

sakh1979
-
Posts
101 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by sakh1979
-
-
29 minutes ago, Frank1940 said:
I would suggest that you post up your diagnostics file after this current parity check completes. ( Tools >>> Diagnostics ) Post this new up in a new post and perhaps one of the Gurus can find the source of your problem.
I would also suggest that you consider a UPS to help protect your server and to ensure that you get a clean shutdown if the power does fail.
Sure, I will post my diagnostics after this party check completes. I have a UPS, but sadly I didn't configure my unRAID to shutdown gracefully after power failure (my bad)
-
1 hour ago, ashman70 said:
There are others here more familiar with ResierFS and it's repair commands, although I am not sure that is going to help you. You should know, that ReiserFS is a dead file system and is no longer being developed. You should consider migrating to XFS.
Yeah, after my system is stable I am thinking of migrating to XFS. Is there a painless way to do so?
-
Just now, ashman70 said:
What is your file system? ReiserFS?
Yes, reiserfs (please see the screenshot)
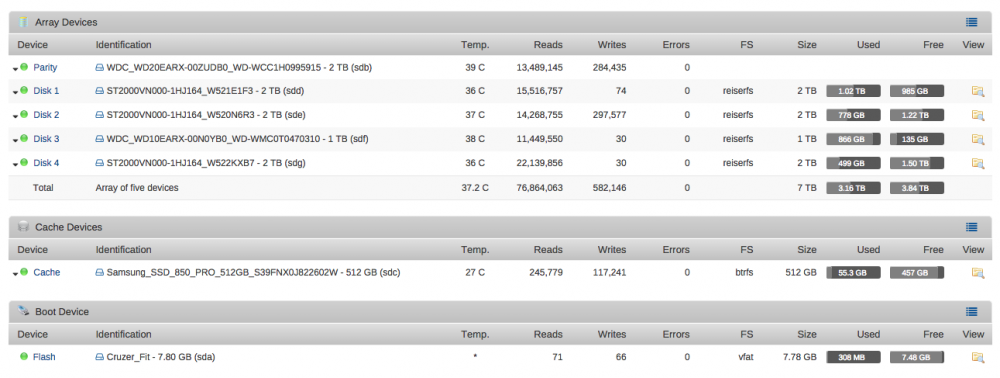
-
Just now, ashman70 said:
How often have you been running parity checks?
Beginning of every month for past 7+ years.
-
Hi -
Yesterday, my unRAID server showed 14,000+ sync errors after power failure.
However, after running parity check again it corrected all but 2 errors.
I ran the parity check again today, it is about 60% done and shows 250+ errors corrected (250+ is far better than 14,000+ errors, but it is scary). I thought, after running the parity check second time, I wouldn't see any error correction the third time.
I have been running unRAID for 7+ years, this is the first time I am facing sync errors, is this behavior normal after power failure?
Thanks,
Sagun
-
2 minutes ago, johnnie.black said:
See if that partition/function can be disabled, maybe in Windows, if not ignore the error or get a different flash drive.
Again, thanks for the help. I will probably get a new flash drive, the errors will eventually start bothering me.
-
1 minute ago, johnnie.black said:
It's your flashdrive, somwhow ther'e a second partiton/function detected as a CD-Rom:
Thanks for the prompt feedback! How do I go about fixing this issue? Do I need to get a new flashdrive?
-
Please find my syslog and diagnostics in the attachment.
