

rcmpayne
-
Posts
121 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by rcmpayne
-
-
Im trying to bring in a docker that has not been converted to UNRIAD but its advising the following
volumes: - $DOCKERDIR/idrive/config:/work/IDriveForLinux/idriveIt - $BACKUPDIR:/home/backup:ro environment: - TZ=$TZ - PGID=$PGID - PUID=$PUIDFor TZ, PGID and PUID, I created the variables like this;
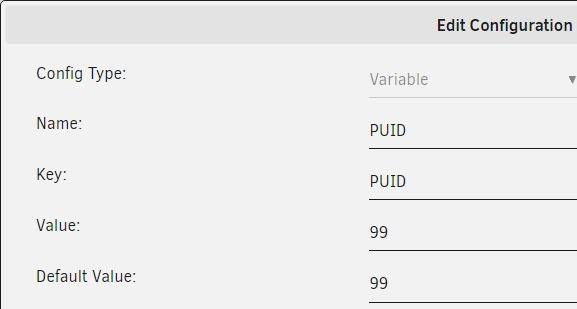
However, how do I correctly add $DOCKERDIR ?
-
2 hours ago, remotevisitor said:
Yes. A format will remove any existing files/directories on the drive.
So you will need to copy the contents to somewhere else
Can "somewhere else" be another drive in the array? Example:
1. Use terminal to move data from Disk1 to Disk2
2. Format the drive1 to XFS
3. Add the drive back to the array?
-
I have 3 disk which i would like to format from reiserfs to xfs. My question is, do I need to move the data off the drives to do this or is there a easy way? Idon't mind doing one at a time as I have enough space to move data around if needed.
-
Hey folks. I cant figure out how to create two dockers for openvpn-as. Even if I rename the config folder and the name it takes over the previous one.
Sent from my SM-N970U1 using Tapatalk -
I just read through all the post again, I'm sorry I don't see it. I see one link to an external page but it's way over my head. I see multiple people asking what this is and I'm not seeing any responses to it. maybe I'm blindThis question has been answered I think x3 in this topic.
Sent from my SM-N970U1 using Tapatalk
-
What do we mean by "Add docker container VPN network support." I'm running openvpn as on a docker so this seems intriguing to me but I'm not really sure what it means.
-
On 1/4/2017 at 6:34 PM, SpaceInvaderOne said:
You will have access to whole network
Is it possible to set up the OpenVPN-as server so it can't access specific internal IPs? I want to ensure users connecting can't access specific servers/shares. I was doing this with pfsense OpenVPN but since I switched to an Unifi UDM-Pro, I can't openvpn from the router anymore. What I would like is to allow the user connecting to get external internet and not internal access. (I know that kind of defeats the purpose of a VPN but I am doing this to trick my remote android TV boxes to route my TV app through my house ISP so it allows me to watch live tv.)
-
9 hours ago, Squid said:
You set the mover schedule to be as often as you want the plugin to run and apply it's rules. If you want at some point mover to move all the files then you set that custom cron schedule down at the bottom of the plugin's settings (or run mover manually)
OK I get it now, thanks. If I set the default settings to run every hour or every day, when it triggers, it won't just start moving, it will check the plug in add on and then only move if the size is greater than 80% of the disk.
-
I have been getting a error in syslog about disk7 having Cache is disabled
Feb 1 08:47:02 Server root: Fix Common Problems: Warning: Share Downloads set to not use the cache, but files / folders exist on the cache drive
Feb 1 08:47:21 Server root: Fix Common Problems: Other Warning: Mover logging is enabled
Feb 1 08:47:21 Server root: Fix Common Problems: Warning: Write Cache is disabled on disk7
Feb 1 08:47:23 Server root: Fix Common Problems: Warning: Unassigned Devices Plus not installedroot@Server:~# hdparm -W 1 /dev/sdk
/dev/sdk:
setting drive write-caching to 1 (on)
write-caching = 1 (on) -
7 minutes ago, Squid said:
I would use the mover tuner plugin instead of the script.
