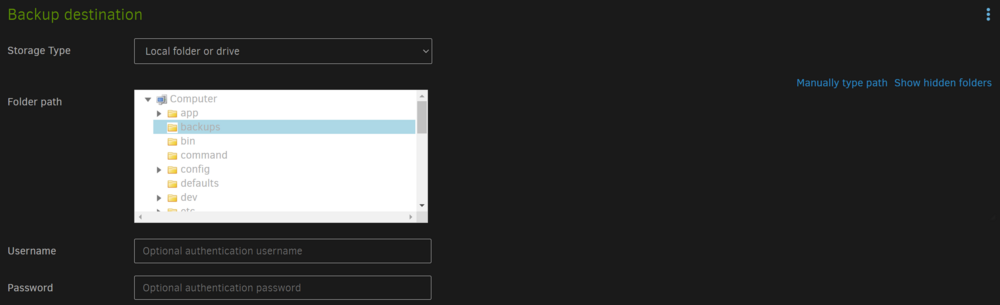
-
I have been running NGINX Proxy Manager (NPM) for a few months now with my personal registered domain for different docker apps (immich.<mydomain>.com, overseer.<mydomain>.com, jellyfin.<mydomain>.com, etc...). My domain is registered and namecheap. I have lately stumbled across across tailscale (and this Plugin) while seaching to improve security and use a VPN. I have installed this great plugin and got it working to access the unraid webui server from different remote devices. I can also access the apps on the VPN using tower:<port number> (for example immich at tower:8080) I am now trying to combine the two so I (and others that I let) can access the apps using <app>.mydomain.com. I saw the below video but don't know how to do it for NPM and the Tailscale plugin. I the example in the video it seems there is a dedicated server for the reverse proxy (Caddy) but if I do this for the unraid server doesn't it expose the whole server to all allowed users? Does anyone have a step-by-step tutorial for achieving this in unRAID with NPM and Tailscale plugin? If it is possible...
-
So I am still having this problem - for all dockers from lscr.io and ghcr.io for lscr.io dockers I remove the lscr.io prefix and used linuxserver directly (for example, changed sonarr repository from lcsr.io/linuxserver/sonarr to linuxserver/sonarr and it now updates very FAST. I Google searched for similar issues and found many references to the same problem, but no solution 😞
-
Whenever I install or update a Linuxserver (lscr.io) docker it takes a VERY long time to download/pull the images. It can take > 10 minutes for ~100MB. This does not happen for other docker distributions - just Linuxserver. Does/Has anyone else expererienced this?
