

hawihoney
-
Posts
3497 -
Joined
-
Last visited
-
Days Won
7
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by hawihoney
-
-
16 minutes ago, windowslucker said:
No VMs are involved in this case. Just copying from my PC to a SMB share.
Ok, but qemu-system-86 is the PC System Emulator. It shows that huge CPU load in the screenshot.
QEMU with high CPU load, and with high IO wait values, points directly to data written thru this emulator. QEMU has to emulate virtual disks and it's reads/writes. If there are no VMs envolved, I'm out because I don't understand running QEMU processes without active VMs.
I do see the shfs process as well, but both can escalate each other. High IO-wait because of QEMU emulator with parallel access to SMB can bring a system nearly to halt.
This is my own experience, but if there are no VMs running I can't help you any further because I do not understand it then.
-
Are you copying from a VM to the array or from the array to a VM? Or does a VM write to an passed thru virtual disk?
I ask because I do see high QEMU utilization in your top window.
-
On 4/11/2021 at 7:46 AM, interwebtech said:
So nobody else is seeing this behavior?
On update to 6.9.0 or 6.9.1 (don't know which one) I got warnings/errors for all filled disks. I did close them all.
After that I recognized the wrong temperature limits on my two M.2 disks. I created a bug report because changes on temperature limit did not apply. I was told a workaround and created smart-one.cfg with the entries for these two M.2 disks. This fixed it.
Now on update to 6.9.2 I got warnings/errors for all filled disks again.
For me it's an annoyance, but not worth a new bug report.
Don't know if this matches with your observations.
-
3 hours ago, bonienl said:
In my opinion we are talking here about a feature request and not a bug.
Correct. It's a feature request to fix something that NEEDS to be implemented because the current implementation, at least in one configuration (here: Config types=path), may lead to terrible and confusing results.
Will add a detailed feature request tomorrow morning.
-
57 minutes ago, bonienl said:
The description itself has no influence on the field
But the description content is not labeled "Description". It's called in some cases as another field. And that's terrible.
Please step a little bit back and see the system from the view of a novice. They are used to e.g. Windows. If there's a field you can change, than that field has the same label on many, if not all, windows. Here's "Container path". Both windows have a label "Container path". But on one windows it is an entryfield, and on another window it's a description somebody else entered. In that case it's a must to label that field Description on the Docker Window. Everything else leads to confusion.
-
OMG, I do see it now. It's the description field.
IMHO, this should be changed at least for "Config Type=Path" to reflect the correct labels and values. If I change a field labeled "Container Path" on the edit window, I do expect to read that value on the container page behind the label "Container path" and not the content of the field "description". This will lead to massive misinterpretation.
There are IMHO two possible options:
1.) On Container page write "Description: <value of description field>"
2.) On Container page repeat the correct value and label from the edit wiindow (e.g. "Container path: <value of container path field>" at least for "Config type=Path".
Just my 0.02 USD.
-
The description/label I've given is "Mnt". I did not change that. I'm not talking about that.
I'm talking about "Container Path" and "Host Path". I did change both. The modified "Container Path" is not reflected on the Container page.
Please look again.
-
This is how BTRFS is designed.
That is one of the reasons why I did throw BTRFS out of my systems. Consider a broken disk in a 2-disk RAID. What is needed as the first step? Put stress on the remaining disk (let BTRFS work #1). After that you can replace the failing disk and put stress on the remainig disk again (let BTRFS work #2).
All other RAID systems I know about don't need #1.
-
-
Ah, thanks.
1.) Do I need to uppercase all characters - as in your example?
2.) Are DOS CR/LF allowed?
3.) Do I need to reboot?
-
1 hour ago, S1dney said:
I know haha, but I'm waiting for the upgraded kernel
")
I'm still on the latest build that had the 5+ kernel included.
I did answer to somebody who wants to run NVIDIA drivers on stable Unraid releases only. The latest stable release of Unraid is 6.8.3. So I did point him to the correct way to add current NVIDIA drivers to that release.
-
3 hours ago, S1dney said:
Can't wait for this to reach a stable release.
