

hawihoney
-
Posts
3493 -
Joined
-
Last visited
-
Days Won
7
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by hawihoney
-
-
44 minutes ago, Amane said:
Ich verdächtige auch den automatischen Optimierungsprozess der Disk (SSD defragmentieren), könnte auch schlecht sein für eine vdisk auf dauer.
Schau mal hier. Diverse Optimierungsmechanismen für Windows VMs werden hier explizit beschrieben:
https://docs.unraid.net/unraid-os/manual/vm-support/
Im Übrigen stehe ich nach wie vor zu meinen oben getroffenen Aussagen bzgl. CPU Passthrough ... Ob Threads zwischen 8 Kernen springen oder 128 spielt überhaupt keine Rolle. Technisch ist das ein Kontext-Wechsel des Instruction Pointers und den Registern sowie Pages. Das ist egal wohin der Wechsel erfolgt - ob zu Kern/HT #4 oder #112. In dem einen Fall stehen aber nur 8 zur Auswahl, im anderen Fall 128. Ist wie am Buffet. Wenn von den 8 Schüsseln gerade 2 leer sind ist das blöder als bei 128 Schüsseln
")
-
21 hours ago, Lons said:
Beim transcodieren mittels Handbreak und 3 laufenden Hdd's bin ich auf 275W.
Da stimmt etwas nicht. Guck mal in meinem Thread (siehe unten). Der ganze 19" Schrank kommt im Idle nicht über 268W.
Teste mal wie Deine CPU eingestellt ist. Ich verwende beim Booten per User Script den Powersave Governor (/etc/rc.d/rc.cpufreq powersave) - sonst keine weiteren Stromsparmechanismen:
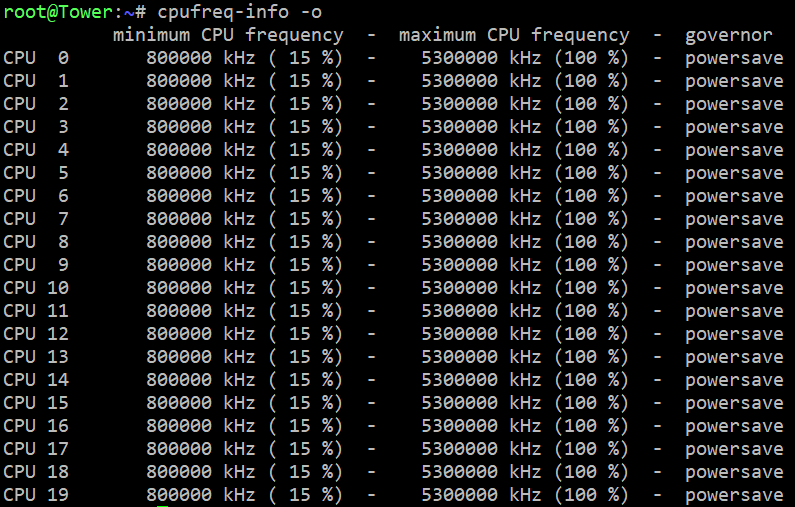

Hier mein Schrank:
Ich halte das in Deinem Fall, zumal bei schlafenden Platten, für viel zu hoch. Wie ist denn die CPU-Auslastung? Ich bin z.B. wieder von SABnzbd zurück zu NZBGet da der Verbrauch durch dieses Python Geraffel bei mir erheblich mehr Saft zog als das hoch optimierte NZBGet.
