
ken-ji
-
Posts
1245 -
Joined
-
Last visited
-
Days Won
4
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by ken-ji
-
-
16 hours ago, deepbellybutton said:
So if I have a pretty vanilla implementation with 3 network interfaces (for no other reason than the motherboard came with two and I had an extra intel to plugin) what would my gateway be? I am currently only using eth0 with a gateway of 192.168.50.1 and UNRAID at 192.168.50.7.
What will my subnet and gateway be for assigning a fixed IP to get two containers running Plex?Thanks!
Best solution I can think of that uses base level network devices (ie plain switches and router)
Configure eth1 as follows (you can opt not to turn on bridging)

Then with the array stopped enable it in docker settings configure the network interface br1 (eth1 if you don't enable bridging)

make sure to use the same subnet as your main LAN (where you want Plex to be)
ie Subnet is 192.168.50.0/24
Gateway is 192.168.50.1
DHCP pool should be something like 192.168.50.0/24
- Ensure the DHCP pool is a range that your DHCP server will never assign (try to prevent collisions now to avoid headaches later on) - again the Docker DHCP pool is not a real DHCP pool and has no connection to the network's actual DHCP server/ nor will it communicate with the network's DHCP server
- 192.168.50.0/24 is the easiest value to use but if you run any containers on this network, there is a non zero chance of IP address collision if you do not set them up statically
- use http://jodies.de/ipcalc to compute possible subnets the fit your use case
When the docker service is enabled, configure/create your plex dockers with the following info

Change the IP to whatever you want it to be
This will make your Plex servers accessible at that specified IP address instead of the Unraid IP and as a bonus, all Plex traffic will use that 2nd network connection without sharing with the rest of Unraid.
-
On 8/12/2021 at 10:26 AM, wgstarks said:
I have a docker container that I’m setting up (locast2plex) on br0. I want to reserve a static IP for it on my pfsense router but I’m unsure how to get the MAC used for this docker?
Docker containers don't actually get their IP from the network DHCP server. the docker engine assigns them in order based on the pool you've set in the network config. Its your job to configure it so that the range will be outside of your DHCP pool (or have a way to ensure they will never conflict)
Here's my docker networks (w/VLAN):