-
I need help I had jellyfin up and running for the last souple of years without issues. Today I updated to Jellyfin 10.9 and something happened (maybe during the update) but my docker fails to run (runs and the stops) with "address in use" in docker log. So I removed/deleted the docker, restarted the server (power cycle) and tried to reinstall the docker but no get error during install. Here is the result of the docker install The existing allocatted docker ports are below - see no Jellyfin (as it is not installed yet) What is the problem?
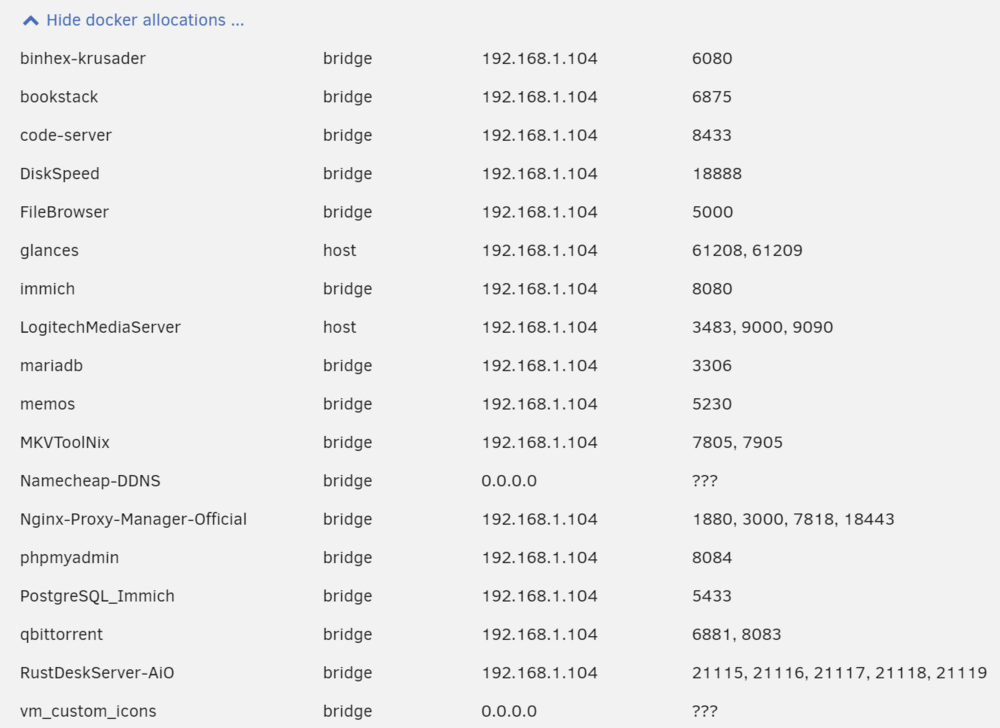
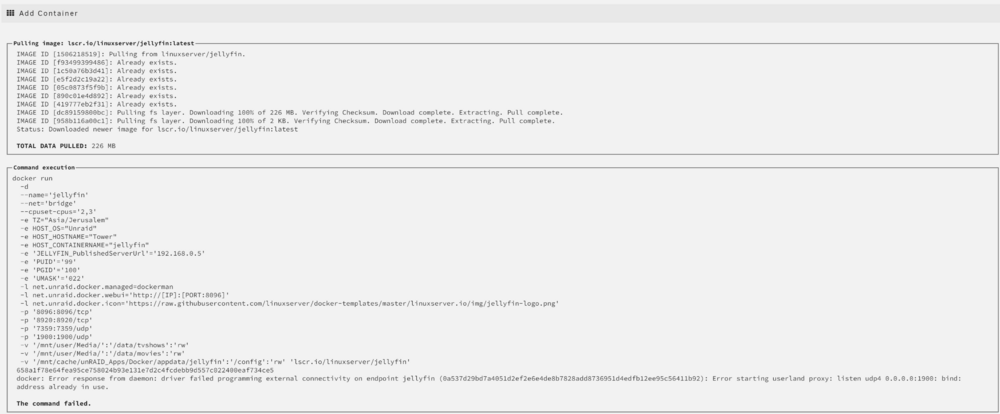
-
How is this done? And will it preserve all dockers, settings, appdata? Or do I need to reinstall them all?
-
What's weird is that if I do back at this stage I get the message "Currently logged in as .... You are about to grand <phone name> access ...." and then pressing "Grant Access" it gets stuck there...
-
Did both but still after entering username and password the message appears at the bottom for a couple of seconds and then the login wheel turn endlessly without actually logging into the account.
-
No change - still the same problem
-
I don't have a problem with Chrome. I have a problem with the Android Nextcloud App
-
I have recently setup NEXTCLOUD on my server and I can't access it using the Android Nextcloud App on my phone. I have it setup also via NGINX reverse proxy manager. I also have the following lines in my Nextcloud config.php file 'overwrite.cli.url' => 'https://files.avidank.com', 'overwritehost' => 'files.avidank.com', 'overwriteproticol' => 'https', 'overwrite.cli.url' => 'https://files.