

cybrnook
-
Posts
613 -
Joined
-
Days Won
2
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by cybrnook
-
-
Are you pinning dockers or vm's? I think each config/xml file for each VM/docker will contain it's own CPU pinning settings which you may need to remove/adjust manually first.
For example, here is the cpu pinning settings of my docker "HandBrake":
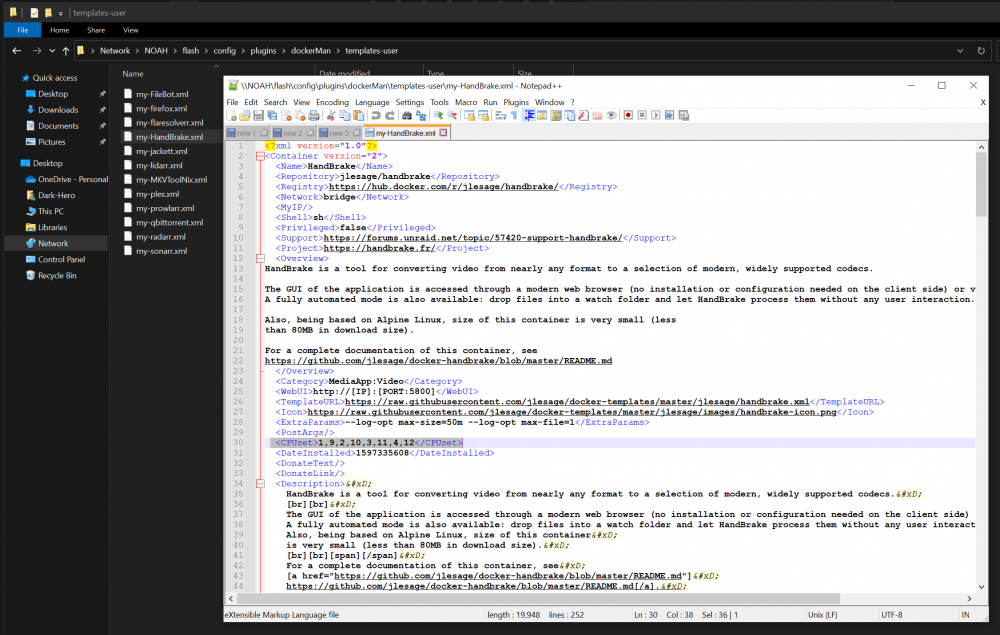
Here are my CPU Cores that coorelate:
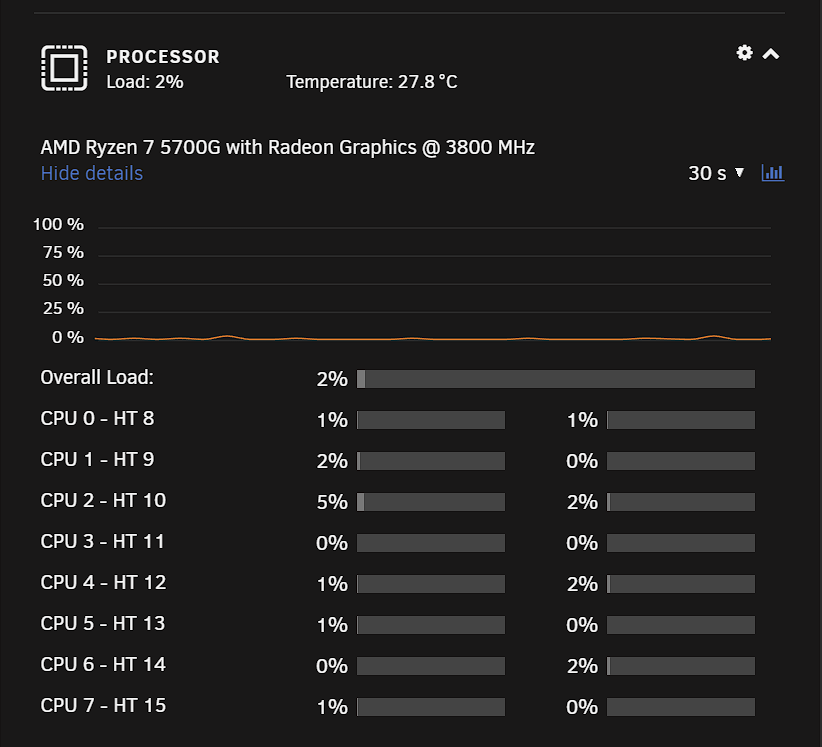
I suspect you've pinned a core number that doesn't exist anymore, and the system is having a hard time interpreting that.
