

MvL
-
Posts
593 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by MvL
-
-
Testing a bit. Is just me or is the NextCloud container a bit slow?
btw I use postgres as database is this not advised?
-
The latest picture is after a reboot so everything is normal again...
7 minutes ago, itimpi said:What is missing? /mnt/user is showing in the screenshot!
If you look to the first picture then it is missing. I also have this error in the logs:
QuoteApr 3 11:34:07 Tower shfs: shfs: ../lib/fuse.c:1451: unlink_node: Assertion `node->nlookup > 1' failed.
-
Indeed it is missing!
root@Tower:~# df -h Filesystem Size Used Avail Use% Mounted on rootfs 63G 627M 63G 1% / tmpfs 32M 372K 32M 2% /run devtmpfs 63G 0 63G 0% /dev tmpfs 63G 0 63G 0% /dev/shm cgroup_root 8.0M 0 8.0M 0% /sys/fs/cgroup tmpfs 128M 308K 128M 1% /var/log /dev/sda1 29G 438M 29G 2% /boot /dev/loop0 9.2M 9.2M 0 100% /lib/modules /dev/loop1 7.3M 7.3M 0 100% /lib/firmware tmpfs 1.0M 0 1.0M 0% /mnt/disks /dev/md1 9.1T 9.1T 66M 100% /mnt/disk1 /dev/md2 9.1T 9.1T 7.3G 100% /mnt/disk2 /dev/md3 9.1T 867G 8.3T 10% /mnt/disk3 /dev/md5 9.1T 9.0T 135G 99% /mnt/disk5 /dev/md6 9.1T 9.0T 182G 99% /mnt/disk6 /dev/md7 9.1T 7.6T 1.6T 83% /mnt/disk7 /dev/md8 9.1T 7.3T 1.9T 80% /mnt/disk8 /dev/md9 9.1T 7.4T 1.7T 82% /mnt/disk9 /dev/md10 9.1T 5.5T 3.7T 60% /mnt/disk10 /dev/md13 9.1T 3.3T 5.9T 36% /mnt/disk13 /dev/sdb1 448G 336G 111G 76% /mnt/cache shfs 91T 68T 24T 75% /mnt/user0 shfs 92T 68T 24T 75% /mnt/user /dev/sdi1 1.9T 156G 1.7T 9% /mnt/disks/downloads /dev/sdc1 1.9T 1.4T 520G 73% /mnt/disks/WDC_WD20EARS-00MVWB0_WD-WMAZA2219709 /dev/loop2 64G 3.2G 59G 6% /var/lib/dockerThe MariaDB is the only container I also used yesterday when I was messing around. Going to try another database. Let see what happens! (Don't wanna report something if I'm not completely sure).
-
Okay it happened again..
QuoteApr 3 11:34:07 Tower shfs: shfs: ../lib/fuse.c:1451: unlink_node: Assertion `node->nlookup > 1' failed.
I was messing with 2 containers when it happened. To be clear nothing was mounted via unassigned devices. I was messing with linuxserver/mariadb and linuxserver/nextcloud. Yesterday when it happened I was also messing with containers, linuxserver/mariadb and linuxserver/piwigo. So if it is container problem than it must be the linuxserver/mariadb or there is something wrong with Docker in combination with SHFS? What uses SHFS? Unassigned devices? If it is the linuxserver/mariadb conainer there should be more reports?
