




Outlaws
Members
-
Joined
Everything posted by Outlaws
-
Very cool, that was the problem. I re-added the default route as 'Route 0.0.0.0/0, <gateway IP>, metric 0'. Connect is back online and the dockers have wider network access again.
-
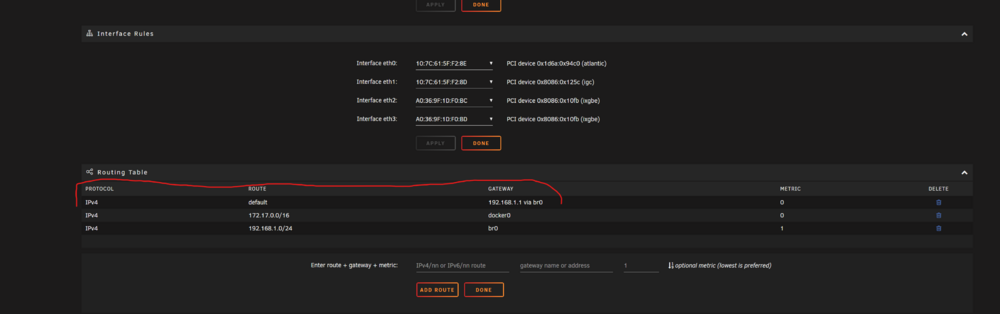
Hi Jorge, I think that I may have found the issue. I noticed that no Docker containers in bridge mode were reachable, only those with an assigned IP in my lan subnet (Plex, PiHole). When I check the network settings, it looks like I'm missing the default route to the gateway somehow? I think that certainly explains the behavior being seen. This 'working' node is still on 7.0.3, so the page looks just a bit different. I was not able to find a page for this setting in the Docs. Can you confirm that I should enter route:"default", address:"192.168.1.1 via eth0", and metric:"0" in those fields? I can then see if things come back, or let me know if there is another way to correct that. This node: Working unit:

-
Hey Jorge!! I hope you have been well, thank you for taking the time to review this concern. Unfortunately the network on the box does seem functional outside of Connect/the apps tab for a few reasons, if it were experiencing a complete network outage that would be much easier for me to continue troubleshooting. I did find that the GluetenVPN docker does not function, and doesn't seem to get network access (pings fail as well), but that is the only other hiccup I've seen aside from Connect. Working on the machine, I can: Access webGUI/SSH/perform file transfers from another LAN host I can access the Plex docker from LAN and WAN The Pihole docker is online, reachable, taking DNS traffic. This docker is NOT configured as the host machines DNS, I know that is not permitted. Yesterday, I was able to access the webGUI and manage the server via https://connect.myunraid.net -> Server Details -> Manage, however this now appears to now be getting stuck on 'Loading'. That is definitely the behavior I would expect, and I found it odd that I was able to access the device remotely yesterday from connect.myunraid.net, where it would still the Connect 'connection error' alert. Apologies that I did not get a screenshot of this behavior. I believe that previous screenshot shows the unraid-api as "status: online" and able to install a plugin over the network, but I may not be interpreting this output correctly. For the ping commands, I believe that output is indicating that ping fails because Connect itself it reporting it does not see a network? I may be misinterpreting that as well, but I can query the box from other network nodes and see ping responses without issue.
