
-
Posts
86 -
Joined
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by lostwebb
-
-
6 hours ago, JorgeB said:
Dec 31 17:38:45 Tower kernel: attempt to access beyond end of device Dec 31 17:38:45 Tower kernel: md12: rw=4096, want=7814037064, limit=7814034952 Dec 31 17:38:45 Tower kernel: XFS (md12): last sector read failedThis suggests you used a slightly smaller 4TB disk in this position, maybe this one:
Model Family: Western Digital Red Device Model: WDC WD40EFRX-68WT0N0 Serial Number: WD-WCC4E1826444 User Capacity: 4,000,785,948,160 bytes [4.00 TB]Notice that it's slightly smaller than the other ones:
User Capacity: 4,000,787,030,016 bytes [4.00 TB]Maybe a shucked disk?
Ahh OK yes I just bought it off eBay so its probably shucked. I have a new one coming next week I'll replace it with that.
How can I get the array back up and running in the mean time? Do I need to add the failing disk back just to assign it and then un assign it?
Thanks and happy new year
I did the process with the failed disk and it has come back online fine. I have a new disk coming so I will replace the failed one with that and use the shucked one as a new drive in my backup Unraid.
Thank you so much for the help as usual.
-
4 hours ago, JorgeB said:
There are read errors in multiple disks:
Dec 31 11:41:40 Tower kernel: md: disk1 read error, sector=5860527944 .. Dec 31 11:41:40 Tower kernel: md: disk6 read error, sector=5860527944 .. Dec 31 11:41:40 Tower kernel: md: disk2 read error, sector=3911257848Need to fix that first, looks like a connection/power problem.
Thanks
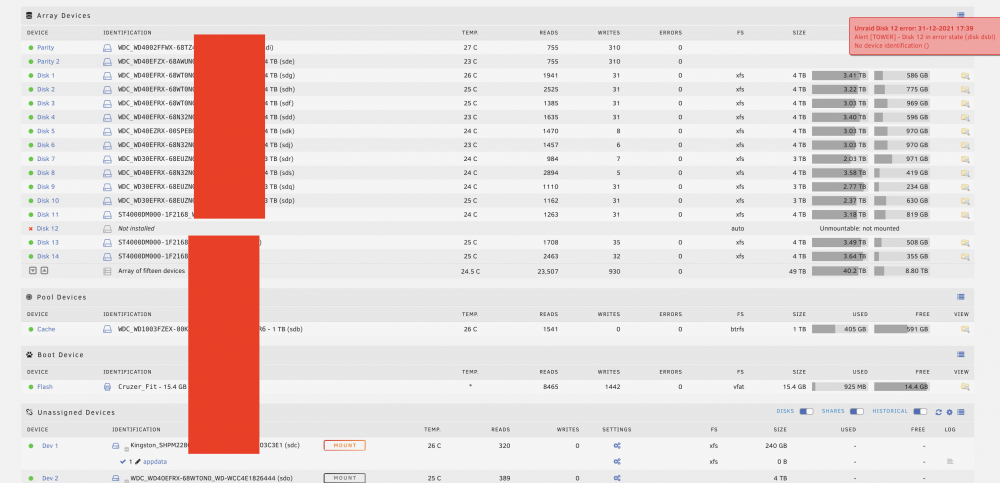
-
3 hours ago, JorgeB said:
Diags after array start in normal mode please.
I triple checked all the assignments are correct.
It's throwing disk errors on 3 disks now too.
thank you
-
On 9/19/2021 at 8:48 AM, JorgeB said:
According to that yes, it was disk12, disk itself looks OK, just a lot of CRC errors which suggest a cable problem, if you didn't write anything to the emulated disk once disk12 got disable you could just re-sync parity (after replacing SATA cables on disk12) but if you want to go back to how it was you can do this:
-Since you've already re-assigned all the disks, so just make sure all assignments are correct.