Update:
No of course SHFS is also part of unRAID.
df -h df: /mnt/user: Transport endpoint is not connected Filesystem Size Used Avail Use% Mounted on rootfs 63G 640M 63G 1% / tmpfs 32M 372K 32M 2% /run devtmpfs 63G 0 63G 0% /dev tmpfs 63G 0 63G 0% /dev/shm cgroup_root 8.0M 0 8.0M 0% /sys/fs/cgroup tmpfs 128M 392K 128M 1% /var/log /dev/sda1 29G 438M 29G 2% /boot /dev/loop0 9.2M 9.2M 0 100% /lib/modules /dev/loop1 7.3M 7.3M 0 100% /lib/firmware tmpfs 1.0M 0 1.0M 0% /mnt/disks /dev/md1 9.1T 9.1T 66M 100% /mnt/disk1 /dev/md2 9.1T 9.1T 7.3G 100% /mnt/disk2 /dev/md3 9.1T 867G 8.3T 10% /mnt/disk3 /dev/md5 9.1T 9.0T 135G 99% /mnt/disk5 /dev/md6 9.1T 9.0T 182G 99% /mnt/disk6 /dev/md7 9.1T 7.6T 1.6T 83% /mnt/disk7 /dev/md8 9.1T 7.3T 1.9T 80% /mnt/disk8 /dev/md9 9.1T 7.4T 1.7T 82% /mnt/disk9 /dev/md10 9.1T 5.5T 3.7T 60% /mnt/disk10 /dev/md13 9.1T 3.3T 5.9T 36% /mnt/disk13 /dev/sdb1 448G 336G 111G 76% /mnt/cache shfs 91T 68T 24T 75% /mnt/user0 ********************************* /dev/sdi1 1.9T 156G 1.7T 9% /mnt/disks/downloads /dev/sdc1 1.9T 1.4T 520G 73% /mnt/disks/WDC_WD20EARS-00MVWB0_WD-WMAZA2219709 /dev/loop2 64G 3.2G 59G 6% /var/lib/docker /dev/loop3 1.0G 17M 905M 2% /etc/libvirtI think I miss the "/mnt/user"? I have to compare that when I have rebooted the server.
-
6 hours ago, acozad1 said:
Good Evening,
I am setting up an new Unraid for Plex. I have installed docker, installed nvidia Unraid. But when i set my Network type, I cant for the life of me figure out why it will not connect to the webui. When i switch it to custom, it gets an ip address but will not connect to the plex servers.
Any ideas would be grateful. Hope all are well and safe. Thank you for your help.
You can check the logs! It is on the right site next to the Docker container. Maybe it gives you some clues..
-
In this post they also mention the error.
https://forums.unraid.net/topic/77422-666-plex-smb-shares-unresponsive/
-
Hi Johnnie, thanks for having a look.
I have the impression that it happens when I mount my NAS with unassigned devices and forget to unmount it before I switch it off. I'm absolutely not certain if this is the problem. To start I don't mount any remote shares then if it happens again I will start with the containers and VM's.
-
It happened again and now I have downloaded the diagnostic file!
I have to correct my case the user directory is not gone but it is colored red. Also the containers are not working anymore. I have to reboot the server to make it work again. Has this something to do with the overlay file system?
I think the problems start with a NAS which was mounted via unassigned devices. I powered down the NAS before I unmounted the share in unassigned devices. I think there goes something wrong.
-
I had a strange issue and I like to know the possibilities causing it.
My "user" directory vanished in my /mnt directory. The "user0" directory was colored red. I discovered it when my Docker containers where failing. I don't have a log file because I forgot to generate one before I rebooted.
-
Johnnie thanks for your reply.
After some searching on the forums I found these useful commands! "lsof" and "kill". I think they are very useful to look for open files and kill them.
-
I'm not sure but maybe I posted this in the wrong forum. Maybe this must be moved to bug reports. Please move if needed!?
-
Hi,
I had some problems yesterday with my unRAID server. I think it started when mounting a NFS share via unassigned devices for some reason it failed.
QuoteMar 27 21:10:47 Tower unassigned.devices: Mount NFS command: /sbin/mount -t nfs -o rw,hard,timeo=600,retrans=10 '192.168.100.20:/volume1/downloads' '/mnt/disks/192.168.100.20_downloads'
Mar 27 21:10:47 Tower rpcbind[25869]: connect from 127.0.0.1 to getport/addr(status)
Mar 27 21:10:47 Tower unassigned.devices: NFS mount failed: mount.nfs: access denied by server while mounting 192.168.100.20:/volume1/downloads .