-
Not seeing the same CPU pinning behavior. Did you recently change hardware maybe and perhaps have CPUs pinned that don't exist anymore?
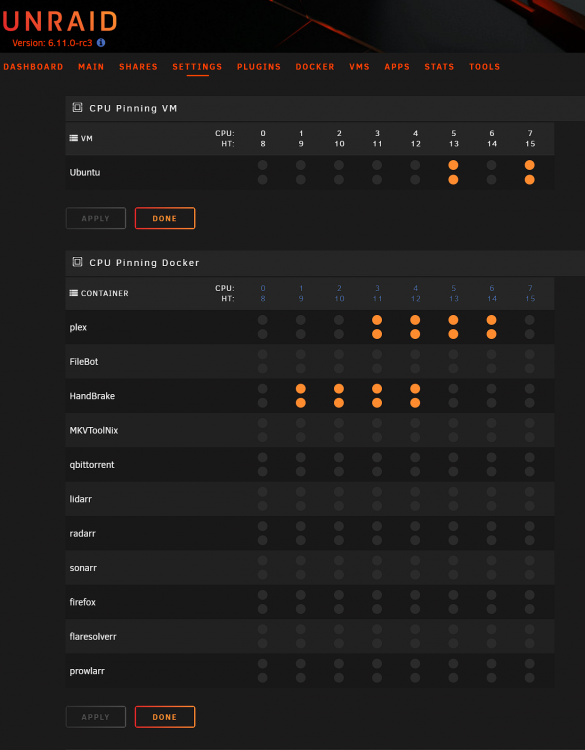
-
26 minutes ago, ljm42 said:
Samba 4.4 is quite old. From the Unraid release notes in the OP:
The above release notes also specify that we are currently using
samba: version 4.15.5Ooof, sorry about that. I was eager to test this as well, since I also use bonding. However, I am reluctant to say I was rushing to get on a work call, so my quick google and copy/paste was off the cuff and out of place.
-
 1
1
-
-
Do we know if 5.11 Kernel is targeted for 6.9 release? Seems to have some perf boosts for AMD users: linux-5-11-is-out-with-amd-and-intel-improvements-and-linus-torvalds-is-happy
-
On 11/20/2020 at 8:11 PM, Squid said:
