

jimbobulator
-
Posts
123 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by jimbobulator
-
-
Hello,
Woke up to a disabled disk today, having trouble deciphering exactly what's going wrong. Diagnostics attached.
- I had some read errors a few months ago on both older drives (disk2 and disk4, both 6TB drives, both older 4-5 yrs old) but smart looked fine on both, so I continued running.
- Server is getting older, built in 2014.
- Parity check started yesterday but didn't finish due to disk2 failure.
- disk2 failure happened late in the parity check and this drive likely wasn't doing anything at that point, as it's 1/2 the size of parity.
- I'm seeing recurring out of memory errors happening between 3-4am each day, along with Plex being killed each time.
I can't really make sense of what's going on, clearly more than just a failed drive. Maybe someone can help? Should I run memtest?
I don't have a spare disk at the moment, but I can copy the data to another disk in the array and remove the failed disk, or copy it off the array if that's safer.
Thanks!
-
On 5/2/2021 at 9:08 PM, theoracle09 said:
I'm finally getting around to updating and getting things working again after the tightening. I've followed the stickied post and spent hours in the FAQ trying to get this working, but I can not get other docker web GUIs to load. b-delugevpn settings:
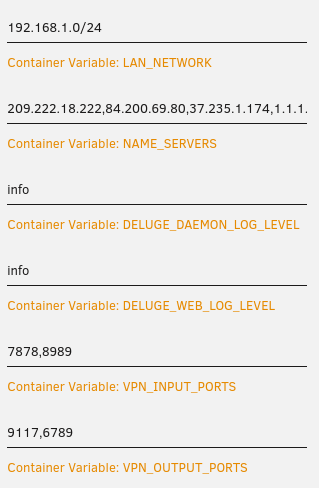
Lan Network is correct and been verified using the tool in Q4 on FAQ. I followed SpaceInvader One's video on routing through deluge and when typing "curl ifconfig.io" in each of the container's consoles I'm getting the IP from the vpn. Radarr's configuration:
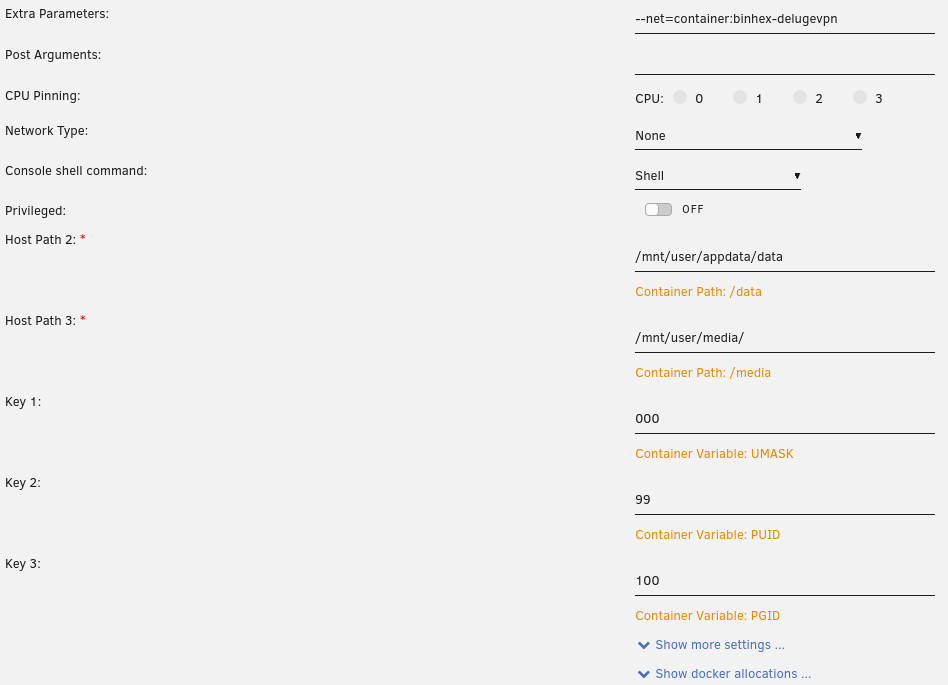
As you can see the extra parameters are set, the network type is set to none, and I've removed any port designations.