Mar 27 21:10:47 Tower unassigned.devices: Mount of '192.168.100.20:/volume1/downloads' failed. Error message: 'mount.nfs: access denied by server while mounting 192.168.100.20:/volume1/downloads '.
Mar 27 21:11:14 Tower unassigned.devices: Mount NFS command: /sbin/mount -t nfs -o rw,hard,timeo=600,retrans=10 '192.168.100.20:/volume1/downloads' '/mnt/disks/192.168.100.20_downloads'
Mar 27 21:11:14 Tower rpcbind[26320]: connect from 127.0.0.1 to getport/addr(status)
Mar 27 21:12:08 Tower unassigned.devices: Mount NFS command: /sbin/mount -t nfs -o rw,hard,timeo=600,retrans=10 '192.168.100.20:/volume1/downloads' '/mnt/disks/192.168.100.20_downloads'
Mar 27 21:12:08 Tower rpcbind[27009]: connect from 127.0.0.1 to getport/addr(status)
Mar 27 21:12:53 Tower unassigned.devices: Mount NFS command: /sbin/mount -t nfs -o rw,hard,timeo=600,retrans=10 '192.168.100.20:/volume1/downloads' '/mnt/disks/192.168.100.20_downloads'
Mar 27 21:12:53 Tower rpcbind[27602]: connect from 127.0.0.1 to getport/addr(status)
Mar 27 21:13:05 Tower unassigned.devices: Removing configuration '192.168.100.20:/volume1/downloads'.
Mar 27 21:16:00 Tower sshd[26889]: Received disconnect from 192.168.100.103 port 49414:11: disconnected by user
Mar 27 21:16:00 Tower sshd[26889]: Disconnected from user root 192.168.100.103 port 49414
Mar 27 21:16:00 Tower sshd[26889]: syslogin_perform_logout: logout() returned an error
Mar 27 21:16:14 Tower sshd[29323]: Accepted password for root from 192.168.100.103 port 49931 ssh2
Mar 27 21:26:08 Tower sshd[29323]: Received disconnect from 192.168.100.103 port 49931:11: disconnected by user
Mar 27 21:26:08 Tower sshd[29323]: Disconnected from user root 192.168.100.103 port 49931
Mar 27 21:26:27 Tower kernel: mdcmd (121): nocheck cancelThen I decided to restart the server because some services became unresponsive. Then the whole server became unresponsive and doesn't want to reboot.
QuoteMar 27 21:49:48 Tower root: /mnt/cache: root kernel mount /mnt/cache
Mar 27 21:49:48 Tower root: /mnt/disk1: root kernel mount /mnt/disk1
Mar 27 21:49:48 Tower root: /mnt/disk2: root kernel mount /mnt/disk2
Mar 27 21:49:48 Tower root: /mnt/disk21: root kernel mount /mnt/disk21
Mar 27 21:49:48 Tower root: /mnt/disk22: root kernel mount /mnt/disk22
Mar 27 21:49:48 Tower root: /mnt/disk4: root kernel mount /mnt/disk4
Mar 27 21:49:48 Tower root: /mnt/disk5: root kernel mount /mnt/disk5
Mar 27 21:49:48 Tower root: /mnt/disk6: root kernel mount /mnt/disk6
Mar 27 21:49:48 Tower root: /mnt/disk7: root kernel mount /mnt/disk7
Mar 27 21:49:48 Tower root: /mnt/disk8: root kernel mount /mnt/disk8
Mar 27 21:49:48 Tower root: /mnt/disk9: root kernel mount /mnt/disk9
Mar 27 21:49:48 Tower root: /mnt/disks: root kernel mount /mnt/disks
