

jameson_uk
-
Posts
78 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by jameson_uk
-
The config isn't variables. It is running a command within the container from the host. If I create the image this way (the same as going it via the extended search in CA) I cannot run the command. This is just running docker run -d --name='cloud-sdk' --net='bridge' -e TZ="Europe/London" -e HOST_OS="Unraid" 'google/cloud-sdk' I can't do a docker run as the container has been created and if I try and do a docker start, it just ends instantly. In the end I created the image as above (allowing me to add an image etc.) then I deleted the container docker -rm gcloud-config and finally created a new container using the run command. After that command is run you are able to start the container (although I don't actually need to) and it picks up all the details and images I set when I first added it. Didn't try adding the xml file manually but it looks like this is the only difference to when I created it via a docker pull
-
Indeed this is a viable option but it isn't just the cost of a hard drive. You need to have a box to run it on, electricity to keep the box on when you want to rsync and bandwith contention. Add on top of that the complexity of setting up firewall rules (or the potential to get things wrong and open your servers up to the world) and in general maintenance of a sever environment it isn't plug and play. This could be simplified by having a couple of USB hard drives and rsyncing to them. Send one off to a family member, next week do the same with the second drive and the family member could return the first drive. If I had another geek in my family I would probably go down this route but I wouldn't really want to be trying to remotely support my dad with a server issue. With a cloud provider you are removing any infrastructure and support issues. They provide massive scale redundancy. If the remote hard drive failed you would loose your backup. With a cloud provider this is effectively not possible. They have massive bandwidth available and tools that allow you parallelise operations much easier. They provide massive scalability. You could store PB of data if you wanted (it would cost a lot) without doing anything differently. They have security built in. Your data is in secure data centres. Access is tightly controlled. You can grant / revoke access easily You don't need to worry about upgrades or vulnerabilities. You are dealing with the cloud at a level of abstraction which means you don't need to worry about what version it is running on whether their servers have been patched for the latest zero day vulnerability. Archive storage at $0.0012 per GB / month seems relatively cheap for this. Looking at NewEgg I see over there a 2TB Ironwolf HDD costs $82.99. Based on the following assumptions You get 12 months free as part of your trial You never need to restore from your backup The HDD doesn't fail You are looking at $2.46 per month. So It would take 45.74 months (82.99/2.46 + 12) for the cloud charges to be the same as the drive (assuming it is going into an existing server and somehow electricity is free). Obviously this is fairy tale marketing and the whole point is that you might need to download this all one day. You also have to pay for network operations, there are other limitations (minimum storage periods etc.) that come into play in the real world. Even so I think you are looking at nearly four years before the HDD has paid for itself and what is the lifespan of a HDD nowadays?
-
This is very specific Google Cloud Storage (Archive). This is there for data that will be there for at least a year and will likely never be accessed. Standard storage for 2TB would be $40.96 a month so you would be far better off with any of the standard cloud storage offerings. This is enterprise grade stuff used by lots of big companies. It is encrypted and locked down by default (in fact I don't believe there is a way to turn encryption off). My understanding is that you can use a customer generated key for encryption which would not be accessible to Google and only you would have the key for decryption. With Gmail and other customer offerings, they are free. Google makes money by using your data. With Google Cloud you are paying for the service and it is aimed at companies not individuals so there are no privacy concerns. This storage is the basis of most cloud offerings and there is zero chance it would be shutdown. They could change the conditions on arhcive storage but they are competing with Amazon and Microsoft who both have similar options and similar costs so it is unlikely.
-
I don't know enough about Docker to understand how to do what I want but after pulling the image I am creating the container via docker run -ti --name gcloud-config google/cloud-sdk:alpine gcloud auth login This creates the container and stores user credentials in it. I did try via CA but this created the container and I wasn't able to embed my credentails afterwards. I was using start instead of run but I am not sure the container is configured to be run (docker files for the image are https://github.com/GoogleCloudPlatform/cloud-sdk-docker).
-
I have added an image manually via the command line docker pull google/cloud-sdk:alpine Doing this means there is no icon, no options etc. I guess this isn't an issue as everything works but it would be nice to have it setup like the others. Do I just need to create a manual file in /boot/config/plugins/dockerMan/templates-user if so is the name I need my-container-name.xml or my-image-name.xml ??