The network is constrained to get IPs from 192.168.2.128-192.168.2.255 (my DHCP range is outside that range)
If you want each container to have a static IP, you can use just set the desired IP in the container settings
 On 8/14/2021 at 3:52 AM, wgstarks said:
On 8/14/2021 at 3:52 AM, wgstarks said:Can I run multiple docker/vm’s on br0?
You can connect as many containers or VMs as you want to the network interface, just take care to avoid dynamic IP assignment collision between the containers and the DHCP server.
-
On 8/9/2021 at 5:15 PM, mortenmoulder said:
I don't think I've ever used a more buggy application before. It constantly tells me to reauthenticate/allow access to Dropbox. Sometimes it says "Dropbox isn't running", when I know for a fact it ran perfectly fine just a couple of hours ago.
If I restart the container, it literally takes hours for it to be done with syncing, because I have a lot of data in my Dropbox.
And yes, I did set it up correctly, by selecting a share with the cache set to Only or No.
I know some of the blame is on Dropbox' side, but man.. I wish this worked perfectly without any issues what so ever.
Yeah, it seems the headless version is not getting as much love from the team.
Have you considered enabling LanSync (I think it is by default), and ensuring the container is on its own IP address (or using host networking). This should help it to sync very fast against your PC (if you have any)
However, mine will pickup right away except for some odd corner cases where rebooting Unraid will cause the container to think its on a new PC and require linking again.
I don't have a lot of data as I only have a free account, and have moved most of stuff to One Drive, being 1TB storage is part of the family package for Office, and shared files don't eat into your quota unless you make copies of the shared files. I'm still supporting this container, but am considering a different solution using rclone given my current use case..
Sorry I can't be much help.
-
I can't replicate it so maybe you have filenames with non-latin characters?
the dropbox.py in this container still runs on python 2.7 which is known to have some issues with string encodingBut I think that shouldn't cause any issue as the dropbox.py script is for interacting with with the headless client.
-
@editedweb
I've built a new image with the latest client (though my account auto updates the client to the latest beta) and I've had it running for a while without any noticeable issues.I have not seen the error message about Rust panic though.
-
5 hours ago, editedweb said:
I have recently been experiencing this error:
RUST PANICKING -- "couldn't deserialize, panicking: Io(Error { kind: UnexpectedEof, message: \"failed to fill whole buffer\" })" at "app/lib/apex/rust/analytics/src/queue.rs":332
This has been happening on two seperate4 machines. Any ideas what this error means? It kills dropbox, and a restart works for a while before subsequently having the same error.
Anything else I should be looking at?
I should also add, that this happened also with the 'dropbox by otherguy' package as well.
Its probably related to the current state of the official dropbox headless client
I'm building a new version of the package and having the client update to the latest to see what's going on.
-
Spending a little time reveals that the bash script is doing exactly the same thing as the WebUI
the webUI triggers this eventtoggle_state(up)which is a function that invokes this since it has no other parameters filled out
$.post('/webGui/include/ToggleState.php',{device:device,name:name,action:action,state:'STARTED',csrf:'REDACTED'},function(){resumeEvents(event,500);if (button) $(button).prop('disabled',false);});which then invokes a curl to http://127.0.0.1/update
function emhttpd($cmd) { global $state, $csrf; $ch = curl_init("http://127.0.0.1/update"); $options = array(CURLOPT_UNIX_SOCKET_PATH => '/var/run/emhttpd.socket', CURLOPT_POST => 1, CURLOPT_POSTFIELDS => "$cmd&startState=$state&csrf_token=$csrf"); curl_setopt_array($ch, $options); curl_exec($ch); curl_close($ch); }the important point here is the cmd parameter which is set using the device query param as "up" thus triggering the same spin up all drives
default: if (!$name) { // spin up/down all devices emhttpd("cmdSpin{$device}All=true"); break; }And I double checked. Clicking the button spins up all my drives at the same time, versus when I try to access my data in the share which is spread out across all my drives.
-
I understand your point, but to provide a counterpoint. those people are running their server dangerously since you should never spec a system with such marginal power capacity - even if your Bios says drive spin up is staggered.
That said, my script spinning everything up at once might be why its giving me issues with performance during parity tests...I'll look into this and add a bash snippet when I've figured this out.
-
come to think of it... the bash code is based on the php script earlier in the discussion.
maybe its not quite the same for current Unraid versions... -
The bash code does exactly what clicking on the webui button does. the parameters are all taken from that.
Its been the same as far as i can tell.
-
So I broke down the mover script
and determined the following command for my dir structure/mnt/cache/Media/Anime/I/Inuyasha Kanketsuhen/*.mkvmover would construct the follwing command
find /mnt/cache/Media/Anime -depth | moveI manually ran this command for more debugging
find /mnt/cache/Media/Anime -depth | move -d 2but only got the following lines in the log
Jul 9 22:09:15 MediaStore move: debug: move: exclude ffffffffffffffff Jul 9 22:09:15 MediaStore move: debug: move: real_path: /mnt/cache/Media/Anime/I/Inuyasha Kanketsuhen/[Raizel] Inuyasha Kanketsuhen - EP01 [BD 720p 10Bit AAC][05C1EB14].mkv Jul 9 22:09:15 MediaStore move: move: file /mnt/cache/Media/Anime/I/Inuyasha Kanketsuhen/[Raizel] Inuyasha Kanketsuhen - EP01 [BD 720p 10Bit AAC][05C1EB14].mkv Jul 9 22:09:15 MediaStore move: debug: create_parent: exclude 1 real_path /mnt/cache/Media/Anime/I/Inuyasha Kanketsuhen Jul 9 22:09:15 MediaStore move: debug: move: real_path: /mnt/cache/Media/Anime/I/Inuyasha Kanketsuhen/[Raizel] Inuyasha Kanketsuhen - EP02 [BD 720p 10Bit AAC][D57FDB5D].mkv Jul 9 22:09:15 MediaStore move: move: file /mnt/cache/Media/Anime/I/Inuyasha Kanketsuhen/[Raizel] Inuyasha Kanketsuhen - EP02 [BD 720p 10Bit AAC][D57FDB5D].mkv ... Jul 9 22:11:39 MediaStore move: debug: move: real_path: /mnt/cache/Media/Anime/I/Inuyasha Kanketsuhen Jul 9 22:11:39 MediaStore move: debug: create_parent: exclude 1 real_path /mnt/cache/Media/Anime/I Jul 9 22:11:39 MediaStore move: debug: move: real_path: /mnt/cache/Media/Anime/I Jul 9 22:11:39 MediaStore move: debug: create_parent: exclude 1 real_path /mnt/cache/Media/Anime Jul 9 22:11:39 MediaStore move: debug: move: real_path: /mnt/cache/Media/Anime Jul 9 22:11:39 MediaStore move: debug: create_parent: exclude 1 real_path /mnt/cache/MediaWhich doesn't tell us much, but when I check disk1 the entire directory has been moved there.
So I moved it back to cache disk and manually copy it over using mc to move from cache-> user0
and the files end up in disk5 (most free space) as directed by the High water setting
I'm starting to think there might be a bug in the move binary logic ...
-
Pretty sure the share config is okay since I've tested changing the min free space, which should have caused the config to be rewritten.
Weekend's coming up so I can probably do a few more tests
-
Hmm. I haven't observed it with any other shares as this is the most used one (and its the only share on Disk1 right now)
-
Can anyone take a look - Its really getting annoying - my only work around now is to either exclude Disk1 or manually migrate stuff off Disk1