One thing I noticed is when the container starts, there's nothing under Port Mappings in the main docker page. See below:
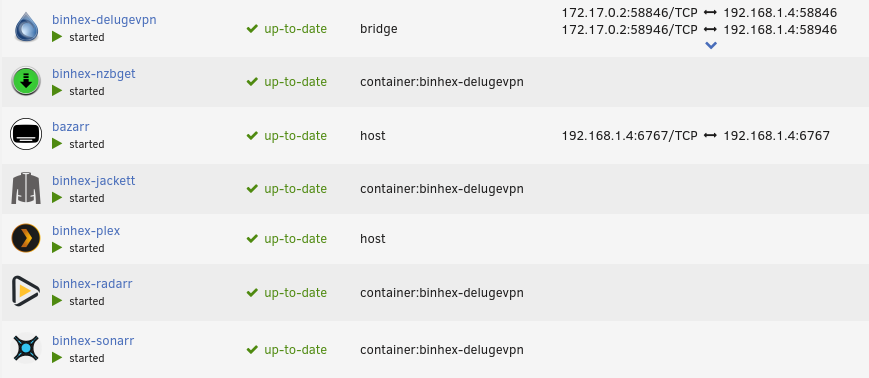
I have never used NZB, I just downloaded it to see if the web gui would load, which it does not. I'm unable to get the web gui to load on any container going through delugevpn. I've changed ovpn files to try different servers, but still no web gui. Not using privoxy in Deluge. I've also made sure deluge was restarted then the other containers restarted once deluge is up and running, still no web guis.
I've checked for spaces or weird line endings in the extra parameters box on each container, it's all correct. At this point I have no idea how to get the web guis to come back Thanks for any help!
Check your vpn container env. variables. I had to add the VPN_INPUT_PORTS variable per the FAQ recently to fix this.
-
Just to follow up, parity swap has completed successfully. Preclear went at reasonable speeds. All is good, so thank you kindly for the assistance. Feels good to have survived my first ever drive failure in 20 years of computing.
Now to preclear the drive with errors and see what happens!
-
6 minutes ago, testdasi said:
Something seems odd with that 6TB preclear.
Yeah it's odd. I checked my old 3TB 7200rpm reports from 7 years ago and they took 30h. I didn't shuck this 6TB, so I'm assuming that I precleared over SATA. But I do have a bunch of USB3 enclosures kicking around, maybe I used one for the preclear, and was affected by the same USB2 issues above. I have no way to know, unfortunately! Drive is working fine, read/write speeds are fine in the array.
The 12TBs are on track to complete preread in 20-30 hours, I think, which seems ok. Not sure why they started slow.
-
8 hours later, one is reading at 130MB/s and one at 137MB/s.
-
6 minutes ago, itimpi said:
The preclear normally starts at the outer (fastest) tracks and gradually slows down as it moves towards the inner (slower) tracks assuming the connection to the server is fast enough. Are you sure the enclosures are USB3?
Yes, it's supposed to be USB3. I can't imagine someone making a 12TB enclosure that didn't support USB3!
-
I just looked up my last preclear report, 6TB from a couple years ago, this one was connected on SATA.
This one was slow too! Oof. Is this normal? I remember pre-clearing my first unraid drives back in 2013 and seeing 180MB/s. Maybe I should post in the preclear thread....
############################################################################################################################ # # # unRAID Server Preclear of disk # # Cycle 1 of 1, partition start on sector 64. # # # # # # Step 1 of 5 - Pre-read verification: [41:50:01 @ 39 MB/s] SUCCESS # # Step 2 of 5 - Zeroing the disk: [41:52:52 @ 39 MB/s] SUCCESS # # Step 3 of 5 - Writing unRAID's Preclear signature: SUCCESS # # Step 4 of 5 - Verifying unRAID's Preclear signature: SUCCESS # # Step 5 of 5 - Post-Read verification: [63:14:18 @ 26 MB/s] SUCCESS # # # # # # # # # # # # # # # ############################################################################################################################ # Cycle elapsed time: 146:57:14 | Total elapsed time: 146:57:14 # ############################################################################################################################ ############################################################################################################################ # # # S.M.A.R.T. Status default # # # # # # ATTRIBUTE INITIAL CYCLE 1 STATUS # # 5-Reallocated_Sector_Ct 0 0 - # # 9-Power_On_Hours 0 147 Up 147 # # 194-Temperature_Celsius 43 57 Up 14 # # 196-Reallocated_Event_Count 0 0 - # # 197-Current_Pending_Sector 0 0 - # # 198-Offline_Uncorrectable 0 0 - # # 199-UDMA_CRC_Error_Count 0 0 - # # # # # # # # # # # ############################################################################################################################ # SMART overall-health self-assessment test result: PASSED # ############################################################################################################################ --> ATTENTION: Please take a look into the SMART report above for drive health issues. --> RESULT: Preclear Finished Successfully!. -
It's late here so I'm calling it a day. The pre-read speeds are slowing creeping up, started around 20MB/s and now at 30MB/s. If it gets past 60 I guess it's not stuck at high speed / usb2, but not sure why it would be this low.
