




beatmurph
Members
-
Joined
-
Last visited
Everything posted by beatmurph
-
OK, sounds great. Thank you.
-
There is a lost+found folder. Is that considered the corruption? Do I need to do something with those files?
-
as requested . . . Phase 1 - find and verify superblock... - block cache size set to 3026936 entries Phase 2 - using internal log - zero log... zero_log: head block 316672 tail block 316672 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 data fork in inode 2147495232 claims metadata block 268635728 correcting nextents for inode 2147495232 bad data fork in inode 2147495232 rebuilding inode 2147495232 data fork Metadata corruption detected at 0x489748, inode 0x80002d40 dinode inode 2147495232 data fork rebuild failed, error 117, clearing cleared inode 2147495232 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 6 - agno = 3 - agno = 4 - agno = 1 - agno = 2 - agno = 5 - agno = 7 entry "Bugonia.2025.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX.mkv" in shortform directory 2147493503 references free inode 2147495232 junking entry "Bugonia.2025.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX.mkv" in directory inode 2147493503 Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... resetting inode 66987112 nlinks from 4 to 3 resetting inode 6576475519 nlinks from 4 to 3 resetting inode 2185476466 nlinks from 8 to 7 resetting inode 8661071999 nlinks from 5 to 4 resetting inode 2187127208 nlinks from 4 to 3 resetting inode 10737964385 nlinks from 7 to 6 resetting inode 12947217367 nlinks from 5 to 4 resetting inode 15033114733 nlinks from 8 to 7 resetting inode 15033550189 nlinks from 6 to 5 resetting inode 15034299570 nlinks from 3 to 2 resetting inode 15035620842 nlinks from 5 to 4 XFS_REPAIR Summary Sun Dec 21 10:40:57 2025 Phase Start End Duration Phase 1: 12/21 10:40:49 12/21 10:40:50 1 second Phase 2: 12/21 10:40:50 12/21 10:40:50 Phase 3: 12/21 10:40:50 12/21 10:40:53 3 seconds Phase 4: 12/21 10:40:53 12/21 10:40:53 Phase 5: 12/21 10:40:53 12/21 10:40:53 Phase 6: 12/21 10:40:53 12/21 10:40:56 3 seconds Phase 7: 12/21 10:40:56 12/21 10:40:56 Total run time: 7 seconds done
-
OK, so I decided to give the server a standard reboot and everything has returned to normal function. I can view the contents of disk 5 again without issue, and apparently there are 1.04TB of data on that disk instead of 177GB it had been showing previously. Should I assume the disk is good, or should I still attempt to correct the alleged file system corruption on that disk?
-
Running the server in Safe Mode I ran the disk Check and received a "File system corruption detected" response. I ran the fix and the result was a dirty log, so I chose to zero the log which resulted in a response of "File system corruption fixed" - cool. I decided to run a follow up Check to verify the fix and I got a "File system corruption detected" response again. Thoughts?