Das ist der aktuelle Verbrauch des ganzen 19" Schrankes und da läuft aktuell Einiges. Die Spitze ist die Maintenance in der Nacht:
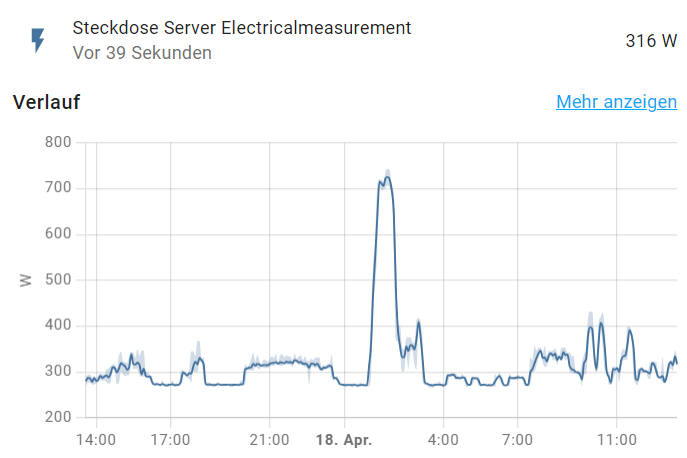
-
11 hours ago, Letztfetz1 said:
Jedoch muss das nicht bei der VM Erstellung, sondern schon im VM Management eingestellt werden. Vielen Dank.
Ich habe den Vermutung, dass hier die zu erstellende(n) vDisks sowie der Ordner für mountable ISOs verwechselt wird. Exakt beschrieben wird das im Hilfesystem zu den VM Einstellungen. Der Pfad mag heute standardmäßig anders lauten - muss also entsprechend angepasst werden. Ich komme aus der Unraid Uralt Zeit und dort gab es das alles noch nicht und ich habe meine eigenen Ordner/Shares verwendet:
Standardmäßig einzustellen in den VM Settings:
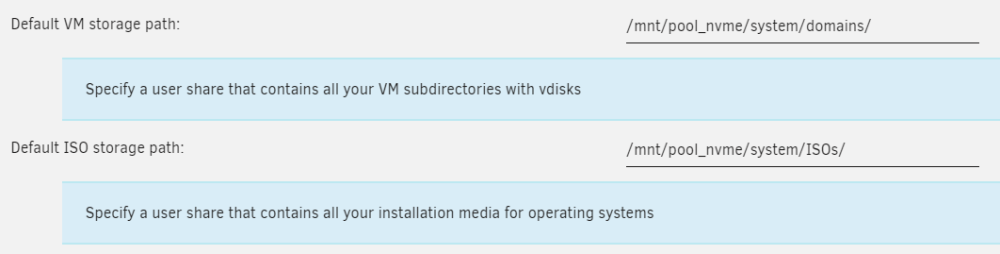
Für jede VM anzupassen:
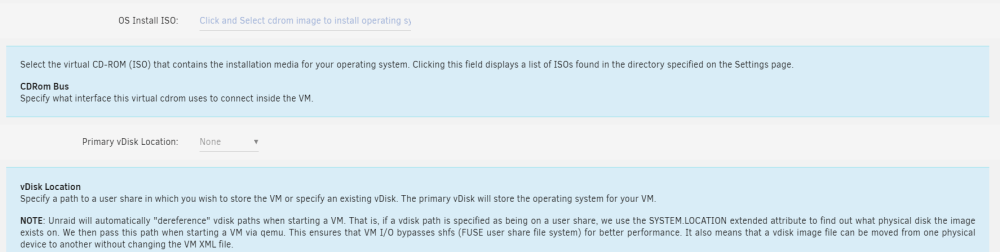
-
5 hours ago, zero_neverload said:
Ok, bei meinem Test bin ich Raid 1 gefahren, wie ich es ja im vorherigen Post bereit geschrieben hatte.
Den Hinweis habe ich jetzt nicht verstanden. Aber egal.
Unraid verwendet ausschließlich Software RAIDs. Die Schreibgeschwindigkeit kann einfach nicht, außer beim Schreiben durch den Linux Block/Buffer Cache im RAM, signifikant schneller sein als die langsamste Platte im RAID1 Verbund. Die Lesegeschwindigkeit kann einfach nicht, außer beim Lesen durch den o.g. Cache, signifikant schneller sein als die schnellste Platte im RAID1 Verbund.
Das mit der "schnellsten" Platte ist kein Vertipper. Die RAID Systeme kennen ja die Drive Characteristics und können die Zugriffe bei RAID1 entsprechend anpassen.