Issue appears to be that if you have any VM running that used VNC, then starting it would mess up the displays on the dashboard.
Either way, this issue is fixed next rev
Confirmed this is fixed in 6.9.0 RC1
-
 1
1
-
-
-
-
Also seeing this same behavior, VM's section of the Dashboard collapses in on itself when I start a VM (even just 1). When I stop the VM, the section in the dashboard appears again.
No VM's running
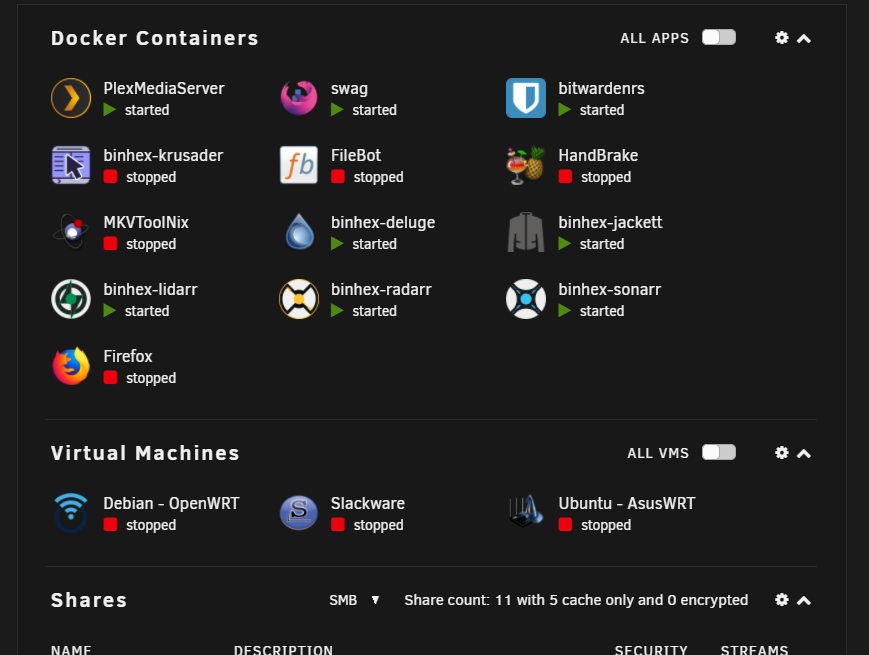
Only Debian VM running (formatting seems to have stacked on itself in the docker section):
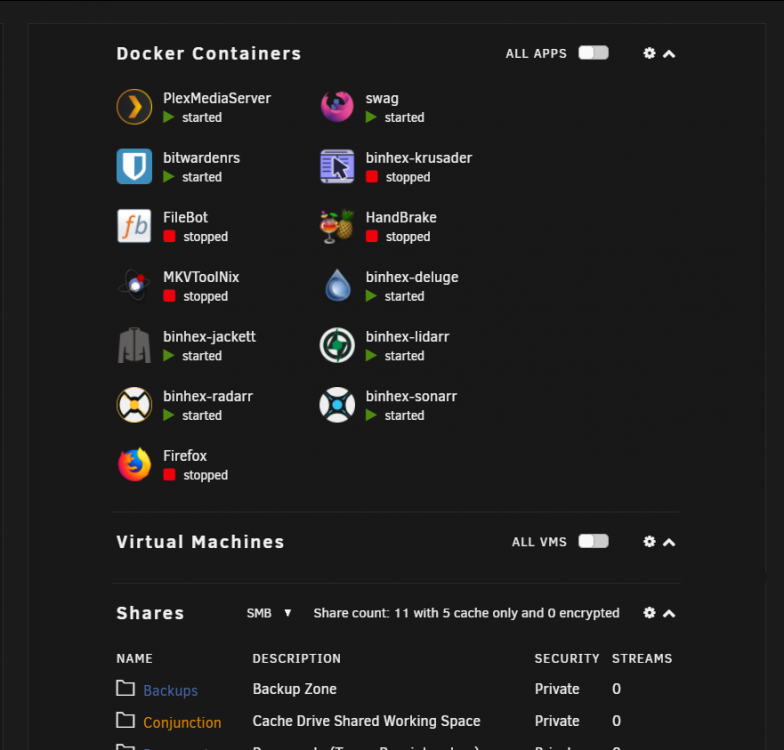
If I collapse the VM section, then the Docker section formatting is again correct:
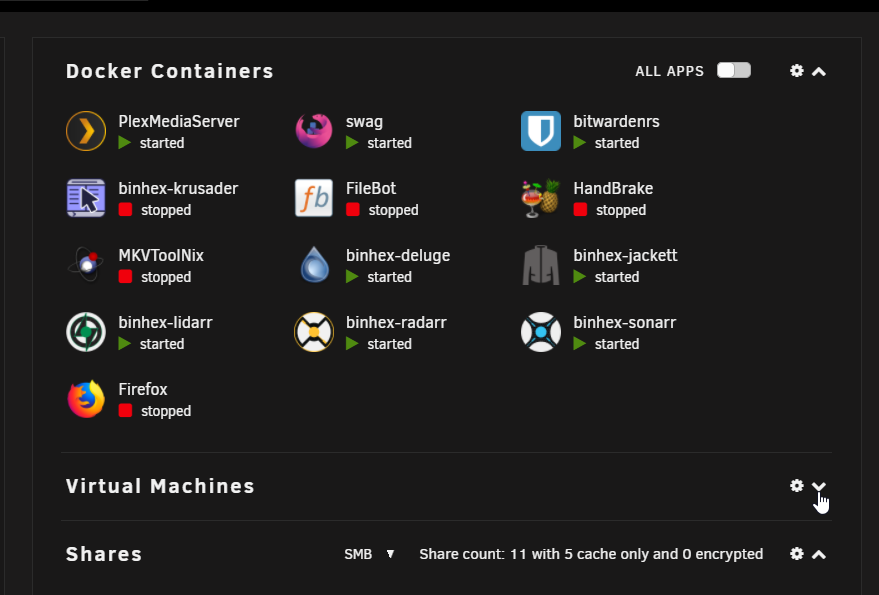
-
Pay no mind to my notifications, it's something custom I do on my own, but was easy to generate notificaitons.