-
Hey all, I performed a hardware upgrade on one of my servers this morning, and all is well except for that it is now showing an Unraid connect error: NETWORK: queryA ECONNREFUSED mothership.unraid.net CLOUD: Socket closed This is a 7.2.2 box using the onboard motherboard NIC, which is the same thing I had before (different motherboard but no secondary NIC/wifi). I took the flash backup from Connect before the hardware change, but since I have started the machine, it has not been able to reconnect to the Connect plugin. Network access itself appears fine, as I can reach the docker containers and webGUI. I changed the DNS settings to the recommended 208.67.222.222 / 208.67.2220.220 and rebooted the machine, but still no change. I saw it recommended in another thread to try this plugin install command via the CLI, this appears to have taken but I still see the same error. I've attached Diagnostics, so please let me know if there are any recommendations for next steps. Thanks, Outlaws unii-diagnostics-20260110-1221.zip
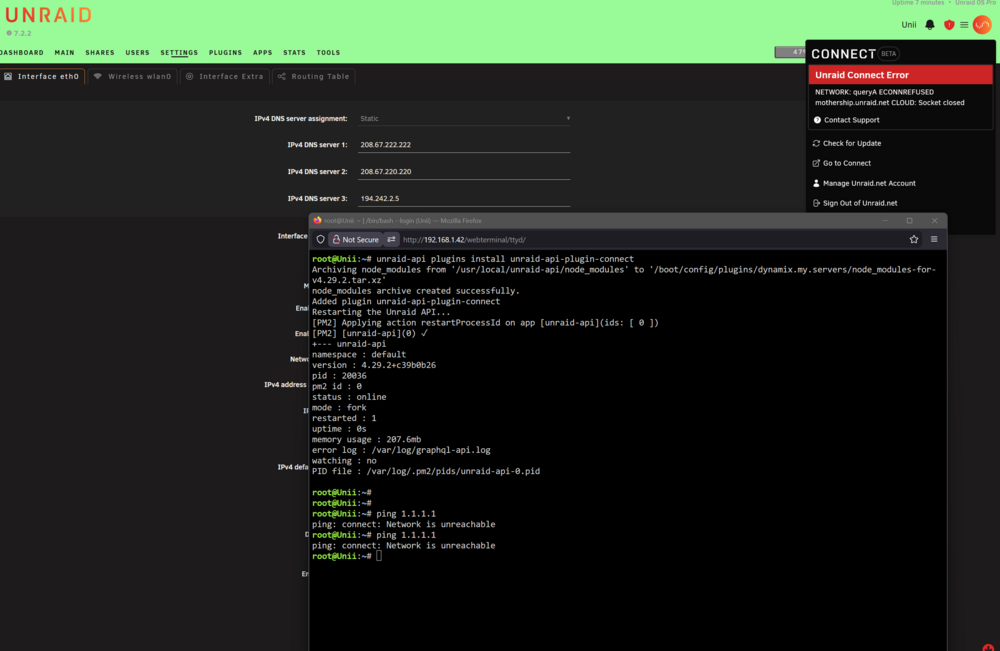
-
Perfect, I figured that was the next step and just wanted to confirm. Worked great!
-
Hey, sorry if this is a silly question - how can I update my v6 container like referenced in the post above? I converted from the old v5 a couple months ago and haven't kept up since - it's currently set on devzwf/pihole-dot-doh:latest-v6, but I haven't seen any updates in a long while and wanted to check if that had been deprecated.
-
Great, thanks for the confirmation! With that, I should be all set. I will keep an eye on the machine and hopefully the parity check completes without issue.
-
Yessir, I am 99% good and the only thing remaining is to regain some confidence in the new hardware, or finish backing it out. But I'm going to let the server sit for a few days and monitor things to make sure it's behaving as normal. I have the server configured to begin a parity check on 3/1, and am hoping I can use that to see if there are any issues with the new memory. If there are parity errors detected, I would then try to revert to the old cpu/ram/mobo and check parity again to see if those errors are valid. Because I don't know for sure that the memory integrity is 100% stable, I do NOT want 'write corrections to parity' enabled for the first run. I have disabled this under Settings -> Scheduler, but the setting remains enabled under the 'Main' tab. I can uncheck it, but it becomes checked again if I refresh the page. 1. Is the setting on the 'Main' page only for parity checks that are manually started after disabling it, which is why it appears to reset? 2. I assume then that the setting under 'Scheduler' is the only one that will be used for the scheduled parity run?
-
I am having a very good laugh now. Trurl, I think you might too - this actually fixed it & see your post at the bottom. I'm back in plex and ready to rock on.
