

Abnorm
-
Posts
93 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Abnorm
-
-
Just checked out this today, really liked it, was looking for some specific dvd extras which I found on youtube and wanted to host locally on my plex server. I'm a bit of a sucker for behind the scenes stuff
")
I would just like to recommend a function, the ability to pre-fetch items in the playlist you're trying to download, and not start the download right away but rather let the user decide when to start the actual download.
I'm getting a lot of issues with ticking off selection boxes and out-of-memory errors for large playlists, resulting in not being able to remove unwanted items from the queue. Tried multiple browsers, though all are chromium based.
Thank you for creating this docker though, it is really useful
-
 1
1
-
-
9 hours ago, jonathanselye said:
Well assuming you want to build a 1PB server with lets say 20tb drives, you still need minimum of 50, and that is without parity and may be reduced with format capacity, im just saying.
If you need petabytes of available storage, is really unraid the best way to go ?
-
 3
3
-
-
11 hours ago, jonathanselye said:
I hope in the future the said 30+ drive limit will be removed and so we have an option to extend our zfs with vdev pairs(eg 4 device,5 device,6 device) for speed and also for more parity im currently building a 1pb server and im sad that i might outgrow my unraid server as much as possible i want to switch OS i want unraid's simplicity and user friendlyness as well as S tier UI i hope in the future end user have the choice to have no limit on the array even if we have to accept a pop up that we are doing it at our own risk, i can live with that.
I know that this was not really in the pipeline specially when unraid was built its target market was home enthusiast and at that time hard disks was not that affordable so at that time devs did not think that people will chuck in more that 30 drive in their servers but now that the times have changed specially server grade equipments are more affordable and easier to acquire even, i hope Limetech can look at my simple request
I have 100TB available storage, i use 21 drives including m.2 cache. I don't see how i'll ever end up with 30+ drives, my single rack chassis can fit 24 drives max. As density is increasing almost monthly on drives, when a drive dies I'll replace it with a drive with nearly double or triple the capacity of the failed disk. Reducing the amount of drives and reducing the power consumption.
Server grade equipment (like HPe, Dell etc) usually have the 24-drives limitation per chassis either way. Yes, there are exceptions.You mention that people will put more drives in server grade equipment, that is not really how it works. Newer server gear today has more data density, meaning more capacity but uses less space, which translates to less drives but drives with way more capacity, less rackspace required = profit and savings on hosting stuff in datacenters, where space is at a premium.
If you're thinking of using up old small capacity drives, that's fine, but isn't it better to just recycle them and buy some bigger drives, save $$$ on power and at the same time be a little greener ?
Also, if the request was simple, unraid would support 30+ drives already.
-
13 hours ago, Kilrah said:
It doesn't "make drives faster", but the point is that on the standard unraid array you may have 8 drives but when you read/write a file it always comes from/to one single drive, limiting individual file access perrformance to one drive's performance. ZFS is/works as a RAID array, so accesses are spread across multiple drives depending on pool configuration.
For example a 5-drive raidz1 will be a bit less than 5x a single drive's performance.
I see, thanks for clearing that up. Parity is written across the vdev and not to a single drive, that will provide a real life performance benefit for sure.
-
On 2/1/2023 at 5:31 PM, Kilrah said:
ZFS pools give more performance but at the price of the flexibility that unraid is known for.
It's just an extra option that can be used instead, in addition in a separate pool, or... ignored completely if that's not something you want/need.
Could you please elaborate on the actual real life performance benefits for zfs vs a classic unraid setup (1 parity, 1 m.2 raid-0 cache, bunch of drives) ? Will it magically make mechanical drives faster ? How will redundancy affect performance ?
I seem to see a lot of people say "its just faster and better" - well, is it, really ?
I'm not at all against changes, I just think people are hyping this way to much for the actual real life performance benefits.
Just to be clear, I don't believe in magic.
-
Hey, just a quick question, would it be possible to add some functionality to force unmount stuff? Especially having issues with NFS where it sometimes crashes on the nfs-server, unable to remotely restart my unraid box since it never stops trying to unmount. Have to cycle power (not a big deal, it only runs a few dockers).
NFS at least has a lazy mode unmount switch which would solve this perhaps.
-
Foreword; not relevant to SMB
I seem to get this issue now, never had it before.
My setup is like this:
I have a Debian VM running on my main unraid box, this has rar2fs installed. On this VM I mount my media shares via NFS3 first, then I point rar2fs to those shares which in turn mounts the unrared/fusefs files to seperate folders which in turn is shared via NFS3 to my secondary box. The secondary box mounts these shares with the unassigned devices-plugin with NFS3 which in turn are mapped in the plex docker for my media locations.
