

nick5429
-
Posts
121 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by nick5429
-
-
1 hour ago, itimpi said:
You have “Included Disks” set to All so the share is not restricted to disk16 even though that might be where all files are currently stored.
That doesn't, and shouldn't, make a difference. After making your suggested change and rebooting:
I don't mean to offend -- but can I get clarity from someone else who confidently knows the correct answer to the core question here? Is this actually possible? I'm surprised that I haven't been able to find anyone else either asking this question or trying but failing to accomplish this....
1 hour ago, nick5429 said:My reading of the exclusive shares and 'pools' concepts in the release notes implied that the 'array' was a pool, largely like any other pool.
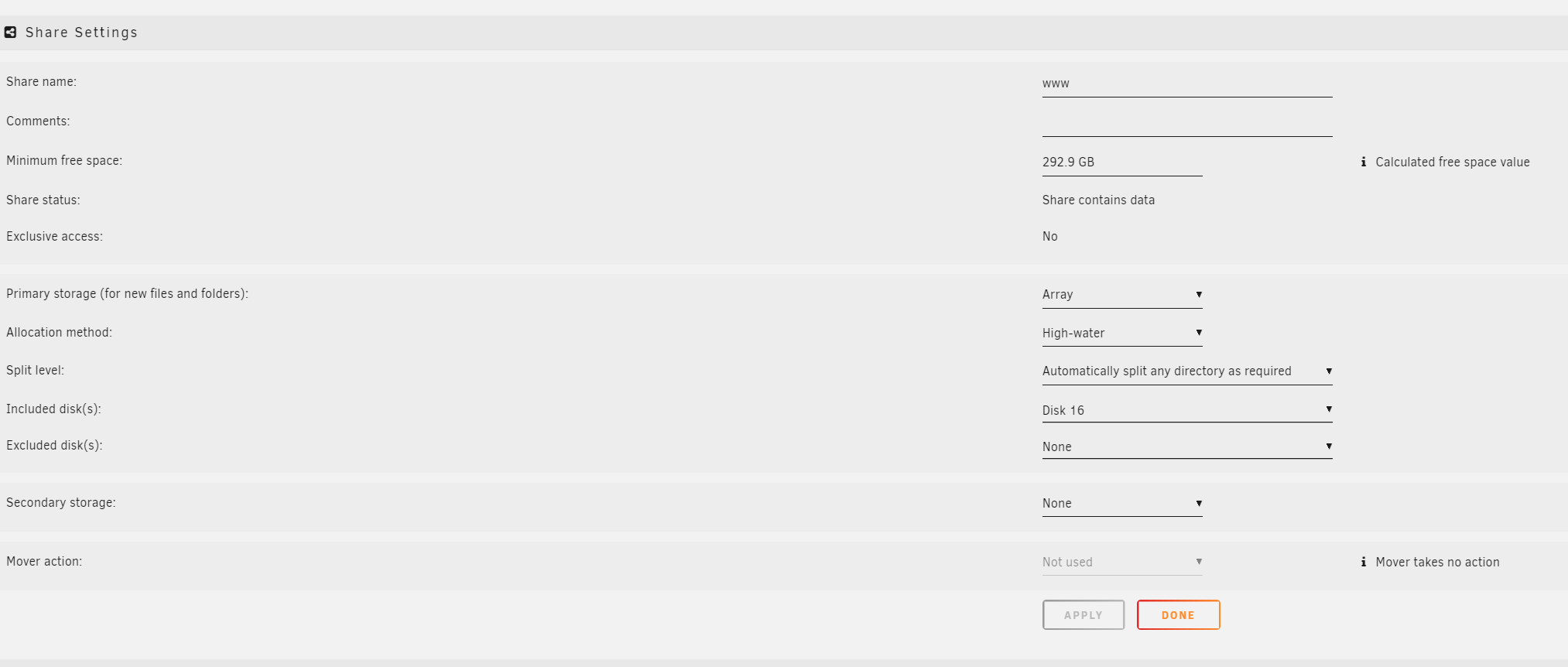
If I have ALL of the data for a share on a single disk, on the regular unraid array (along with the other usual conditions) -- is it eligible to be mounted as an 'exclusive share'?
I have several shares which I have worked to reorganize onto a single disk, inside the regular pool. NFS is disabled both on the shares, and globally. No data for those shares exists on other disks, nor empty directories. The shares still do not mount as 'exclusive share'.
Diagnostics attached
-
I'm talking above about read-only scenarios where my server has become nearly unusable. The write parity mechanism isn't coming into play.
Accessing the data I mentioned above using direct disk shares alleviates many of the problems, but I'm not interested in trying to memorize which shares belong on which disks just to use them without twiddling my thumbs while I wait for a directory listing.
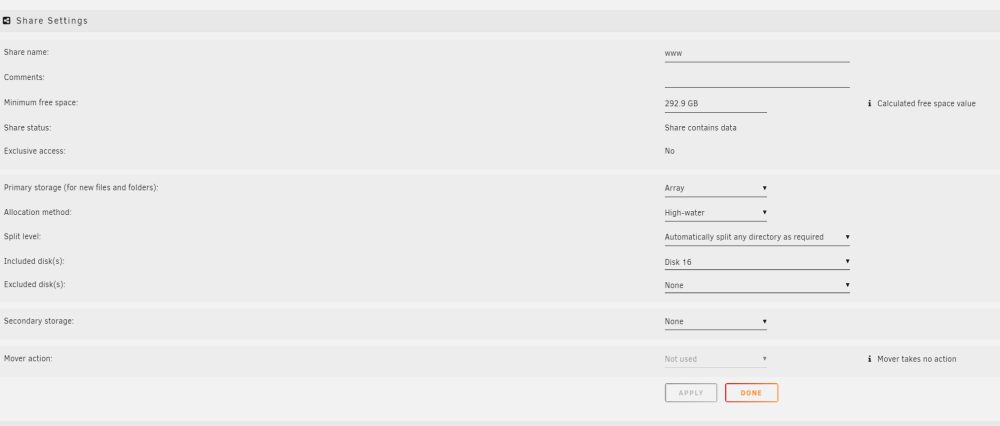
# ls -d /mnt/*/www /mnt/disk16/www/ /mnt/user/www/ /mnt/user0/www/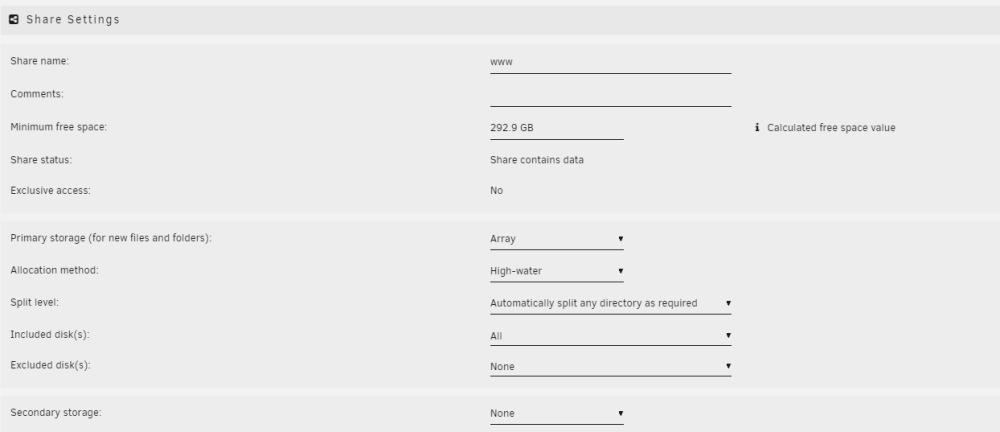
This extremely simple share stored entirely on disk16, and won't mount with 'exclusive access'. Should it be able to, or am I wasting my time trying to get this working with data on the regular unraid pool?