-
OK, so attempts to start the array in maintenance mode are failing: TL;DR: I'm unable to start the array in Maintenance Mode I have checked the Maintenance Mode box and clicked Start 4x. I believe this is reflected at the bottom this shot from the syslog: Each time I select Start the UNRAID working symbol (I just learned that's apparently called a "throbber"?) pops up for 2 seconds and the Main screen returns to how it was showing the array is not started. Unfortunately Disk 5 seems to agree the array isn't started: System logs are attached if needed calculon-diagnostics-20251219-1222.zip
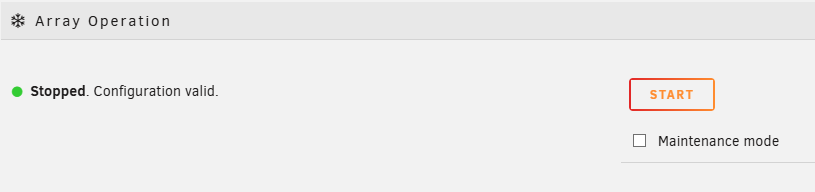
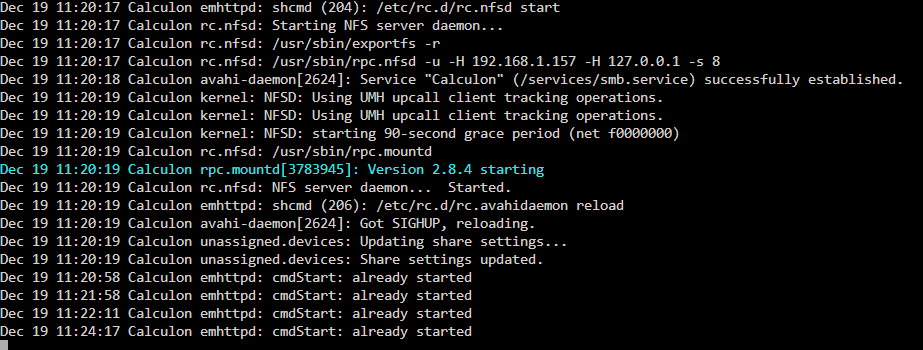
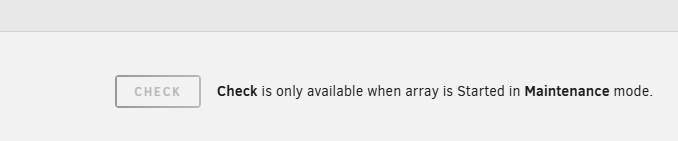
-
Thank you, I finished the extended SMART Test and will proceed with the filesystem check SMART test results are attached in case they provide any value calculon-smart-20251219-1115.zip
-
Ok, Something about writing everything out must have spurred some thought because I decided to compare the cache and array contents. What I discovered is that it seems everything currently residing on the cache drive is only new since the parity rebuild. The difference across between the cache drive download share and what is contained in the download share on the array disks represent are a perfect match to what I was seeing in Krusader during reboots (2 separate shares). More concerning is that I've now noticed that while the "main" page in the UNRAID GUI shows everything is good with Disk 5, when I click the "browse" button at the far left to view the contents, it loads a blank page that simply says "Invalid path" instead of showing the disk contents (177GB worth). I'm thinking my parity rebuild did fail. Disk 5 is the original disk I manually moved the data off via Krusader before rebuilding on a new disk. I'm not sure why I believe I was able to make space on the cache drive using Mover now though, as it seems something is preventing anything from actually moving from cache to array. Perhaps items that I had been deleting were now actually represented as free space as a result of mover? Maybe it was in my head. I'm sure that's irreverent now. I'm guessing despite my array being "Healthy" that it's actually not and I will need to rebuild with a new configuration, and whatever is on Disk 5 is lost? For now I am going to run an Extended SMART test on Disk 5 and wait your direction. A quick test came back without error.