<mydomain>.com', 'overwritehost' => 'files.<mydomain>.com', 'overwriteproticol' => 'https', and 'trusted_domains' => array ( 0 => '192.168.1.104:8666', 1 => 'files.<mydomain>.com', I can access it OK from my PC and phone from a web browser locally (192.168.1.104:8666) and remotely files.<mydomain>.com. When I try to access it locally or remotely from the Nextcloud Android app It gets stuck (endless turning wheel) on either Granting Access page or login page and sometimes show message at the bottom "Strict mode: no HTTP connection allowed!" What is the problem?
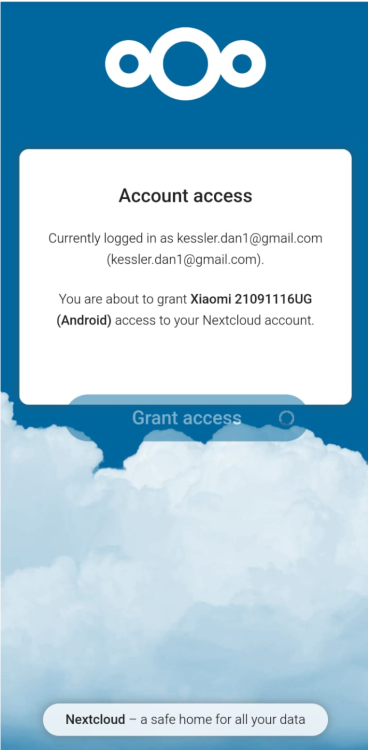
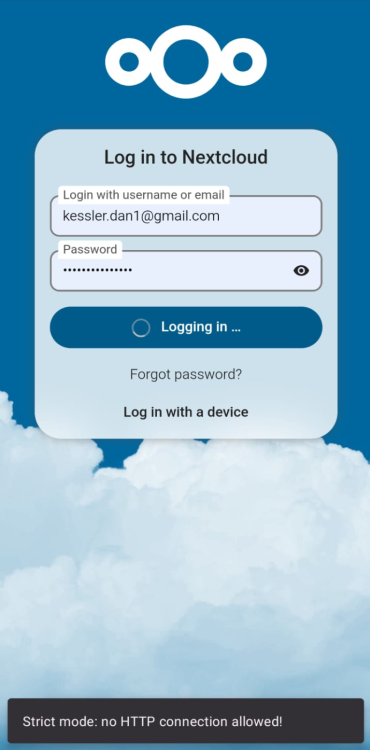
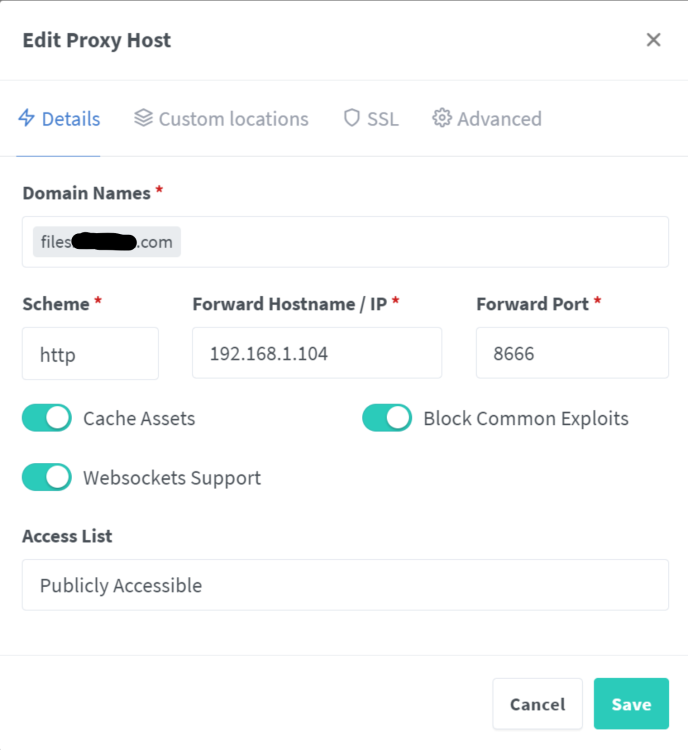
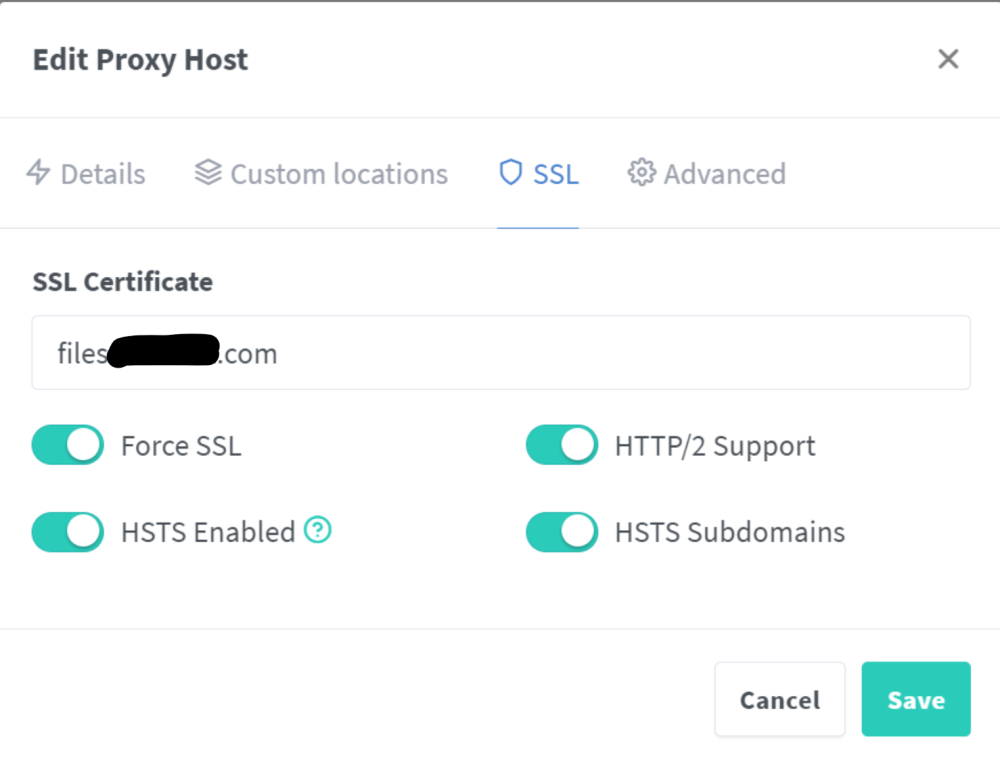
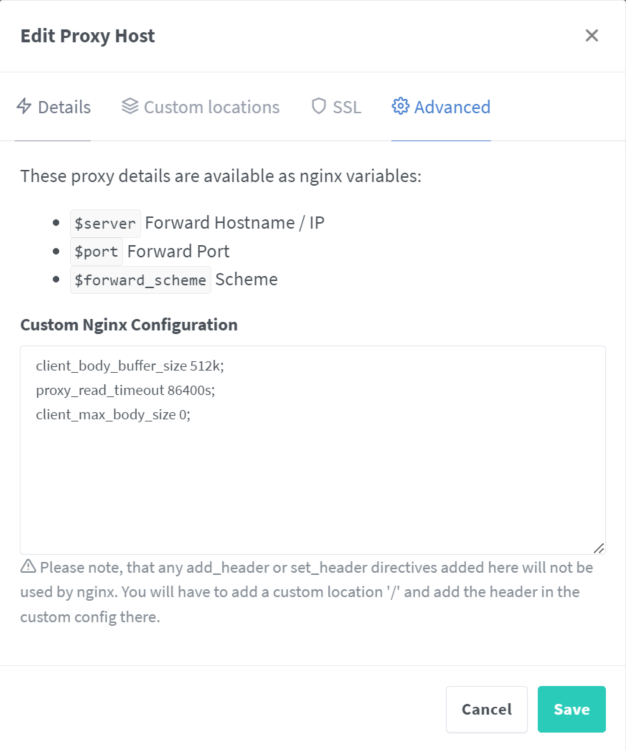
-
I use the Rustdesk AIO container by ich777. It works good in my home network. I want to use it remotely but dont' know how to config NGINX proxy manager. I tried Step 5 here https://gist.github.com/Lvdwardt/707d9c3fb4581d38102399f91a21c9c6 but I don't understand what to write in the "yout_stack_name". my domain is rustdesk.mydomain.com what should I place in the streams as the "Forward Host"? I tried the below but although the 1st one shows Online the remote connection doesn't work. The blacked out part is "mydomain". and also this But still not working. Do I need to define a proxy host under proxy hosts? I have additional unraid self-hosted services (jellyfin, immich, etc...) that are working perfectly fine from LAN and remotely. I have port forwarding defined on my router 80 --> 1880 (NGINX port), 443 --> 18443 (NGINX port) What am I don't wrong or missing?