-
My reading of the exclusive shares and 'pools' concepts in the release notes implied that the 'array' was a pool, largely like any other pool.
If I have ALL of the data for a share on a single disk, on the regular unraid array (along with the other usual conditions) -- is it eligible to be mounted as an 'exclusive share'?
I have several shares which I have worked to reorganize onto a single disk, inside the regular pool. NFS is disabled both on the shares, and globally. No data for those shares exists on other disks, nor empty directories. The shares still do not mount as 'exclusive share'.
Performance even of browsing directories through shfs has gotten atrocious. I can't even stream a single moderate-bitrate video through a user share over samba while simultaneously browsing directories on completely separate disks via user share, without the video skipping and buffering.
-
On 2/7/2024 at 8:59 PM, dlandon said:
Update to the latest UD Preclear and test. I can only do limited testing because I don't have a drive that gives a double quote in the family string.
Updated, and get no errors on boot with the new version. Haven't testing anything beyond that. But thanks!
-
21 minutes ago, nick5429 said:
Two diagnostics along with accompanying physical terminal output screenshots, immediately after a fresh reboot. Both have all my other regular 'stuff' enabled. The only thing that changed between these boots was installing the UD preclear plugin immediately before rebooting.
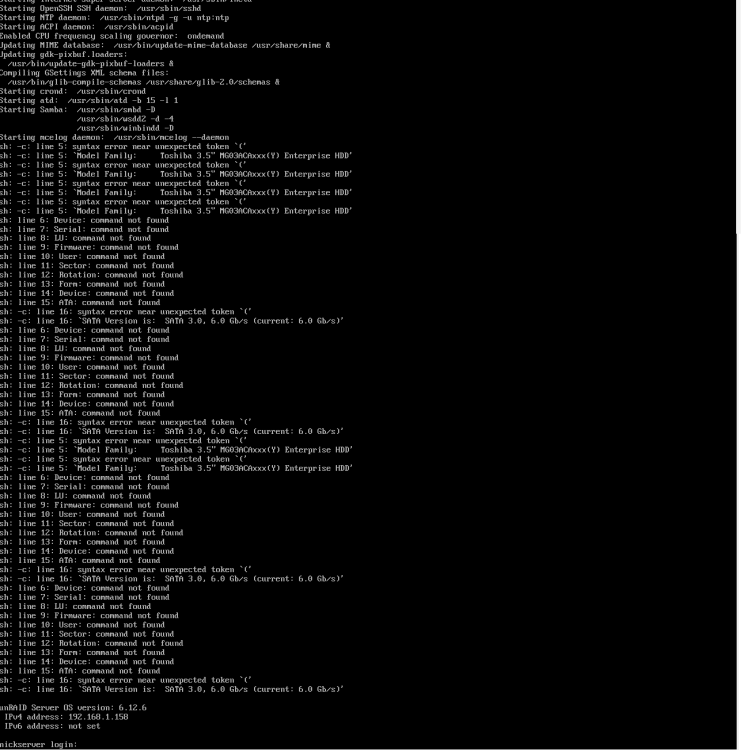
Looks like it's the quote returned in 'Model Family' for these drives:
root@nickserver:~# /usr/sbin/smartctl --info --attributes -d auto /dev/sdc smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.1.64-Unraid] (local build) Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Family: Toshiba 3.5" MG03ACAxxx(Y) Enterprise HDD Device Model: TOSHIBA MG03ACA300 Serial Number: 64OUKFOJF LU WWN Device Id: 5 000039 59c580e61 Firmware Version: FL1A User Capacity: 3,000,592,982,016 bytes [3.00 TB] Sector Size: 512 bytes logical/physical Rotation Rate: 7200 rpm Form Factor: 3.5 inches Device is: In smartctl database 7.3/5528 ATA Version is: ATA8-ACS (minor revision not indicated) SATA Version is: SATA 3.0, 6.0 Gb/s (current: 6.0 Gb/s) Local Time is: Tue Feb 6 15:13:57 2024 EST SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000b 100 100 050 Pre-fail Always - 0 2 Throughput_Performance 0x0005 100 100 050 Pre-fail Offline - 0 3 Spin_Up_Time 0x0027 100 100 001 Pre-fail Always - 11608 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 4143 5 Reallocated_Sector_Ct 0x0033 100 100 050 Pre-fail Always - 0 7 Seek_Error_Rate 0x000b 100 100 050 Pre-fail Always - 0 8 Seek_Time_Performance 0x0005 100 100 050 Pre-fail Offline - 0 9 Power_On_Hours 0x0032 001 001 000 Old_age Always - 69664 10 Spin_Retry_Count 0x0033 182 100 030 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 153 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 120 193 Load_Cycle_Count 0x0032 098 098 000 Old_age Always - 21236 194 Temperature_Celsius 0x0022 100 100 000 Old_age Always - 38 (Min/Max 16/80) 196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0 197 Current_Pending_Sector 0x0032 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0030 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0 220 Disk_Shift 0x0002 100 100 000 Old_age Always - 0 222 Loaded_Hours 0x0032 001 001 000 Old_age Always - 53131 223 Load_Retry_Count 0x0032 100 100 000 Old_age Always - 0 224 Load_Friction 0x0022 100 100 000 Old_age Always - 0 226 Load-in_Time 0x0026 100 100 000 Old_age Always - 195 240 Head_Flying_Hours 0x0001 100 100 001 Pre-fail Offline - 0
I believe this specific problem is here:
$out = timed_exec(10, "/usr/sbin/smartctl --info --attributes ".$type." ".escapeshellarg($device)." 2>/dev/null"); $info = trim(shell_exec("echo -e \"{$out}\" | grep -v '\[No Information Found\]' | grep -c -e 'Vendor:' -e 'Product:' -e 'Serial Number:' -e 'Device Model:'")); $attr = trim(shell_exec("echo -e \"{$out}\" | grep -c 'ATTRIBUTE_NAME'"));
These, and similar, need escapeshellarg()
-
On 2/5/2024 at 9:23 PM, dlandon said:
Post dioagnostics.