Could it be that it's just reading at the middle of the platters and it's naturally slower, and will speed up over time? That still seems crazy slow though.
Cheers!
-
I couldn't get a video output working to get into the BIOS, so I had to open the case and reset it manually. I went through all the settings, including enabling the xHCI/EHCI handoffs. Now lsusb is showing 5Gbps connections for my connected USB drives (success?), but the preclear is proceeding at the same speed as before (fail!). Argh.
Edit: removed diagnostics
-
Hello,
I'm trying to preclear some 12TB drives in external enclosures over USB. Currently pre-reading at ~20MB/s. Yikes, should be ~200MB/s.
lsusb indicates that it's a 480Mbps interface, and there's not any usb 3.0 interfaces shown at all. A one point a few years ago I was having difficulty passing through USB devices to VMs, and spent some time messing around with BIOS settings for xHCI/EHCI handoff, perhaps I've left this setting in a weird state and it's disabled usb3 capability? I don't remember ow I left it.
Kids are streaming a movie at the moment and I need to drag up a monitor/keyboard to check BIOS settings. Will update when I get a chance.
Thanks!
-
2 minutes ago, trurl said:
A disabled disk is no longer in sync with parity. The only options to get it enabled again are to rebuild it, or New Config and rebuild parity instead. Rebuilding the disabled disk is the recommended procedure in most cases (and in your case).
Right, of course. Thank you very much for the prompt and efficient help!
-
1 minute ago, trurl said:
Not sure why it would say array turned good when you still had a disabled disk.
Agreed, this is strange. It's how it went down, though.
The drive is still disabled - I assume Unraid keeps the drive disabled on successive boots after a write error, to ensure no further damage?
1 minute ago, trurl said:If you want to backup anything before your start you can copy files from the emulated disk to another computer. I never recommend trying to shuffle files to other disks in the array when you are already emulating a disk, since all disks must be read to get the contents of the emulated disk, and moving or copying to the array is just more activity when you are already without protection.
This was my thoughts as well. I've got a plan now: copy off critical files to an external disk (paranoia), then attempt a parity swap with a bigger drive. Will report back in a few days or a week once it's *hopefully* cleared up.
-
Well, unfortunately my server rebooted today for unknown reasons. I got a notification that "array turned good", which was sent after the reboot. So sadly I don't have the juicy syslogs, and stupidly I turned turned off the syslog to flash setting a while back. Doh.
Here is a recap of the notifications I got today.
07:36 - Notice: Parity Check Started 10:54 - Alert: Disk 2 in error state (disk dsbl) 10:54 - Warning: array has errors. Array has 1 disk with read errors 15:11 - Notice: array turned good. Array has 0 disks with read errors 15:11 - Notice: Parity check has finished (0 errors). Duration 17 hours, 53 minutes, 19 seconds. Average Speed nan B/sNotes
- After the notification at 10:54 I logged in remotely and saw the disk2 was disabled, and the "Main" page summary that disk2 had 2048 errors.
- I couldn't see the SMART data for disk.
- The parity check was now a 'read check'
- I wasn't able to log back in throughout the day.
- The parity check notification is bugged - clearly wasn't 17 hours, and probably should've said 'Read check has finished", I suppose?
Anyway, disk2 now shows 88 reallocated sectors. Most of the contents of this disk are non-important media, but there are some things with clear priority that I'd like to try and save. What's the best step forward?
Diagnostics removed.
-
Thanks for the answers!
2 hours ago, trurl said:3 hours ago, jimbobulator said:I have a disabled drive due to read errors.
Unraid only disables a disk for write errors. It is possible for a read error to cause Unraid to get the data for the failed read from the parity calculation and try to write it back to the disk. If that write-back fails then the disk would be disabled.
Ok, the notification just said read errors, but I'll check tonight.