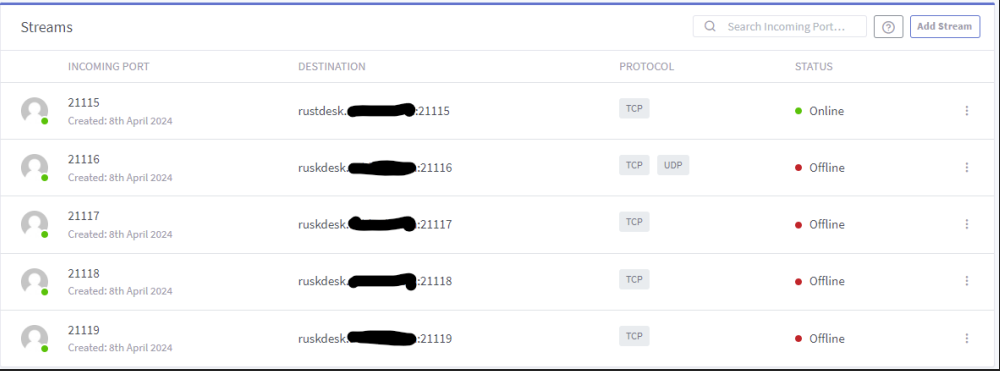
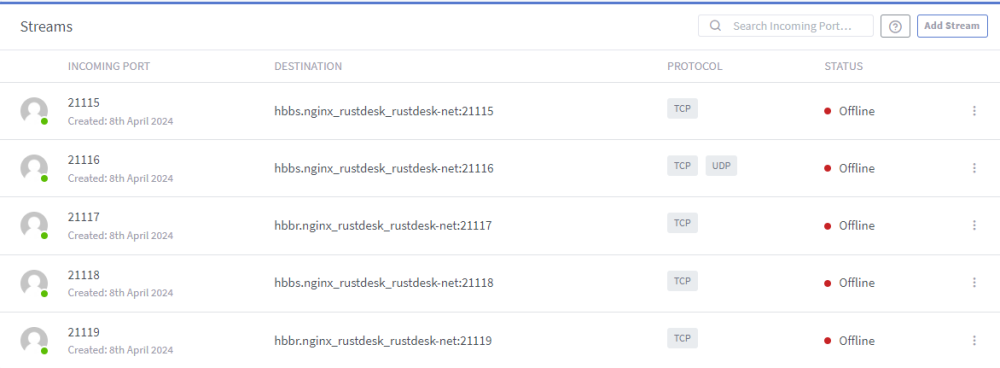

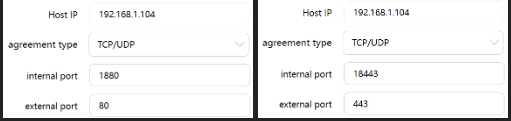
-
I use the AIO container by ich777. It works good in my home network. I want to use it remotely but dont' know how to config NGINX proxy manager. I tried this but I don't understand what to write in the "yout_stack_name". my domain is rustdesk.mydomain.com what should I place in the streams as the "Forward Host"? I tried the below but although the 1st one shows Online the remote connection doesn't work. The blacked out part is "mydomain".
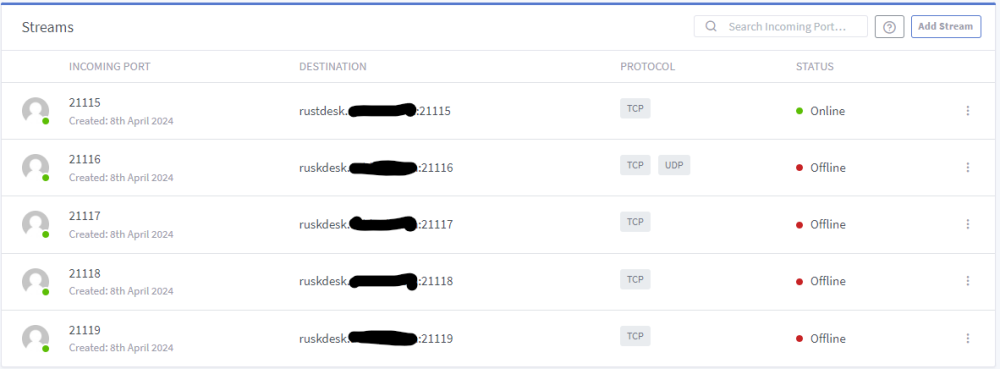
-
I have version 6.12.9 update pending restart. Do I have to install it to see the 6.12.10 update?