On 2/5/2024 at 4:06 PM, nick5429 said:BUG REPORT
Something in this plugin is causing error messages to get dumped to the physically attached console/monitor on boot, which do not appear to be shown or logged to syslog or anywhere else I've been able to locate. I narrowed it down to this plugin by removing all plugins, then individually enabling plugins and rebooting until the errors returned.These messages are not generated for me when the plugin is "installed" - only on full reboot.
It looks like something is using unsanitized input into a shell command, where the parsing chokes likely on either a single/double quote, or open-parenthesis. I'm not sure if the actual problem is the parens in "Toshiba...(Y) Enterprise HDD" logged to the screen, or some prior parsing step
See this thread for someone else with the same problem: https://forums.unraid.net/topic/143922-weird-error-messages-on-console/#comment-1297893
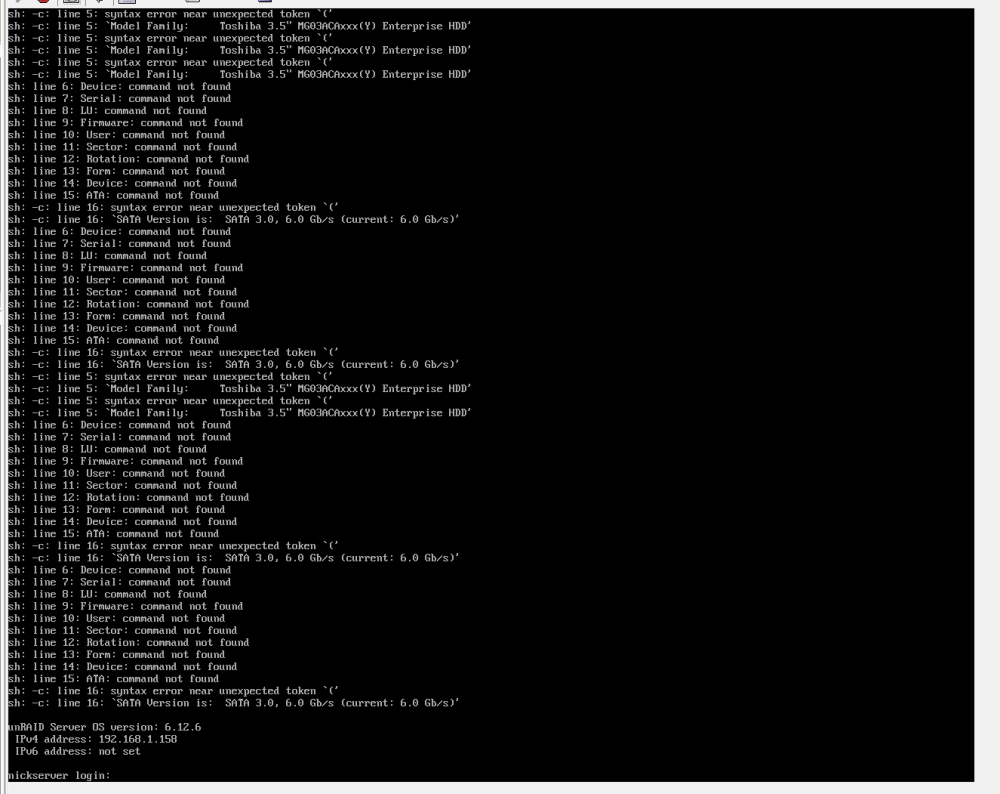
Two diagnostics along with accompanying physical terminal output screenshots, immediately after a fresh reboot. Both have all my other regular 'stuff' enabled. The only thing that changed between these boots was installing the UD preclear plugin immediately before rebooting.
-
For me, it appears to be the Unassigned Devices Preclear plugin. I reported it in the author's thread here:
-
BUG REPORT
Something in this plugin is causing error messages to get dumped to the physically attached console/monitor on boot, which do not appear to be shown or logged to syslog or anywhere else I've been able to locate. I narrowed it down to this plugin by removing all plugins, then individually enabling plugins and rebooting until the errors returned.These messages are not generated for me when the plugin is "installed" - only on full reboot.
It looks like something is using unsanitized input into a shell command, where the parsing chokes likely on either a single/double quote, or open-parenthesis. I'm not sure if the actual problem is the parens in "Toshiba...(Y) Enterprise HDD" logged to the screen, or some prior parsing step
See this thread for someone else with the same problem: https://forums.unraid.net/topic/143922-weird-error-messages-on-console/#comment-1297893
-
Did you figure out what was causing this issue? I have this as well and been trying to track it down off and on for a year or so, but haven't gone through the effort yet of iteratively enabling plugins.
The errors messages for me only log to the physical console, and not to syslog or anywhere else I've found.