When doing some troubleshooting I've found that the rar2fs/fusefs stuff works fine, no processes are crashing or whatnot. It seems that the initial NFS3 mount between the main unraid box and the VM goes stale. When that happens the unrared media is not available in plex (naturally). But there are only 2 folders this happens to, they are not the biggest, they're the smallest, which is bizzarre.This has worked perfectly before i upgraded to 6.9/6.9.1, so I wonder what actually has changed here that can be related.
Turning of hardlinks did not work, allthough worth mentioning I have not rebooted the servers after disabling this. I will try that tomorrow just to make sure.
PS: I've also tried changing allowed open files to an astronomical value without any difference. As this seems to be somewhat relevant to why you get stale file handles.
-
read the documentation. webui can be reached at http://<yourip>:8080/pwndrop
-
On 10/1/2020 at 5:35 AM, gbdavidx said:
how can i prevent this from happening again? Can i export the logs somewhere else?
you might be able to reconfigure the log location, adding a location in your variables but you'll need to look into the unms config files i presume. I have not tried it myself, maybe @digiblur have some ideas ? Maybe it would be possible to setup the docker to let us configure log locations ourselves?
-
Had this exact issue today, I've recently changed from a Raid0 w/2 ssd-drives to a single ssd. Had to reformat my cache drive to fix this as mentioned earlier in this thread. Strange issue but whatever, it works again !
Ramblings;
Just had to delete my docker.img file and redownload the dockers (you'll get a notice about this when you try to enable your docker service after the reformat and backup restore)
Oh and just a side note, I took a backup of the data with: rsync -a --progress /mnt/cache/ /mnt/disk1/temp before formatting of course. (reverse when copying back).
And just a note, plex database files failed to copy, i suspect since the cache got "full" it somehow corrupted the db-files. Thankfully my plex takes its own db backups so just had to roll back to latest backup by renaming the affected .db files, all good now.
-
Hey guys,
first of all, thank you @Ich777 for all your hard work, this is a great addition to any unraid deployment!
So me and a few friends started messing around with Arma3, it's really fun but without any mods it's, well.. Arma..
Any idea how you define specific mods to be added to a server deployment? I see theres a "Mod" field in the docker config but no idea how to use it.
Would love some pointers, I though maybe if the account connecting to steam are subscribed to specific mods in the workshop that it would sort it out itself.
Thanks again for this great addition, have a good one!
-
Hey all,
I'm in the process of moving my server to a new rack chassis and needed some sff-8643 compatible controllers for the backplane. Bought two Dell WFN6R via ebay and this worked for me:
https://jc-lan.org/2020/01/09/crossflash-dell-0wfn6r-9341-8i-to-9300-8i-it-mode/Links corrected - Thanks @wow001 !
https://www.broadcom.com/site-search?q=installer_P16_for_UEFI
https://www.broadcom.com/site-search?q=9300_8i_Package_P16_IR_IT_FW_BIOS_for_MSDOS_Windows
You'll need to short the TP12 jumper
Firmware and tools can be found on broadcom's site:
You'll need the following files:
Installer_P16_for_UEFI.zip - uefi flashing tool
9300_8i_Package_P16_IR_IT_FW_BIOS_for_MSDOS_Windows.zip - firmware etc.
use UEFI, dos mode didn't work for me
Hopefully this helps someone
Cheers!
-
2
-
-
On 9/2/2020 at 2:02 PM, b0m541 said:
Is it normal that the UNMS container is so bloated?
unms container: 3.67 GB writable: 1.81 GB log: 28.2 MBIf not, what can I do to get it back to normal?
Add this to extra parameters in the docker config page (you need to click "advanced view")
"--log-opt max-size=10G" without the quotes, this will append the log when it reaches 10Gb. You can set this to what you want though.
It is normal when the log is allowed to grow as it pleases.
-
9 minutes ago, emod said:
I posted diagnostics more than an hour before you posted your reply. Why didn't you read them?
You might give an example of a "rational person" if you read posts before you react. If you'd like to set an example of a "rational person", then carefully read the entire thread before reacting. If the way you react you seem fit (given ignorance of not reading the post and data provided), then you are no better than me.
The problem was triggered exclusively by updating UNRAID (and I've done that numerous time), with no changes to any other infrastructure components.
"Bashing"? No, warning of a very serious issue, which severely compromised the server. If other users of UNRAID see how raising issues results in personal attacks on the person who raised the issue, what is the likelihood that UNRAID problems will be raised to begin with?
Kk, good luck on troubleshooting.