Ok, just installed it... looks like the same question still exist for this new plugin right?
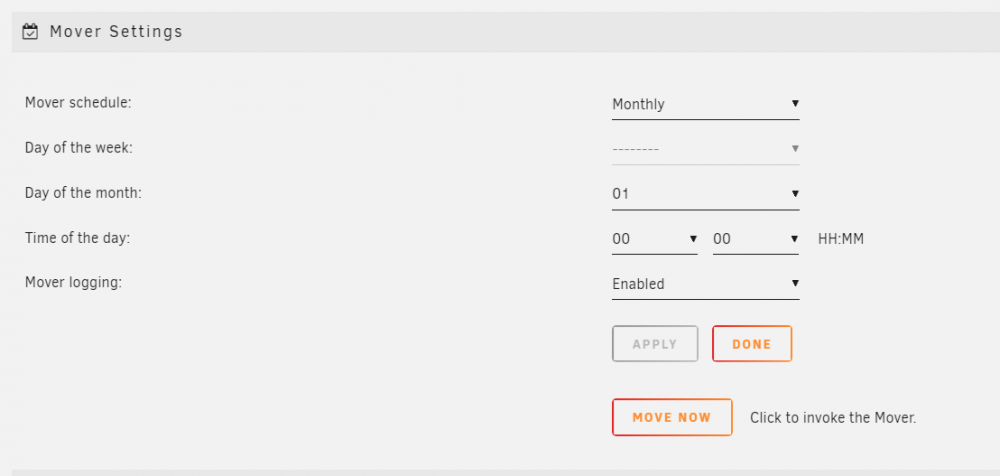
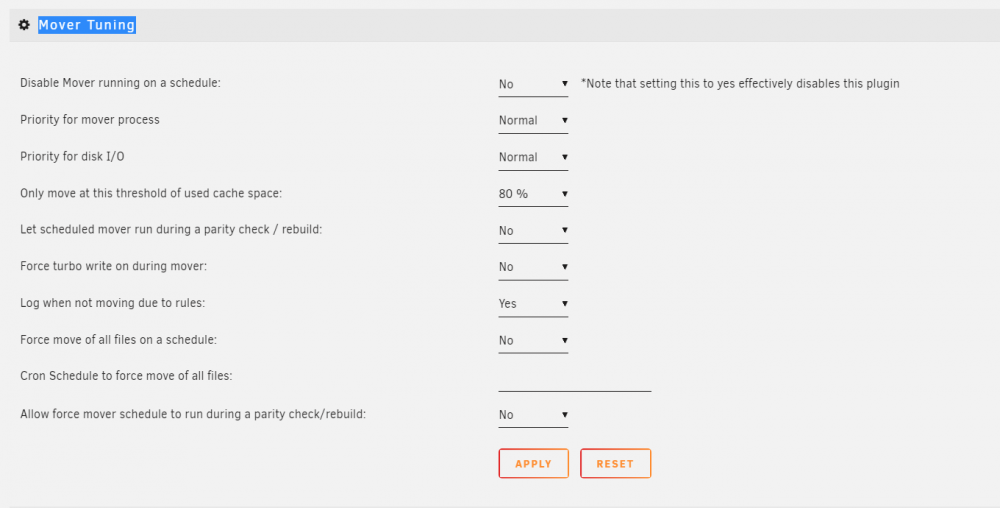
-
On 7/23/2016 at 1:00 PM, Squid said:
Run mover at a certain threshold of cache drive utilization.
Adjust the value to move at within the script. Really only makes sense to use this script as a scheduled operation, and would have to be set to a frequency (hourly?) more often than how often mover itself runs normally.