Thanks,
Sagun
-
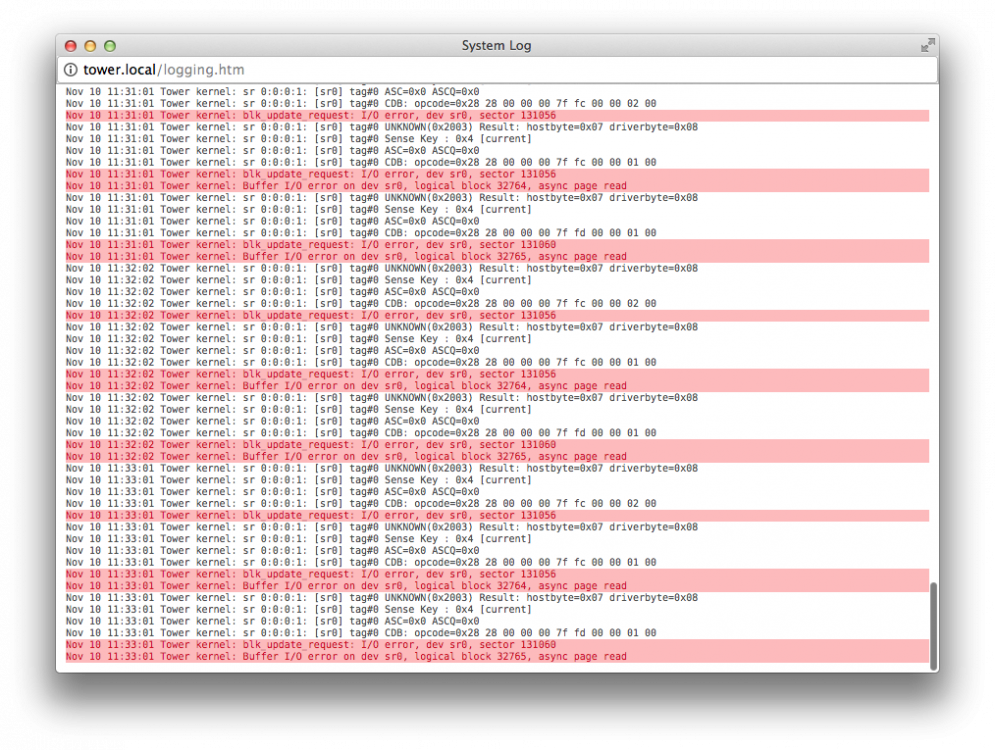
I took off the SSD from my unRAID server, and booted it just to make sure the SSD wasn't causing it.
However, during the booting of the server I still see these errors (please see the attachment). They don't repeat every minute like they did when I had the SSD plugged in, but I still see (almost) the same errors.
The error is complaining about the same sectors: 131056 and 131060, how can this be?

-
I checked the cables (SATA and power) and swapped them but I am still getting the same errors.
Even though the SSD SMART checked out fine, do you think there is something wrong with it?
Should I return the SSD and get a replacement for it?
-
The extended SMART test just ended, and it didn't find any errors on the SSD (please see the attachment).
Next, I'll switch the SATA cable and see if it will fix the errors.
Thanks,
Sagun
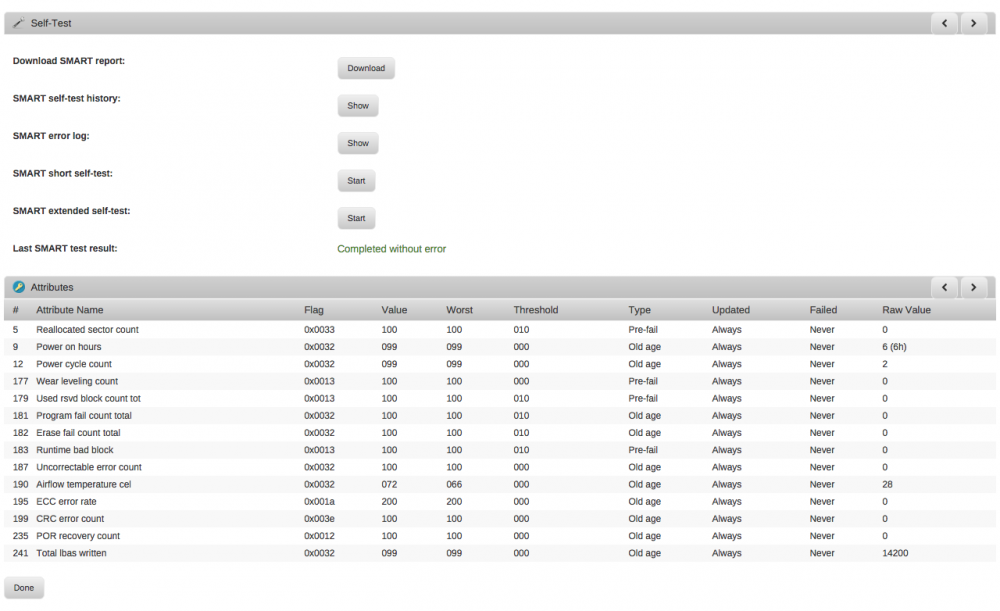
-
I just installed a new Samsung 850 Pro SSD drive, and I see a lot of error on the system log (please see the attachment). I am running unRAID version 6.3.5
However, the SMART status show green, I am currently running an Extended SMART test on the drive, and will update after it finishes.