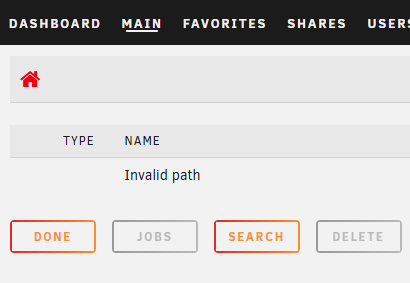

-
This is a complicated issue, and I'm not sure where to begin, but I'll try my best to describe as briefly, but effectively, as possible. About 2 weeks ago I had 2 drives fail on my dual parity array. I first attempted to fix the perceived root cause of power delivery issues, then proceeded with a parity rebuild. After the rebuild completed (seemingly successfully) about a week ago I've been seeing bizarre behavior that got worse today (described below). Background: Because I have historically had a lot of drives becoming disabled, I decided before proceeding with the parity rebuild to move the files off one of the emulated drives that had comparatively little data, then swap out the drive and rebuild from parity. While moving this data manually from the emulated disk to a good disk via Krusader, I ran into an issue where Krusader appdata wouldn't properly move to the good disk. In retrospect this is probably because I was using Krusader and I couldn't move the app data? Some of that appdata moved, as did all the appdata from the other dockers. Anyway, I don't know if that lead to the issues I figured I should mention it. The other scary thing that happened is that I had another disk issue during the rebuild. I don't remember exactly what happened (there was a lot going on) but I believe I had a separate 3rd drive suddenly show as not present during the parity rebuild. Againn, I'm not sure but something that had me very nervous because there were now 3 drives with issues at the same time. I do recall I paused the rebuild, rebooted the server and that drive returned to normal operation, so I proceeded with the rebuild which eventually completed. Again, seemingly without issue. The current issues: So once the rebuild finished, everything seemed to be operating normally and without issue at first. At some point shortly after though I noticed operations failing because they seemed to not have permissions. First I noticed I would be unable to download something through SABNZB which was giving an error that it was unable to create the necessary folder. I also noticed that the download share in Krusader had different files than what had been in there the day before. At this point I did a server reboot and everything returned (correct files in download share via Krusader & SABNZB able to download again). It was almost like the server was recognizing a separate set of shares (or at least one for downloads). I assumed it was a glitch, but the next day I woke up to alerts that appdata backup had failed. I believe the log for that showed a similar permission issue for the backup as SABNZB had been showing. I restarted the server again and was able to manually run a successful appdata backup though. These issues persisted where I would need to restart my server at least daily. Everything would be running like it historically had, then suddenly it seemed like there was a reconfiguration (or something) and many operations were unable to function. Reboots always fixed it until today. Today I was continuing to download some files while researching potential fixes and the cache drive filled up. I had noticed this has been an issue in the last few days though I previously had been able to manually clear SOME space with Mover and keep operating. Today though, most of the space stayed full so I cancelled the downloads and I rebooted the server, but this time I couldn't get Krusader the Krusader GUI to load. All my other Dockers seem to be working still. I deleted and reinstalled the docker but it still wont load. In fact the Docker logs for Krusader wont come up either. The log window shows up for a split second and vanishes. I assume all these issues are related to some kind of corruption, but I have no idea how to proceed with troubleshooting. There is additional detail I could add but this is already way too long and I think I hit the broad strokes. Logs attached. calculon-diagnostics-20251218-1851.zip
-
So I was able to swap my HBA SAS expander to a newer 12GB/s version (for what that's worth) and was able to get my drive power split down to 3 HDD per rail. It's been a little over a week and no drive issues yet - fingers crossed. Unfortunately I did have some issues with the parity rebuild, and am now having strange behavior that seems to be worsening. This issue can be closed though.So I was able to swap my HBA SAS expander to a newer 12GB/s version (for what that's worth) and was able to get my drive power split down to 3 HDD per rail. It's been a little over a week and no drive issues yet - fingers crossed. Unfortunately I did have some issues with the parity rebuild, and am now having strange behavior that seems to be worsening. This issue can be closed though.
-
I did meant it, but it sounds like there may be necessary detail that is still only in my head. I'll try to provide as much as I can here: PSU: EVGA Supernova 750G+ (modular) This has 5 total (3xSATA & 2xPERIF) connectors which I understood to be identical The PSU came with 3x SATA cables which end in 3 connectors, as well as 2x molex cables which also end into 3 connectors What I had done previously was purchase Cable Matters 1-to-1 molex to SATA adapters and attach them to the 2x molex power cables (connected to the PSU PERIF connector) so I was running 5 total cables from the PSU (3 drives per cable). This is when the 1 drive would not show as present after reboot. I'm doing some digging now and it seems the PERIF connector on the PSU end is different in that in may not have the 3.3v pin (makes sense). Since I have a mix of SAS/SATA drives, it's possible the drive wasn't showing without that 3.3v pin? My current request to EVGA is though my product registration for this specific PSU, so the request is hopefully a clear attempt to get cables specific to this power supply. I had read EVGA is a good company and willing to do that. I'm not sure if that's true, but I guess I'll find out. 120-GP-0750-X1.pdf
-
That's interesting. I actually had previously tried to use the molex->SATA power cables included with my power supply so that I could reduce the amount of splits. Unfortunately every time I powered on the sever one of the drives wouldn't show up (I don't recall exactly how it was represented in the UI, but I think as just not present). After 3 attempts to reseat and double check everything I gave up and went back to the 1 into 5 SATA set up I'm currently running. Obviously I'm still running into disable issues, but at least all the drives are present. Perhaps I should instead see if EVGA will send more molex cables instead.