#!/usr/bin/php <?PHP $moveAt = 70; # Adjust this value to suit. $diskTotal = disk_total_space("/mnt/cache"); $diskFree = disk_free_space("/mnt/cache"); $percent = ($diskTotal - $diskFree) / $diskTotal * 100; if ( $percent > $moveAt ) { exec("/usr/local/sbin/mover"); } ?>I just added this script and set it to 80% and run hourly. The question I have is what do you set the Mover Settings in http://Server/Settings/Scheduler set to? it looks like it cant be disabled so I assume you max it to monthly maybe?
-
Power flickered and for some reason my ups did not hold. Anyway the disk3 shows disabled (red x). Wondering if I can get some assistance with a review.
Disk 3WDC_WD30EFRX-68EUZN0_WD-WCC4N5LP0K5H - 3 TB (sdd)
xfs_repair status -nPhase 1 - find and verify superblock...
Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk
Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 3 - agno = 1 No modify flag set, skipping phase 5
Phase 6 - check inode connectivity... - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ...
Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting.
-
Is it possible to add the Stable Candidate and testing branches to the docker config?
-
I have two security cams that are logging directly to my unraid server (Cache drive) in Mp4 10MB files. I am wondering if someone can recommend a program/docker/script that might scan each camera folder and combine the files in maybe 1h chunks. Furthermore, wondering if a docker/android app exists to watch/sream these videos locally or remove without the need for my laptop and smb.
Any recommendations for those that store security video on your unraid server would be greatly appreciated.
-
5 hours ago, Hoopster said:
I don't know if the issue is with the container, but, it is the only thing that has changed recently with my UniFi network.
Every couple of days ALL of my devices go into the disconnected/adopting loop. It is guaranteed to happen if I reboot the server for an unRAID update (currently on 6.7.0 rc5); at least it has both times I have updated OS since moving to this container. I either have to manually run set-inform or change the container to host (maybe I will leave it there) to get the devices to be readopted.
I am still running the same version of UniFI (5.9.29) and the same firmware (the latest on all devices) as I was with the prior container with which I never had these issues through many updates. Again, I don't necessarily know why it would be the container as I do not see other reports of repeating adoption issues, but, it is the only change on my UniFi network, so, I am starting there.
If the answer is "it is NOT the container and something else is broken", can you point me at what that might be?
Latest server log attached
Here's the docker run command:
Command: root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='unifi-controller' --net='host' --log-opt max-size='100m' --log-opt max-file='2' -e TZ="America/Denver" -e HOST_OS="Unraid" -e 'UDP_PORT_3478'='3478' -e 'TCP_PORT_8080'='8080' -e 'TCP_PORT_8443'='8443' -e 'TCP_PORT_8880'='8880' -e 'TCP_PORT_8843'='8843' -e 'UDP_PORT_10001'='10001' -e 'UDP_PORT_1900'='1900' -e 'PUID'='99' -e 'PGID'='100' -v '/mnt/user/appdata/unifi/':'/config':'rw,slave' 'linuxserver/unifi-controller:5.9'Can you try turning on L2 adoption in the UniFi controller. When I was on host mode I was having this problem and after turning on L2 adoption everything fixed itself.
Obviously you need the two ports 1900 and 10001 which I see you have.
Let me know if this works for you
-
Another issue I just found is when I add UDP 1900 as a port it does not show up.