-
Apologies, here is a new Diag as well. unii-diagnostics-20250226-0642.zip
-
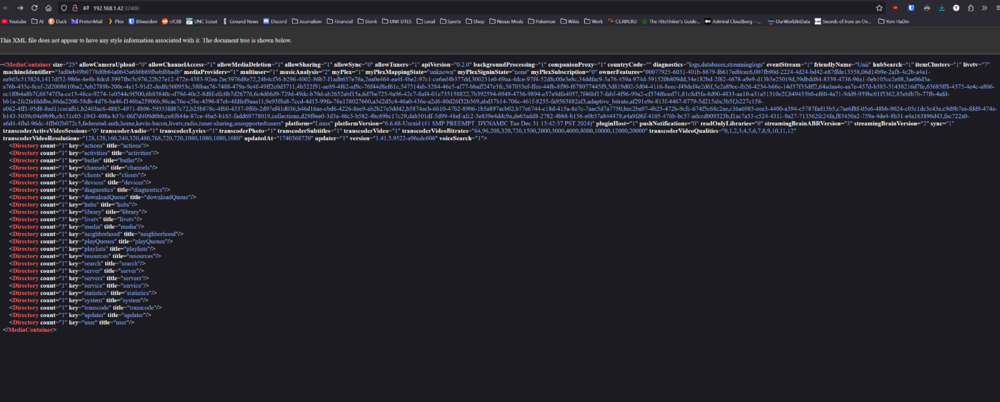
Hi All, Thank you for the help!!! I have mostly good news to report. I was able to set the shares back to Primary:Cache, stop the array, remove the new pool, and restart the array without issue. Once I started Docker again, the original containers re-appeared. Most of the containers seem to be good - however, the most important container in binhex-plexpass seems to have become broken? I've attached the output of the GUI and container log to this post, but recognize it may be best to start a new thread or post in the Binhex thread for further support with this specific issue. I don't see any specific error in the container log except a usb error, and I can verify the container has network connectivity from it's console. binhex-plexpass container log.txt
-
Sorry for the bump - a few quick edits to the plan above before I move forwards tomorrow morning. I think the best action would be to have the shares configured correctly before stopping and restarting the array - so they know exactly where to look for their original files. I plan to disable docker, flip them back to primary:cache, but not invoke the mover. Fingers crossed & I will let you know how it all goes!
-
Understood. I will probably take more actions tomorrow after I can finish testing the old equipment that I want to reinstall. So the current plan from my side would be to: 1. Take diag/flash backup 2. Not change share settings/mover actions 3. Disable Docker service 4. Stop the array 5. Remove the new SSD from the new 'cachefast' pool 6. Remove the new 'cachefast' pool 7. Start the array and pray all the disks show healthy 8. Start the Docker service, and see if containers have restored 9. Take diag/flash backup 10. Pause if things appear to have returned to normal, and consider if I still want to proceed with hardware backout Does that sound right, or would you modify any steps?
-
Jorge, thank you for confirming that these logs are not indicating another issue on my side!! I am still most likely going to revert the hardware change so I can regain some trust in the system, and that will allow me to test that new hardware further outside the chassis. My main question at this point is what settings I should configure for the appdata/system shares prior to shutting down? I am most likely going to remove the new 'cachefast' SSD after all, and repurpose that for another system. For that scenario, would it be best to 1. configure the shares as 'cache' only, not pointed to 'cachefast', and then 2. restart and mount the array without the 'cachefast' pool? Should I avoid invoking the mover since the original containers/data should still exist on 'cache', and it may try to overwrite them with the new files on /cachefast/? I can see via the File System that it created a docker.img file in /cachefast/system which is the same size as the one in /cache/system I have attached a backup of the config/shares folder from before any of these changes if that would be helpful to compare vs the current settings. Thank you again for all the assistance so far! Thomas/Outlaws original shares.zip
-
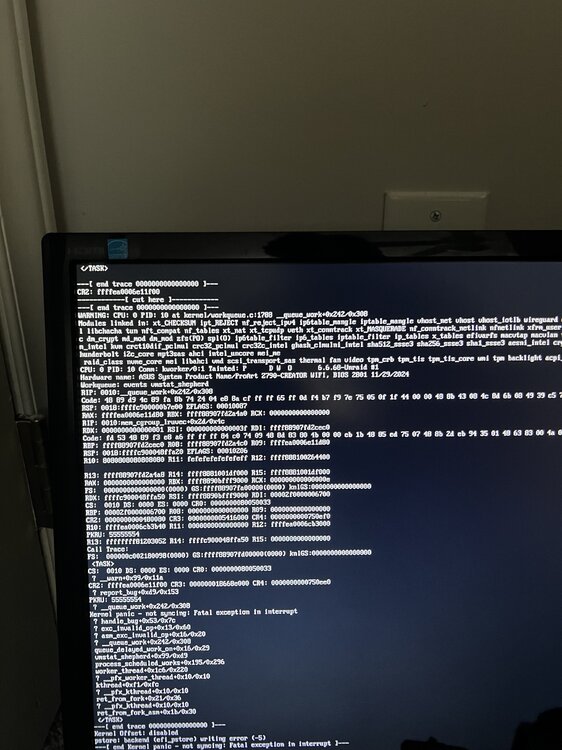
Hi trurl, I think the only thing that will make me trust this machine again is to remove the new hardware (motherboard/processor/memory) - except the new SSD, since that can be disabled via software. I am going to revert back to a known good combination of hardware hopefully Wednesday, once a part arrives overnight and I can spend some time testing it outside of the unraid box. When I looked at the Log from GUI, I can see that it reports a kernel panic overnight at 1:15am. This looks similar to the kernel panic that caused the machine to hang & reboot the morning prior. If you have any interest, I've attached a current diag + log + a capture of the original kernel panic. One thing I am still wondering - why is Fix Common Problems alerting for this? Could it not be recognizing both pools as cache for some reason? appdata: Primary: Cachefast, Secondary: Cache Feb 23 12:58:34 Unii root: Fix Common Problems: Error: Default docker appdata location is not a cache-only share unii-diagnostics-20250224-1540.zip unii-log.txt
-
Hi Jorge - love the circuit profile picture. Thanks for this note of reassurance, it makes sense that the ram is involved in crypto processes. Obviously, my biggest worry is that I will stop the array and be unable to re-mount - are there any additional checks that I can perform with the array mounted via gui or terminal to check the file system & hopefully address these concerns? Sorry if it feels like I am asking the same questions here, I really appreciate both of your input!
