

hawihoney
-
Posts
3491 -
Joined
-
Last visited
-
Days Won
7
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by hawihoney
-
-
Thanks. I don't use this backup plugin. I do have a self written complex backup environment (three different internal stores, two different external stores, four different timed roles). I would like to use that for automatic Flash backup creation as well.
Is it possible without the plugin - from console - or with a wget/curl call to the Web GUI?
-
I can get diagnostics from console. Is it possible to get a flash backup from console as well? I mean that same archiv I get when I call the flash backup from GUI.
Currently this is a manual act here. I would like to add that to my backup job.
Thanks in advance.
-
Thanks for your answer. Two profiles, one for the router and one for Unraid/Wireguard, is a good idea, really.
-
I'm more than impressed. Never had a VPN tunnel configured that fast and easy with all our devices. Respect.
May I ask two questions:
1.) I'm not quiet sure if I want Unraid/Wireguard vs. our router to be the endpoint in our house. What do you think?
2.) Do you guys use the Wireguard App on your remote devices or do you use the VPN settings in your mobile OS. I ask because 100,000 Downloads for this App are not that many. Is there a reason to avoid the App?
Thanks again for a thrilling addition to Unraid. I'm a customer since ~11 years and never thought that this was a bad decision ...
-
Ah, Thanks. This red error was to much for me
")
-
It was Cache disk missing or Disk missing in red within the cache slot. The array was not started. Had to put the cache Disk back in.
What should've had happened? Should Unraid change that new config itself or do I have to do that?
AFAIK I never removed a Disk (Array, cache) so I'm a little bit nervous.
Any help is highly appreciated.
-
Tried again today. Can't figure out how to seamlessly remove the cache disk I no longer need in a particular server. All steps in the original post verified:
1.) Remove cache disk and reboot --> Error
2.) Keep cache disk in place --> Unraid puts it back into the first Cache slot
Hmm?
-
@je82: It's standard 4U. I'm not good in photography ... The Last picture is one of the two JBODs. The picture before that is the server.
@ghoule: Yes, one VM with one HBA passed through for one attached JBOD. Previously they were three complete Servers. But it was a waste of Material. One Single HBA is more than enough for one JBOD. To be honest, even the HBAs for the JBODs are not necessary. So it's only the drive Limit and the lack of multiple array Pools that drove my decision. The day multiple array Pools are implemented in Unraid I will throw out the two 9300-8e HBAs and use the expander Feature of the backplanes and make that Beast one single shiny Server.
The Main Server does see all individual Disks of the JBODs. I do not give user shares to the server. It's because all disks are spun down usually and spinning up user shares for a single file was a show Stopper. I know about the disk Cache Plugin. But reading 60 disks regulary is no Option for me. So all applications work with individual disks and build their own Pools/shares.
BTW this combination is running without any problems since over a year. It's cool to see three parity Checks Running in parallel on one Server ...
-
Thanks for your answer.
Yes, "Use Cache Disk" was set to "No" under "Global Share Settings".
I did plug the Cache disk back in. So the diagnostics is with cache disk in place. Everything else is like mentioned: Two simple dockers running on array, three special shares (isos, domains, system) with Cache=No, Global Share setting is Cache=No. The only step that's missing is stop array, set cache disk to unavailable, start array. That will lead to the error.
-
On one server I no longer need the cache disk. Unraid always complains about the missing cache after reboot - but it's not in use any longer. What do I need to do?
What I did so far:
* Copied the contents from cache to array (folders: domains, isos, system)
* Edited the user shares of these three folders above to "Use cache: no".
* On Global share settings set Use cache disk to No.
* Deleted contents of cache disk
* Stopped array
* Changed cache disk to unassigned
* Started array
--> Unraid complains
What do I need to do additionally? Do I still need to issue New Config? I though that, when using GUI, the steps above would be enough.
Many thanks in advance.
-
10 hours ago, testdasi said:
You can actually get a pretty decent estimate from the passmark score and the relative complexity difference between 4k vs 1080p and H265 vs H264.