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='unifi-controller' --net='br0' --ip='192.168.0.101' --log-opt max-size='50m' --log-opt max-file='1' -e TZ="America/Halifax" -e HOST_OS="Unraid" -e 'UDP_PORT_3478'='3478' -e 'TCP_PORT_8080'='8080' -e 'TCP_PORT_8443'='8443' -e 'TCP_PORT_8880'='8880' -e 'TCP_PORT_8843'='8843' -e 'UDP_PORT_10001'='10001' -e 'TCP_PORT_6789'='6789' -e 'PUID'='99' -e 'PGID'='100' -v '/mnt/user/appdata/unifi-controller':'/config':'rw' 'linuxserver/unifi-controller:latest'
bdccaa76c7e239f12a4706a4b823c61b8c429cd08ede539bc77b459af80b27f3
The command finished successfully! -
Having an issue when i move the docker to Custom: Br0 due to having conflicts with host mode. When i change to Br0 custom, i get this error. Things seems to be working at first glance tho
Brought to you by linuxserver.io We gratefully accept donations at: https://www.linuxserver.io/donate/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [cont-init.d] 10-adduser: exited 0. [cont-init.d] 20-config: executing... [cont-init.d] 20-config: exited 0. [cont-init.d] 30-keygen: executing... [cont-init.d] 30-keygen: exited 0. [cont-init.d] done. [services.d] starting services [services.d] done. Feb 25, 2019 9:15:56 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: I/O exception (java.net.ConnectException) caught when processing request: Connection refused (Connection refused) Feb 25, 2019 9:15:56 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: Retrying request Feb 25, 2019 9:15:56 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: I/O exception (java.net.ConnectException) caught when processing request: Connection refused (Connection refused) Feb 25, 2019 9:15:56 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: Retrying request Feb 25, 2019 9:15:56 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: I/O exception (java.net.ConnectException) caught when processing request: Connection refused (Connection refused) Feb 25, 2019 9:15:56 PM org.apache.commons.httpclient.HttpMethodDirector executeWithRetry INFO: Retrying request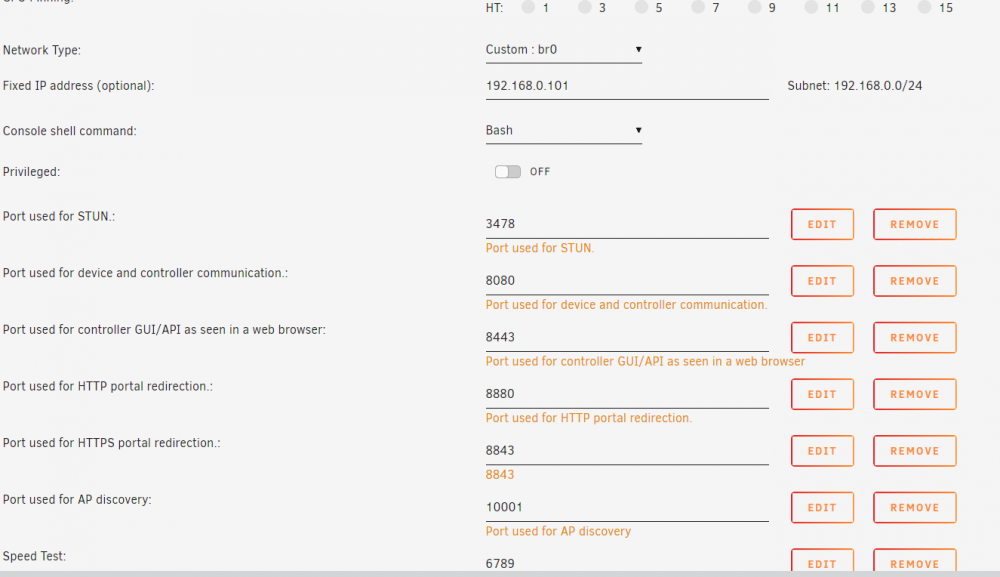
-
not sure why but i fixed it. One of my dockers is piehole and my unraid adapter had the piehole ip as a dns entry for DNS 1. I removed this dns entry from my unraid adapter and now the error is gone and the update for docker reports back in a few seconds
-
When i open my Docker tab and try to do a check for updates, it spins forever and the following is see in the log. anyone know how to fix this connection timeout? I do have a letsencrypt nginx docker running.