-
My collection isn't growing that much so it will probably still be around 500 GB. The free storage is 5GB but I am not sure whether this covers archive class buckets or not. Charges are then per GB. Still at $1.10 a month it is quite cheap. For 2TB the cost is a out $2.45 for storage plus the operations. I need to check how many operations rsync invokes but I am hoping that after the original upload (which would be covered by the trial) it should just be new and updated files and the cost would then be minimal. What would hit you is downloading 2TB from archive class storage is going to cost $102.40. The use case of this storage is that you don't access it regularly but even at this rate over 12 months you would be looking at $131.80 if you did download everything (12x $2.45 + $102.40). I can't see Google Drive pricing in US but I am guessing 2TB is $9.99? If so that would be £119.88 over the 12 months so would be cheaper but if you look over 24 months and downloaded once you would be looking at $161.20 vs $239.76 so the longer you have the archive without using it the cheaper it is. Not sure if you could get away with signing up for a new trial after 12 months and doing an other upload or not (I think they get payment details off you when you sign up to prevent this but I guess as long as you enter a different card it might work). For the cost and hassle of uploading everything again I am not sure it is with it though.
-
I hadn't but that is still $6 a month. I think using archive storage on Google Cloud should come out about $1.10 a month (probably slightly less) and is effectively free for a year
-
THESE ARE MY NOTES ON BACKING UP DATA TO GOOGLE CLOUD. THIS MAY COST YOU MONEY SO PLEASE ENSURE YOU READ THROUGH EVERYTHING AND ARE HAPPY DOING THIS AT YOUR RISK I have a 500GB+ music collection that I have carefully tagged and organised and after loosing a hard disk recently I started looking at a decent backup solution. My first through was a standard cloud storage option but the costs of getting 500GB storage get prohibitively expensive Google Drive - 2TB (£7.99/month or £79.99/year) Dropbox Plus (2TB) (£9.99/month or £95.88/year) Microsoft One Drive - 1TB but only as part of Micrsoft 365 (£5.99/month £59.99/year) Of these only the One Drive offering looks remotely tempting as it includes Office. Having used some of the cloud storage options for work I started looking for a more cost effective option. I did not want or need fancy synchronisation, a GUI or anything like that just somewhere to backup files to. Now the Cloud options for true backups started looking much much better. The cloud solutions for backup storage are based on files being stored but rarely accessed (ideal as the whole point of this is I should only ever need to restore from the cloud if something catastrophic happens). So Microsoft, Amazon and Google all have similar offerings and have a free tier but I have used Google Cloud at work so started there. Google offer a free trial which lasts for 12 months and comes with $300 credit which gives you plenty of room to play with and you won't be charged anything until you upgrade to a full account. So you can simply register for the free trial https://cloud.google.com/free signing in with a Google account. I can't remember whether you are guided through creating a project or not. If not you need to create a project which will hold everything together. When you get to the console you can navigate to the storage menu where you will an option to create a bucket (somewhere to store files). The name of this needs to be globally unique (an easy way to do this is included the project name in the bucket name). When you create the bucket you should see a monthly cost estimate on the right hand side so you can see what difference each of the options make. For the cheapest costs you want to chose Choose where to store your data Location Type - Region Location - US-WEST1, US-CENTRAL1, or US-EAST1 regions (These have additional free tier operations but Choose a default storage class for your data Archive Choose how to control access to objects Doesn't really make a difference but uniform is sufficient for our needs Advanced Settings Leave as defaults Now the storage costs for 500 GB work out at £0.49 per month which is obviously quite a lot cheaper than any of the options above. It isn't quite that simple as you also get charged for network operations. In our use case the main thing is going to be our initial storing of files so lets say we add 17k files so if we set 17k Class A Operations our monthly cost jumps to a massive £1.17. This however is only a one off cost of adding the files