

ds679
-
Posts
49 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by ds679
-
-
welp....I figured that 'time would tell' if those changes were successful.....the answer is no.
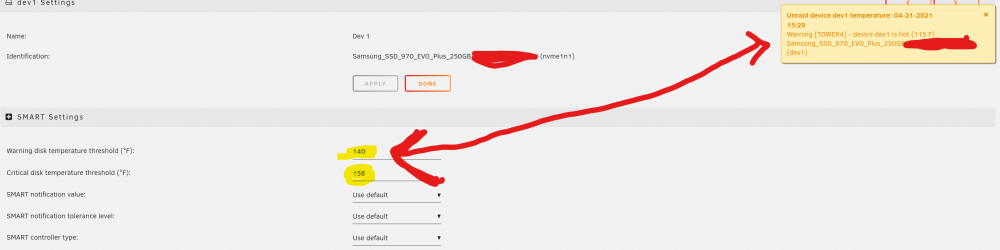
Just received the 'Yellow Warning' with the 115F temp (whereas the actual file shows correct/higher temp) and it is ignoring it.
Is it an 'Unassigned Devices' issue? (UPDATE: Nope....as it just happened to my other NVMe drive - yellow warning @ 115 and not the set temp)
-dave
-
And just another follow-up.....after rebooting the GUI page for each drive shows non-corrected values (still the default ones) for all of my NVMe drives....BUT the CLI reading of the files shows the accurate/corrected values.
Something seems really broken?
-
Just now, ds679 said:
And such a weird thing....my 'Cache' drives are showing the temps in 'F' (which is what my system default is) but the 'Dev 1' drive (which is part of 'Unassigned Drives') is showing its information in Celsius? (the correct information with my updated temps - but still different format)....I'm thinking that might be the issue?
OH....and another weird issue.....my Cache drive entries include their names....while the assigned drive entry does not? Here is my new file:
root@Tower4:/boot/config# cat smart-one.cfg
[GIGABYTE_GP-ASM2NE6100TTTD_SN202808919XXX]
GIGABYTE_GP-ASM2NE6100TTTD_SN202808919XXX_hotTemp="140"
GIGABYTE_GP-ASM2NE6100TTTD_SN202808919XXX_maxTemp="158"
at0="5"
at1="187"
at3="197"
at4="198"
at5="199"
[GIGABYTE_GP-ASM2NE6100TTTD_SN202808919XXX]
GIGABYTE_GP-ASM2NE6100TTTD_SN202808919XXX_hotTemp="140"
GIGABYTE_GP-ASM2NE6100TTTD_SN202808919XXX_maxTemp="158"
at0="5"
at1="187"
at3="197"
at4="198"
at5="199"
[Samsung_SSD_970_EVO_Plus_250GB_S4P3NG0M1159XXX]
hotTemp="60"
maxTemp="70" -
3 hours ago, Squid said:
First, you should update to 6.9.2
would love to...but when I did - drive spin down after timeout stopped happening...bug report submitted.
3 hours ago, Squid said:If it still happens, then delete smart-one.cfg from /config on the flash drive, reboot and set things back up if necessary
the original smart-one.cfg seemed to have the correct information (and I have rebooted multiple times since originally changing/correcting the numbers). Will try again - super appreciate the follow-up & response!
Ok...when I went back to update/change the numbers (changing them on the line and clicking 'Apply') - it doesn't seem to 'take' - they revert back to the original numbers after the 'Apply' is pressed and screen refreshes! BUT looking at the file from the CLI shows the correct info in the file. I guess it is just waiting for a reboot to show on the screen?And such a weird thing....my 'Cache' drives are showing the temps in 'F' (which is what my system default is) but the 'Dev 1' drive (which is part of 'Unassigned Drives') is showing its information in Celsius? (the correct information with my updated temps - but still different format)....I'm thinking that might be the issue?
Thanks again - dave
-
I have a NVMe that I've set to warn at 140F but continue to get the 'Yellow Warning' that drive is hot (115F). How can I get this warning to respect drive settings? Is this a bug in 6.9.1?
-
9 hours ago, SimonF said:
Hi Dave, Can you add your issue to the bug thread. Thanks Simon.
Please mention models of disks etc.
Howdy SimonF.....anything to help out the team!
-
 1
1
-
-
1 hour ago, ds679 said:
Yes...running latest/greatest.....sounds like I'm going to go back to 6.9.1 and test (guess things happened at the same time so I thought it was new hardware)
Ding...ding...winner-winner, chicken dinner
back to 6.9.1 and it works.......thanks again
-
 1
1
-
-
5 minutes ago, doron said:
Hang on. I may be missing something. Do you have SAS hard drives in your system?
(or have you connected your SATA drives to the new LSI HBA - in which case, the plugin is not really applicable, although it has been known to help in some corner cases.)
