
-
Posts
16119 -
Joined
-
Last visited
-
Days Won
65
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by JonathanM
-
-
22 minutes ago, bytchslappa said:
lack of interest from the devs around this
Trust me, @limetech is very interested. It's a pretty small team, and lack of regular updates on every forum thread does not equal neglect of the product. They are very actively working on isolating the issue so they can fix it.
-
 1
1
-
-
It was an idea anyway. My thought process was that even though the CPU may not be vulnerable, the mitigations would still be applied in the code regardless. Honestly I don't know enough low level coding to be able to figure it out for myself, so I just wanted to advance the theory.
All these issues seemed to start popping up at roughly the same time frame, so it's tough to distinguish what may or may not be truly causal, or just coincidental.
-
12 minutes ago, johnnie.black said:
I have a small server here, based on a Core2Duo 8400, which isn't affected and the behavior is exactly the same.
So toggling the mitigations doesn't change anything?
-
Could you please toggle this plugin and check status with all mitigations enabled and disabled?
-
I wonder if the sqlite thing is related, since we know there have been issues with sqlite on the fuse system for some users for a long time, but recently it's become a major issue. Perhaps when the file system performance falls below some threshold, sqlite reacts poorly and corrupts instead of waiting for completion.
Maybe there is a latent bug in sqlite that is being triggered by i/o speed?
-
Does this happen on different browsers?
-
Does it happen on a normal restart? If not, then I would not classify this as an unraid issue. Servers should be on battery backup, as the results of unclean restarts are unpredictable.
-
Quote
I guess there will also be a problem if a small disk is used first and then replaced with a larger one, likely parity will say valid but it won't be synced past the end of the smaller device.
I think I remember something like that happening, where the first parity check after a "successful" parity build ends up with thousands of errors. That could be nasty if a user happens to add a larger data disk in that state before parity is truly correct.
-
40 minutes ago, CaryV said:
the signature gets 'wiped' upon formatting and the precleared condition could not be recognized.
Formatting not only removes the signature, it writes data to the disk, so it is no longer cleared. The filesystem format is data, whether or not there are any files written. A blank formatted disk is NOT clear, so it can't be added to the array without breaking parity.
Think of formatting as adding in filing cabinets to an empty room. There may not be any documents in the file cabinets yet, but they still take up space in the room.
-
7 hours ago, limetech said:
Thank you for the analysis, we'll study this further to see if we can create an auto-tuned setting for that.

-
6 minutes ago, itimpi said:
Perhaps the options reading something like:
- update ready (instead of ‘updated’)
- apply update (instead of ‘update ready’)
would be clearer and less likely to lead to confusion (and not take up more space)?
+1
Much better than the current wording.
-
8 hours ago, Can0nfan said:
makes it seem as its already "updated"
Well, from one perspective it is already updated. It's been updated at the source, and the update is ready to apply to your server.
I agree it's clumsy, but it does parse.
"Newer version available" Says the same thing, but wordier. Space is at a premium on that page, so I don't know what is better.
I guess the question is, did it make you aware there was an update that needed to be applied?
-
I believe this is an issue outside of @limetech's control.
-
Not that it this is the proper solution, but if you enable NFS it enables the dashboard as well.
To summarize, NFS or SMB (workgroup) must be enabled for the desktop to populate properly.
-
14 minutes ago, eagle470 said:
I've also discovered the CA plugin is no longer working properly due to DNS. Neither was speedtest.net.
I've rolled back to 6.6.7 at this point.
Works fine here, 2 systems upgraded with no such issues.
-
Restart in safe mode and see if that makes any difference.
-
On 3/30/2019 at 8:23 AM, RGauld said:
The console font appears to have changed. In GUI mode with my monitor attached directly to the server, the web interface font is so large I have to reduce the screen to 30% to get the icons to appear for logoff, reboot, etc...
This is probably an attempt to fix this
Dunno how that's going to be solved. Either some people have fonts that are tiny, or others have huge fonts.
-
Not sure if this is normal or not. Bottom left rebuild stats don't match tile.
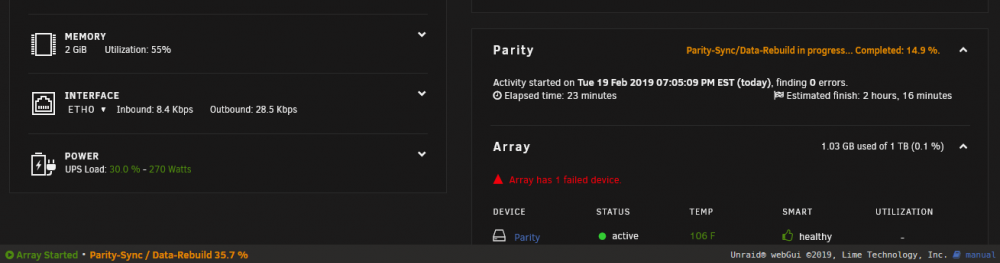
-
16 minutes ago, bonienl said:
No, this is under "management access"
Not a bug.
Is there a technical reason why the setting can't be shown in both places?
-
1 hour ago, trurl said:
Then something to "Apply" and the page would refresh with them sorted according to number.
Or, just click on the start order column header to sort by start order instead of sorting by some other column.
Yeah, it's a pretty heavy feature request. I've already been slapped for suggesting feature creep, so I'll shut up now.
-
3 hours ago, marshy919 said:
Not a bug report...
On the docker page, 99% of it is using your mouse to move dockers up/down.
It cancels out all other function, I can't copy/paste paths or addresses because it.
I don't think many people are interested in adjusting their docker rows that often that all other functionality is removed. There could be a small row to the left which allows you to do the same function.
Sounds like a feature request. Add a column to the far left, Start Order, with numbers indicating such. That would allow sorting based on the other columns, as the number would stick with the docker, until such time as the user dragged around the Start Order number in that column. You would be dragging the number to match the docker order you wished, rather than the way it is now where you drag to docker to the slot you want.
-
26 minutes ago, hawihoney said:
I'm reading disk17 and all disks spin up and have low read activity.
Do you have cache dirs plugin installed?
-
Still there. Notice the difference between our two screenshots?
-
This is not a new thing. I leave the webgui open in multiple browsers on multiple OS's, and it's been this way since before 6.5. Since my unraid servers are rarely rebooted, I don't get csrf errors from leaving the tabs open, but I've learned to just do a quick F5 before trying to interact with the GUI in any way.
This happens on Windows 7, 8.1, debian, and mint, just to name a few I have actively observed it on. Browser wise, now that I think about it, they are all varieties of firefox. I don't leave chromium open, so can't say it happens there.
Maybe it is a firefox thing.




SQLite DB Corruption testers needed
in Stable Releases
Posted
If you really want to, you could do something like you said if you have enough RAM. However... if you have a power outage, you will need to manually intervene and have a long enough UPS runtime to stop the docker service, move appdata and system share to an array disk, then shut down after all data is safely back on the array. I'd guestimate you'd need probably around an hour of runtime to get all that accomplished, so not a consumer grade UPS, or have a backup generator that will allow seamless power through the UPS.
Then, when the coast is clear, start the array, manually move the appdata and system to /mnt/cache (the mover won't work if there is no real cache drive), enable the docker service and be back up running.
If at any point the box shuts down before you get your data moved out of RAM, it's all gone.
So, theoretically given enough resources (RAM, UPS runtime) you could make it work.
However, it would seem to me that sourcing a SSD cache drive would be much cheaper and less stress.