-
I am trying to setup a mouse to wake up a Windows VM. I connected the mouse to the server and it appears corrrectly as "Microsoft Corp. Basic Optical Mouse" But when I run the following it does not appear ls /dev/input/by-id/ Also "by-path" doesn't give additional information How do I proceed?
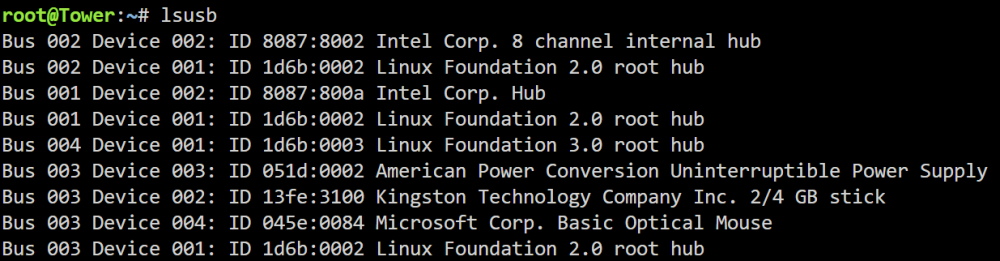


-
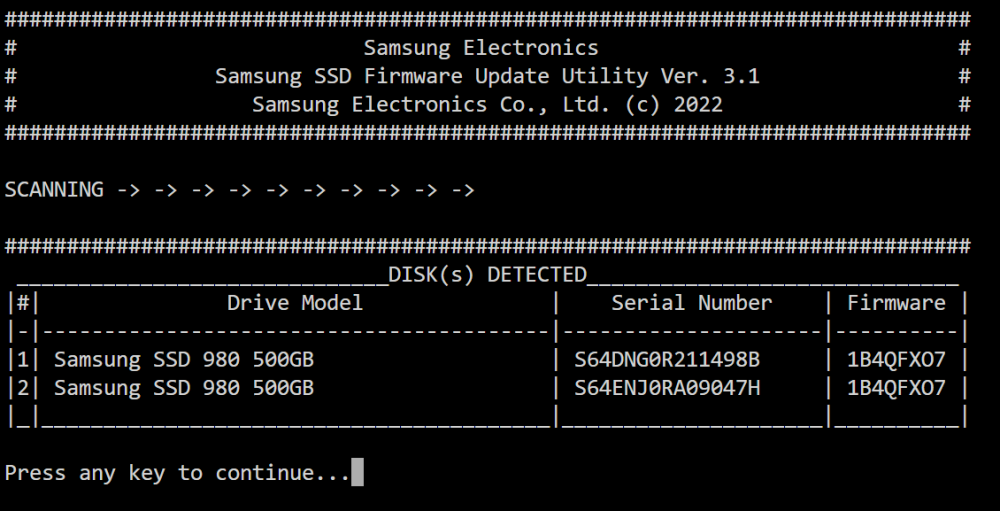
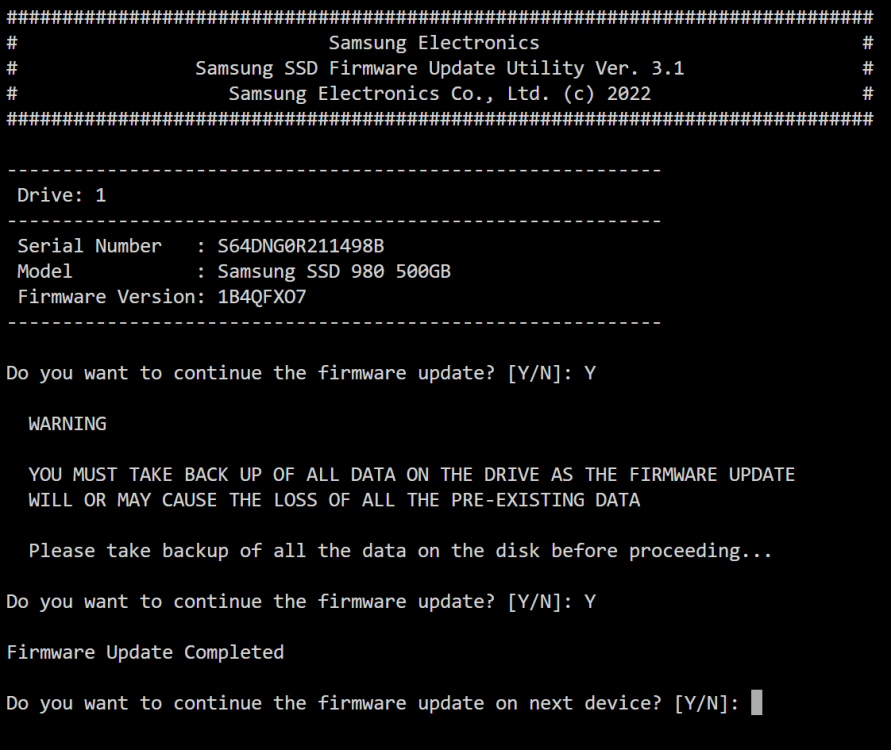
I tried the FW update my 2 980 drives. it correctly finds them, does the update - givess "Firmware update complete" message but FW still previous version (1B4QFXO7) and not new version (3B4QFXO7) for both drives. Do I have to stop the array and/or reboot? When I rerun the update the FW is still the "old" 1B4QFXO7 version.