On a related note - which Unraid version are you running? If it's 6.9.2 (latest when writing this), there's an open issue on SATA drives not spinning down (or, actually, spinning back up immediately) in this particular version. Not applicable to any other version.
The fact that you're not seeing anything in the log is peculiar - at the very least you should have seen "spinning down /dev/sdX" type messages.
Sorry...maybe I misunderstood (I'm still trying to learn even though have been using UnRaid forever.....I have all my SATA drives connected to the LSI HBA....so, I'm guessing this plugin is not the right one. Thanks for letting me know!
Yes...running latest/greatest.....sounds like I'm going to go back to 6.9.1 and test (guess things happened at the same time so I thought it was new hardware)
Agreed on the weirdness in logs!
Thanks again - dave
-
1 hour ago, doron said:
Definitely not the intended behavior... "Should" work with the Spindown timers.
Can you elaborate on what you're seeing?
- which SAS drives do you have?
- what have you configured as Spindown times?
- what do you see on syslog when the timer expires?
(I presume you aren't seeing the green ball turning grey when the timer expires.)- have the 4-to-1 SATA to SAS cables (I guess technically that whole thing should be reversed)
- 15 minutes (in Settings --> Disk Settings --> Default spin down delay
- as an addendum to above.....Enable Spinup Groups is set to 'No'
- In system logs (from GUI) -- nothing
- dmesg - nothing of value to drives
and....right, no gray ball...just constant green (with drive temp visible).....is it just tricking me?
I think it is a bit disturbing to not see anything in the logs (which is where it checks to issue the spindown....hmm). This used to work on the same system with it was direct to the SATA drives?
Thanks again -dave
P.S. from other posts (and I'm not sure if it is relevant) but I don't have any SATA drives connected to the on-motherboard SATA ports....only other drives are NVMe on motherboardP.S.S after doing the manual shutdown (by clicking on the green ball) - logs show:
Apr 11 19:20:34 Tower4 emhttpd: shcmd (144): /usr/local/sbin/set_ncq sdd 1
Apr 11 19:20:34 Tower4 emhttpd: shcmd (145): echo 128 > /sys/block/sdd/queue/nr_requests
Apr 11 19:20:34 Tower4 emhttpd: shcmd (146): /usr/local/sbin/set_ncq sdc 1
Apr 11 19:20:34 Tower4 emhttpd: shcmd (147): echo 128 > /sys/block/sdc/queue/nr_requests
Apr 11 19:20:34 Tower4 emhttpd: shcmd (148): /usr/local/sbin/set_ncq sde 1
Apr 11 19:20:34 Tower4 emhttpd: shcmd (149): echo 128 > /sys/block/sde/queue/nr_requests
Apr 11 19:20:34 Tower4 emhttpd: shcmd (150): /usr/local/sbin/set_ncq sdf 1
Apr 11 19:20:34 Tower4 emhttpd: shcmd (151): echo 128 > /sys/block/sdf/queue/nr_requests
Apr 11 19:20:34 Tower4 emhttpd: shcmd (152): /usr/local/sbin/set_ncq sdg 1
Apr 11 19:20:34 Tower4 emhttpd: shcmd (153): echo 128 > /sys/block/sdg/queue/nr_requests
Apr 11 19:20:34 Tower4 emhttpd: shcmd (154): /usr/local/sbin/set_ncq sdb 1
Apr 11 19:20:34 Tower4 emhttpd: shcmd (155): echo 128 > /sys/block/sdb/queue/nr_requests
Apr 11 19:20:34 Tower4 kernel: mdcmd (37): set md_num_stripes 2048
Apr 11 19:20:34 Tower4 kernel: mdcmd (38): set md_queue_limit 80
Apr 11 19:20:34 Tower4 kernel: mdcmd (39): set md_sync_limit 5
Apr 11 19:20:34 Tower4 kernel: mdcmd (40): set md_write_method
Apr 11 19:20:38 Tower4 emhttpd: shcmd (156): /usr/local/sbin/set_ncq sdd 1
Apr 11 19:20:38 Tower4 emhttpd: shcmd (157): echo 128 > /sys/block/sdd/queue/nr_requests
Apr 11 19:20:38 Tower4 emhttpd: shcmd (158): /usr/local/sbin/set_ncq sdc 1
Apr 11 19:20:38 Tower4 emhttpd: shcmd (159): echo 128 > /sys/block/sdc/queue/nr_requests
Apr 11 19:20:38 Tower4 emhttpd: shcmd (160): /usr/local/sbin/set_ncq sde 1
Apr 11 19:20:38 Tower4 emhttpd: shcmd (161): echo 128 > /sys/block/sde/queue/nr_requests
Apr 11 19:20:38 Tower4 emhttpd: shcmd (162): /usr/local/sbin/set_ncq sdf 1
Apr 11 19:20:38 Tower4 emhttpd: shcmd (163): echo 128 > /sys/block/sdf/queue/nr_requests
Apr 11 19:20:38 Tower4 emhttpd: shcmd (164): /usr/local/sbin/set_ncq sdg 1