My hunch is that it has to do with SAS drives.
updated edit:
I've vaguely suspected unBalance, sinceI also have problems with unBalance not working right / choking on SAS drives, but these appear related as this problem does not occur with unBalance enabled on boot. -
On 2/8/2023 at 5:37 PM, meganie said:
But in unraid I get zero lines with "egrep 'CPU|eth1' /proc/interrupts":

(eth0 is the non RSS capable onboard NIC)
I'm using the same card, and I'm pretty sure my configuration is working for RSS. The "this command must show..." just doesn't account for how the mellanox driver reports its interrupts (maybe only in certain configurations of the card/driver/firmware?). Try:# egrep 'CPU|eth*|mlx' /proc/interrupts

On the Windows side, you may also want to run something like the following, in an admin Powershell:
> Set-NetAdapterRss -Name "Ethernet_10Gbe" -MaxProcessors 6 -NumberOfReceiveQueues 6 -BaseProcessorNumber 4 -MaxProcessorNumber 16 -Profile Closest

I'm not sure why Windows is reporting 'Client RDMA Capable = False' for me; I thought at one point it showed 'True' during my setup/config of the RSS feature, but I might be mis-remembering. Docs seem to indicate that you need the Windows Workstation license for RDMA as a *server*, but not for RDMA *client*, so I'd hoped to be able to get that flipped on as well
Though OTOH, I think the ConnectX 3 [non-Pro] require correctly configured PFC or Global Pause in order to function over ethernet/fiber (ie, non-infiniband). This requires support in your switch, too.
RoCEv2 (in the ConnectX 3 Pro and beyond) might be more easily managed in that regard
-
It appears the difference is the '-a' flag. Without '-a', the command I thought was safe appears to be safe:
root@nickserver:/mnt/disk4# rsync -v --info=progress2 --remove-source-files /mnt/disk4/death /mnt/disk4/ skipping directory death 0 100% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/0) sent 17 bytes received 12 bytes 58.00 bytes/sec total size is 0 speedup is 0.00 root@nickserver:/mnt/disk4# ls -lha /mnt/disk4/death total 0 drwxrwxrwx 2 root root 66 May 12 11:14 ./ drwxrwxrwx 9 nobody users 142 May 12 11:13 ../ -rw-rw-rw- 1 root root 0 May 12 11:14 myfile1 -rw-rw-rw- 1 root root 0 May 12 11:14 myfile2 -rw-rw-rw- 1 root root 0 May 12 11:14 myfile3 -rw-rw-rw- 1 root root 0 May 12 11:14 myfile4 root@nickserver:/mnt/disk4# rsync -av --info=progress2 --remove-source-files /mnt/disk4/death /mnt/disk4/ sending incremental file list 0 100% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/5) sent 144 bytes received 49 bytes 386.00 bytes/sec total size is 0 speedup is 0.00 root@nickserver:/mnt/disk4# ls -lha /mnt/disk4/death total 0 drwxrwxrwx 2 root root 6 May 12 11:24 ./ drwxrwxrwx 9 nobody users 142 May 12 11:13 ../ -
8 minutes ago, JorgeB said:
without a backslash after DLs you're transferring from /mnt/disk6/DLs to /mnt/disk6/DLs
This was precisely the intent
rsync manpage shows:
Quote--remove-source-files This tells rsync to remove from the sending side the files (meaning non-directories) that are a part of the transfer and have been successfully duplicated on the receiving side.
Nothing got transferred, so nothing should be deleted
I'd have sworn that in the past when I was *TRYING* to copy-verify-and-delete data which was duplicated on two different disks (e.g., at times when the mover flaked out and identical data existed on both the cache and the regular array), it completely ignored (and explicitly did not delete) source files which also existed at the destination. But the trial example I just constructed shows different behaviour:
root@nickserver:/mnt# ls /mnt/disk4/death myfile1 myfile2 myfile3 root@nickserver:/mnt# ls /mnt/disk5/death myfile1 myfile2 myfile3 myfile4 root@nickserver:/mnt# rsync -av --remove-source-files --info=progress2 -X /mnt/disk4/death^Cmnt/disk5/ root@nickserver:/mnt# rsync -av --remove-source-files --info=progress2 -X /mnt/disk5/death /mnt/disk4/ sending incremental file list death/ death/myfile1 0 100% 0.00kB/s 0:00:00 (xfr#1, to-chk=0/5) death/myfile2 0 100% 0.00kB/s 0:00:00 (xfr#2, to-chk=2/5) death/myfile3 0 100% 0.00kB/s 0:00:00 (xfr#3, to-chk=1/5) death/myfile4 0 100% 0.00kB/s 0:00:00 (xfr#4, to-chk=0/5) sent 309 bytes received 128 bytes 874.00 bytes/sec total size is 0 speedup is 0.00 root@nickserver:/mnt# ls /mnt/disk4/death myfile1 myfile2 myfile3 myfile4 root@nickserver:/mnt# ls /mnt/disk5/death root@nickserver:/mnt#
-
The unBalance plugin was not giving me sane behavior, so I decided I could just rsync manually on the commandline to accomplish the same thing: moving all the data in a ~7TB share onto a newly-installed, empty 8TB disk -- the new disk is disk6
I ran the following to generate the list of commands I intended to execute:
root@nickserver:/mnt/disk6# for i in /mnt/disk* > do > echo rsync -av --remove-source-files --info=progress2 -X "$i/DLs" "/mnt/disk6/" > done rsync -av --remove-source-files --info=progress2 -X /mnt/disk1/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk11/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk12/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk13/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk14/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk15/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk16/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk17/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk18/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk2/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk3/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk4/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk5/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disk6/DLs /mnt/disk6/ # unnecessary, but I assessed as harmless rsync -av --remove-source-files --info=progress2 -X /mnt/disk9/DLs /mnt/disk6/ rsync -av --remove-source-files --info=progress2 -X /mnt/disks/DLs /mnt/disk6/ # unnecessary, but I assessed as harmless
Not all of these were fully relevant, not all had data on them -- but I briefly evaluated that 'it should be fine anyway'. I copied and pasted all those rsync commands back into my terminal, and walked away for a couple days. When I returned, disk6 had essentially zero data:
root@nickserver:/mnt/disk6# du -hs /mnt/disk6 292K /mnt/disk6
My log/alerts showed various other disks decreasing below the warning thresholds as their data was offloaded. Disk6 showed filling up; filling up; filling up to 97% warning threshold -- then 5 minutes later, dropping down to 'normal utilization level' (which appears to effectively be "empty"):
10-05-2022 20:53 Unraid Disk 6 message Notice [NICKSERVER] - Disk 6 returned to normal utilization level H7280A520SUN8.0T_001649PAR4LV_VLKAR4LV_35000cca260bc9574 (sdd) normal 10-05-2022 20:47 Unraid Disk 6 disk utilization Alert [NICKSERVER] - Disk 6 is low on space (97%) H7280A520SUN8.0T_001649PAR4LV_VLKAR4LV_35000cca260bc9574 (sdd) alert 10-05-2022 20:32 Unraid Disk 6 disk utilization Alert [NICKSERVER] - Disk 6 is low on space (96%) H7280A520SUN8.0T_001649PAR4LV_VLKAR4LV_35000cca260bc9574 (sdd) alert 10-05-2022 19:29 Unraid Disk 6 disk utilization Warning [NICKSERVER] - Disk 6 is high on usage (91%) H7280A520SUN8.0T_001649PAR4LV_VLKAR4LV_35000cca260bc9574 (sdd) warning 10-05-2022 18:05 Unraid Disk 4 message Notice [NICKSERVER] - Disk 4 returned to normal utilization level TOSHIBA_DT01ACA300_X3G716ZKS (sdx) normal 10-05-2022 16:28 Unraid Disk 2 message Notice [NICKSERVER] - Disk 2 returned to normal utilization level TOSHIBA_MG03ACA300_54G1KI4TF (sds) normal 10-05-2022 13:38 Unraid Disk 17 message Notice [NICKSERVER] - Disk 17 returned to normal utilization level HUS726060AL5210_NAGZ0EHY_35000cca242369310 (sdk) normal
Did I overlook something obvious/stupid in my rsync commands? Was that ` rsync -av --remove-source-files --info=progress2 -X /mnt/disk6/usenet /mnt/disk6/ ` command destructive after all? It shouldn't be, given the description of the --remove-source-files flag (which only deletes successfully transferred source data; and this command should have moved nothing)
In related news -- do we have a preferred xfs un-delete tool; ideally which will attempt to preserve filenames as much as possible?