-IMPORTANT - Check both "parity is already valid" and "maintenance mode" and start the array (note that the GUI will still show that data on parity disk(s) will be overwritten, this is normal as it doesn't account for the checkbox, but it won't be as long as it's checked)
-Stop array
-Unassign disk12
-Start array (in normal mode now), ideally the emulated disk will now mount and contents look correct, if it doesn't you should run a filesystem check on the emulated disk
-If the emulated disk mounts and contents look correct you can then rebuild to a new disk or the old one.
Hi again
I have just had the same happen again, had to wait for a disk to arrive, wrote contents to the emulated disks. Since the original issue I have added a second parity. I rebooted, lost the disk assignments, assigned all disks back, including the new disk to the missing slot, stated in "maintenance mode" with "parity is valid", stopped the array, unassigned the disk and started in normal mode and am getting unmountable error and I am unable to start a disk check in maintenance mode. Does this same fix work with dual parity or is there some other issue?
Thanks again for the help.
-
7 hours ago, JorgeB said:
According to that yes, it was disk12, disk itself looks OK, just a lot of CRC errors which suggest a cable problem, if you didn't write anything to the emulated disk once disk12 got disable you could just re-sync parity (after replacing SATA cables on disk12) but if you want to go back to how it was you can do this:
-Since you've already re-assigned all the disks, so just make sure all assignments are correct.
-IMPORTANT - Check both "parity is already valid" and "maintenance mode" and start the array (note that the GUI will still show that data on parity disk(s) will be overwritten, this is normal as it doesn't account for the checkbox, but it won't be as long as it's checked)
-Stop array
-Unassign disk12
-Start array (in normal mode now), ideally the emulated disk will now mount and contents look correct, if it doesn't you should run a filesystem check on the emulated disk
-If the emulated disk mounts and contents look correct you can then rebuild to a new disk or the old one.
Thank you very much, it has worked perfectly! I did exactly what you said and it came back first time.
Thank you!!!
-
 1
1
-
-
12 hours ago, JorgeB said:
That's pretty important, post current diagnostics, if a disk is clearly failing it should be visible on SMART.
I have just realised it says in the DISK_ASSIGNMENTS.txt that I get User Scripts to create once a week. I believe it was disk 12 that was disabled. Not sure if you can collaborate that with the diags? But I believe it to be accurate as it was a higher number disk I remember being disabled and the user scripts disk list was created 5 days ago.
So it looks like I need to get Unraid to believe that disk 12 is disabled again and emulate its contents from parity. I will buy a replacement disk and a second parity right away to stop this from happening again.
Thank you for your help.
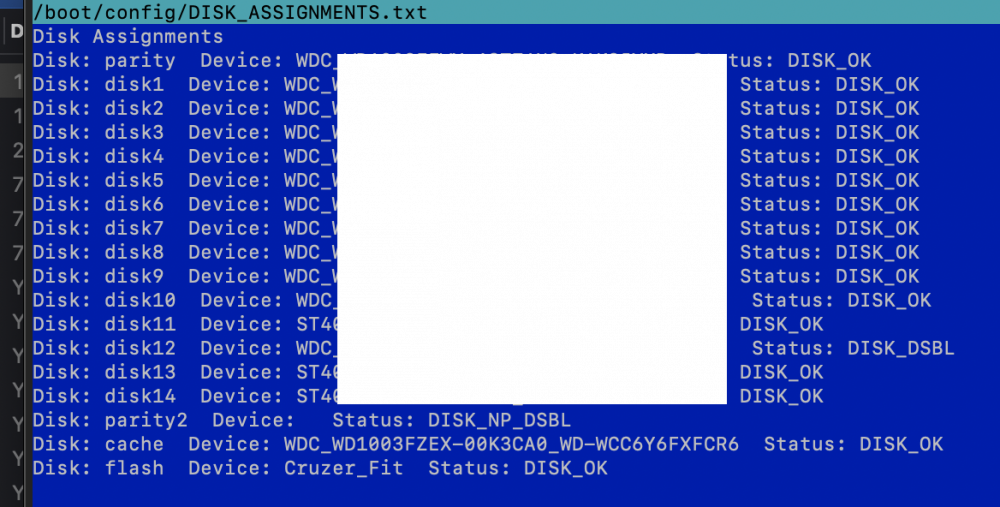
-
14 minutes ago, JorgeB said:
There's a way, do you know all the disk assignments, single or dual parity?