1 hour ago, trurl said:3 hours ago, jimbobulator said:I'll probably replace all the old Seagate disks with 10 or 12TB drives. If I replace the current failed drive with a >6TB drive I'll have to format for 6TB to match parity, then later I'll need to reformat it once I get a bigger parity drive, correct? I'd rather avoid getting a 6TB drive now (it's a SFF case so larger capacity the better).
This is confusing, I suspect because you are confused about what "format" does. You must let Unraid format any disk it will use in the array, and you must NEVER format a disk you are rebuilding. And you must NEVER format any disk that has data on it you want to keep. I just don't see how the idea of "format" figures into this at all.
Right that was not clear at all. First and foremost, my priority is to recover the data from the failed disk and get the array healthy again. I could buy a 6TB drive and rebuild disk2 onto that one. But I'd rather not buy another 6TB drive, as I have limited physical space in my server. So if the replacement drive could be bigger than my current parity disk, I might consider that.
As it's not a normal procedure, let's scrap this idea. This is why I asked... What I was thinking, which is likely the 'short-stroking' you mention: Could I assign a new disk2 that is larger than parity and let it rebuild? Would Unraid would limit the size of the filesystem to parity size? Then later on, I'd replace parity with a drive matching or exceeding disk2's true capacity, copy of the data from the disk2 somewhere else, and then format disk2 it to it's true capacity.
1 hour ago, trurl said:There is already a method for replacing a disk with a disk larger than parity. Actually, what it does is copy parity to the larger disk then use the original parity for rebuilding the failed data disk.
Ok, this might work... I'm already at the device limit for my Unraid Basic license and the limit of SATA ports on my mobo, so I'm not sure I can do all the steps yet. Will read more closely and see if this is a possible solution.
-
Hello,
I have a disabled drive due to read errors. I'm at work and can't physically access the server until later, so diagnostic files and such will come later. I'd like to ask a few questions first in case I want to order a drive or something now so it's here tonight (or tomorrow). I'm worried and want to make sure I don't do something wrong.... First disk issue in 7 years on Unraid.
Facts
- Unraid v6.8.0
- 1x 6TB WD Red parity.
- 1x 6TB WD Red Enterprise
- 3x 3TB Seagate drives shucked from external enclosures 6 years ago (notorious for early failures). One of these is the disabled drive. I'm aware that I'm living on borrowed time here.
- Smart values were all good, no errors or pending sectors, etc. when checked a few weeks ago.
- Power flipped off then on this morning and kicked off a parity check.
- Halfway through the check I get a notification that there are read errors and Disk 2 is disabled.
- Verified by logging in remotely on my phone. Showing 2048 errors Disk2 and doing a read check.
- Judging by the giant generator on the street outside my house and the electrical company truck sitting there, I'm assuming my house is being powered by this generator while they are working on the something. Yay for clean power.
Questions
- Should I order a replacement drive ASAP? Is there a possibility that it's something else (bad connection or similar).
- I'll probably replace all the old Seagate disks with 10 or 12TB drives. If I replace the current failed drive with a >6TB drive I'll have to format for 6TB to match parity, then later I'll need to reformat it once I get a bigger parity drive, correct? I'd rather avoid getting a 6TB drive now (it's a SFF case so larger capacity the better).
-
What should be my first steps tonight for troubleshooting? My thoughts
- Backup USB
- Get the diagnostics
- Run a SMART on Disk 2 if possible
- Reboot and see if drive is responsive?
-
What are my options for data recovery?
- Copy data off, assuming drive is responsive (it's not currently).
- Rebuild with new drive?
- The 3x Seagate 3TB drives were at 90% for several years and didn't see much or any write activity. I recently deleted some old media I didn't need, so it's likely new files have been written in the last month. Might this have accelerated the death clock a bit?
And of course this all happens as I'm in the middle of finally testing out a proper offsite backup system in place. The most critical files (several TB or family photos) are duplicated somewhere else thankfully.
Thanks!
edit0: numbers added on questions
-
edit: I figured it out. The %T part seems to be the issue, I'm guessing because it uses colons. Replaced with more specific values to get HH.MM.SS rather than HH:MM:SS and it's okay now. Cheers.
Hello. Weird issue. My script is writing to a logfile in my appdata share (works fine). I'm trying to move the file to a unique, dated file for each run of the script (daily). I'm using $(date) to append the date to the log file. Works fine in a shell session, but when I run it from my script, the resulting filename is something like BEZTLJ~Z.LOG.
mv /path/to/logs/logfile /path/to/logs/logfile.$(date "+%F.%T").logNormal logfile is named correctly. Dated logfiles have garbled filenames. Any ideas what I'm doing wrong?