") I have another empty disk large enough to hold any recovered data....
I have another empty disk large enough to hold any recovered data....
-
On 12/22/2021 at 9:05 AM, MSOBadger said:
First, a huge heartfelt thank you for this awesome utility.
I'm trying to clean up my share data so that each share is no longer scattered across numerous drives (so that "movies", for example, is limited to 3 drives and unraid only has to spin those drives up when movies are being accessed).
I'm running into a hurdle using the Gather function however; when I get to the screen to select the Target drives to gather the share data on to, only a few drives are showing up (and they don't happen to be the drives that I want to target). I'm guessing I'm probably just missing something simple. I've disabled all of my dockers and VMs so nothing should be accessing drives. I've tried spinning up all the drives before hand as well.
I have been able to work around this by slowly piecemealing the transfer by using Scatter to move share data disk-by-disk, but that's obviously a much more manual process.
Any ideas?
Thanks in advance!
It doesn't look like this report was ever addressed, and I have this same problem
For my case...
the target disk I *want* to select has enough free space (7.5TB out of 8TB) to move the entire usershare that I've selected (~6.2TB), but that disk does not show in the available targets. Often, there are zero options for selecting the target. Other times, unBalance offers me target disks that have <1TB free (for this 6+TB transfer)
Docker-safe new permissions has been recently run; all dockers are stopped
Any idea what's going on here or how to resolve?
-
On 7/21/2019 at 5:05 PM, Forusim said:
Hello @gfjardim
When a drive is mounted as unassigned (not even shared), your plugin issues "lsof -- /mnt/disks/tempdrive" command every few seconds.
This causes remarkable CPU spikes (30% out of 400%) via process "php" and don´t let that drive ever spin down.
Would it be possible not to issue this command when no preclear activity takes place?
As workaround I have to uninstall this plugin, when not used.
This enhancement is much appreciated.
Hey this is happening to me now as well [2 years later]. Unraid 6.9.3, plugin version 2021.04.11 [up-to-date]
I noticed 'lsof' was pegging an entire cpu to 100%; investigated and it's coming from /etc/rc.d/rc.diskinfo
From /var/log/diskinfo.log , it looks like this benchmark is being run continuously in a loop, with no delay/sleep between iterations
Mon Oct 18 22:17:49 EDT 2021: benchmark: shell_exec(lsof -- '/mnt/disks/SanDiskSSD' 2>/dev/null | tail -n +2 | wc -l) took 14.509439s. Mon Oct 18 22:18:03 EDT 2021: benchmark: shell_exec(lsof -- '/mnt/disks/VolatileSSD' 2>/dev/null | tail -n +2 | wc -l) took 13.332904s. Mon Oct 18 22:18:47 EDT 2021: benchmark: shell_exec(lsof -- '/mnt/disks/SanDiskSSD' 2>/dev/null | tail -n +2 | wc -l) took 13.167924s. Mon Oct 18 22:19:00 EDT 2021: benchmark: shell_exec(lsof -- '/mnt/disks/VolatileSSD' 2>/dev/null | tail -n +2 | wc -l) took 12.680031s. Mon Oct 18 22:19:44 EDT 2021: benchmark: shell_exec(lsof -- '/mnt/disks/SanDiskSSD' 2>/dev/null | tail -n +2 | wc -l) took 12.882862s. Mon Oct 18 22:19:58 EDT 2021: benchmark: shell_exec(lsof -- '/mnt/disks/VolatileSSD' 2>/dev/null | tail -n +2 | wc -l) took 14.628200s. Mon Oct 18 22:20:44 EDT 2021: benchmark: shell_exec(lsof -- '/mnt/disks/SanDiskSSD' 2>/dev/null | tail -n +2 | wc -l) took 14.887803s. Mon Oct 18 22:20:57 EDT 2021: benchmark: shell_exec(lsof -- '/mnt/disks/VolatileSSD' 2>/dev/null | tail -n +2 | wc -l) took 13.041714s.Those drives are mounted by Unassigned Devices. I'm not sure what this benchmark was trying to accomplish, as I don't have any preclear's running, and haven't since a reboot.
-
I have two separate dockers running delugevpn on my unraid machine via PIA vpn. They both worked well simultaneously with PIA's 'old' network and deluge ~2.0.3. After upgrading to the newest delugevpn docker and PIA's 'nextgen' network (identical .ovpn files for each), only one of them works properly.
One works perfectly, the other gets stuck on Tracker Status: 'announce sent' (vs 'announce ok'), with the exact same public linux test torrent (or with any other torrent). The logs appear to show that both are properly getting separate forwarded ports setup with no obvious errors, and I don't think I changed anything other than what was required to move to nextgen PIA vpn.