Das "signifikant" habe ich bewusst geschrieben, denn im Real-World Schreiben/Lesen und damit meine ich nicht dd, gibt es noch die Nickeligkeiten mit Metadaten und den eigentlichen Daten (was IMHO u.a. den Spass mit BTRFS versaut). Auch das kann und wird entsprechend auf die Platten im Verbund (nicht RAID 0/1) verteilt. Dadurch ergeben sich Unterschiede.
Aber von 2x oder /2 kann keine Rede sein.
Ich lasse mich aber gerne eines Besseren belehren. So kenne ich das jedenfalls und so habe ich es bisher immer erlebt.
-
Ich habe das Gefühl, dass hier teilweise RAID0 und RAID1 vertauscht werden. Ich empfehle für einen kurzen Überblick über Performance und Ausfallsicherheit die beiden Wikipedia Artikel. Die beschreiben beide Varianten sehr gut - auch den Sonderfall "Verdoppelung der Leseleistung" bei der Verwendung von RAID1 und entsprechenden Controllern:
https://de.wikipedia.org/wiki/RAID#RAID_0:_Striping_–_Beschleunigung_ohne_Redundanz
https://de.wikipedia.org/wiki/RAID#RAID_1:_Mirroring_–_Spiegelung
Und nicht vergessen: Unraid nutzt ausschließlich Software-RAIDs ...
Um auf die Ausgangsfrage zurückzukommen. Die Antwort: Kommt vorrangig auf die Anbindung an ...
-
19 minutes ago, Amane said:
Ist die Ordnerstruktur der beiden Platten nicht gleich?
Das ist halt die Frage. Deshalb lieber mit interaktiver Kontrolle.
-
On 4/13/2024 at 11:49 PM, Amane said:
Na dann zumindest noch ein Befehl der leere Ordner löscht
In seinem konkreten Fall kann er nach Erfolg disk2 komplett löschen. Macht rsync das rekursiv? Hab ich noch nie dafür genutzt. Hätte rm genommen. Und nur der Vollständigkeit halber: Die beiden Optionen empty/delete genau in dieser Reihenfolge ...
Der OP kannte rsync, find, etc nicht sonst hätte er sie verwendet. Also befindet er sich in einer anderen Blase als wir. Der Linux Weg ist "Nimm doch das" ohne weitere Anleitung.
So funktioniert das im Endbenutzer Bereich nicht. Diese holt man in ihrer Blase ab und geht mit ihnen gemeinsam in unsere. So bildet man aus, so lehrt man. Wenn dann das Vertrauen und die Kenntnis weiter gereift ist wird er selbst eigenen Schritte unternehmen.
Das ist seit fast 2 Dutzend Jahren so, dass man Linux Kennern Arroganz vorwirft. Die Diskussionen hierzu sind wirklich uralt. Das wollte ich nie. Ich wollte Wissen transportieren. Leute anleiten, richtig helfen. Nicht zuviel Geschwafel, nur genau dosiert. Dabei startet man mit bekannten, klaren Umgebungen, stellt sie kurz vor und zeigt mit Beispielen dem Endbenutzers wie es gehen könnte. Den Rest muss er trotzdem selbst machen. Und daran reift er.
-
 1
1
-
-
6 minutes ago, Amane said:
Und wieso jetzt nicht einfach ein rsync von platte disk2 nach disk4 oder umgekehrt und dann source löschen ?
Hab ich oben erklärt. Ich will das sehen. Blind auszuführen mache ich nicht, nie. Oft fällt mir dabei etwas auf und ich lösche oder verschiebe noch was.
Ist mein Vorschlag an den OP. Jeder kann machen was ihn glücklich macht. Hatte vor der Rente 42 Jahre in der IT gearbeitet. Ich habe so viele Pferde koxxxn sehen. Dieses kleine bisschen zusätzliche Kontrolle hat mir extrem oft den Hintern gerettet.
Nur meine 0.0 Cent.
-
Nachtrag.
Offensichtlich geht es um die kompletten Platten disk2 und disk4. Zielplatte ist dann natürlich die auf der am meisten drauf ist.