-
My switch is unmanaged so I can't get statistics from it. Also, I have different speed clients on the LAN (100Mb and 1Gb). Why do you say that the card is 1G only? it is a motherboard NIC that supports 10/100/1000. How do I turn flow control ON/OFF?
-
In the last 24 hours I have had network loss twice on my unRAID server. This means I cannot reach it from another network device (PC, phone) on the local network. This is also true for the VMs running on the server (Windows and Home Assistant - they loose network connection - LAN and internet) To solve this I disconnect and reconnect the LAN cable connected to my server. This has happened to be in the past but maybe once every few weeks/months - Not twice in 24 hours. I see nothing in the logs regarding network loss and only see Local Master change after connection is regained. In the morning (08:48) realised no network connection (home assistant not working) so reset network cable (According to home assitant logs connection lost at 04:20) Got back from work (19:23) and again realised no network connection (home assistant not working) so reset network cable again (According to home assitant logs connection lost at 17:48) What could be the reason for this? Could it be the Local Master take over? and if so how do I turn it of on Raspberry Pi OS? Jan 15 03:32:40 Tower root: /etc/libvirt: 88.1 MiB (92360704 bytes) trimmed on /dev/loop3 Jan 15 03:32:40 Tower root: /var/lib/docker: 6.2 GiB (6674800640 bytes) trimmed on /dev/loop2 Jan 15 03:32:40 Tower root: /mnt/virtual_machines: 173.8 GiB (186667610112 bytes) trimmed on /dev/nvme0n1p1 Jan 15 03:32:40 Tower root: /mnt/downloads: 10.8 GiB (11549663232 bytes) trimmed on /dev/sdf1 Jan 15 03:32:40 Tower root: /mnt/cache: 51.7 GiB (55552176128 bytes) trimmed on /dev/nvme1n1p1 Jan 15 03:40:01 Tower crond[1439]: exit status 1 from user root /usr/local/sbin/mover &> /dev/null Jan 15 04:40:01 Tower apcupsd[6374]: apcupsd exiting, signal 15 Jan 15 04:40:01 Tower apcupsd[6374]: apcupsd shutdown succeeded Jan 15 04:40:03 Tower apcupsd[23838]: apcupsd 3.14.14 (31 May 2016) slackware startup succeeded Jan 15 04:40:03 Tower apcupsd[23838]: NIS server startup succeeded Jan 15 06:36:21 Tower ntpd[1418]: no peer for too long, server running free now Jan 15 08:48:45 Tower kernel: r8169 0000:06:00.0 eth0: Link is Down Jan 15 08:48:45 Tower kernel: br0: port 1(eth0) entered disabled state Jan 15 08:48:49 Tower kernel: r8169 0000:06:00.0 eth0: Link is Up - 1Gbps/Full - flow control rx/tx Jan 15 08:48:49 Tower kernel: br0: port 1(eth0) entered blocking state Jan 15 08:48:49 Tower kernel: br0: port 1(eth0) entered forwarding state Jan 15 08:50:01 Tower nmbd[10802]: [2023/01/15 08:50:01.932508, 0] ../../source3/nmbd/nmbd_incomingdgrams.c:303(process_local_master_announce) Jan 15 08:50:01 Tower nmbd[10802]: process_local_master_announce: Server LOBBYPI at IP 192.168.1.107 is announcing itself as a local master browser for workgroup WORKGROUP and we think we are master. Forcing election. Jan 15 08:50:01 Tower nmbd[10802]: [2023/01/15 08:50:01.932782, 0] ../../source3/nmbd/nmbd_become_lmb.c:151(unbecome_local_master_success) Jan 15 08:50:01 Tower nmbd[10802]: ***** Jan 15 08:50:01 Tower nmbd[10802]: Jan 15 08:50:01 Tower