They're setup basically identically except for different download folders, and different host port mappings (went port+1 for each). Both running in network bridge mode.
Any ideas?
-
How can I select multiple drives at once to process in a 'scatter' operation? I have 5 disks that I want to move all the data off and decommission; doing them one at a time (and needing to circle back and remember to move on to the next one at the appropriate time) is going to be a hassle.
-
Good catch, where do you see that in the diag reports? I found similar info digging in the syslog once you pointed it out, but not formatted like you have quoted. Is there a summary somewhere I'm missing?
Looks like these are the commands for SAS drives:
sdparm --get=WCE /dev/sdX sdparm --set=WCE /dev/sdXPossibly has to be re-enabled on every boot, from internet comments?
Will give that a try and see how the 2nd parity disk rebuild goes. Initial regular array write tests with 'reconstruct write' definitely see speed improvement after enabling this on the parity drive.
-
You're likely right, I misinterpreted the output of iostat and came to the wrong conclusion. 'write request size' is listed in kB, writes are just being buffered to 512kB chunks before written. Unlikely to have anything to do with drive block size.
I did a brief parity check for speed test after the rebuild finished, and a read-only parity check was going at ~110MB/sec. Still, something's not right if the 5-6TB portion of the rebuild (when the new fast drive is the only disk active) is going at 40MB/sec, when it was >175MB/sec during the preclear
nickserver-diagnostics-20200717-1007.zip
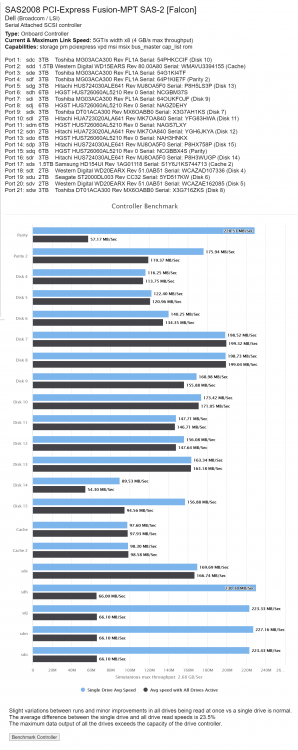
"routine writes" to the array (non-cache, tested with dd) with the new 6tb drive installed go at about 40MB/sec, regardless of RMW or 'turbo write' mode. The new drives are all 6TB SAS, and individually perform great. Something odd showed up when testing with the diskspeed plugin, which shows that when all drives are in use -- the new 6TB SAS ones consistently take a much bigger perf hit than the legacy SATA's (when if anything I'd expect them to be faster; and alone they are faster)
Diags and diskspeed results attached
-
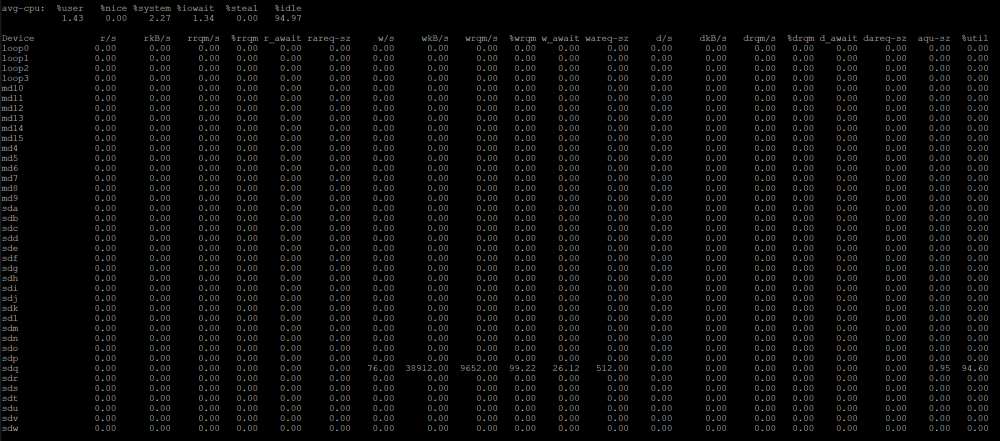
I'm in the process of adding several 6TB 512e drives (physically 4k block size, but emulate 512). Right now, my parity drive upgrade with the first drive is going *extremely* slow compared to expected speeds with this new drive, even on the portion of the drive that is larger than any other drive (ie, no reads are required)
All other drives in the system are <=3TB, and the parity rebuild onto the 6TB drive is currently at ~5TB position, but is only writing at <40MB/sec. The only activity is write to the new parity drive, and no reads are happening at all. From preclear testing, even the slowest portion of this one disk writes at >175MB/sec.
Digging into iostat details, it looks like unraid is using write size of 512 instead of 4k, which is likely slowing this down significantly (I assume the drive internally does a read-modify-write to emulate 512B writes to a 4k physical sector?).
How can I tell unraid to use a 4k access size for parity checks/rebuilds?
New filesystems can be done with a 4k block size which should help for the new data disks, but if my parity drive is 512e, it would also likely be faster if unraid used 4k access size for everything, not just new filesystems; is there a setting to change this as well?
-
I have an old nvidia card which requires the 340.xx driver line for support, and the card *does* support nvenc/nvdec.
I'm able to compile and load the appropriate nvidia driver myself, but I'd also like to take advantage of the other modifications that have been done as part of the work for this plugin for docker compatibility, beyond simply loading the driver.
Where is the source for the additional changes made to the underlying unraid/docker system with build instructions to create these distributed packages? A general outline is fine, I can figure it out from there.
-
Hm. Well, I blew away the old installation, and re-selected the packages (being careful to only select things that weren't already installed by the underlying unraid system), and it seems fine.