-
I like that I can add a drive at a time. I like that I can switch hardware very easily. I like the community and support available. I like the continuous development and improvement. I like that Unraid is an appliance when I need it to be one, or a homelab when I want it to be one. I like that Unraid hasn't become a subscription service like everything else. Wait. I was just supposed to pick one thing?
For the future I would like Unraid to continue evolving and improving without losing focus on it's core stability as a file server.
-
I tried a dry-run (1.3.7) moving the contents of a old disk (disk2) onto an empty disk (disk3). I selected all the shares in settings. I was expecting nothing to change, being a dry-run, but to my surprise this morning, 700GB out about 2.1GB of data was moved from disk2 to disk3 during the dry run. Shouldn't the dry-run leave everything where it is? And weirder still, if it didn't do a dry-run, why only move some of the files?
Where can I find the log files for unbalance?
Hi, right ... dry-run shouldn't move anything.
You can find the log file at /boot/logs/unbalance.log
I'll take a look at the logs tonight and see if I can see anything weird.
-
I tried a dry-run (1.3.7) moving the contents of a old disk (disk2) onto an empty disk (disk3). I selected all the shares in settings. I was expecting nothing to change, being a dry-run, but to my surprise this morning, 700GB out about 2.1GB of data was moved from disk2 to disk3 during the dry run. Shouldn't the dry-run leave everything where it is? And weirder still, if it didn't do a dry-run, why only move some of the files?
Where can I find the log files for unbalance?
-
As an aside I lost my webui links from the drop downs for all my containers back in the late betas for v6. Never got around to troubleshooting after my comment in the beta thread got lost. New containers have the correct links but old ones don't. Deleting and recreating from local templates didn't fix it, if I recall.
-
Using needo-plex. I was able to reduce and possibly completely remove the ballooning docker utilization by mapping the Plex transcoding outside of the docker.img file. I haven't watched it closely to see if it is completely stable or not but I've stopped seeing it go up GB at a time. I can see the transcode temporary files being generated in my external folder. I did not make any settings in the Plex WebUI related to transcode location - the temporary transcode location setting is blank.
To me this was a smoking gun for my problem. I thought that Plex was not transcoding anything, but as it turns out it's occasionally transcoding audio and often transcoding between contains (direct stream vs. direct play), which generates the same large temporary files. I'm surprised more people aren't seeing this issue since even using direct stream with container transcoding can easily generate many GB of temporary files and none of the Plex containers have any instructions on how to map transcode directories, or why it should be done.
-
Could be Plex - that seems plausible. My Plex streaming is local and video usually isn't transcoded except for some x265 stuff recently. Audio is sometimes (only DTS, I think).
Assuming this is the problem, I have no interest in dedicating RAM to transcoding; I think it's a waste when I have a perfectly good SSD with lots of space. If/when I get some time I'll dig in and see if I can track the disk usage inside the docker...
-
The solution is to configure your dockers properly, more specificly on your volume mappings and to not run dockers that do constant updates.
My 5 docker containers use less than 1.7gb total after an entire month. Recent addition was PyTivo which added 1gb to the size because it uses a different base image.
I'm confident in my docker mapping configuration. None of my dockers (only 5 running) have any constant updating beyond the way needo-plex and needo-plexwatch update on restart. I basically never restart them. So I don't think this explains it.
The last two times I noticed a rapidly ballooning docker.img I happened to be using streaming locally from Plex. Both times were direct play with audio transcode, relatively high bitrate files. I'm not sure it's linked to Plex, just a casual observation.
These are the dockers I'm actually running:
binhex-sonarr
binhex-delugevpn
needo-plex
needo-plexwatch
hurricane-ubooquity
As per my understanding of docker, the images are static, and when we start a container, it's basically an running instance of said container. With btfrs and qcow2, the incremental size on disk of this instance shouldn't be significant, unless it changes significantly from the image. That shouldn't be happening though. Is there a way to check the size on disk of a running container instance vs. the image sizes found by running "docker images"?
-
Thanks I will check this out tonight.



disk disabled + recurring out of memory errors
in General Support
Posted · Edited by jimbobulator
Hello, thank you for the response. I checked and re-set the drive connectors and did a hard reboot to see if it would come back. I could hear a drive doing a click / click / click routine, and now it's showing disk2 as not installed. I'm thinking it's completely toast? I'm going to start moving the data off that drive in preparation for removal.