Each 4k H265 stream needs about 7500-8000 passmark => each 1080p H265 stream about 1800-2000 => each 1080p H264 stream about 1000.
Double that values. Here you'll find the official Plex requirements:
https://support.plex.tv/articles/201774043-what-kind-of-cpu-do-i-need-for-my-server/
What you'll find there:
4K HDR (50Mbps, 10-bit HEVC) file: 17000 PassMark score (being transcoded to 10Mbps 1080p)
4K SDR (40Mbps, 8-bit HEVC) file: 12000 PassMark score (being transcoded to 10Mbps 1080p)
1080p (10Mbps, H.264) file: 2000 PassMark score
720p (4Mbps, H.264) file: 1500 PassMark scoreI can confirm these official and higher values. And don't forget - lot's of new 4K material needs more than 50Mbps. I've seen one 4K movie with a peak of 100Mbps - that even maxes out the 100Mbps LAN port of traditional TVs and hardware players. And who the hell thinks that 1080p comes at 10Mbps? My library average for thet resolution is beyond 15Mbps.
My 2x 2860 v2 with a total of ~31,000 maxed out at two parallel 4K transcodes without a dedicated graphics card.
For example, with a dedicated Nvidia 1050ti two 4K transcodes can run on the graphics card. And the CPU cores are free for the rest.
-
10 minutes ago, saarg said:
Sorry, but there's not a single hint regarding my question on that site. Does "containers" refer to the Letsencrypt container and/or the Nextcloud container?
A "default" file does exist in exact the same location in both containers (/config/nginx/site-confs/default).
-
I'm confused if the required Nextcloud changes need to be applied to the Letsencrypt site-confs or Nextcloud site-confs or both.
I do have a default file in the Letsencrypt site-confs folder and a default file in the Nextcloud site-confs folder. Both are completely different. In fact I did recreate the Nextcloud default file. The Nextcloud specific settings are in it's own file located within Letsencrypts site-confs.
There are no warnings on Nextclouds security page and no warnings on the Nextcloud Check-Website.
Any help is highly appreciated.
-
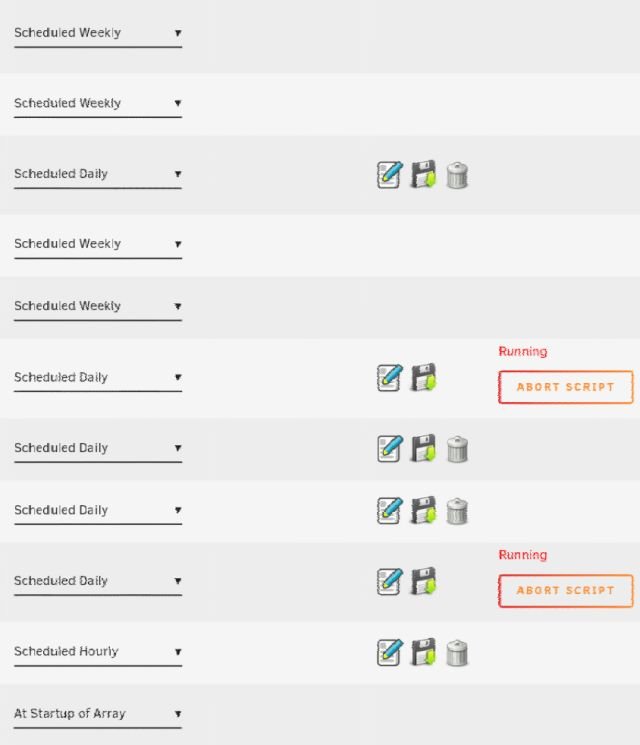
I did use User Scripts because I was under a wrong Impression. I thought if there are catagories (Daily, ...) the Plugin would call all Scripts of the same category in order - one after another and not all at once.
BTW, why would one call a bunch of Daily Scripts at once?
-
So I build my own Daily, Weekly, Hourly scripts?
Ah, I see. Thought User Scripts would work that way. Will do it.
NowI do understand why my M.2 NVMs report high temperatures in the night. No good idea to start approx. six daily scripts at once.