My question is: should I return this SSD drive and get a new one?
Thanks,
Sagun
-
After I upgraded from 6.2.4 -> 6.3.2 I started seeing this error message in the log:
Feb 18 20:53:08 Tower emhttp: err: handleRequest: getpeername: Transport endpoint is not connected Feb 18 20:53:08 Tower emhttp: err: handleRequest: getpeername: Transport endpoint is not connected
I only seem them if I am connecting to unRAID via a Window's 10 laptop, connecting to unRAID with any other OS (Linux or OSX) does not give me this error message.
Is there something I can do to prevent this error from showing up?
-
johnnie.black thank your for the response, and pointing me to the right direction.
I ran the
reiserfsck --check /dev/md2
command, which after completion prompted me to run
reiserfsck --rebuild-tree /dev/md2
.
The last command after completion created a
lost+found
directory in the
/mnt/disk2
with out any content. Does this mean I was lucky and there was no data loss?
Thanks,
Sagun
-
Hi -
Recently I have been noticing lots of errors on the syslog from disk 2. However, everyday the system notification checks out fine, i.e. it reports the disks are operating fine, I don't understand the errors on the log.
Dec 26 00:03:03 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/.DS_Store (30) Read-only file system Dec 26 00:03:08 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/.DS_Store (30) Read-only file system Dec 26 00:03:08 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/.DS_Store (30) Read-only file system Dec 26 00:03:13 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:03:13 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:03:13 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/.DS_Store (30) Read-only file system Dec 26 00:03:13 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/.DS_Store (30) Read-only file system Dec 26 00:03:29 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:03:29 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:03:35 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:03:35 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:03:42 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:03:42 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:04:21 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:04:21 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:04:26 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:04:26 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:06:07 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:06:07 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:06:12 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:06:12 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/backup october 2015/.DS_Store (30) Read-only file system Dec 26 00:06:19 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/.DS_Store (30) Read-only file system Dec 26 00:06:19 Tower shfs/user: err: shfs_open: open: /mnt/disk2/Academia/.DS_Store (30) Read-only file system
I have attached my syslog in the attachment as well.
I have looked at the SMART report for disk 2, there are no relocation errors, or any errors for that matter. Please advise what should I do next to rectify the errors.
Thanks,
Sagun
-
I deleted the
/boot/config/parity-checks.log
file.
Now I have the following line in the parity-checks.log file:
root@Tower:~# cat /boot/config/parity-checks.log Jan 1 06:40:36|0|0|0
However, I am still not seeing the logs in the Parity History Log popup. Please see the attachment below.
Thanks,
Sagun
-
Yes! the drive is Seagate 2TB NAS drive.
-
I just got a new 2tb drive, ran a full cycle of pre-clear script.
The script said the drive was good, so I replaced my dying drive with the new one.