-
You're right, you have been a tremendous resource and sanity check - and apologies that I type as if I'm paid by the word. Support was able to share why this issue may have occurred: the syslog shows that the issue resulted from the old cache not mounting initially, this was likely caused by the bad RAM issue, and since the default shares didn't exist, Unraid created new ones on the other pool, since that one mounted. Right now, I believe that I understand the plan for getting files back on to the 'cache' pool. I also think that explains why it looks like I have duplicate filespace consumed up on both drives, if it recreated the docker and libvirt.img on both 'cache' and 'cachefast'. However, before I take any further mover actions or stop the array, I want to know if it is possible to get any reassurance that it will remount the array without similar errors that I saw with the faulty RAM installed (where password was initially rejected, and some Data drives showed Unmountable - no file system). Would there be any way to validate the file system on the drives or the password integrity? Or am I stuck with having to stop the array and finding that out when I try to remount? After that, I will revert to trying to restore the docker containers.
-
trurl, thanks again for your support and suggestions yesterday! The tech world exists because of people like you, kindly sharing their knowledge. As I had just recently upgraded my license key (in order to add the new cache drive), I have created a support case with Limetech so that they can review this issue and behavior as well. If the container XMLs are stored on the flash drive, I'm hopeful that they can be restored or pulled from one of the flash backups that I've taken recently. I have paused the mover for now, and will update here once support is able to review and offer a suggestion.
-
Okay, that sounds like an action plan. I already have the Appdata Backup plugin files from before this morning and before the HW upgrade yesterday - just wondering about backups for the backups lol. I did see on their Restore page where it notes that it cannot rebuild the Docker Containers, which I think is the part that is malfunctioning here? When I rebuild the docker container via installing one from the App store, it can detect the previous configs from appdata. It shows those 3x apps as having data on cachefast and cache, so I'm guessing it installed the new container on cachefast. What would be the best way to get Docker to recognize the previous Docker containers on 'cache', or is it better to reinstall them all? Do you think disabling Docker and setting appdata to Primary:cache; Secondary:cachefast; Mover action:cachefast->cache, then invoking mover would be the best step? I really appreciate the help on a Sunday afternoon 🥲
-
Okay - I compared the 1143 diag file vs the 1213 file, and they both show the same config for the system share - so not sure when I set that to have Array as secondary. But I have updated system to now use what you recommended, Primary:cachefast; Secondary:cache; Mover action:cache->cachefast -- but I have not invoked the mover just yet. Wanted to correct that before it tried to split the docker.img and libvirt.img across all three pools.