Mar 27 21:49:48 Tower root: /mnt/user: root kernel mount /mnt/user
Mar 27 21:49:48 Tower root: /mnt/user0: root kernel mount /mnt/user0
Mar 27 21:49:48 Tower root: Active pids left on /dev/md*
Mar 27 21:49:48 Tower root: USER PID ACCESS COMMAND
Mar 27 21:49:48 Tower root: /dev/md1: root kernel mount /mnt/disk1
Mar 27 21:49:48 Tower root: /dev/md2: root kernel mount /mnt/disk2
Mar 27 21:49:48 Tower root: /dev/md21: root kernel mount /mnt/disk21
Mar 27 21:49:48 Tower root: /dev/md22: root kernel mount /mnt/disk22
Mar 27 21:49:48 Tower root: /dev/md4: root kernel mount /mnt/disk4
Mar 27 21:49:48 Tower root: /dev/md5: root kernel mount /mnt/disk5
Mar 27 21:49:48 Tower root: /dev/md6: root kernel mount /mnt/disk6
Mar 27 21:49:48 Tower root: /dev/md7: root kernel mount /mnt/disk7
Mar 27 21:49:48 Tower root: /dev/md8: root kernel mount /mnt/disk8
Mar 27 21:49:48 Tower root: /dev/md9: root kernel mount /mnt/disk9
Mar 27 21:49:48 Tower root: Generating diagnostics...I think the "Mar 27 21:49:48 Tower root: Active pids left on /dev/md*" was the reason why the server didn't want to reboot, but I like some assistance from some more experienced person! I like to prevent this in the future.
I also attached the diagnostic file.
-
I have Kobo e-reader but I understand that you can e-mail e-books from Calibre Web to a Kindle. Has someone this working? I don't want to buy a Kindle if it is not working..
-
Thank you bonienl!
-
I investigate a bit and I disabled "bounding" in network settings. It seems that my problems are solved now. I upgraded to RC3 and the Docker containers updates also the right way.
Please if my Network setting are not properly configured let me know!
-
20 minutes ago, itimpi said:
Looks as though there may be some issue at the Amazon end?
If you can get the zip file then you can manually upgrade by extracting all the bz* type files overwriting the versions the flash drive
A thank you for your reply!
16 minutes ago, bonienl said:Other people had similar issue and turned out their network was wrongly configured.
Can you post your diagnostics.
Yes, that could be the case. I struggled a bit with the setup of my network. I have add-on 10Gb Nic and I wanted that to use.
I also have issues with updating Docker containers. It shows updates but there aren't because the download is 0kb. Maybe that is related.
I attached diagnostic file. Thank you for checking my problem.
-
Hi,
For some reason I can't upgrade to the latest RC3 (from 6.7.2). The webui is acting strange. I had to click the button several times to upgrade and after that I receive a error. See the screenshot posted. When I manually copy the link in the browser it downloads the zip file from Amazon. Your thoughts?