Now I am seeing this in the SMART output:
SMART Attributes Data Structure revision number: 10Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 114 100 006 Pre-fail Always - 82266888
3 Spin_Up_Time 0x0003 098 098 000 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 7
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
7 Seek_Error_Rate 0x000f 100 253 030 Pre-fail Always - 217594
9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 46
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 1
184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0
189 High_Fly_Writes 0x003a 068 068 000 Old_age Always - 32
190 Airflow_Temperature_Cel 0x0022 073 060 045 Old_age Always - 27 (Lifetime Min/Max 26/40)
191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 0
193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 8
194 Temperature_Celsius 0x0022 027 040 000 Old_age Always - 27 (0 26 0 0)
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
Is the drive bad? The "Reallocated_Sector_Ct" is still zero, but the "Raw_Read_Error_Rate" and "Seek_Error_Rate" are high. What should I do.
Thanks,
Sagun
-
Sorry about the confusion, I meant I bought total of 8GB RAM, 4 x 2GB 800MHz sticks.
I believe, my motherboard (BIOSTAR A760G M2+) takes up to 16GB RAM.
-
Yes, DDR2 are very expensive compared to DDR3.
Luckly, yesterday while browsing through Craig's List, I found someone selling 8GB DDR2 800 MHz for $30. So, I snatched it.
However, like you, if I hadn't found the dirt cheap RAM, was thinking of upgrading my current system.
But, now since my system is capable of running few Docker application, I think I'll put off upgrading the system for few more years.
-
lionelhutz, thank you for taking time to answer my question. However, I do have a follow up question...
My current unRAID server configuration is as follow:
- Motherboard: BIOSTAR A760G M2+ AM2+/AM2 AMD 760G Micro ATX AMD
- CPU: AMD Sempron 140
- RAM: 8GB (just updated the system from 2GB)
- Hard drives: 1x 2TB as a parity drive, and 4x 1TB for data drives.
Currently, I am running unRAID version 4.7. But, when a stable unRAID6 is released, I am planning on upgrading to the latest version.
I was wondering, if my current system is capable of running unRAID6, along with couple of Docker applications/VM. Notthing too fancy like GUI passthrough, or on the fly video encoding, just couple of Docker applications like postgresql, and a Linux OS.
Thanks!
- Motherboard: BIOSTAR A760G M2+ AM2+/AM2 AMD 760G Micro ATX AMD
-
Hi -
Could someone let me know if following MB, CPU, and RAM configuration works with unRAID 6?
-
CPU: AMD Phenom X4 9850 Black Edition with Vantec Cooler
-
Motherboard: GIGABYTE GA-MA78GM-S2H
-
Memory: 4x Corsair XMS2 DDR 800 2GB DIMMs
Thanks!
-
CPU: AMD Phenom X4 9850 Black Edition with Vantec Cooler
-
Just ordered one of these, thanks!
-
Hi -
I am using unRAID 4.7 Plus and a Mac Mini running OS X Lion. My unRAID hard drives are configured as below:
Hitachi 1TB (Parity)
Hitachi 1TB
Hitachi 1TB
WD 1TB
Yesterday night I copied 14 files from my Mac Mini to unRAID (each of them were few 100MB).
Thing that puzzles me is that only 13 out of 14 files got copied to unRAID. I looked at the SYSLOG and there were no error(s). So, I copied all 14 files to unRAID again, and this time it copied the 14th file.
Does any one know what happened there? I have been running unRAID for almost 2 years, and this is the first time I seeing this behavior.
Thanks,
Sagun







Parity sync error: please help with diagnostics
in General Support
Posted
Hi -
Yesterday, after a power failure I got 14,000+ sync errors, then I ran second parity check (with parity correction this time). The second parity check did "correct" all but couple of errors.
Today, I ran the third parity check (hoping I would get 0 errors). However, I ended up with 286 errors, please see the attachment.
Could someone please take a look at my diagnostics and let me know what is causing all these errors?
Thanks,
Sagun
tower-diagnostics-20171113-2331.zip