-
Oh, I guess I never noticed that. I only recently set up my alerts so that's what caught my attention. Thanks again
-
OK, this is a new one to me. Yesterday I had stopped my array for a bit, then I restarted it. I believe it was at this time that the I received this alert from the server: Event: Unraid array errors Subject: Notice [CALCULON] - array turned good Description: Array has 0 disks with read errors Can you help me understand? How did the read errors just dissapear? I didn't realize that could happen. Do you have thoughts on what that could potentially mean in this case? The 2 data drives are still dissabled, but it is accurate that no read errors are displayed in the UI. calculon-diagnostics-20251202-0927.zip
-
Thank you for the clarification Jorge. As always I appreciate it. I am still going to update the HBA to a modern 12Gb version as they are cheap. In addition, I will contact EVGA to see about getting 2 addition SATA cables. I do have 5 SATA/PERIF outputs on my power supply but only 3 SATA cables. This is why I'm running 3-5 drives off each cable. I will also purchase all new splitters. Hopefully getting the down to the 3 drives/PSU cable with new cabling will help.
-
Thank you for the quick response. I know I through a lot at you. For power I'm using a 750W EVGA power supply. I wouldn't know how diagnose any issues it's having other than sound and it sounds fine. I believe it's more than a enough theoretical power for the use case. I am splitting the power though using these: https://www.amazon.com/dp/B012BPLW08?ref_=ppx_hzsearch_conn_dt_b_fed_asin_title_32 Data is being managed through a 3GB/s HBA SAS expander using these cables: https://www.amazon.com/dp/B013G4FEGG?ref_=ppx_hzsearch_conn_dt_b_fed_asin_title_31&th=1 I was troubleshooting this issue with a friend as well and he identified that I have several 6GB/s drives which can apparently encounter handshake issues when the drives spin up/down while interacting with a 3GB/s HBA. Is this a known issue that could be responsible for frequent disabling of drives by UNRAID? I am considering upgrading to a 12Gb version.