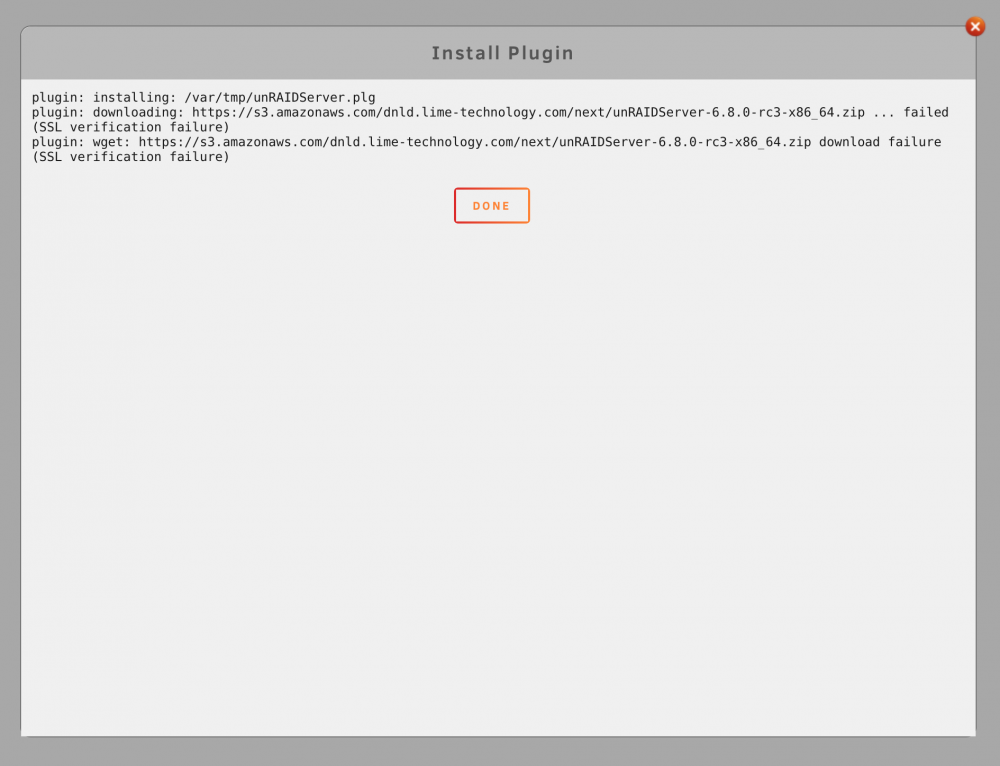
-
The Passmark memtest detected ECC error's. I'm trying to figure out which module is defect..
-
Okay.
The log of unRAID is reporting Chan#1_DIMM#0. I'm guessing this is DIMM A2? So the first DIMM position (A) on the motherboard then the second slot of DIMM A thus DIMM A2? I'm guessing there is also a channel 0. So channel 0 --> slot 1, channel 1 --> slot 2.
-
Appreciate your guidance.
I've checked the event log via IPMI and there are no events. The latest event was on 2019-5-2.
I have put Passmark memtest on usb stick and it is now running.
-
So this is ecc error? Googling Passmark memtest.
-
Investigating!
I have found the memtest86 what you see in the options during booting of unRAID. It's running at the moment. I'll keep you informed.
-
Thank you for the reply.
The weirdest part is I don't see errors in my bios log files. Any idea how to diagnostic this further?
-
I see this in the syslog:
QuoteMay 17 22:35:46 RackServer kernel: mce: [Hardware Error]: Machine check events logged
May 17 22:35:46 RackServer kernel: EDAC sbridge MC0: HANDLING MCE MEMORY ERROR
May 17 22:35:46 RackServer kernel: EDAC sbridge MC0: CPU 0: Machine Check Event: 0 Bank 13: 8c000049000800c0
May 17 22:35:46 RackServer kernel: EDAC sbridge MC0: TSC ab5c2e16c9629
May 17 22:35:46 RackServer kernel: EDAC sbridge MC0: ADDR a58102000
May 17 22:35:46 RackServer kernel: EDAC sbridge MC0: MISC 90000008000928c
May 17 22:35:46 RackServer kernel: EDAC sbridge MC0: PROCESSOR 0:306f2 TIME 1558125346 SOCKET 0 APIC 0
May 17 22:35:46 RackServer kernel: EDAC MC0: 1 CE memory scrubbing error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0xa58102 offset:0x0 grain:32 syndrome:0x0 - area:DRAM err_code:0008:00c0 socket:0 ha:0 channel_mask:2 rank:0)Are this memory error's? I've checked my bios but I can't find anything related to this..

Docker container for serving PDF's magazines
in Lounge
Posted
Not sure where to post this but I'm searching for a Docker container which can host PDF magazines so users can visit this site and read the PDF's. I've searched the app's section on my unRAID server but can't find anything. Anyone!?