root@Server:/var/log# tail -f /var/log/syslog
Jan 29 19:26:04 Server kernel: docker0: port 4(veth94d12fa) entered disabled state
Jan 29 19:26:04 Server kernel: device veth94d12fa entered promiscuous mode
Jan 29 19:26:04 Server kernel: IPv6: ADDRCONF(NETDEV_UP): veth94d12fa: link is not ready
Jan 29 19:26:05 Server kernel: eth0: renamed from veth74e9146
Jan 29 19:26:05 Server kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth94d12fa: link becomes ready
Jan 29 19:26:05 Server kernel: docker0: port 4(veth94d12fa) entered blocking state
Jan 29 19:26:05 Server kernel: docker0: port 4(veth94d12fa) entered forwarding state
Jan 29 19:26:06 Server avahi-daemon[15111]: Joining mDNS multicast group on interface veth94d12fa.IPv6 with address fe80::3c1d:5eff:fefb:7687.
Jan 29 19:26:06 Server avahi-daemon[15111]: New relevant interface veth94d12fa.IPv6 for mDNS.
Jan 29 19:26:06 Server avahi-daemon[15111]: Registering new address record for fe80::3c1d:5eff:fefb:7687 on veth94d12fa.*.
Jan 29 19:28:14 Server nginx: 2019/01/29 19:28:14 [error] 15188#15188: *6858 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 192.168.0.141, server: , request: "POST /plugins/dynamix.docker.manager/include/DockerUpdate.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "192.168.0.100", referrer: "http://192.168.0.100/Docker"Jan 29 19:28:14 Server nginx: 2019/01/29 19:28:14 [error] 15188#15188: *6858 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 192.168.0.141, server: , request: "POST /plugins/dynamix.docker.manager/include/DockerUpdate.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "192.168.0.100", referrer: "http://192.168.0.100/Docker"
I am on 6.7.0-rc2 but was having the issue on the release branch as well
192.168.0.100 is unraid
192.168.0.141 is my laptop
-
Is it possible to add this within the docker?
https://github.com/Kevin-De-Koninck/pi-hole-helpers/blob/master/README.md
Sent from my Pixel 2 using Tapatalk -
Hello All,
I have been using letsencrypt nginx for a few years now and all is working fine except for a new entry i added. Ive added a docker for pihole which is using the following. Note: my unraid is on 192.168.0.100.
pihole is the first docker to run in custom br0 mode. all other dockers are using host or bridge mode on the same ip ad unraid (.100)
Current domains
tv,sab,unifi,movies,guac,router,unraid,pihole
in nginx i've added a new entry for pihole.domain.com and duplicated a existing nginx config but when i use this address i get a 502 bad gateway.
server { ssl_session_cache shared:SSL:10m; ssl_session_timeout 4h; listen 443 ssl http2; ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3; ssl_session_tickets on; root /config/www; index index.html index.htm index.php; server_name pihole.mydomain.com; add_header Strict-Transport-Security "max-age=31536000; includeSubDomains" always; ssl_certificate /config/keys/letsencrypt/fullchain.pem; ssl_certificate_key /config/keys/letsencrypt/privkey.pem; ssl_dhparam /config/nginx/dhparams.pem; ssl_ciphers ECDH+AESGCM:ECDH+AES256:ECDH+AES128:!3DES:!ADH:!AECDH:!MD5; ssl_prefer_server_ciphers on; client_max_body_size 0; location / { auth_basic "Restricted"; auth_basic_user_file /config/nginx/.htpasswd; include /config/nginx/proxy.conf; proxy_pass http://192.168.0.101; } }nginx log for pihole request
2018/11/11 19:17:34 [error] 377#377: *1 connect() failed (113: Host is unreachable) while connecting to upstream, client: 142.xxx.xxx.xxx, server: pihole.mydomain.com, request: "GET / HTTP/2.0", upstream: "http://192.168.0.101:80/admin", host: "pihole.mydomain.com" 2018/11/11 19:17:37 [error] 377#377: *1 connect() failed (113: Host is unreachable) while connecting to upstream, client: 142.xxx.xxx.xxx, server: pihole.mydomain.com, request: "GET /favicon.ico HTTP/2.0", upstream: "http://192.168.0.101:80/adminfavicon.ico", host: "pihole.mydomain.com", referrer: "https://pihole.mydomain.com/" -
I have dual AMD Opteron™ 4386 @ 3.1 GHz cpus and the tips and tweaks shows the following. any ideas how to fix this?