and all of this will be more than covered by the free tier credits. So I then started looking at getting this up and running. I am sure there are better ways of doing this and this can certainly be streamlined but this is relatively simple and seems to work well. Google provide a docker image with all their utilities included so lets pull the smallest, most basic image via the command line docker pull google/cloud-sdk:alpine We can then test this works and has connectivity docker run --rm google/cloud-sdk:alpine gcloud version as long as this output the version numbers we can then move to store our google login credentials in a container called google-config docker run -ti --name gcloud-config google/cloud-sdk:alpine gcloud auth login this will output a URL you need to copy and paste into a browser. You will need to log into your Google account and this will output a code that you need to copy and paste back into the command that should still be waiting for you. Now I want to backup my local share (/mnt/user/music) to my bucket docker run --rm -ti --volumes-from gcloud-config -v "/mnt/user/music:/music google/cloud-sdk:alpine gsutil -m rsync -r /music gs://<BUCKET_NAME> which does a few things --rm - deletes the docker container after we use it --ti - creates an interactive shell --volumes-from gcloud-config - mounts the data from the google-config container we created above and contains our Google credentials -v "/mnt/user/music":/music - This makes my share (/mnt/user/music) appear in the container under /music google/cloud-sdk:alpine gsutil -m rsync -r /music gs://<BUCKET_NAME> runs a Google rsync operation syncing /music to your bucket -m makes it run in parallel -r makes it process sub-folders I have left this running for about two days now and it is nearly finished copying 480 GB. My Class A Operation costs are running at £0.32 and I still have £242.42 credit remaining on my trial. I will get charged for storage later (looking at £0.49 each month) but again this won't touch the free credit. Once I have this all backed up I will see what the cost of running an rsync (with no changes) comes out as. I am not sure which operations rsync calls under the covers but I am hoping it should be pretty low. There is a warning here. The whole point of using archive class storage is that you don't access it. You will get charged a fair amount to download everything (I think it was in the region of £20 to download 500GB) which you would only need to spend in a disaster recovery situation. There is also a minimum storage term of 365 days so if you delete files you will be charged as if they had been there for 365 days. So just to reitterate where I started THESE ARE MY NOTES ON BACKING UP DATA TO GOOGLE CLOUD. THIS MAY COST YOU MONEY SO PLEASE ENSURE YOU READ THROUGH EVERYTHING AND ARE HAPPY DOING THIS AT YOUR RISK
-
I am currently looking at creating a backup of some of my media files in a Google Cloud storage bucket. Currently I am doing this on a windows client which is working fine but this is obviously access the files over SMB which is adding an overhead. It needs a python setup (which I have never managed to get working directly on unraid using Nerd Tools). Are there any really simple docker images for Python development (I can only seem to find useful info on packaging up python apps to run in docker)
-
Typical, this has been bothering me for weeks and I have just noticed the problem...... For some reason disk 1 had the "Spin down delay" set to never (no idea how this got set) and the other drives have use default... 😕 whoops....
-
I have disabled all my docker containers and still Disk 1 is always spun up when I check in the morning. In the logs I always have Jul 10 02:32:48 Deepthought2 kernel: mdcmd (94): spindown 3 Jul 10 02:33:59 Deepthought2 kernel: mdcmd (95): spindown 2 Jul 10 03:40:02 Deepthought2 root: mover: started Jul 10 03:40:02 Deepthought2 root: mover: finished Jul 10 12:09:10 Deepthought2 kernel: mdcmd (96): spindown 3 Jul 10 12:09:17 Deepthought2 kernel: mdcmd (97): spindown 2 but drive 1 just never spins down automatically. I spin the drive down manually (which is fine) but the next morning it is always still spun up. This is with no docker containers running. The drive is the same model as the other two data drives and only contains media files (all app data is definitely on the cache drive). The shares that are on disk 1 are all spread across disks 1 and 2. I have tried Open Files and File Activity plugins and neither show anything that is using disk 1. Is there any debugging I can do to figure out why the drive isn't spun down automatically (yet does spin down manually) ?