Thanks.
-
After many months of usage, I realized today, that the user scripts seem to run in parallel (see image attached).
As I do have scripts that need to run after each other, how can I force that?
Many thanks in advance.
-
This is the second time I try to compile something on Unraid and I do get this error in Make. What is 'as' (Assembler?) and how can I install that on Unraid?
cc: error trying to exec 'as': execvp: No such file or directoryAny help is highly appreciated.
Thanks.
-
I'm using this XMLRPC-Client to send "Start/Stop downloads" commands from Tautulli to another Unraid docker container:
https://gist.github.com/bjoern-r/c3afda16d45edad5f4a5
The last two lines of this script look like this:
curl -k $verbose --data "@$rpcxml" "$servUrl" 2>/dev/null | xmllint --format - \rm -f $rpcxml
xmllint is not part of Unraid so I removed the pipe:
curl -k $verbose --data "@$rpcxml" "$servUrl" 2>/dev/null \rm -f $rpcxml
I was under the impression, that "\rm $rpcxml" would remove the temporary xml file in $rpcxml. That does not work. Every RPC request leaves the temp file in the directory.
Any help is highly appreciated.
-
OMG, it was that easy.
Had to put "sleep 5s" in script between docker start (mariadb, nextcloud) and before calling mysqldump.
Thank you very much.
-
I do have MariaDB running in a docker container. I would like to take a backup of all databases every night with the help of the user scripts plugin. Whatever I try, it doesn't work.
This is the last iteration of my tests. If I call it from the console it works perfect. Running from user scripts fails:
docker exec mariadb /usr/bin/mysqldump --user=root --password=******** nextcloud > /mnt/user/data/mariadb_backup/nextcloud/dump.sql
Here's the complete MariaDB/Nextcloud backup script with the failing line:
#!/bin/bash #arrayStarted=true #clearLog=true #noParity=true docker stop nextcloud docker stop mariadb rsync -avPX --delete-during /mnt/cache/system/appdata/mariadb/ /mnt/user/data/appdata_backup/mariadb/ rsync -avPX --delete-during /mnt/cache/system/appdata/nextcloud/ /mnt/user/data/appdata_backup/nextcloud/ rsync -avPX --delete-during /mnt/cache/NextCloud/ /mnt/user/data/nextcloud_backup/ rsync -avPX --delete-during /mnt/cache/NextCloud/hawi/files/.Contacts-Backup/ /mnt/user/data/nextcloud/contacts/ docker start mariadb docker start nextcloud # Does not work # docker exec mariadb /usr/bin/mysqldump --user=root --password=******** nextcloud > /mnt/user/data/mariadb_backup/nextcloud/dump.sql
I even tried to but "sudo" in front of it - no joy. I'm out of ideas. Is there really no way to take a backup of a MariaDB database with user scripts?
Many thanks in advance.
-
Is it possible to send commands to Unraid like Start/Stop Parity Check via RPC (e.g. XML-RPC)? If yes, how?
If no, are there other methods to send commands to Unraid?
Many thanks in advance.
-
Thanks.
-
Thanks for your answer.
What puzzles me is that it happened during start of the first parity check (non-correctional). This one was immediately canceled. The then re-started parity check (correctional) does not mention any problems at all.
BTW: It's a LSI 9300-8e HBA connected to a Supermicro BPN-SAS2-846EL1 backplane.
I guess, if the correctional parity check comes to a successful end I simply can ignore these 3x128 errors in the error column?
-
Today I did start a non-correctional parity check on a dual parity array. Within the first 5 GB Unraid did report three disks with read errors (128 each) but did go on with the parity check.
I immediately canceled the non-correctional parity check. After that I did start a correctional parity check. This correctional parity check went thru the first 5 GB without any warnings/errors.
What's the status? The read errors just happened once? Why? The disks in question don't show any SMART problems. Something I need to worry about?
Many thanks in advance.
Diagnostics attached.

Get flash backup from console?
in General Support
Posted
Sorry, don't understand. /boot and what command?
The question was: Can I issue Flash zip creation via Console?