-
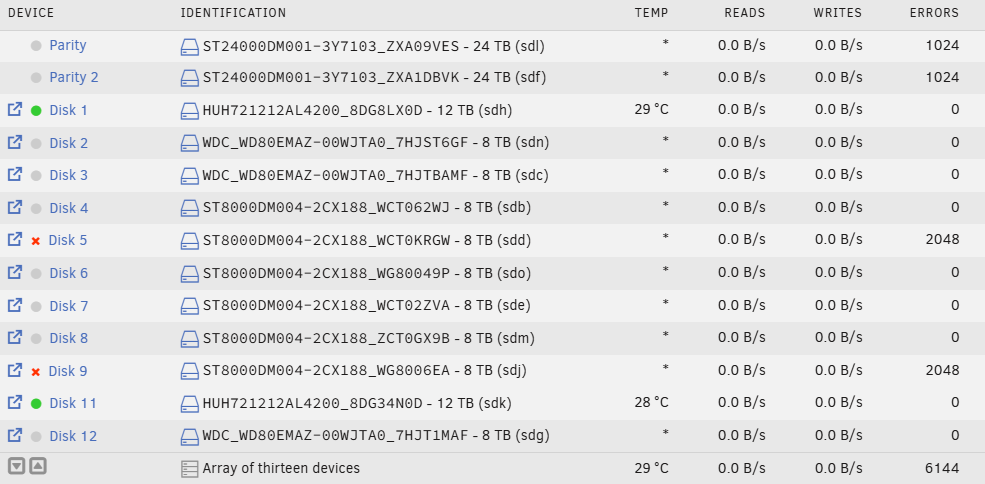
Hello, I've had ongoing issues with disks being disabled on my server. If possible, I am looking for guidance on 2 issues; one immediate, and one to try and the other long-term resolution. Immediate issue: Overnight my dual-parity server was running some of it's maintenance routines (backup & mover) when I had 2 data disks become disabled: Disk9 @0418 & Disk5 @0431. This comes on the heals of 2 other drives becoming disabled several weeks ago. I mention this other recent failure because one of those failures was a parity drive (Parity2) I had purchased new back in August after an even earlier drive failure. Because the 2 Parity drives I had were new since Aug (and expensive) I made the assumption they would be fine. What I did was move all the data off the one failed data drive, then removed it from the array. I then left the 2 parity drives in place and rebuilt parity with the new smaller array. When parity was done rebuilding all drives were showing good except Parity 2 which was enabled but showing 1024 errors. As you'll see in my current logs, and the below screen shot, that number appears to be related in a way that seems far from coincidental: So with the immediate issue I'm hoping to get your guidance on what you think the state of these drives might be and the safest way to proceeded in getting my data back to a proper protected state. I'm extra concerned because the current failure seems to be tied to the parity drive errors even though that Parity drive seems operational. Long term-issue: The ongoing issue I'd like to troubleshoot is that the problem of drives being disabled is one I haven't been able to solve since I built the server 7 years ago. This was my first server and so I have been learning, but this problem persists. I believe it's most likely power as that's what I hear is the most common reason for UNRAID to disable a drive; however, what I'm not sure about is if these seemingly minor power inconsistencies would lead to drives becoming inoperable? In the 7 years I've been running this server I've had 4 or 5 drives become unusable after becoming disabled the first time (meaning they wont pre-clear or rebuild into an array due to errors) despite the fact that I can mount them as unassigned devices and see the original data still there. Can an inconsistent power issue result in drives becoming destroyed or corrupted in some way that also makes them unusable or is this indicative of a some other possible issue? Aside from the recent purchase of used 12TB drives earlier this year (one of which wont rebuild anymore), all my drives have been purchased new. I just seem to have an unusually high failure rate. Additionally, I ran the server for 5+ years with all 11-12 drives running off of a single power connector from the power supply because I didn't know what I was doing (and obviously still don't). In that time I didn't have disk spin down set up for the array, so all disks would run at all times. Yet, in those 5+ years I had maybe 4 instances of drives being disabled? Since then I did set up a disk spin down and have split off 3 total power runs from the power supply but I seem to have disks disabling more frequently now and it always seems to be 2 drives at the same time or in quick succession. This has obviously become very frustrating because I'm spending a lot on drives that wind up in the trash and it's always a panic state with my data. Any help on troubleshooting would be very much appreciated. I haven't dine anything and have attached the diagnostics. calculon-diagnostics-20251201-1014.zip
-
That's definitely how it looked to an amateur. Thank you for all your help. It was a cheap used drive, so I guess that's the chance I took. Hopefully the other 2 last a little longer. I think that one lasted like 2 months.
