




SmallwoodDR82
Members
-
Joined
-
Last visited
Everything posted by SmallwoodDR82
-
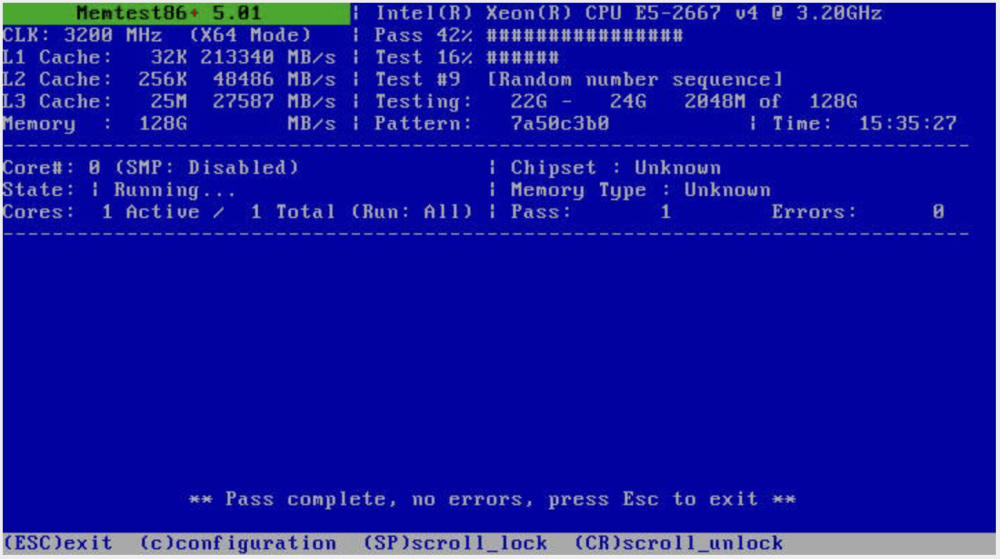
update. Had another crash on Monday. Ran memtest. All Passed. Then I was digging around in forums and came across this post. I moved all my containers to a separate NIC via this Guide and since then, it's been stable. 48 hours so far! Fingers crossed.
-
chasing another crash issue and I'm giving this tutorial a shot. I just have one question. After all these configs are complete, I want all my containers to run the on same IP, different ports obviously. On my first container, it works great. Custom IP taken with eth2 (my dedicated Docker interface) selected. But when I select eth2 and type in the same IP on the second container, I want I get 0.0.0.0 because that IP is in use? How do I get around this? I really don't want a different IP for every container. Just want to use a dedicated NIC for all containers. Thanks in advance!
-
It’s a dual power supply server (Supermicro CSE-836) Updated: I’ve looked in IPMI and the syslog has zero errors logged and while unraid crashes IPMI stays up. It crashed again today and the NVME drives were removed and had VMs off because of that. So it’s not NVME or VM related. I’m currently running a mem test and I’m half way through it with no errors.
-
my fault everyone. I thought it was added to the diags zip. See attached mirrored syslog. I was changing some switches around on Aug 10 so those link down can be ignored. Crash was around Aug 11 23:15 I believe. syslog
-
I had mirror to flash enabled is that different from local syslog server? That mirrored flash should be in the attachment.
-
I have been running this exact USB key on an older Supermicro board for years with zero issues. Very stable. I since moved all drives and key over to a newer system. (I did run the new system on a trial of unRAID for 30 days, which was stable). After moving everything over and adding 2 NVME drives for a VM pool, I'm now having a stability issue. Over the last 3 days I can't get the server to stay up for 24 straight hours. But during that time it's solid and I see no errors in the logs. I might pull the NVMEs out for testing but it's odd, as I see no real errors and the VMs seem to run just fine. When it locks up I lose GUI and VGA. IPMI still works so I know the board isn't "down". I can reset via IPMI and then I'm back up and running for another 24ish hours. Any thoughts? Thank you in advance! smc-unraid-diagnostics-20230811-2355.zip
-
I have attempted to create this and am struggling a bit (tried to "auto" create from the CA. I saw a few years ago someone else requested this as well. Would love it if someone could assist, I'm more than willing to help in anyway I can. https://hub.docker.com/r/keshavdv/unifi-cam-proxy Is what I'm looking for. Thank you so much in advance!
-
Been running resilio sync for years but been using the Limetech template. Been cleaning up my containers and moving any I can to Linuxserver versions as they seem to be updated often and actually managed. Is there a guide anywhere to convert from Limetech's version? I tried to mirror all the settings and map same folders and when I fire up the Linuxserver version it asks me to create a user name and password which tells me it's not seeing the config folder from my Limetech's version. Anyone have some thoughts or experience with this? Thanks, Daniel
-
Hi SmallwoodDR82, What you can try with is to add below line to your go file located in /boot/config/ /etc/rc.d/rc.openvpnclient start //Peter Peter so this works perfect thanks! My final issue is even with the array mounting option set to 'no' and the go file adjustment. If I stop the array to make an unraid change the OpenVPN client stops the VPN connection. Shouldn't it stay connected when array is offline? When I stopped the array, I then have no way to start it again Thanks for the help in advance!
-
@peter fantastic job! I'm running client (2016.12.31a) on unRAID 6.2.4 and everything is working perfectly. My question - I noticed someone asking about auto start on boot instead of with array for the openvpn server. With me running the client is there a way for the openvpn client plugin to start on boot rather than waiting for array? My issue is this unRAID box is not local to me and if I need to stop the array on this box to make an unRAID change I lose connectivity due to vpn closing. I'd like the VPN to be connected basically all the time while the webgui is running. Any thoughts? Maybe a feature request? Thanks for everything and I'm happy to test!
-
Thank you so much for this docker! Works perfectly and import from plexwatch db works as well! Any chance we can add the option in the docker so we can choose dev branch from github for plexpy? Thanks again!
-
Nobody? I can't use virtualbox Sent from my iPhone using Tapatalk hmmm also having same issue.
-
If I'm already using the SF webserver for an actual webserver is there a way for me to run php also?