CPU Frequency Scaling
Driver: * no driver *
Governor:
root@Server:/tmp# cpufreq-info -d root@Server:/tmp# cpufreq-info -o minimum CPU frequency - maximum CPU frequency - governor root@Server:/tmp# cpufreq-info -g root@Server:/tmp# cpufreq-info cpufrequtils 008: cpufreq-info (C) Dominik Brodowski 2004-2009 Report errors and bugs to [email protected], please. analyzing CPU 0: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 1: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 2: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 3: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 4: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 5: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 6: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 7: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 8: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 9: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 10: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 11: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 12: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 13: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 14: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms. analyzing CPU 15: no or unknown cpufreq driver is active on this CPU maximum transition latency: 4294.55 ms.Edit: found the issue. i checked the BIOS and found the CPU was set to performance mode. i changed it to OS controlled and its working now
CPU Frequency Scaling
Driver: ACPI CPU Freq
Governor: Power Save
-
Ok I backed up the drive to a spare and removed and re-added it to the array. After it rebuilt, everything was backed and matched the backup I took.
Sent from my Pixel 2 using Tapatalk -
If I do a new config, will it rebuild the missing data from that drive?
Sent from my Pixel 2 using Tapatalk





[6.12.8] Log full of "SATA link down (SStatus 0 SControl 310)" on ATA1 "Flash Boot USB"
in General Support
Posted
Hello All,
I was looking at my server logs today, and they seem to be full of the following. While doing a few searches and commands, it appears to be related to my Flash USB boot drive. Any ideas what this may be, as it appears that my USB drive was replaced not long ago?
Mar 19 19:48:17 Server kernel: ata1: limiting SATA link speed to 1.5 Gbps Mar 19 19:48:18 Server kernel: ata1: SATA link down (SStatus 0 SControl 310) Mar 19 19:48:18 Server kernel: ata1: limiting SATA link speed to 1.5 Gbps Mar 19 19:48:19 Server kernel: ata1: SATA link down (SStatus 0 SControl 310) Mar 19 19:48:19 Server kernel: ata1: limiting SATA link speed to 1.5 Gbps Mar 19 19:48:20 Server kernel: ata1: SATA link down (SStatus 0 SControl 310)root@Server:~# ls -l /sys/class/ata_port/ total 0 lrwxrwxrwx 1 root root 0 Mar 4 19:41 ata1 -> ../../devices/pci0000:00/0000:00:1f.2/ata1/ata_port/ata1/ root@Server:~# ls -l /dev/disk/by-path total 0 lrwxrwxrwx 1 root root 9 Mar 4 19:41 pci-0000:00:1d.7-usb-0:3:1.0-scsi-0:0:0:0 -> ../../sda lrwxrwxrwx 1 root root 10 Mar 4 19:41 pci-0000:00:1d.7-usb-0:3:1.0-scsi-0:0:0:0-part1 -> ../../sda1 root@Server:~# ls -l /dev/disk/by-id total 0 lrwxrwxrwx 1 root root 9 Mar 4 19:41 usb-Kingston_DataTraveler_3.0_408D5CE4B641B541295B036A-0:0 -> ../../sda lrwxrwxrwx 1 root root 10 Mar 4 19:41 usb-Kingston_DataTraveler_3.0_408D5CE4B641B541295B036A-0:0-part1 -> ../../sda1smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.1.74-Unraid] (local build) Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org /dev/sda: Unknown USB bridge [0x0951:0x1666 (0x110)] Please specify device type with the -d option. Use smartctl -h to get a usage summaryserver-diagnostics-20240319-2346.zip