Apr 11 19:20:38 Tower4 emhttpd: shcmd (165): echo 128 > /sys/block/sdg/queue/nr_requests
Apr 11 19:20:38 Tower4 emhttpd: shcmd (166): /usr/local/sbin/set_ncq sdb 1
Apr 11 19:20:38 Tower4 emhttpd: shcmd (167): echo 128 > /sys/block/sdb/queue/nr_requests
Apr 11 19:20:38 Tower4 kernel: mdcmd (41): set md_num_stripes 2048
Apr 11 19:20:38 Tower4 kernel: mdcmd (42): set md_queue_limit 80
Apr 11 19:20:38 Tower4 kernel: mdcmd (43): set md_sync_limit 5
Apr 11 19:20:38 Tower4 kernel: mdcmd (44): set md_write_method
Apr 11 19:20:57 Tower4 emhttpd: spinning down /dev/sdc
Apr 11 19:20:58 Tower4 emhttpd: spinning down /dev/sdf
Apr 11 19:20:59 Tower4 emhttpd: spinning down /dev/sdg
Apr 11 19:21:01 Tower4 emhttpd: spinning down /dev/sdb
Apr 11 19:21:03 Tower4 kernel: mdcmd (45): set md_write_method 0 -
Am the proud new owner of a LSI 9305-16i (my first adventure into HBAs) - I'm super grateful for your plugin but wanted to know if this is common:
- works great if I manually spin-down the whole array or individual drives
- does not work when drives 'time out' and should spin down
Is this a config error on my part? Not included with normal functionality?
Thanks in advance for any help - dave
-
45 minutes ago, John_M said:
You could make use of the "wasted" space by adding more devices to make it a 3- or 4-device pool. Take a look at the btrfs calculator at https://carfax.org.uk/btrfs-usage/
Hmmm....ok....so you've got me thinking. I believe that you're saying is to do this:
- Current Setup: Single M.2 256Gb drive setup as Cache (formatted BTRFS)
- Future Setup: THREE M.2 drives - existing 256Gb & 1TB & 750GB
In that way I could combine the three to make a single 1TB cache?
-
6 minutes ago, John_M said:
Unraid doesn't support more than one partition per disk. The only way to access multiple partitions is via the Unassigned Devices plugin, in which case the whole of the device would have to remain outside the array and cache pool.
ahhh....the best laid plans....thanks for the clarification.
I guess it would help to add a note to the Wiki/UnRaid docs that while BTRFS doesn't require matched sizes - that the remainder would be wasted in this situation? -
Hi Jonathan,
That's why I thought using CLI and pre-partitioning might do the trick? Then I specify the individual partition to join the BTRFS?
-
Can someone help me understand if/how this can happen
Here's what I got:- Current Setup: Single M.2 256Gb drive setup as Cache (formatted BTRFS)
- Future Setup: Two M.2 drives - existing 256Gb & 1TB
My thoughts/questions:
- Do I need (or should I) format/partition the new 1TB drive into 250 & 750 segments to match existing setup? (while I know it is not a requirement that the sizes be the same - as BTRFS can handle mismatched sizes) - I'd like to use the extra 750Gb for another/different share other than cache (since this portion won't be mirrored)
- Will mirroring of the old data happen automagically once setup/established as a pair?
- The instructions on wiki.unraid.net seem like, if followed, will add the compete new 1TB to the cache creating a portion that is mirror and a portion that is not? or does it just ignore the other 750GB?
- Is there a CLI method to complete/do this? Any reason to have to 'go there'?
- Anything else I'm missing or should consider
Thanks so much in advance for the help/guidance!
-
1 hour ago, Big Dan T said:
Hi all,
this is a real problem in plex for using an NVIDIA card for encoding (decoding work fine) is there anyway to update the drivers to 450.66 ?

im Currently on 440.59
thanks all!
D.
Yes...the Beta is currently using the updated drivers
-
Just a FYI and update...after thinking variables weren't being adding/initialized - it was a dumb mistake of not supplying the key value (just naming it the variable name). duh!
Thanks again for the kindness to hunt down the bug/issue!
-
40 minutes ago, saarg said:
You have not added the GPU to the container. There are no env variables for the UUID and the compute options. So no wonder it's not working.
Also, why do you volume mount the transcode folder of the appdata to /transcode? It's already in the appdata volume mount.