-
Well it worked perfectly here, every update from 5.x to 6.8.3 has never given me a single issue. This has to be in your end. Post diagnostics, stop bashing unraid for your incompetence and behave like a rational person.
-
1
-
-
17 hours ago, johnnie.black said:
Converting to different profiles doesn't delete data but it's always recommended to backup anything important before starting.
Great, thank you for the input
-
Hey, I've been running 2x SSD's in raid0 for quite a while now, and I'm getting some write errors on one of the drives as they're getting pretty old. I've got a single 1 tb ssd replacement (getting the second one later).
So, how do I go about changing my cache to not use raid any more ? Should I just change the mode to "single" or will this delete the existing data? I'll do a backup first of course.
Thanks! -
i had partly the same issue before, but it was related to some cheapo marvel based sata controller cards, I've replaced everything and moved over to lsi raid cards (flashed out the raid-function). Could there be a issue with your sata controller and the new kernel perhaps ?
-
Hey
delete the docker including the image
then delete the appdata/mariadb folder
2. remove relevant appdata folders
-
Hey, seeing that DNS over HTTPS is getting more and more relevant these days, is it possible to include Cloudflared in a future (or maybe an alternative) docker image (https://developers.cloudflare.com/1.1.1.1/dns-over-https/cloudflared-proxy/ ) ?
A writeup on installation and setup; https://docs.pi-hole.net/guides/dns-over-https/I haven't messed to much with dockers before, but if the above is not possible, would the correct way to proceed be to fork this image to my own private dockerhub/git (not looking to steal any of Spants excellent and hard work though) ? Not sure if that's even possible though
Have a great day everyone!
-
Hey,
Nice plugin, thank you for the work you put into this!
I keep deleting games when my computer cleaning instinct kicks in, usually it means deleting all my steam games etc, but I get bored easily and are pretty random as to what i want to play at a given time. Last month i downloaded gta5 3 times  Just to save some time a cache would be nice, as I'm also have LANs from time to time with my friends. I could prolly stop freeing up diskspace, but hey, there's a even lazier option if i got it cached locally
Just to save some time a cache would be nice, as I'm also have LANs from time to time with my friends. I could prolly stop freeing up diskspace, but hey, there's a even lazier option if i got it cached locally
I tried getting this to work;
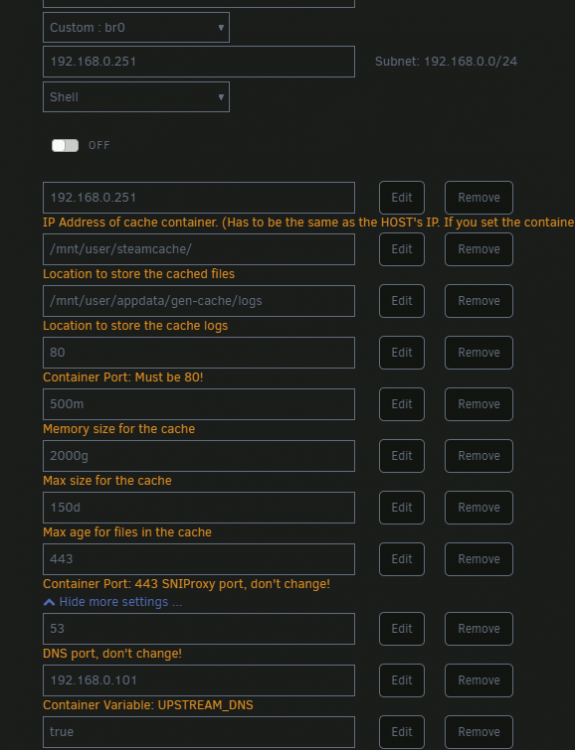
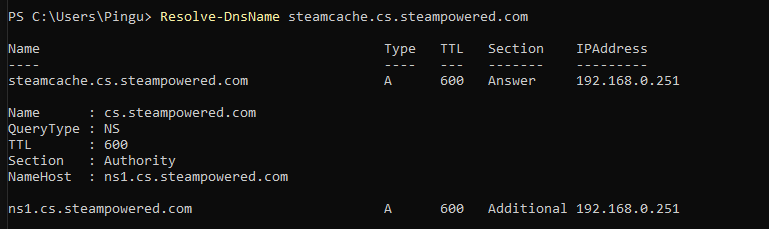
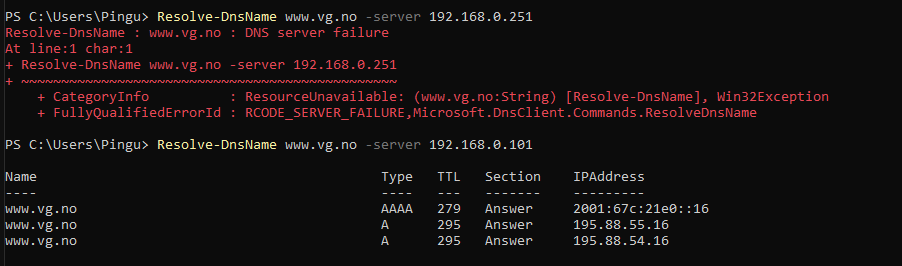
If i configure the steamcache ip as my dns on my gaming rig, it works downloading with steam, but dns is not working for any other sites.