Yes I know the disk assignments, but I don't recall the disk that was disabled. Ive looked through as all the logs I could find and cant find any sign of which one it was. It is single parity.
Thanks Jorge!
-
Hi there, thanks in advance for the help.
I had a disk errored for a few weeks. The contents were emulated and I had been using the array.I had to reboot the server after changing some network settings and when it booted back up it had reset the drive assignments. Now any disk assignments I made show up as a new config and I only have the "parity is valid option". I don't remember which disk was disabled and the logs folder is empty.
Is there anything I can do at this point to get the array back to its contents emulated state?
I know its a bit of a mess but I appreciate the help.
Thank you
")
-
4 hours ago, fryfrog said:
Try the `:latest` tag, I think it should be 3.10.1. I don't see an actual 3.10.1 tag, so I'll push that now-ish too.
I can switch back and forth between 3.10.1 and 3.10.2 just fine, .1 works and .2 doesn't w/ an error about the user table being corrupt.I don't know much about the docker, but i found this information about upgrading and some Mongol changes...scroll down to the update to 3.10.2 instructions. Might not mean anything though.
https://github.com/exsilium/docker-unifi-video
-
On 4/17/2019 at 8:08 PM, IamSpartacus said:
Any plans to update the docker hub dockerfile for 3.10.2 @fryfrog @Pducharme?
On 4/17/2019 at 8:31 PM, fryfrog said:Last I looked, it was withdrawn... is it good now?
Edit: Now I don't see any trace of it having been withdrawn...
I too would be very grateful to see it updated :). Thanks for all the work with the dockers.
-
Hi there.
Thank you fro all the work you put in to the dockers. I don't pretend to know how exactly they work, I am using the Jottacloud docker and all the files from UnRaid are getting uploaded to a folder called "sync" in the synced files main directory. Where it should be just to the root directory.
I believe the issue may be in the following command:
jotta-scanner /sync /Jotta/Sync
From what I understand I THINK the initial "/sync" reference is unneeded and is what is causing everything to upload to the folder called 'sync". Not specifying a directory should just upload it to the root of the Jottacloud folder.
I am not able to test this as I don't know how to.
Really sorry if I'm wrong, thanks for taking the time.
Regards
-
1 hour ago, Cmc0619 said:
Well... That's where the awesome Community Applications shines! You can search for nzbhydra and when it comes back with the results you just click 'Get more results from DockerHub', up towards the top of the screen, and then select the docker from the theotherp and configure it appropriately. That being said, it's more of a manual process and I'm super excited for linuxserver.io to come through for us!
I did that, and it wouldn't work even after manually configuring it. I have installed it from the command line and got it working now
-
-
Thank you very much for this thread, I have bene having problems for ages with disk errors on parity check and rebuild and never knew about this until the "Fix Common Problems" plugin sent me here. I got with of my SAS LAPS and bought two Dell Percs and its perfect, no errors, nothing. Just perfect working server.
Thank you everyone that has put time into researching the cards and posting their experiences.
-
Just wanted to say thank you for this! I used to use this on UnRaid when it was called Mobile PC Monitor but then it stopped working.
Its great to have it working again. Have setup all the port monitors and everything for my setup.
Thanks again

-
Getting this problem too. did you find a fix?