-
Well, that didn't take long 😬 Parity 2 extended SMART Report attached calculon-smart-20250812-1029.zip
-
OK, I moved Parity 2 to a new slot, started the array, and the diagnostics are attached. calculon-diagnostics-20250812-1044.zip
-
Duh 🤦 sorry about that. Diagnostics are attached.calculon-diagnostics-20250812-0941.zip
-
So I did finish the previously mentioned rebuild which finished with ~250 errors on Parity 2. I then attempted to do a data rebuild on Disk 10 which got to the mid-90s on completion before stopping. In the end there were 9198 errors on Parity 2 and 1024 on the disk I was attempting to rebuild (Disk 10). I have another drive I can replace Parity 2 with, but it's too large to put in the array. Would that be best next step? I also looked at the data being emulated on Disk 10 and don't mind if I lose it. So I'm wondering if it's safer to rebuild the array altogether (new Parity) without Disk 10 if it's currently throwing lots of errors?
-
As always, I appreciate your support Jorge. I just woke up and the data-build now estimates 17 hours to completion with all the read/writes synced at 100-110 MB/s so it seems to be working? I'm now thinking the safest bet is to let it complete? I do see Parity 2 has 100 errors displayed on the main page. Does this change your recommendation?
-
I did forget to mention, if it matters, that all attempts to do the data-rebuild have been in Maintenance Mode. I did just find a post from someone with a similar issue commenting that rechecking all their physical drive connections fixed a the issue. Given I have had apparent power issues, this is a possibility. For what it's worth I did check all the connections already given the history, but I could try disconnecting and reconnecting them just in case. I don't want to make and changes or shut down the system right now in case someone is going offer advice, so I'm going to leave everything as is for now.
-
Yesterday I discovered I had 2 drives (Disk 9 & 10) from my dual parity array be disabled by Unraid (Why is it always 2 at once? Can't it ever just be 1 at a time? Ugh) likely as a result of power issues I've yet to pin down. I had a drive (sdi) sitting in unassigned devices from the previous time this happened. After that incident I ran an extended self-test on the drive which it passed so I left it in the array in case of an emergency. So the first thing I attempted (after stopping Docker, I have no VMs) was to remove one of the disabled array drives (Disk 10) and replace it with the drive (sdi) sitting in Unassigned Devices. Once I started the array, the data-rebuild began, but after about 20m I noticed the projected completion time for this 8TB drive was sitting around 400 days . . . wut? So I stopped the array and removed that drive from the array. I then decided decided to do a file system check on that drive. The test showed errors that I believe were something to the effect of "File System Corruption", so I had it run the fix and the next test showed no errors. I then attempted to put that Disk back in the array and start the data-rebuild but the result was the same: a super slow data-rebuild. As a result I pulled that drive from the array and put it back in Unassigned Devices. It now will not mount under Unassigned Devices, returning the error: " . . . mount() failed: Structure needs cleaning. dmesg(1) may have more information after failed mount system call." I ran a Short SMART Test which passed on that drive (sdi). I have added that SMART test to this post. Returning to the issuing of restoring my array, I then decided to run a Short SMART Test on the other currently disabled disk (Disk 9) and attempt to rebuild it in place if it passed. The SMART test passed so I unsigned that disk (sdj), restarted the array with no disk assigned to Disk 9, then reassigned the same drive (sdj) to Disk 9 and started the array. Data-rebuild started, seemingly normally, after starting the array and showed an estimated rebuild time for the 8TB drive of about 14 hours. However, I checked back about 15m later and it again was showing something like a year to complete the data-rebuild. The data-rebuild has now been running for 2hs 20m and is showing an estimated rebuild time of 470 days, and I've seen it fluctuate between estimates of 350-550 days. What are the chances of this happening with 2 different drives? Can anybody help me understand what is causing this? I tried to do some research, but I'm not finding anything yet. I will point out that all the drives currently in the system have been in the array during previous data and parity rebuilds. I have never had either of those take longer than 2 days and that was a result of replacing the parity drive with a 24TB drive. Any help would be greatly appreciated. I obviously can't wait a year and a half for this data-rebuild. I did download and attach the system logs as well. Many thanks calculon-diagnostics-20250807-1842.zip calculon-smart-20250807-1800.zip