Nehmen wir an disk4 ist voller als disk2. Dann wird disk4 zur Zielplatte. disk2 links, disk4 rechts. Compare. Synchronize. Nur Copy links nach rechts aktivieren. Keine Löschungen, kein Copy nach links.
Danach nochmal vergleichen. Er darf kein Copy nach rechts mehr anbieten.
Wenn Du glücklich bist kannst Du links löschen - nicht formatieren.
Hmm, denk bitte auch mal drüber nach. Hab ich was vergessen?
-
37 minutes ago, yasirrisay said:
wird aber dauern, da ca. 1,5 TB an kleinen Daten nicht doppelt sind und nur ca. 0,3 TB an Daten doppelt.
Wird es immer. Es kommt beim Compare auch nicht auf die Größe der Dateien an sondern deren Anzahl.
37 minutes ago, yasirrisay said:Wenn ich es richtig verstehe, wäre dein Vorschlag, alles inkl. "subdirs" zu synchronisieren und dann die Daten von einer Festplatte zu löschen?
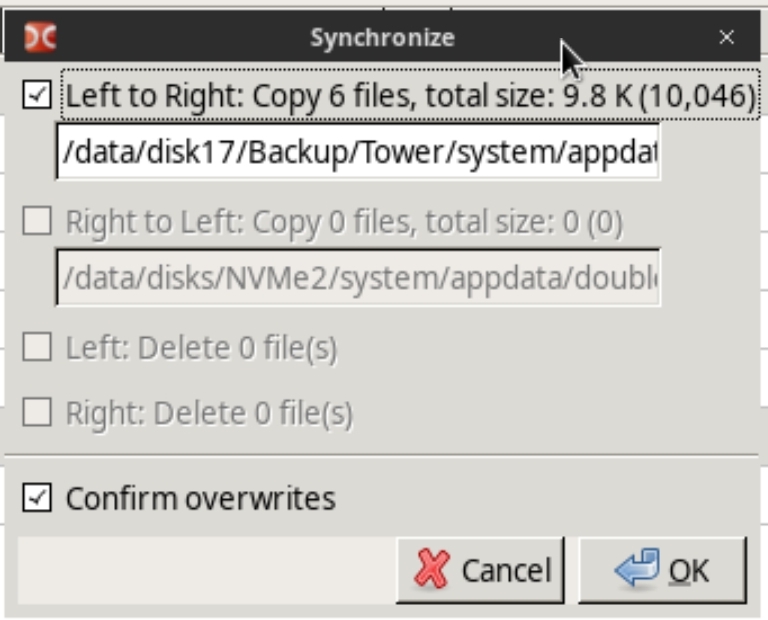
Schalte einfach mal Subdirs für einen Unterordner wie Daten oder Daten/Sortiert an. By content würde ich bis zum tatsächlichen Sync abschalten. Du siehst dann wie viele Dateien wo sind. Dann klickst Du auf Synchronize. Auf dem folgenden Dialog wählst Du die Aktion aus nach links, nach rechts, links löschen. Etc. Einfach mal gucken ohne es zu starten.
Beispiel:
-
4 hours ago, yasirrisay said:
Händisch wäre dies in meinem Fall sehr aufwendig.
Ich werfe ebenfalls ein Werkzeug in den Ring.