In my case, althub test passes, but every nzb added via api results in the following:
Message Request Failed: Failed to add nzb Ballers.2015.S02E05.720p.HDTV.x264.nzb Exception NzbDrone.Core.Download.Clients.DownloadClientException: Failed to add nzb Ballers.2015.S02E05.720p.HDTV.x264.nzb at NzbDrone.Core.Download.Clients.Nzbget.Nzbget.AddFromNzbFile (NzbDrone.Core.Parser.Model.RemoteEpisode remoteEpisode, System.String filename, System.Byte[] fileContent) <0x41840c60 + 0x0026f> in <filename unknown>:0 at NzbDrone.Core.Download.UsenetClientBase`1[TSettings].Download (NzbDrone.Core.Parser.Model.RemoteEpisode remoteEpisode) <0x417a7300 + 0x00525> in <filename unknown>:0 at NzbDrone.Core.Download.DownloadService.DownloadReport (NzbDrone.Core.Parser.Model.RemoteEpisode remoteEpisode) <0x417a6780 + 0x00561> in <filename unknown>:0 at NzbDrone.Api.Indexers.ReleaseModule.DownloadRelease (NzbDrone.Api.Indexers.ReleaseResource release) <0x417a65c0 + 0x000c1> in <filename unknown>:0 at NzbDrone.Api.Indexers.ReleaseModule.<.ctor>b__7_0 (System.Object x) <0x4179eb30 + 0x0002b> in <filename unknown>:0 at (wrapper dynamic-method) System.Object:CallSite.Target (System.Runtime.CompilerServices.Closure,System.Runtime.CompilerServices.CallSite,System.Func`2<object, object>,object) at Nancy.Routing.Route+<>c__DisplayClass4.<Wrap>b__3 (System.Object parameters, CancellationToken context) <0x416b0310 + 0x0014f> in <filename unknown>:0
from Sonarr, and NZBGet gives me
ERROR Sun Aug 21 2016 10:03:13 Could not add collection Ballers.2015.S02E05.720p.HDTV.x264.nzb to queue ERROR Sun Aug 21 2016 10:03:13 Error parsing nzb-file Ballers.2015.S02E05.720p.HDTV.x264.nzb ERROR Sun Aug 21 2016 10:03:13 Error parsing nzb-file: Premature end of data in tag html line 1 ERROR Sun Aug 21 2016 10:03:13 Error parsing nzb-file: Opening and ending tag mismatch: body line 3 and html ERROR Sun Aug 21 2016 10:03:13 Error parsing nzb-file: Opening and ending tag mismatch: hr line 5 and body
-
You have what looks like two SAS2LP on the two bottom PCIe x16 slots, if that's case these would be my number 1 suspect, disks 3,4 and 8 referenced in this thread are connected to one or the other, there have been reports of similar issues with theses controllers and a small number of users.
If you are not using virtualization disable VT-d in the bios, it may solve the issue.
Ok fantastic thank you. I will try that!
Sent from my iPhone using Tapatalk
-
Anything in the logs that stands out?
Do have older logs, from when the errors occurred, it could be more helpful.
I do not have any older logs Im sorry.
I got everything running again and now another disk has gone and has loads of errors. I have stripped out all the cables and redone them, reseated the cards etc.
Is it possible there is some underlying file system corruption on the disks? I have moved files onto the disk that has now failed, is it possible to move corrupted files and damage a new disk?
I have attached a new set of logs:
Regards
-
Are the problem disks on the same controller card?
Have you tried reseating the controller card in its slot?
Have you check all cable connections, power and SATA at both ends?
Different controller cards.
Have reseated the one card.
Have not checked the PSU end but have the other end.
I'll take everything out and reseat them all and run memtest.
Thank you so much for the help.
Anything in the logs that stands out?
-
Tools - Diagnostics. Post complete zip.
What is the exact model of your power supply?
Have you done a memtest recently?
Did you test (with preclear or otherwise) any of your disks before adding them to your array?
Its a CX750M
Did memtest around 6 months ago when I upgraded the server.
I have precleared most of the disks, some have not. The disks that have been acting up are new and old ones.
-
I have repaired the disks, got everything working then another disk showed as needing to be formatted. I replaced it and did a rebuild and now a different disk has started showing as needing to be formatted. This is now the 4th disk. I'm starting to think there is a bigger problem here somewhere.
Can I post logs or something that might help, if someone could take a look?
thank you all
-
Thank you again.