-
Every time I check disk 1 is spun up. I have tried the File Activity plugin but this doesn't show anything which makes me think it is a docker container. I have Plex Speedtest Tracker Unifi Controller up and running but there is no appdata on disk 1 (it is all on my SSD cache drive) I initially through it might be Plex doing a scan but media is spread across disks 2 & 3 too so if that was the case I would expect them to be spun up too. All three disks are the same make model too. Disk 1 only contains media files. I don't run any VMs and the docker image is on the cache drive. In the logs I see Jun 22 08:33:41 Deepthought2 emhttpd: Spinning down all drives... Jun 22 08:33:41 Deepthought2 kernel: mdcmd (93): spindown 0 Jun 22 08:33:41 Deepthought2 kernel: mdcmd (94): spindown 1 Jun 22 08:33:41 Deepthought2 kernel: mdcmd (95): spindown 2 Jun 22 08:33:42 Deepthought2 kernel: mdcmd (96): spindown 3 Jun 22 08:33:42 Deepthought2 emhttpd: shcmd (11211): /usr/sbin/hdparm -y /dev/sdb Jun 22 08:33:42 Deepthought2 root: Jun 22 08:33:42 Deepthought2 root: /dev/sdb: Jun 22 08:33:42 Deepthought2 root: issuing standby command Jun 22 08:33:45 Deepthought2 kernel: mdcmd (97): clear Jun 22 09:06:14 Deepthought2 kernel: mdcmd (98): spindown 3 Jun 22 18:54:53 Deepthought2 kernel: mdcmd (99): spindown 3 Jun 22 18:55:00 Deepthought2 kernel: mdcmd (100): spindown 2 Jun 22 21:28:10 Deepthought2 webGUI: Successful login user root from 192.168.1.51 Jun 23 02:32:24 Deepthought2 kernel: mdcmd (101): spindown 2 Jun 23 02:32:58 Deepthought2 kernel: mdcmd (102): spindown 3 Jun 23 03:40:01 Deepthought2 root: mover: started Jun 23 03:40:01 Deepthought2 root: mover: finished So I spun down all the disks and cleared stats at 08:33. I can then see some spin down logging but never any spin up. Any suggestions on how to identify why the disk is spun up?
-
I have often thought about backing up some of my media (mainly my 450 GB music collection) just in case the worst did happen. Personal options seem pretty expensive for this amount of storage so I have been considering Google Cloud archive storage (or possibly Amazon Glacier storage). This seems to be the cheapest storage option but you obviously get hit on restoring (which hopefully I won't ever need to do). Just wondering if anyone else has done this or whether there are other options?
-
I have just put in an old SSD as a cache drive and I am getting the following SMART health warnings pop up Unraid Cache disk SMART health [199]: 18-06-2020 14:41 Warning [xxx] - write sectors tot ct is 2313651806 OCZ-VERTEX_xxx (sdb) Unraid Cache disk SMART health [198]: 18-06-2020 14:41 Warning [xxx] - read sectors tot ct is 2399328758 OCZ-VERTEX_xxx (sdb) Which I believe is just the total number of sectors written to / read from. Looking at the config I can see the notifications state 197 - Current pending sector count 198 - Uncorrectable sector count 199 - UDMA CRC error rate Which would be things you would want to monitor for a HDD but looks like the codes have been (miss?) used for different attributes on the SSD. I take it I can just untick the options to notify against those codes as it is actually just reporting numbers against code 197/198/199 rather than what the numbers represent?
-
How do i have cron jobs remain after a reboot ?
jameson_uk replied to Ryan2207's topic in General Support
So I have this working with something I wanted to CRON but is there a way to tell this schedule is setup? crontab -l doesn't show up the job but it is running -
thanks, that makes sense. A cache drive isn't caching anything but is rather just a disk that is not part of the parity array. One thing that is still bothering me though is what the difference is between a cache drive and an unassigned one. Other than being able to overflow to the array if the cache drive is full what benefit do I get from setting up the SSD as a cache drive rather than just an unassigned disk with me pointing the docker containers at the mounted unassigned drive rather than cache?
-
I think I have misunderstood then. The wiki states which I read as all reads and write would take place on the cache. When mover runs it would sync up the array. If you were to ever loose the cache drive you would be left with appdata on the array and you would loose any writes since last time the cache was synced. I also came across something on Reddit which attempts to explain the difference between yes and prefer and has confused me even more After running the mover script I did see some appdata files on Disk 1 but I think this is because one of the docker containers didn't shutdown cleanly. I have now killed everything run the script again and now appdata is only on cache. If I change to yes, does this mean that writes are applied to the cache and then writer puts them onto the array? If so does that mean that reads are going to be from array as only the latest writes are stored on cache (and each time mover runs it will move whatever is on cache to array) ?? Is there a way to have a share on the SSD that isn't part of the array but syncs across to a share that is on the array?