@Squid If I relocate to top right, it works fine (And has that little gap between):
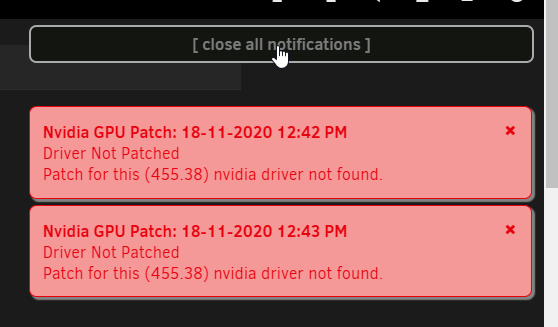
If I put it back to bottom right (where I like it), it doesn't work, which is also the same behavior for bottom left:
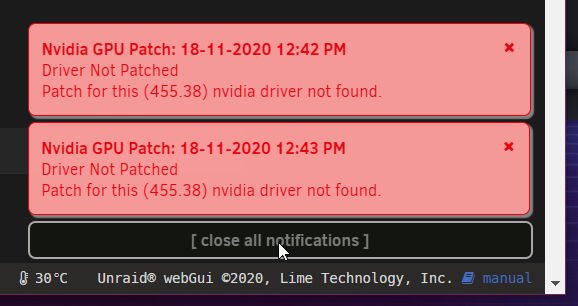
-
2 hours ago, TRaSH said:
So we don't need to use the following anymore for plex ?
NVIDIA_VISIBLE_DEVICES:
NVIDIA_DRIVER_CAPABILITIES:
and only need to keep using: --runtime=nvidiaThose are still needed. (I added some more screenshots above)
-
1
-
-
Just wanted to share a quick success story. Previously (and for the past few releases now) I was using @ich777's Kernel Docker container to compile with latest Nvidia. Excited now to see this be brought in natively, it worked out of the box for me.
I use the regular Plex docker container for HW transcoding (adding --runtime=nvidia in the extra parameters and setting properly the two container variables NVIDIA_VISIBLE_DEVICES and NVIDIA_DRIVER_CAPABILITIES).
To prepare for this upgrade, while still on beta 30:
- disabled docker service
- upgraded to beta 35
- uninstalled Kernel Helper Plugin
- uninstalled Kernel Helper Docker
- rebooted
- Installed Nvidia Drivers from CA
- rebooted
- reenabled docker