6.8.3 is a stable release and there's a prebuilt image with NVIDIA 450.66 available. Just copy an handful of files over to the stick and reboot. That's all.
-
14 hours ago, Eviseration said:
So, what are we supposed to do until 6.9 is officially released? It would be nice if I could get my actual "production" cluster to work, and I'm not really a fan of running my one and only Unraid server on beta software (I'm not at the point where I have a play machine yet).
I'm running the prebuild images e.g. NVIDIA for 6.8.3 from here:
-
Hmm, must be something different then. I can see the problems you describe for small folders too.
-
Are you sure that this is related to large folders only?
The whole day I was fighting with a similar effect. All my apps are portable and stored remote. Opening a file e.g. media/executable took minutes.
I deactivated AV Scanner, Windows Search, did Reboot several times. It was poor pain. It was not possible to work. If it's the same tomorrow, I will go back to 6.7.2 AND reinstall my Windows Client.
BTW, in addition Array Performance dropped by ~10% here.
-
Quote
New features, such as multiple pools
Just curious: Multiple cache pools and/or multiple arrays.
-
Ah, thanks. Stumbled over the wording "during boot". Should've been "during login" then?
-
Quote
If you have set a root password for your server, upon boot you'll now see a nice login form.
Does that mean that I need to attach a Monitor to my headless Server just to enter the password of root during Server Boot?
-
'de' VNC keyboard here. Missing backslash is the most annoying thing.
-
Quote
Isn't it better to switch the servers? Copy from the unraid vm to the bare metal one? That way the writing happens on the supported unraid.
Ok, I will do a test and copy a big file from VM to bare metal. But I think that will not show the real problem. Bare metal server has 128 GB RAM. IMHO part of the problem shows up here whenever the size of the copied file exceeds the available RAM of the target machine.
Perhaps copying over SAS cables to SMB mount points is to fast for the target server in a VM. Perhaps something caches to much. In one of my first posts here I did point at SMBD. This process is eating up all available RAM and CPU on the target side. Perhaps that's only happening within a VM. So many questions
")
Will test tomorrow and report back. But I bet this will work.
-
Can't go back to two bare metal servers. Within the last weeks I did rebuild my systems to one bare metal server and several JBOD chassis. Each JBOD chassis is driven by it's own 9300-8e in the bare metal server. All chassis are connect thru SAS cables, not Ethernet.
So please close that thread. My problem is still there, but I can't retest that in an official supported environment.
I decided to swap the contents. Big files on Main Server, small files in VMs on JBODs.
-
Quote
Definitely something else going on. This is not normal behavior.