nmbd[10802]: Samba name server TOWER has stopped being a local master browser for workgroup WORKGROUP on subnet 192.168.1.104 Jan 15 08:50:01 Tower nmbd[10802]: Jan 15 08:50:01 Tower nmbd[10802]: ***** Jan 15 08:50:20 Tower nmbd[10802]: [2023/01/15 08:50:20.321813, 0] ../../source3/nmbd/nmbd_become_lmb.c:398(become_local_master_stage2) Jan 15 08:50:20 Tower nmbd[10802]: ***** Jan 15 08:50:20 Tower nmbd[10802]: Jan 15 08:50:20 Tower nmbd[10802]: Samba name server TOWER is now a local master browser for workgroup WORKGROUP on subnet 192.168.1.104 Jan 15 08:50:20 Tower nmbd[10802]: Jan 15 08:50:20 Tower nmbd[10802]: ***** Jan 15 08:58:29 Tower webGUI: Successful login user root from 192.168.1.218 Jan 15 19:23:30 Tower kernel: r8169 0000:06:00.0 eth0: Link is Down Jan 15 19:23:30 Tower kernel: br0: port 1(eth0) entered disabled state Jan 15 19:23:33 Tower kernel: r8169 0000:06:00.0 eth0: Link is Up - 1Gbps/Full - flow control rx/tx Jan 15 19:23:33 Tower kernel: br0: port 1(eth0) entered blocking state Jan 15 19:23:33 Tower kernel: br0: port 1(eth0) entered forwarding state Jan 15 19:25:31 Tower nmbd[10802]: [2023/01/15 19:25:31.349402, 0] ../../source3/nmbd/nmbd_incomingdgrams.c:303(process_local_master_announce) Jan 15 19:25:31 Tower nmbd[10802]: process_local_master_announce: Server LOBBYPI at IP 192.168.1.107 is announcing itself as a local master browser for workgroup WORKGROUP and we think we are master. Forcing election. Jan 15 19:25:31 Tower nmbd[10802]: [2023/01/15 19:25:31.349724, 0] ../../source3/nmbd/nmbd_become_lmb.c:151(unbecome_local_master_success) Jan 15 19:25:31 Tower nmbd[10802]: ***** Jan 15 19:25:31 Tower nmbd[10802]: Jan 15 19:25:31 Tower nmbd[10802]: Samba name server TOWER has stopped being a local master browser for workgroup WORKGROUP on subnet 192.168.1.104 Jan 15 19:25:31 Tower nmbd[10802]: Jan 15 19:25:31 Tower nmbd[10802]: ***** Jan 15 19:25:48 Tower nmbd[10802]: [2023/01/15 19:25:48.454809, 0] ../../source3/nmbd/nmbd_become_lmb.c:398(become_local_master_stage2) Jan 15 19:25:48 Tower nmbd[10802]: ***** Jan 15 19:25:48 Tower nmbd[10802]: Jan 15 19:25:48 Tower nmbd[10802]: Samba name server TOWER is now a local master browser for workgroup WORKGROUP on subnet 192.168.1.104 Jan 15 19:25:48 Tower nmbd[10802]: Jan 15 19:25:48 Tower nmbd[10802]: ***** Jan 15 19:36:47 Tower ntpd[1418]: no peer for too long, server running free now
-
Since 6.10 I have been getting the following errors. ACPI BIOS Error (bug): Could not resolve symbol... the SATA drive changes from SATA link 6.0Gbs to SATA link 3.0Gbps. This has not appeared in 6.9.2 (I have checked several historical logs). Mostly It happens during boot (see attached logs) but now it also happened during server idling (disks spun down). Jun 1 19:45:18 Tower webGUI: Successful login user root from 192.168.1.186 Jun 1 19:45:54 Tower emhttpd: spinning down /dev/sde Jun 1 19:45:54 Tower emhttpd: spinning down /dev/sdd Jun 1 19:45:55 Tower emhttpd: spinning down /dev/sdc Jun 1 19:45:56 Tower emhttpd: spinning down /dev/sdb Jun 1 19:45:57 Tower emhttpd: spinning down /dev/sdh Jun 1 19:45:58 Tower emhttpd: spinning down /dev/sdg Jun 1 19:48:20 Tower ntpd[1355]: kernel reports TIME_ERROR: 0x41: Clock Unsynchronized Jun 1 19:53:00 Tower