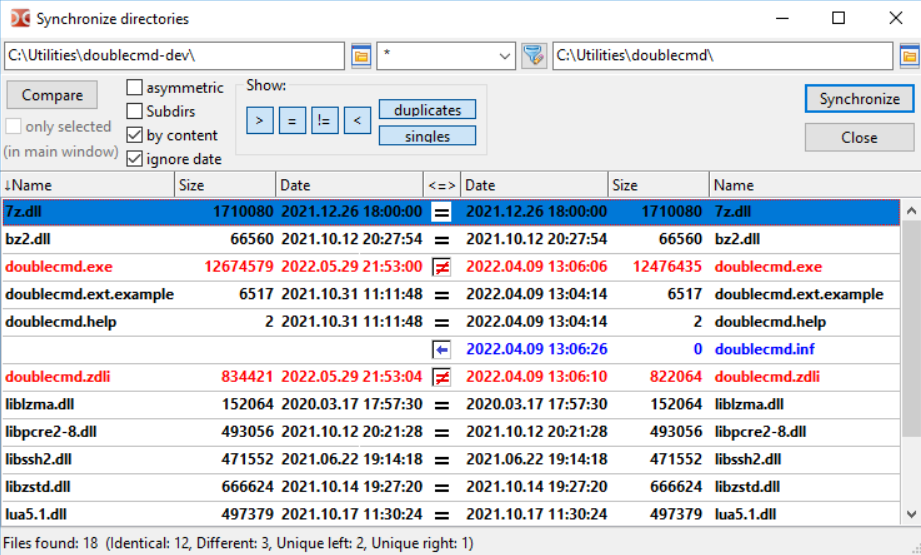
In den Unraid Apps gibt es den "Double Commander" als Docker Container. Das ist ein 1:1 Clone des "Total Commander" - und der ist unfassbar mächtig im Funktionsumfang. Das ist ein Norton 2-Fenster Dateimanager.
1. Dem gibst Du in der Konfiguration einen zusätzlichen r/w Pfad /mnt/ <-> /data/.
2. Stell Dich im linken Fenster auf die Quelle (z.B. /data/disk1/)
3. Stell Dich im rechten Fenster auf das Ziel (z.B. /data/disk2/)
4. Menu Commands, Synchronize Dirs aufrufen
5. Compare starten
--> Nun hast Du li/re die verschiedenen Inhalte.
5. Über Show steuerst Du was Du sehen willst (welche Seite, Duplikate, etc)
Spiel mal ein wenig damit rum ohne direkt das Synchronsieren auszuführen.
Fragen an mich. Ich bin eher der visuelle Mensch bei solchen Aktivitäten. Deshalb nutze ich in solchen Fällen eher solche Werkzeuge als find/rm/mv.

-
Ich arbeite so nicht, aber muss das nicht anders eingerichtet werden:

-
 1
1
-
 1
1
-
-
52 minutes ago, Amane said:
Er meint im Tab CPU Pinning, für die VMs sollten CPU abgetrennt vom restlichen System sein, das hast du?
Du verwendest CPU Pinning in Linux? Guck mal was IBM dazu schreibt. Das ist nur für extrem seltene Situationen empfehlenswert:
QuoteDo not use CPU pinning, because a successful CPU pinning depends on a variety of factors which can change over time:
CPU pinning can lead to the opposite effect of what was desired when the circumstances for which it was designed change. This may occur, for example, when the host reboots, the workload on the host changes, or the virtual servers are modified.
https://www.ibm.com/docs/en/linux-on-systems?topic=management-linux-scheduling
-
1 hour ago, FlorianHE said:
Ja hab ich. aber das sollte doch kein unterschied machen oder ?
Doch. Es gibt kein Werkzeug auf der Welt das den Linux Scheduler besser bedient als Linux selbst. Selbst wenn man es glaubt, man schafft es nicht. Man beginnt also damit, dass man Linux alles überlässt. Das testet man. Wenn man damit nicht zufrieden ist kann man immer noch rumfummeln. Und ja, es gibt Situationen in denen man einem der Komponenten absoluten Vorrang einräumen will, aber das probiert man erst im zweiten Schritt:
1. CPU Isolation komplett aus:

2. CPU Pinning VM komplett an. Das kann man auch in den VM Konfigurationen setzen:
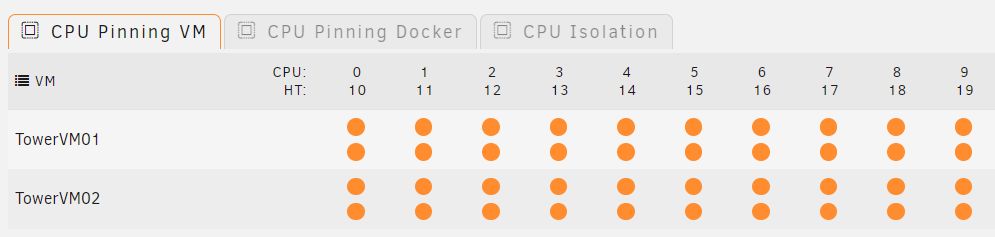
3. Testen.
-
30 minutes ago, FlorianHE said:
Wie bekomme ich das hin das meine VMs im Passthrough modus mit ihrer gewohnten preformance laufen
Du meinst das? Irgendwelche CPU Pinnings für die VM, bzw. CPU Isolation eingerichtet?