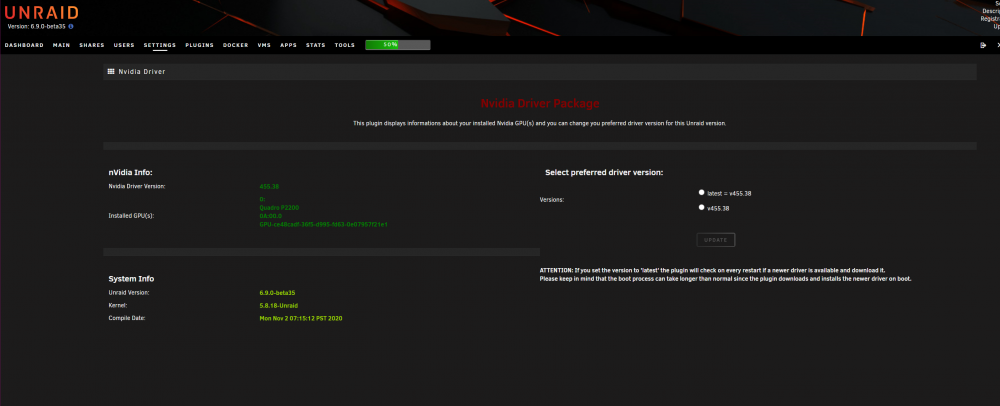
So far all is working fine on my Quadro P2200
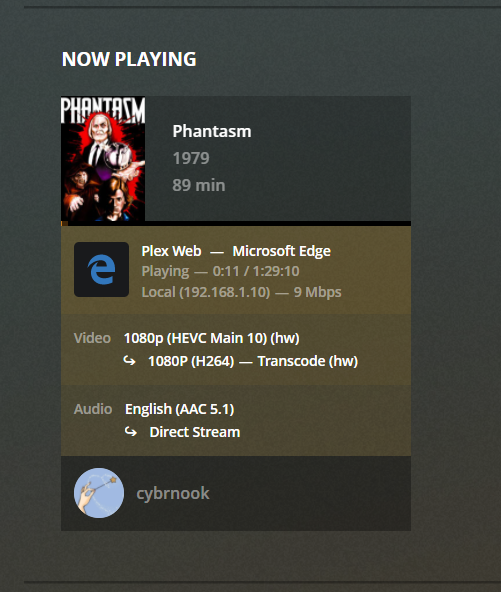
Install Nvidia Drivers
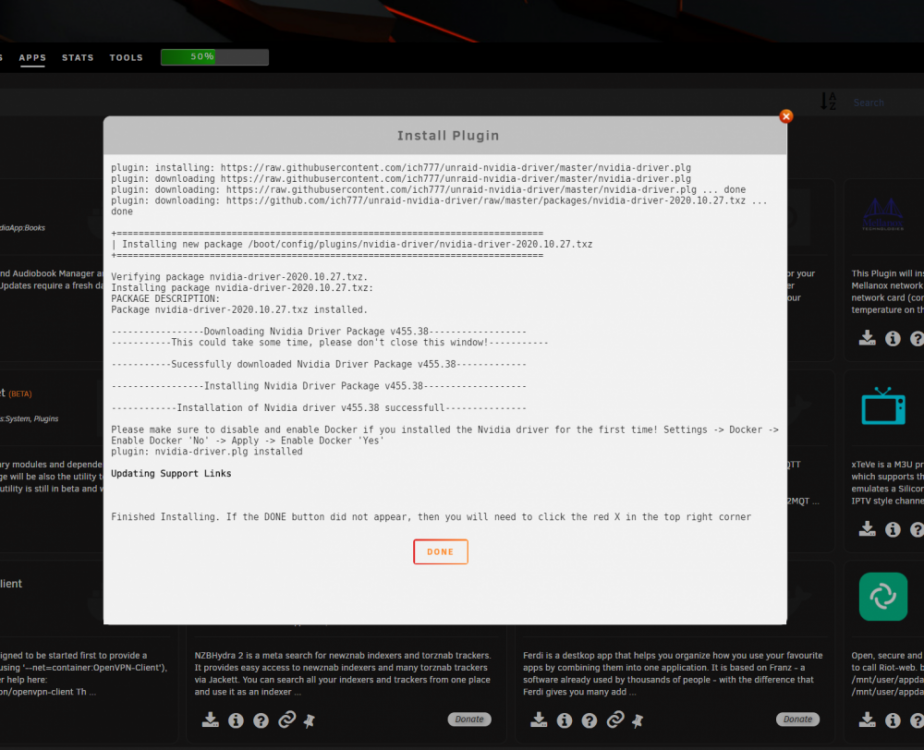
Docker Settings:


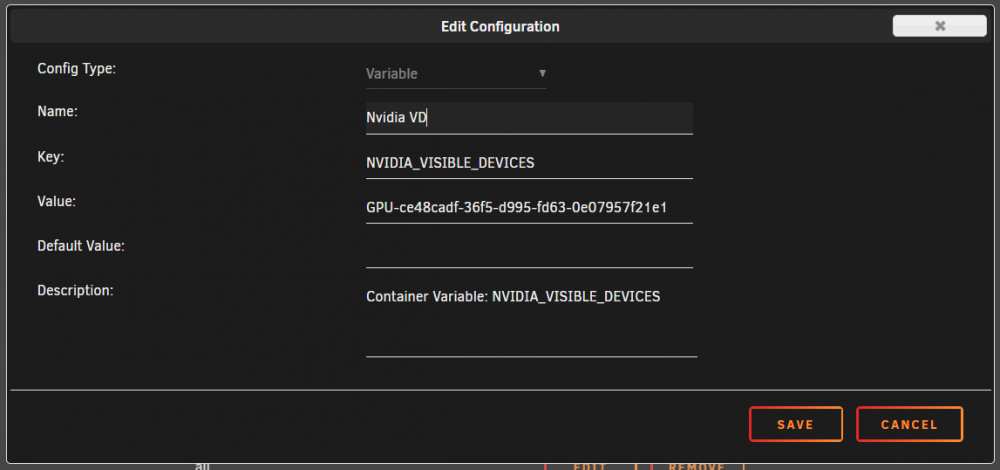
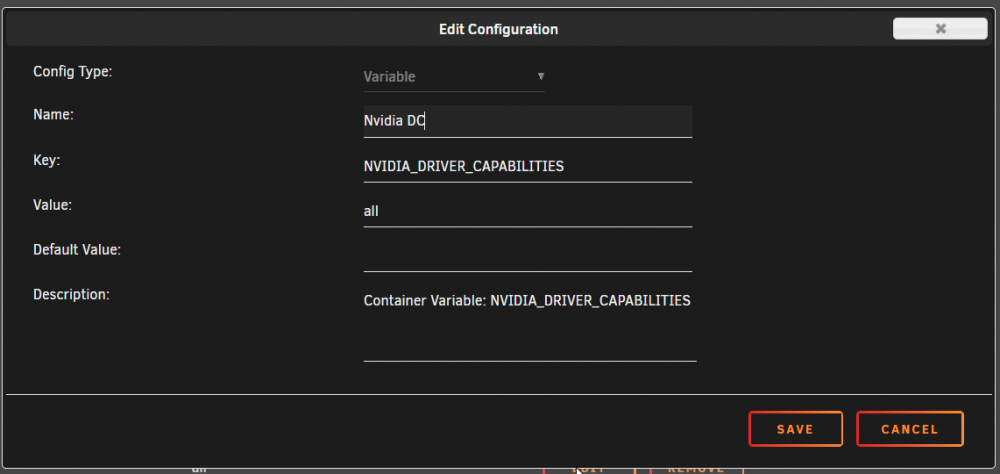
Validate in Settings (P2200 and drivers detected fine)
HW transcoding working fine
-
5
-
4
-
-
Painless update from beta 25
-
1
-
-
I guess I will set this to closed as everything I pointed out so far seems to be either specific to me or expected. Thanks @bonienl for explaining in detail my concerns.
Perhaps it was timing, or something else on my side, but without having Host Access enabled, my custom br0 dockers were not able to talk to one another, at least at the time. Which is what led me down this path anyways.
regardless, so far using a VLAN has removed the call traces I was seeing, and with the rules in the firewall , everyone can talk to everyone, so I guess that's good enough 🙂
-
Changed Status to Closed
-
5 hours ago, bonienl said:
So either your containers are ALL bridge/host network or are ALL custom network.
This may explain it then. Is this a hard requirement that in order to use some docker containers with static IP's, then ALL my docker need to be set to use a static IP? I can't have one using host, a few using bridge, then a handful using custom br0, they would all need to be custom br0?
-
On 8/8/2020 at 3:05 AM, bonienl said:
In worst case when pfsense can not cope with this, you need to disable the host access function, which is rarely needed anyway.
Thanks for the response @bonienl that helps paint of picture of what's going on.
To your line I quoted above. I would say this option is needed for those who want to assign a static IP to your docker containers, but also don't want to have to go through the trouble of setting up a separate VLAN for those docker containers because either it's too hard, or their equipment does not support it.
What I found in the past was that when you assign static IP's to your docker containers, Unraid by default blocks those containers from talking to one another. So if you have a setup like mine (and I assume others run something similar for automation) Sonarr and Radarr need to be able to talk to Jackett, they also need to be able to talk to your torrent client to pass information back and forth. Without this option enabled, this won't work. Or, creating a separate network for these dockers, hence the need for a VLAN.