So strange...I have it listed as a PLEX variable entry?! I've been also setting up LinuxServer.io and noticed that is was present in the docker run command there....so, progress!
when you say 'compute options' - do you mean the NVIDIA_DRIVER_CAPABILITIES = 'all' ? or something else?
the transcode info must be part of PlexInc's setup....should I remove?Thanks again - this really helps!
-
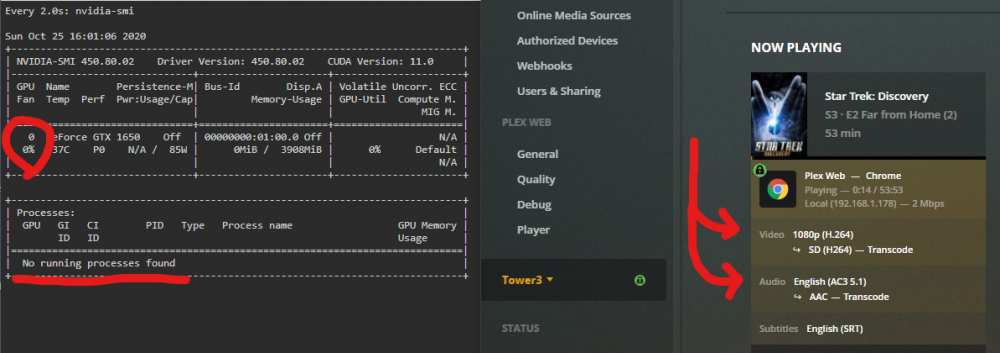
If I understand it right...when transcoding the audio & video - it should be activating the GPU?
-
Which was the procedure describes by Space Invader via:
-
4 minutes ago, saarg said:
Did you activate hardware transcoding in plex and do you have plex pass?
Did you follow the first posts for setting up the plex container?
Post your docker run command.
Check box within PLEX Settings --> Transcoder (Disable video stream trancoding - unchechecked, Use hardware acceleration when available - checked, Use hardware-accelerated video encoding - checked))
Yes, PLEX Lifetime pass
Setting up PLEX Container --> added the 'Extra Parameters: --runtime=nvidia, and two variables (with 'all' and UUID)
docker run command:
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='PlexMediaServer' --net='host' --privileged=true -e TZ="America/Chicago" -e HOST_OS="Unraid" -e 'PLEX_CLAIM'='Insert Token from https://plex.tv/claim' -e 'PLEX_UID'='99' -e 'PLEX_GID'='100' -e 'VERSION'='latest' -v '/mnt/user/appdata/PlexMediaServer/Library/Application Support/Plex Media Server/Cache/Transcode/':'/transcode':'rw' -v '/mnt/user/appdata/PlexMediaServer/':'/data':'rw' -v '/mnt/user/Recorded_TV-Archive2/Kindle_Movies/':'/media/Kindle_Movies':'rw,slave' -v '/mnt/user/Recorded_TV-Archive2/':'/media/TV_Shows-Tower3':'rw,slave' -v '/mnt/user/Music-Library/':'/media/music_redo':'rw,slave' -v '/mnt/user/Pictures/':'/media/Photos':'rw,slave' -v '/mnt/user/appdata/PlexMediaServer':'/config':'rw' --runtime=nvidia 'plexinc/pms-docker'8201a247e5df38516ddff953b83e577e35e2391d02d50adf2f4203eaa35b0c3e
-
Hi Everyone,
I've recently purchased and installed a Geforce GTX 1650 (after initially setting up the plugin on the existing GeForce GT 1030 - which doesn't 'do' transcoding I found out afterwards). I've changed the UUID (to the new card), rebooted/powered-off a few times, changed from the Nvidia 6.8.3 to Nvidia 6.9.0 beta 30 builds - all in an effort to get it working (as evidenced by seeing the 'running process' and percentage load changed via nvidia-smi engage when I watched a video that is 'transcoding' in PLEX). All to no avail - nothing I seem to do is getting the GPU to engage (constantly at 0%).
Is it because I'm running the plexinc/pms-docker rather than the LinuxServer.io version? If so - that would seem strange but can someone provide a HowTo in switching a PLEX setup (with a few external users) from one to the other?
Is there something I can share (logs, etc) that might help?Thanks in advance - just trying to get it to work and at wits end.
-
[SOLVED}
edit /root/.bash_profileadding the line:
export PATH="$PATH:/mnt/user/scripts"
-
Can you help me to correctly modify/set-this-up? I've looked through my 'go' file and don't see that the path variable is set there. I'm nervous about setting one as it might overwrite where it setup (somewhere else)?
Thanks again - dave
-
Great idea....thanks!




[Support] [Depreciated] FlippinTurt PiHole DoT-DoH
in Docker Containers
Posted
Looks like there is a v5.5.1 'hot fix' just released:
https://pi-hole.net/2021/08/04/hotfix-pi-hole-web-v5-5-1-released/#page-content