192.168.0.101 is a pihole running on a different unraid server on my LAN. Pihole then in turn uses google dns.
Any advice ?
I though the point of defining a UPSTREAM_DNS means that all the stuff steamcache docker cannot resolve itself, it forwards the query to the upstream dns ip - which in this case is my pihole, and returns this to the client.
I see that I have some steam-dns queries from the docker ip, but as soon as i try something else it doesn't log anything.
-
*bump*
-
Hello fellow Unraid users.
I've gotten myself a secondary unraid license for my old gaming rig and seem to have some issues with stability.
It runs amongst other stuff the pihole docker and plex docker which my old box used to run. when i ran both these on my old box and a library scan is running, the old box is pretty much stuck in 100% cpu for hours and pretty useless for accessing media and using pihole (dns stops working). Prolly because of fillrate on my wd red drives. But no matter, the old storage box is not the issue here.
The issue i have with the new box is that after about 3-4 days pihole turns unresponsive resulting in no more dns. I could switch dns but that's not the point
I can access the machine in gui mode, webgui works but sometimes just doesn't respond to key/mouse inputs and forces me to hard reset (yes, this is far from optimal).
To me it looks like the network just dies followed by a panic state, at least that is what the symptoms would suggest.
I do not have a complete log of what exactly happens but I'll add the debug log, a screenshot of the systemlog right before it hung today and here are the hardware it is running on:
Model: N/A
M/B: MSI Z97 GAMING 5 (MS-7917) Version 1.0 - s/n: To be filled by O.E.M.
BIOS: American Megatrends Inc. Version V1.13. Dated: 02/16/2016
CPU: Intel® Core™ i7-4770 CPU @ 3.40GHz
HVM: Enabled
IOMMU: Enabled
Cache: 256 KiB, 1024 KiB, 8192 KiB
Memory: 24 GiB DDR3 (max. installable capacity 32 GiB)
Network: eth0: 1000 Mbps, full duplex, mtu 1500
Also to note, the NIC is a Killer E2205 - I'm thinking this might be buggy or something.
Are there any particular BIOS settings that could be messing this up perhaps?

-
2 hours ago, saarg said:
You have specified the port in the host variable. Remove the port and it should work.
Well, there you have it. It works !
Thanks a lot for the help, i was pulling my hair out, had to be something super trivial I had missed
-
1
-






HBA Temperature monitoring
in Plugin System
Posted
Hi,
A lot of users are most likely using LSI controllers from Broadcom in initiator target mode, it would be nice to monitor the temperatures in the dashboard as these cards get quite hot. Seeing trends over time is a good way to decide if you need to add more cooling/fans or what have you.
Came across a tool that seems to work on at least my card which is an LSI 9305-24i, I would assume most 93xx cards would work. There are also alternative tools (Megacli and lsiutil) that supports other models but unsure exactly which, it would be some work figuring out what supports what, but if more are interested there shouldn't be that big of a deal to at least look at the most commonly used models, 9xxx-series is at least among the most used I would think.
Storcli;
https://docs.broadcom.com/docs/1232743501
Unzip to folder
Enter folder
unzip Unified_storcli_all_os.zip
go to unzipped folder -> Linux
open storcli-007.2707.0000.0000-1.noarch.rpm in 7zip
browse to /opt/MegaRAID/storcli/
copy storcli64-file to somewhere on your unraid box
In terminal, run: ./storcli64 /c0 show temperature
(chmod +x if it's not executable)
should give the folllwing output;
root@tower:./storcli64 /c0 show temperature
CLI Version = 007.2707.0000.0000 Dec 18, 2023
Operating system = Linux 6.1.64-Unraid
Controller = 0
Status = Success
Description = None
Controller Properties :
=====================
--------------------------------------
Ctrl_Prop Value
--------------------------------------
ROC temperature(Degree Celsius) 37
--------------------------------------
Not sure if it's possible to utilize this tool to poll for readings ?