-
Thank you for the quick response! I have tried that suggestion with the 'domains' share as a test, since there should be 1 VM but I don't really care about it like I do the appdata information. I set the mover action as suggested and invoked the mover, and it moved about 13gb over. However, the VM manager is not starting - shows the error "Libvirt Service failed to start." and no logs. I disabled the VM Manager again and captured Diagnostics - attached. Let me know if I should rerun with the VM manager set to enabled. Could this be because I did not touch the system share - where I see libvirt.img? I see now that 'system' is set to primary:cachefast and secondary:array with Mover being cachefast -> array. I can't recall if this was the setting was done before the first diag was taken, if you could please compare and check that. I am guessing the best move would be to have it set to Primary:cachefast; Secondary:cache; Mover action:cache->cachefast and see if the VM manager can start? When I look in the File Manager, I can see the 3x docker containers I re-installed now show as having data on 'cachefast' and 'cache'. All the others are cache only. At this point, I want to 1. copy the appdata information off of cache/cachefast to the array as an additional backup, just in case it gets overwritten in a mover event - should this be possible via the built in File Manager or something like Krusader? I am hoping to just copy the files from the appdata share, not try to move the share to Array as primary/secondary. Then 2. I would like to try restoring the containers on the 'Cache' pool and have 'Cachefast' back to blank/unused. Eventually, I see that the new 'cachefast' drive was formatted without encryption. I would prefer to reformat it as btrf - encrypted to match the other cache drive and other array devices being encrypted, and because it was formatted with the bad memory installed in the system. But it looks like this involves stopping the array, so I will probably save that for another day. unii-diagnostics-20250223-1213.zip
-
Here, apologies - Diagnostics output unii-diagnostics-20250223-1143.zip
-
Hi friends, It has been quite an eventful morning. First, thank you for reading my post. There is a long story of troubleshooting that precedes this current issue, included at the bottom of the post. I am concerned about the default shares available under the 'shares' tab, which appear to have attempted to default to a new Cache pool that was created - 'cachefast' - instead of remaining on the standard 'cache' pool/drive. The intention of the new drive is to act as a dedicated share for VMs/appdata while the old would serve for the array cache and downloads. However, I hadn't made any changes to the shares configs at this point. Thankfully, my non-default Data shares appear normal and remain set to Cache (primary) and Array (secondary). The 'Fix Common Problems' plugin is alerting to this issue, with the following messages: "Share appdata set to use pool cachefast, but files / folders exist on the cache pool". Okay, so I understand that it is telling me to move the files or reconfigure the share. I tried that with the 'isos' share, but may have done something wrong? Now it is showing the opposite message when the share is set to Cache (primary) and Array (secondary). Should that be changed to Cachefast (secondary)? "Share isos set to use pool cache, but files / folders exist on the cachefast pool" When I go to 'Docker', it showed No Containers Installed. I verified that the data still exists in user/appdata, and try to re-install one of the containers. I reinstalled FreshRSS and it picked up right where things left off. Same with Observium and Plex, thankfully - so the containers may just need to be reinstalled? I would really appreciate some assistance in reviewing this issue and ways to address. Software troubleshooting is not my strong point. I am happy to post any screenshots or diagnostic information that would be helpful, but to be quite blunt, I am terrified of restarting the server at this point. There is little confidence that it will boot cleanly - I've gotten it up and online, and I would like to stop walking back to that room for now. Background: This is very truncated, but all started with a hardware upgrade yesterday, moving from an AMD 5600g/32gb/MSI B550 to an Intel 14500/64gb/Asus Z790 and installing the new SSD (cachefast). I assemble the new parts outside of the system, and it boots without issue once the BIOS is updated. However, the memory became unseated when installing the board in the chassis and I noticed that the server only showed 32gb when online. This was after multiple reboot attempts and periods of memory training, very stressful. Once the array is started and things appear normal with the new hardware, I decide to leave the memory issue until this morning. This morning, I take flash and appdata backups, and shutdown the system. I found that both sticks were not fully seated and correct that issue. However, the board takes a long time and multiple reboots again before showing any post output. Once I am able to get in to unraid after ~30m of troubleshooting, I can see 64gb and attempt to start the array. However, it does not accept my normal password. I re-enter the same pw and it is accepted, the array starts, but two of the Data disks show unmountable/no file system. My heart sinks and the server kernel panics shortly after. I am able to get back to the BIOS eventually with one stick installed, and boot back up in to unraid. The system again rejects my password then accepts, and now shows 8 of 9 Data drives as 'unmountable'. Another reboot, and I launch the Memtest86 from unraid. The memory stick almost immediately fails. I swap it for the other stick - installed in to a different slot - and the machine takes some time but eventually boots again. After 1.5hr of testing with no issue, I stop Memtest and try to boot in to unraid. Not clean, another round of memory testing and anxiously waiting for POST output. Finally, the dang thing starts and I'm back in unraid. I successfully start the array with no password error or missing disks. That is what lead to now, where I noticed the Docker containers missing. For some reason, the plugin Unraid Connect was also removed - but that is reinstalled now. Thank you again for reading my novel and any suggestions you can offer, Outlaws
-
Appreciate the reassurance Thomas, from another Thomas My upgrade went smooth, no issues. Sorry to hear you ran in to that issue Mellow - my AMD 5600G didn't run in to the same, don't believe I have that chipset anywhere. I hope you get it fixed soon!
-
Haha I've been procrastinating the upgrade from 6.11.5 - any notable concerns jumping from 6.11.x straight to 6.12.6?