-
59 minutes ago, worli said:
Ich wollte nur das Setup von Timmey verstehen, der ja für jede Disk nochmal einen Usershare angelegt hat. Das kam mir unnötig vor.
Ach so. Wird wohl z.B. User-Share "share1" auf "disk1" begrenzt haben und "share2" auf "disk2". Dann kannst Du z.B. mit /mnt/user/share1 ausschließlich mit Disk1 arbeiten. Und umgekehrt mit /mnt/disk1/share1 ausschließlich mit Share1.
Das Problem mit Disk-Share-Only wie bei mir ist, dass Du keine Shares erhälst. Du musst das dann über SMB-Extra lösen. Wahrscheinlich fehlt diese Kenntnis. Ich würde mir wünschen, dass bei "User-Share=no" und "Disk-Share=yes" in Dynamix File Manager einen Knopf neben Root-Ordnern gäbe um dies zu erstellen.

-
1
-
-
1 hour ago, worli said:
Da müsste man jeden User Share auf die entsprechende Disk fixieren und dann für jeden Share das Verzeichnis aus dem Cache und der Disk mappen.
1. Ich arbeite nicht mit dem Cache.
2. Wenn es etwas mehr wird, dann sollte schon ein wenig Ordnung herrschen.
3. Ich arbeite ausschließlich mit Disk-Shares (s.o.). Und nein, da ist nix kompliziert. Dafür gibt es viele, viele Werkzeuge. Plex z.B. muss nur einmal eingerichtet werden.
Und wenn es mal ein Werkzeug nicht geben sollte, dann baue ich es mir halt selbst. 45 Jahre Informatik müssen ja für etwas gut gewesen sein ...
-
16 hours ago, Timmey85 said:
schwört darauf, da hast du es wahrscheinlich auch her
Das kann man so pauschal nicht sagen. Für mein System gibt es halt keine Alternative. Für Andere mit einer Handvoll Platten, entsprechend dimensioniertem RAM sowie wenigen wechselnden Schreib-/Lese-Aktivitäten mag das hingegen kein Problem sein.
Das liegt an der Struktur vom Linux Caching z.B:
https://www.oreilly.com/library/view/understanding-the-linux/0596002130/ch14.html
Und an FUSE z.B:
https://www.kernel.org/doc/html/next/filesystems/fuse.html#what-is-fuse
Stell Dir vor Du hast ein voll ausgebautes 4 HE System mit 24 Platten. Ein User-Share reicht über alle Daten-Platten (22). Und nun verwendest Du diesen User-Share (/mnt/user/<share>) in z.B. Plex. Das läuft so lange gut, bis der Linux Cache im RAM, aus welchen Gründen auch immer, geleert wurde.
Das kann z.B. beim Laden eines Unraid Updates passieren (ja ja, selbst beim Herunterladen eines Unraid Updates läuft ein Sync um den RAM Cache vorsorglich auf die Platten zu schreiben). Das kann aber auch durch heftige Schreiblast passieren.
Sobald dann der RAM Cache den angeforderten Verzeichniseintrag nicht mehr gecacht hat, werden die Platten dieses User-Shares der Reihe nach hochgefahren und das jeweilige Verzeichnis geladen, bis der gesuchte Eintrag gefunden wurde.
Und genau das ist der Knackpunkt - der Reihe nach. Bei mir dauert das Hochfahren einer einzelnen Platte mit Laden des Verzeichnis bis zu 10 Sekunden. Das wären bei 22 Platten ...