-
Just to add, I ended up breaking down and building out another VLAN for dockers in the meantime. However, I think this is a bug as the MAC of unraid should not be changing. Way too much of a pain in the butt though, when the check box should have avoided this all together 🙂
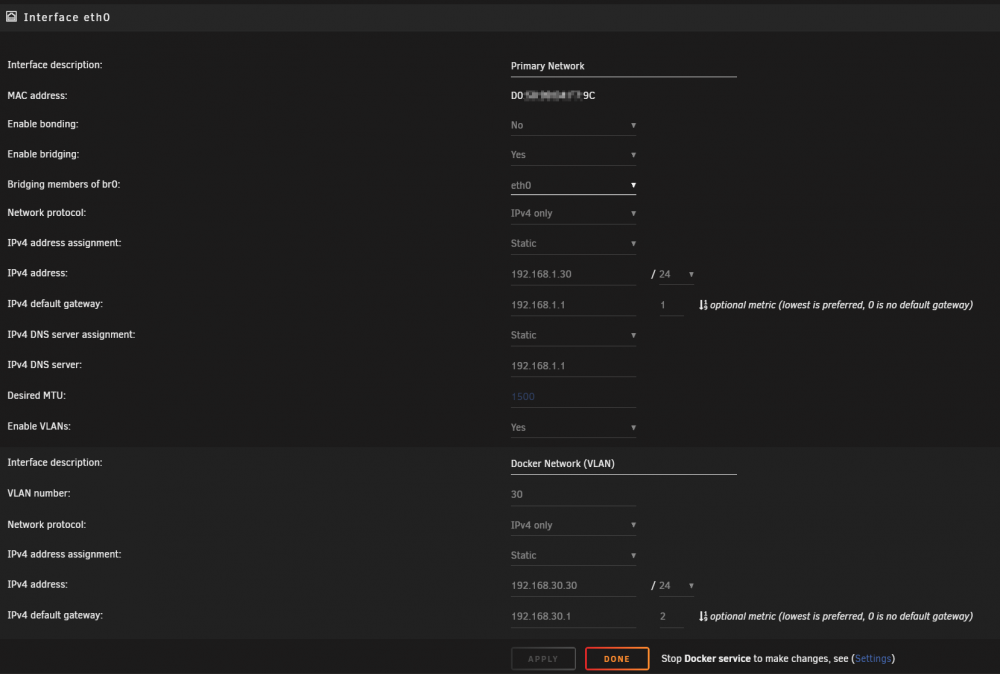

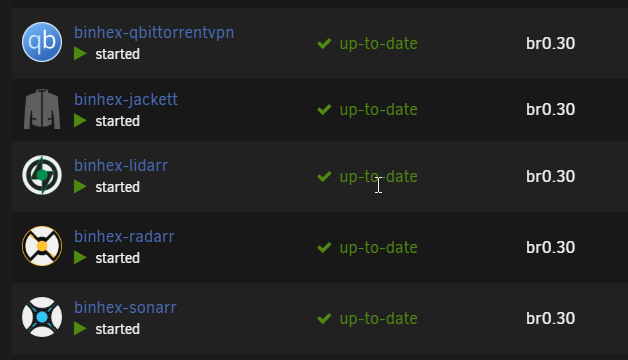

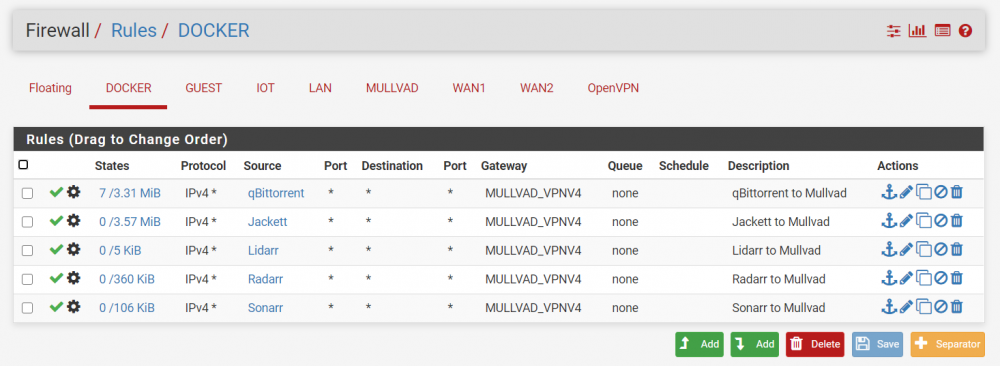

-
2 hours ago, limetech said:
When you get a chance please post the file:
/var/local/emhttp/smart/parity
Ask and you shall receive:
cat /var/local/emhttp/smart/parity smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.7.8-Unraid] (local build) Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000b 100 100 016 Pre-fail Always - 0 2 Throughput_Performance 0x0004 129 129 054 Old_age Offline - 112 3 Spin_Up_Time 0x0007 151 151 024 Pre-fail Always - 440 (Average 431) 4 Start_Stop_Count 0x0012 100 100 000 Old_age Always - 346 5 Reallocated_Sector_Ct 0x0033 100 100 005 Pre-fail Always - 0 7 Seek_Error_Rate 0x000a 100 100 067 Old_age Always - 0 8 Seek_Time_Performance 0x0004 128 128 020 Old_age Offline - 18 9 Power_On_Hours 0x0012 099 099 000 Old_age Always - 9248 10 Spin_Retry_Count 0x0012 100 100 060 Old_age Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 86 22 Helium_Level 0x0023 100 100 025 Pre-fail Always - 100 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 486 193 Load_Cycle_Count 0x0012 100 100 000 Old_age Always - 486 194 Temperature_Celsius 0x0002 240 240 000 Old_age Always - 27 (Min/Max 17/45) 196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0 197 Current_Pending_Sector 0x0022 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0008 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 0 -
Reboot sorted it out, but figure I will leave this here anyways JIC.