Good for me, but doesn't fully solve the answer of whether it was a problem with my flash, or a problem with some built-in package system being replaced. If I feel bold (and feel like dealing with another crashed system), maybe I'll re-enable having DevPack install all the old packages later
-
Something in this prevents my server from booting on unraid 6.4.1

Took a couple hours for me to narrow it down to this plugin. This was working fine with my setup on 6.3.5 and I didn't enable/disable any packs. Here's what I've got in DevPack.cfg:
attr-2_4_47="no" binutils-2_27="yes" bzip2-1_0_6="yes" cxxlibs-6_0_18="yes" expat-2_2_0="no" flex-2_6_0="no" gc-7_4_2="yes" gcc-5_4_0="yes" gdbm-1_12="no" gettext-0_19_8_1="no" glib2-2_46_2="no" glib-1_2_10="yes" glibc-2_24="yes" gnupg-1_4_21="no" gnutls-3_5_8="yes" gpgme-1_7_1="no" guile-2_0_14="yes" json-c-0_12="no" json-glib-1_2_2="no" kernel-headers-4_4_38="yes" libelf-0_8_13="no" libevent-2_1_8="no" libgcrypt-1_7_5="no" libgpg-error-1_23="no" libjpeg-turbo-1_5_0="no" libmpc-1_0_3="yes" libnl-1_1_4="no" libpcap-1_7_4="no" libunistring-0_9_3="no" libX11-1_6_4="yes" make-4_2_1="yes" ncurses-5_9="yes" openssl-1_0_2k="no" pcre-8_39="no" pkg-config-0_29_1="yes" sqlite-3_13_0="no" tcl-8_6_5="yes" tclx-8_4_1="no" tk-8_6_5="no" xproto-7_0_29="no" xz-5_2_2="yes" zlib-1_2_8="yes"This caused a similar symptom as in
Unfortunately, I wasn't able to capture a more complete log, since it completely locks up the system. The files in /boot/config/plugins/DevPack/packages/6.4 that it managed to download before locking up are:
binutils-2.27-x86_64-2.txz* bzip2-1.0.6-x86_64-1.txz* cxxlibs-6.0.18-x86_64-1.txz* gc-7.4.2-x86_64-3.txz* gcc-5.4.0-x86_64-1.txz* glib-1.2.10-x86_64-3.txz* glibc-2.24-x86_64-2.txz* gnutls-3.5.8-x86_64-1.txz* guile-2.0.14-x86_64-1.txz* kernel-headers-4.4.38-x86-1.txz* libX11-1.6.4-x86_64-1.txz* libmpc-1.0.3-x86_64-1.txz* make-4.2.1-x86_64-1.txz* ncurses-5.9-x86_64-4.txz* packages-desc* packages.json* pkg-config-0.29.1-x86_64-2.txz* tcl-8.6.5-x86_64-2.txz* xz-5.2.2-x86_64-1.txz* zlib-1.2.8-x86_64-1.txz*Unfortunately, they're all timestamped in the same second, so I'm unable to determine processing order that way.
PS -- this is super handy! Hope you get it working again soon, and thanks
-
I had this same problem, and it went away when I disabled the DevPack plugin
Not sure yet what in there might be triggering it
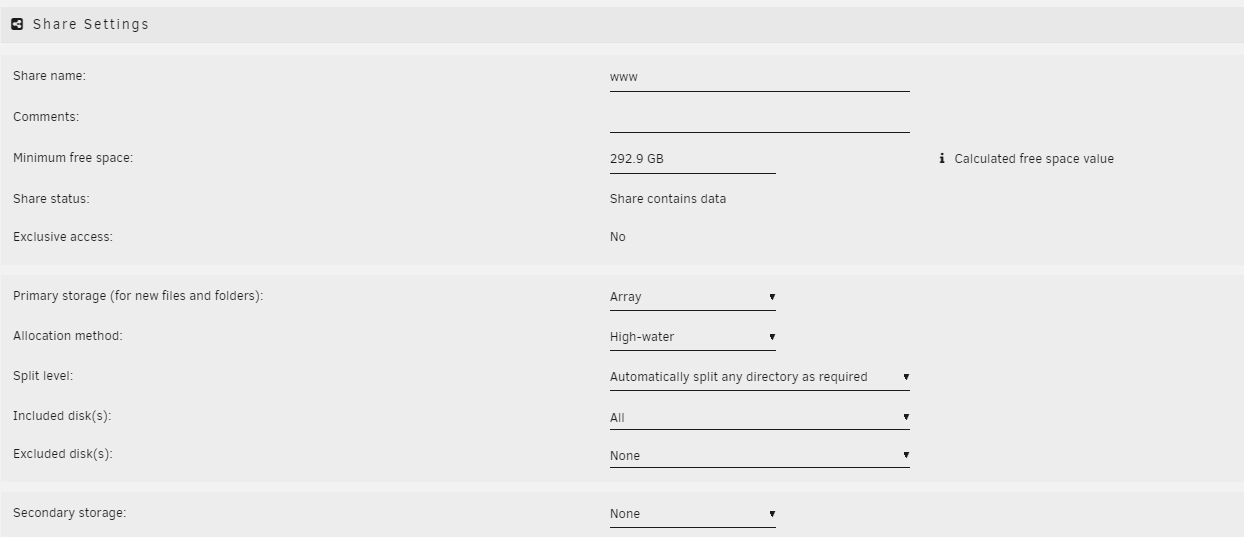
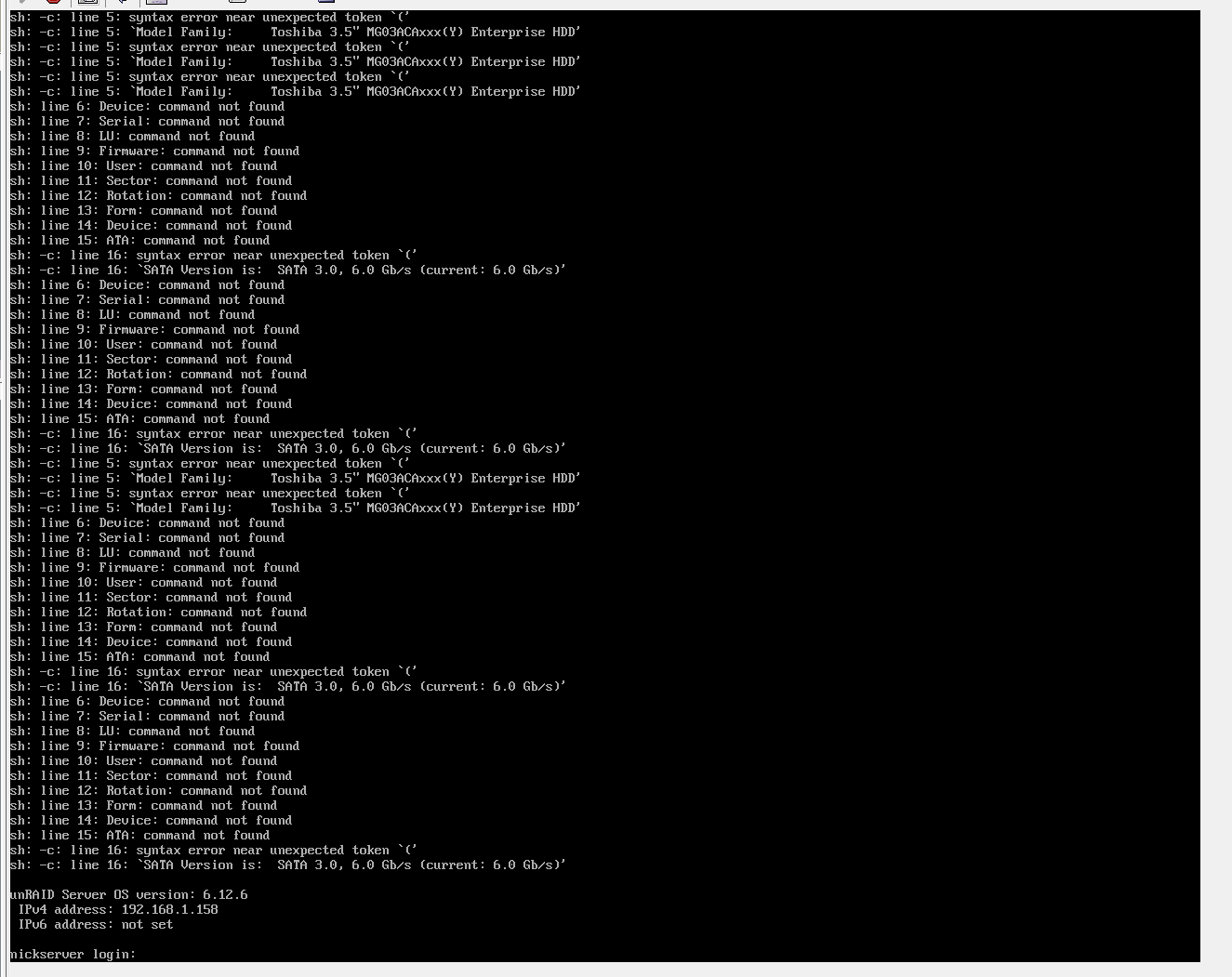
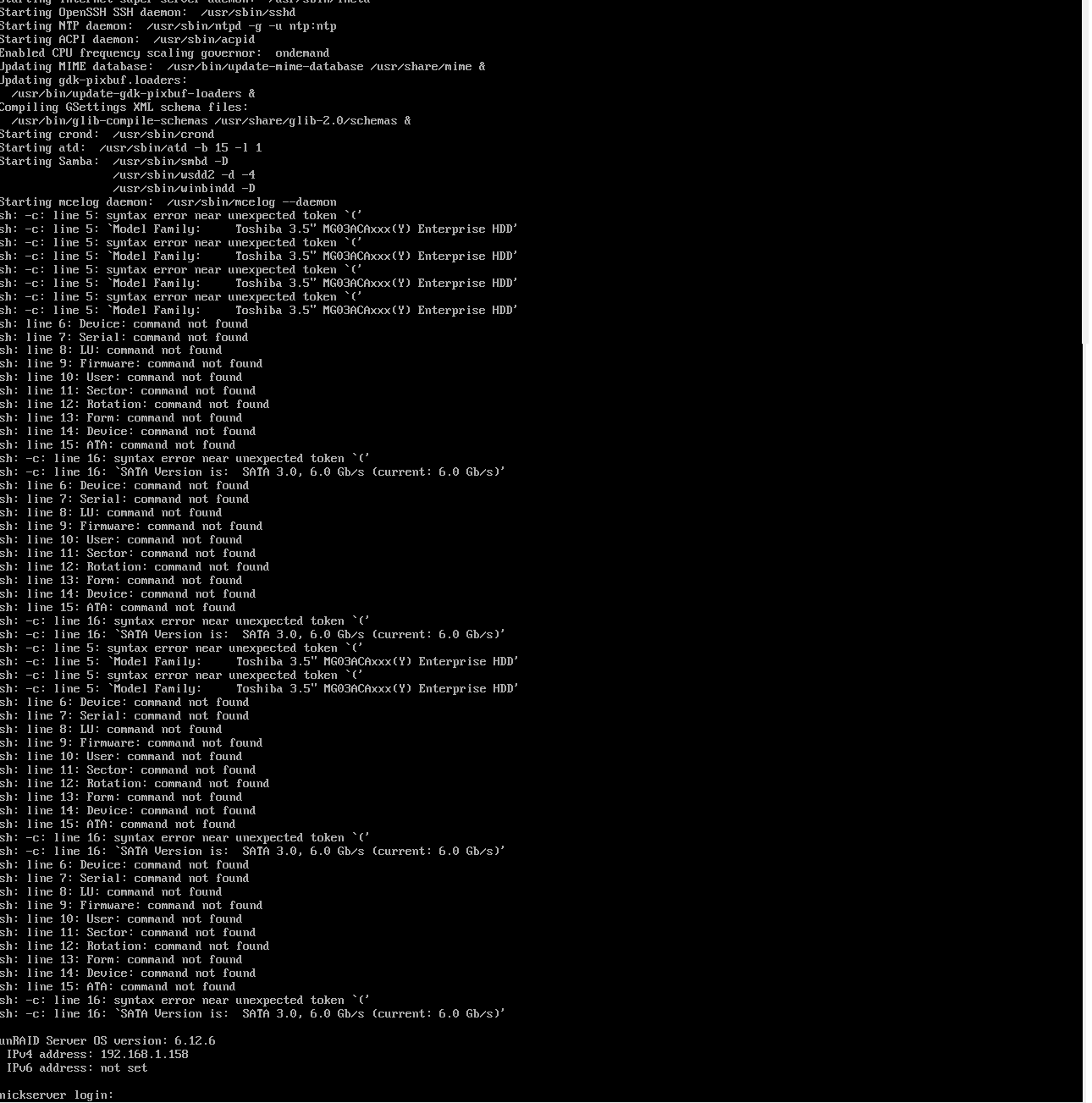





Exclusive shares -- can it be on a single drive, on the main array?
in General Support
Posted · Edited by nick5429
Thanks for clarifying
It would be great to have this documented much more clearly/prominently and explicitly, since in other places IIRC parallels are/were drawn between the prior concepts of 'cache' and 'main unraid array' as 'pools'. If that were the case, then what I was originally trying to do ought to have been possible