I did a rebuild of the drives previously and they still said that they were being emulated after the rebuild, anyway, i have done it for a second time and drives are showing as unformatted. I have run xfs_repair and got this one the disks:
Linux 4.4.15-unRAID.
root@tower:~# xfs_repair -v /dev/md4
Phase 1 - find and verify superblock...
bad primary superblock - bad magic number !!!
attempting to find secondary superblock...
<few thousand more dots>
..................................found candidate secondary superblock...
verified secondary superblock...
writing modified primary superblock
- block cache size set to 1470096 entries
sb realtime bitmap inode 18446744073709551615 (NULLFSINO) inconsistent with calculated value 97
resetting superblock realtime bitmap ino pointer to 97
sb realtime summary inode 18446744073709551615 (NULLFSINO) inconsistent with calculated value 98
resetting superblock realtime summary ino pointer to 98
Phase 2 - using internal log
- zero log...
zero_log: head block 3289420 tail block 3289415
ERROR: The filesystem has valuable metadata changes in a log which needs to
be replayed. Mount the filesystem to replay the log, and unmount it before
re-running xfs_repair. If you are unable to mount the filesystem, then use
the -L option to destroy the log and attempt a repair.
Note that destroying the log may cause corruption -- please attempt a mount
of the filesystem before doing this.
SECOND DISK:
Linux 4.4.15-unRAID.
root@tower:~# xfs_repair -v /dev/md8
Phase 1 - find and verify superblock...
bad primary superblock - bad CRC in superblock !!!
attempting to find secondary superblock...
<few thousand more dots>
.................found candidate secondary superblock...
verified secondary superblock...
writing modified primary superblock
- block cache size set to 1470088 entries
Phase 2 - using internal log
- zero log...
zero_log: head block 109735 tail block 109729
ERROR: The filesystem has valuable metadata changes in a log which needs to
be replayed. Mount the filesystem to replay the log, and unmount it before
re-running xfs_repair. If you are unable to mount the filesystem, then use
the -L option to destroy the log and attempt a repair.
Note that destroying the log may cause corruption -- please attempt a mount
of the filesystem before doing this.
I am currently looking on here and google for the correct command to mount the file system, just posting the logs here before I loose them.
-
Thank you for the reply. I ran:
xfs_repair -v /dev/md5
on the disk Sunday evening and ever since then it has been stuck at:
attempting to find secondary superblock.....
With more dots appearing every second for the last 5 days. I canceled it today as there is not even any disk activity anymore.
I am very confused because in maintenance mode it says that the "disk is disabled contents are emulated" so does that mean that xfs_repair is working or not? When I start the server and it mounts the disks it shows them as needing to be formatted and the array size does not take into account the two unformatted disks and the data is missing. So why does unraid say the contents are emulated if they clearly aren't?
Where did the contents actually go? This all came about from doing a 2 disk parity rebuild. As parity was valid before the rebuild?
I really dont understand whats going on with it, doesn't seem to add up?
The worst part is that due to split level I could have lost loads of picture, videos etc for projects I have not started yet that I naively thought were protected. All my old stuff is on Dropbox but more recent stuff I dumped on UnRaid waiting to be sorted.
I would really be so grateful to anybody that could help!
 :-*
:-* -
I think I got mine used off eBay. But it still wasn't cheap then.
It's in the PMS server settings under library I think. There are a few settings they have recently added regarding thumbnails. Change it to advanced view and check it out!
Sent from my iPhone using Tapatalk



 :-*
:-*
Docker Template Request With Bounty
in Lounge
Posted
Hey all
I was wondering if anyone would turn this into an Unraid docker:
https://github.com/Prem-ium/BingRewards
I have tried myself several times and can't get it to work. It creates and runs, but I believe it's not reading the config file.
I'm confident it's just me not configuring the docker correctly, as there is official docker support for the project.
You could test the docker with a free Microsoft account that has signed up for the free Bing rewards program.
$25 PayPal bounty to whoever gets it working and submits it to Community Apps. Is that worthwhile for someone?
Thanks")