-
1
-
-
-
6.8.2 is on an older kernel. We are waiting for the new 5.4+ kernel.
-
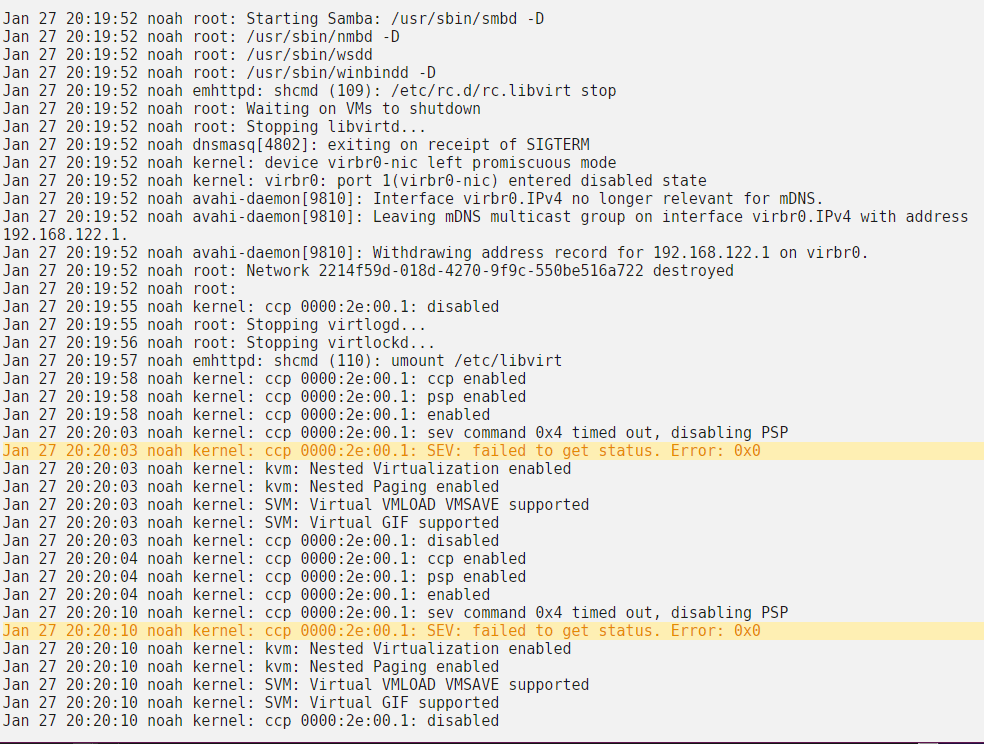
Just noting that attempting to stop VM manager while system is running still causes a large hang/timeout. (Running latest 6.8.2)
-
6 hours ago, bastl said:
Doesn't happened for me on 6.8.0 and started yesterday with the upgrade to 6.8.1. I think we had that issue somewhere in an 6.6 or 6.7 builds. Can't remember if it was a RC or stable, but it got fixed really quick.
Same
-
@limetech did you even sleep last night ? 🤘

























Unraid OS version 6.12.4-rc19 available
-
-
-
-
-
in Prereleases
Posted
You guys are wild 🙂