Gibst Du Plex aber alle Disk-Shares (1 bis 22) dann entfällt das. Es muss nur exakt die eine Platte geweckt und im "Katastrophenfall" durchsucht werden.
Ich würde mir wünschen, dass in dem o.g. Fall alle Platten auf einmal geweckt würden (wie es aus der GUI heraus geschieht). Dadurch steigt dann aber der Strombedarf, denn es würden dann immer alle 22 Platten geweckt, selbst wenn der gesuchte Eintrag schon auf der ersten Disk liegen würde ...
Wie oben gesagt, es kommt auf den Einzelfall und die Geduld der User an. Meine Eltern würden sofort anrufen wenn es dann 3 Minuten oder so dauern würde: "Kind, das Dings ist kaputt".
-
1
-
-
1 hour ago, Infosucher said:
allerdings geht sowas ja auch per VPN mit Kodi
Nicht ganz. Kodi transcodiert meines Wissens nicht. Nimm einfach mal einen durchschnittlichen 4K Content mit sagen wir 50 Mbit/s Bandbreite. Hast Du einen solchen Upload zu Hause? Ich nicht.
Und trotzdem könnten bei mir mehrere externe Benutzer parallel diesen Stoff gucken. Plex passt die Bandbreite und die Wiedergabe automatisch an die vorhandene Infrastruktur an - das macht der Transcoder:
https://support.plex.tv/articles/200250347-transcoder/
Proof:
root@Tower:~# python3 /mnt/disk1/Projekte/Plex/GetMovieStats.py --height 2160 [...] Movie parts streams video bitrate min (kbit): 10.118 Movie parts streams video bitrate max (kbit): 100.258 Movie parts streams video bitrate avg (kbit): 64.109 [...]
-
1
-
-
6 minutes ago, xST4R said:
kann ich jetzt einfach wenn ich das verzeichniss ändern möchte die docker image editieren und dann einmal neustarten und es wird ein anderer pfad genommen ?
Ja. Das ist das Volume Mapping im Docker System.
https://docs.unraid.net/unraid-os/manual/docker-management/#volume-mappings
-
 1
1
-
-
1 hour ago, xST4R said:
das nas ist ja kein externes "laufwerk" sondern ein internes
Verstehe ich nicht. Wie kann ein NAS (Network Attached Storage) ein internes Laufwerk sein - außer über Unassigned Devices als Remote Share (/mnt/remotes/).
Aber egal. Ich bin raus.
-
12 hours ago, xST4R said:
richte es so ein das die daten auf meinem "nas" gespeichert werden
Kenne das Tool nicht. Von außen betrachtet würde ich das so machen:
1. NAS Speicherort in Unassigned Devices hinterlegen (/mnt/remotes/...)
2. /mnt/remotes/... in dem Feld "Backup Folder" in den Container-Einstellungen hinterlegen (read/write/slave)
3. Nachtrag: Den "Log Folder" würde ich ebenfalls auf das NAS umbiegen.
-
1
-
-
24 minutes ago, JannikGHG said:
Plugins
Versuch es trotzdem mal mit dem Deaktivieren des System Stats Plugins. Das crasht dauernd lt. log. Vielleicht ist es die Kombination aus diesem Plugin mit einem bestimmten Docker Container. Kostet Dich nix wenn Du ohnehin noch auf der Suche bist.
-
36 minutes ago, Infosucher said:
Dann werde ich es wohl so machen.
Und als Plexpass Inhaber nimmst Du das Teil mit in den nächsten Urlaub und hast Zugriff auf Deinen eigenen Stoff an einem Regentag ...

















IPTV über Magenta TV One und Fritzbox auf PLex bzw. generell im Heimnetz
in Deutsch
Posted
Ich nutze seit vielen Jahren die Magenta App auf einem Fire-TV 4K Ultra Stick. Da ich auch Plex auf dem selben Stick nutze ist das eine sehr gute Abdeckung. Ich muss seit damals 5 EUR pro Monat zusätzlich zu meinem DSL Vertrag zahlen.