-
The disks would only spin when it synced (overnight?) or the space ran out?? They shouldn't spin up at other times would they? Leaving at prefer should mean that I have a backup on the array that is at most 24 hours out of date?
-
I got nothing at all 😕 This did however solve it. appdata is excluded from the plugin due to the amount of logging, turns out I forgot to copy part of my appdata share over to the cache drive. Running the mover job now. Hopefully that should solve it.
-
I set this up and everything is working but the drives are still spinning. I reset the drive stats but there are still some reads and writes to disks 1 & 3 which is stopping them spinning down. There is nothing connected to the array but these docker containers are running. Any ideas how I can track down what is actually accessing the disks?
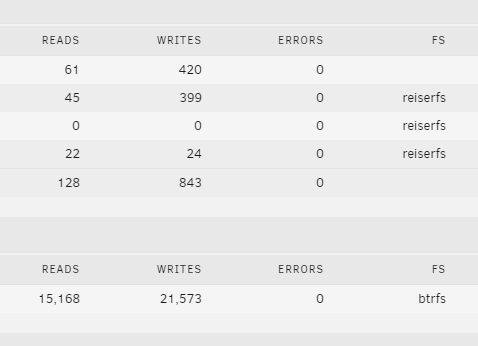
-
I have a fairly old 30 GB SSD hanging round and a spare SATA port in the server so was thinking about the best option to put it to use. I had noticed that my parity and disk 1 never spin down and I believe this is down to some Docker containers I am running (and presumably them logging to /mnt/apps in the array). I guess simply adding the device to the array wouldn't stop the constant activity on the parity drive so not sure this is that worthwhile? The server workload is mainly media storage and Plex with a few application Ubiquiti Unifi Controller Open VPN AS What is my best option to use the drive?
-
[Support] Linuxserver.io - OpenVPN AS
jameson_uk replied to linuxserver.io's topic in Docker Containers
OK here is what I did and what I was missing... The tickbox in the console sets it for everyone and I couldn't get the server to start after setting this. I also wanted to set it for a specific user as last time I couldn't get it to work so ended up having to trash everything and start again. So after setting up the user I opened up the console for the container and from /config/scripts I ran ./sacli --user <USERNAME> --key "prop_google_auth" --value "true" UserPropPut Then the key thing I was missing was that I needed to logon to the web interface rather than the Android client. Logging on via the Android client just prompts you for an authenticator code and doesn't give you the option to register. logging in via the web console lets you login and then gives you the QR code to register with Google Authenticator. Still haven't figured out whether this sticks following a container update??? -
[Support] Linuxserver.io - OpenVPN AS
jameson_uk replied to linuxserver.io's topic in Docker Containers
I have everything working but I want to setup Google Authenticator. Just setting the option to enable it in user management means I cannot login as anyone. Reading around it looks like I can add this via the command line? If I do this will it persist across container updates? (On a similar note I have read somewhere about the admin user returning after an update? Is this a thing?) -
[Support] Linuxserver.io - Plex Media Server
jameson_uk replied to linuxserver.io's topic in Docker Containers
I was using the Android app and didn't even think about the web portal. Having just tried and videos play in Chrome on my phone however the interface is pretty poor on a small screen. Given the app works when connected to WiFi and the VPN is obviously getting me to the server any thoughts on what I can try to get video playback working in the app via the VPN? -
[Support] Linuxserver.io - Plex Media Server
jameson_uk replied to linuxserver.io's topic in Docker Containers
By it do you mean VPN or PLEX? VPN is via a hostname that had a dynamic DNS entry. As for PLEX I am no longer sure.... I set it up years ago when there was a server config option and now you just sign in I don't know any more. How do you tell (and it is connecting to the server as I can see all the media) I am connecting to VPN over a strong 4G / LTE cellular connection.