That's possible, indeed. Would be two different problems showing the same symtoms then. Interesting.
Here are the results - just in case:
I copy with MC from the bare metal server a 52GB file to the VM server. The source is a folder created on an Unassigned Devices RAID1 (BTRFS). The target is a folder in the VM. The disk of that remote folder is mounted on the bare metal server as follows. I use own Mount and Unmount scripts in User Scripts because I need to wait for the start of the VMs before mounting and Unassigned Devices seems to get a race condition when showing 48 SMB mount points on the Main Page:
mkdir -p /mnt/hawi mkdir -p /mnt/hawi/192.168.178.101_disk1 mount -t cifs -o rw,nounix,iocharset=utf8,_netdev,file_mode=0777,dir_mode=0777,vers=3.0,username=hawi,password=******** '//192.168.178.101/disk20' '/mnt/hawi/192.168.178.101_disk20'
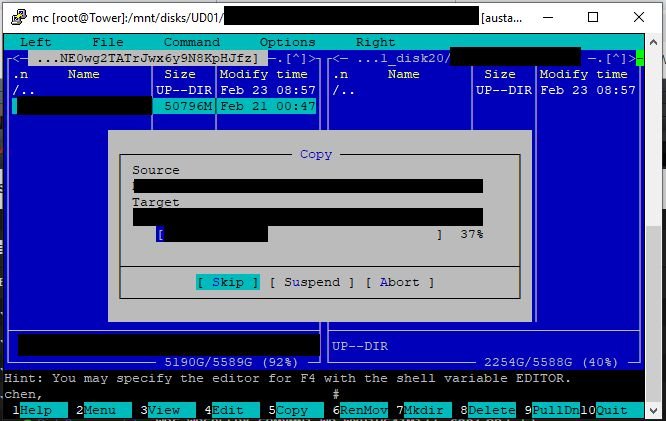
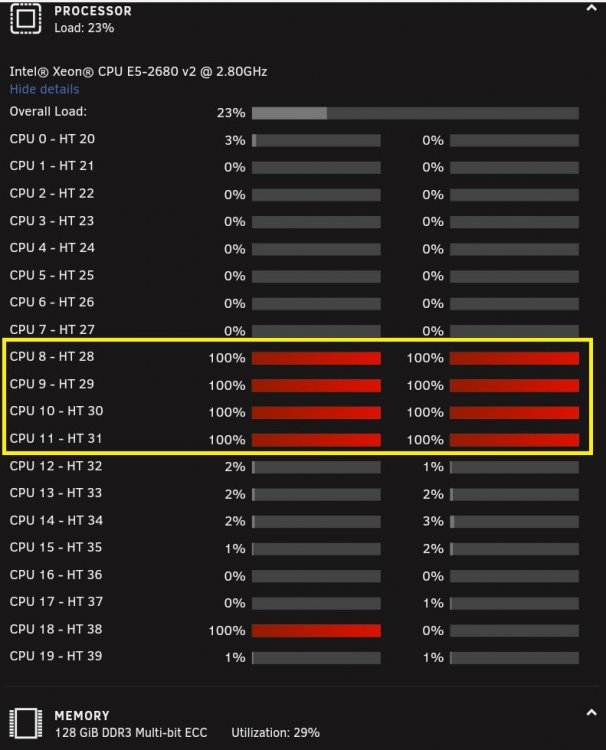
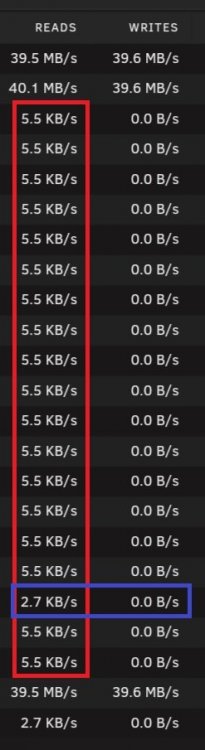
The start looked promising. RAM usage on target did not get beyond 12-13%. CPU was around 30%. At 32% of the copy process (15GB of copy done, RAM total is 16GB) the problem started. MC halted, those 8 threads showed 100% CPU on source server (host of the VM). Dto. on target server. Last I saw was 87% RAM usage on target server. The small read requests on the other disks started. First they came in chunks (disk1-disk5, disk6-disk10, ...). Short time later all disks were reading in small values. On one picture you see red marks and a blue mark. This blue mark shows the disk that is not part of the User Share and shows 50% of the read amount of the other disks.
I know, Unraid in VM is not supported, but I think that shows a problem. My first guess (look two pages before) was SMBD. Because that process is holding that amount of CPU and virtual RAM when the problems are showing up.
tower-diagnostics-20190223-0833.zip
towervm01-diagnostics-20190223-0833.zip


-
I think it's not fixed. Did upgrade everything to 6.7.0-RC5 and did the same copies. It looked different, but in the end the same result happened. Other disks are read with small Intervalls, the system had a hard time. RAM usage beyond 87%, CPU usage nearly 100%.
Took a lot of screenshots and diagnostics. Will post them here in an hour.
This time unRAID sending server is bare metal with 128GB and 40 CPU threads, receiving server unRAID VM with 16GB and 8 CPU threads. If you need two bare metals, other users need to jump in.
-
Thanks for this information. BTW, nice read between Red Hat, Suse, etc developers.






[6.8.3-6.9.2] Huge CPU Load and IO-Wait when copying to Array
in Stable Releases
Posted
Please have a look at the screenshot below. This is my running system with two active VMs. There's a 20 GB copy going on from bare metal from the host to one of the VMs.
Now compare the CPU usage of my system with your screenshot. My VMs are heavily in use and your VMs are not actively used? I guess that the VM's are