root: Fix Common Problems Version 2022.05.30 Jun 1 19:53:15 Tower root: Fix Common Problems: Warning: Deprecated plugin serverlayout.plg Jun 1 19:53:29 Tower root: Fix Common Problems: Other Warning: Background notifications not enabled Jun 1 19:53:30 Tower sSMTP[30931]: Creating SSL connection to host Jun 1 19:53:30 Tower sSMTP[30931]: SSL connection using TLS_AES_256_GCM_SHA384 Jun 1 19:53:32 Tower sSMTP[30931]: Sent mail for [email protected] (221 2.0.0 closing connection k7-20020a5d6d47000000b0020e5e906e47sm1992490wri.75 - gsmtp) uid=0 username=root outbytes=895 Jun 1 19:56:06 Tower webGUI: Successful login user root from 192.168.1.227 Jun 1 21:09:07 Tower kernel: ata7: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Jun 1 21:09:07 Tower kernel: ACPI BIOS Error (bug): Could not resolve symbol [\_SB.PCI0.SAT1.SPT2._GTF.DSSP], AE_NOT_FOUND (20210730/psargs-330) Jun 1 21:09:07 Tower kernel: ACPI Error: Aborting method \_SB.PCI0.SAT1.SPT2._GTF due to previous error (AE_NOT_FOUND) (20210730/psparse-529) Jun 1 21:09:07 Tower kernel: ata7.00: failed to read native max address (err_mask=0x100) Jun 1 21:09:07 Tower kernel: ata7.00: HPA support seems broken, skipping HPA handling Jun 1 21:09:07 Tower kernel: ata7.00: revalidation failed (errno=-5) Jun 1 21:09:12 Tower kernel: ata7: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Jun 1 21:09:12 Tower kernel: ata7.00: failed to IDENTIFY (I/O error, err_mask=0x100) Jun 1 21:09:12 Tower kernel: ata7.00: revalidation failed (errno=-5) Jun 1 21:09:12 Tower kernel: ata7: limiting SATA link speed to 3.0 Gbps Jun 1 21:09:18 Tower kernel: ata7: SATA link up 3.0 Gbps (SStatus 123 SControl 320) Jun 1 21:09:18 Tower kernel: ACPI BIOS Error (bug): Could not resolve symbol [\_SB.PCI0.SAT1.SPT2._GTF.DSSP], AE_NOT_FOUND (20210730/psargs-330) Jun 1 21:09:18 Tower kernel: ACPI Error: Aborting method \_SB.PCI0.SAT1.SPT2._GTF due to previous error (AE_NOT_FOUND) (20210730/psparse-529) Jun 1 21:09:28 Tower kernel: ACPI BIOS Error (bug): Could not resolve symbol [\_SB.PCI0.SAT1.SPT2._GTF.DSSP], AE_NOT_FOUND (20210730/psargs-330) Jun 1 21:09:28 Tower kernel: ACPI Error: Aborting method \_SB.PCI0.SAT1.SPT2._GTF due to previous error (AE_NOT_FOUND) (20210730/psparse-529) Jun 1 21:09:28 Tower kernel: ata7.00: configured for UDMA/133 Jun 1 21:09:28 Tower emhttpd: read SMART /dev/sdg tower-diagnostics-20220601-2212.zip tower-diagnostics-20220601-1839.zip tower-diagnostics-20220601-0836.zip
-
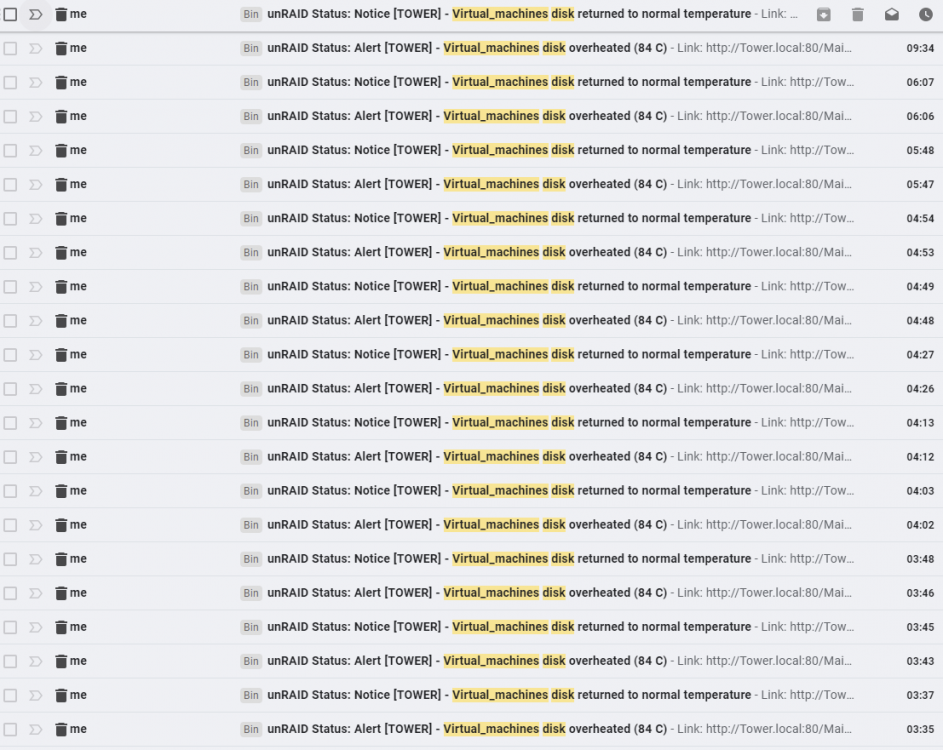
I upgraded from 6.9.2 to 6.10.0 and everything works except... I have 2 identical NVME drives and one of them gives temperature overheat warnings. Sometimes it is every few minutes and sometimes it is every few hours (not consistant). The usual temperatue is about 35-40C and the warning gives a temperature of 84C (always) for a one minutes and then back to normal - I guess it is the polling frequency. This happens when working with the server and also in complete idle (during the night). This did not happen in 6.9.2 and started immedaitely after the upgrade to 6.10.0.
-
I wouldn't have thought that a change of 10% in capacitance (330uF --> 300uF) would have such an impact on the UPS operation. But it seems it does...😕