-
You can probably run
root@MediaStore:~# docker network inspect br1 [ { "Name": "br1", "Id": "dd6c416d2efd0344bfd6f0bb0c3336dbd9e9f0ca3063f5afd599e083fb334f79", "Created": "2021-05-20T08:02:01.315812887+08:00", "Scope": "local", "Driver": "macvlan", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "192.168.2.0/24", "IPRange": "192.168.2.128/27", "Gateway": "192.168.2.1" } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": { "ed5c7c0711940e2afa7475732a0af723a6c1e18ef176762e300c398cd3511bb4": { "Name": "EmbyServer", "EndpointID": "aab01aaffad69b23bfa9719083fd9b14a6ba2d9eb16f54ea9786ef469d083253", "MacAddress": "02:42:c0:a8:02:46", "IPv4Address": "192.168.2.70/24", "IPv6Address": "" } }, "Options": { "parent": "br1" }, "Labels": {} } ]And pay attention to the Containers object as its a dict of the various containers plugged into that docker network.
My sample is IPV4 only since I'm using the SLAAC method to distribute IPv6 addresses (which does not require any adjustments to the Unraid networking if the delegated prefix changes)
And as long as the container mac address doesn't change, the SLAAC IPv6 address won't either
-
-
Hi
I've been having a weird issue lately, it seems when mover runs it insists on sticking all my files to disk1
even with the following share settings


only yesterday I invoked mover and it decided to stuff about 32G worth of files into disk1 when the high water allocation should move them to disk5
But moving files from my cache disk to user0 manually using mc or mv command moves the files correctly.
Any ideas where I've got it configured wrong?
-
@bonienl I think I've pointed this out before, but some fun points.
- Containers can use SLAAC (as advertised by a router) instead of DHCPv6 since some routers (Mikrotik ones in particular) do not support DHCPv6 completely - only SLAAC
This approach is extremely useful when your ISP doesn't even consider assigning you a static prefix and just delegates an entire /56 to you dynamically and you can configure your router to dynamically advertise the prefix
Docker networking in IPv6 wants a static prefix or you will be restarting the docker network whenever you need the prefix to change
In order to use SLAAC, the docker custom network does not need to have IPv6 enabled (or the interface for that matter)


To configure a container to enable SLAAC, you then need to pass the extra parameters specified
--sysctl net.ipv6.conf.all.disable_ipv6=0The container will then have its own IP address based on what the network is advertising (again SLAAC)
root@MediaStore:~# docker exec nginx ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 3: gre0@NONE: <NOARP> mtu 1476 qdisc noop state DOWN qlen 1000 link/gre 0.0.0.0 brd 0.0.0.0 4: gretap0@NONE: <BROADCAST,MULTICAST> mtu 1476 qdisc noop state DOWN qlen 1000 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff 5: erspan0@NONE: <BROADCAST,MULTICAST> mtu 1464 qdisc noop state DOWN qlen 1000 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff 6: ip_vti0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 7: sit0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN qlen 1000 link/sit 0.0.0.0 brd 0.0.0.0 75: eth0@if33: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP link/ether 02:42:c0:a8:5f:0a brd ff:ff:ff:ff:ff:ff inet 192.168.95.10/24 brd 192.168.95.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fd6f:3908:ee39:4001:a170:6031:f3df:e8b/64 scope global secondary dynamic valid_lft 3296sec preferred_lft 1496sec inet6 fd6f:3908:ee39:4001:42:c0ff:fea8:5f0a/64 scope global dynamic valid_lft 3296sec preferred_lft 1496sec inet6 fe80::42:c0ff:fea8:5f0a/64 scope link valid_lft forever preferred_lft forever root@MediaStore:~# docker exec nginx ip -6 route fd6f:3908:ee39:4001::/64 dev eth0 metric 256 expires 0sec fe80::/64 dev eth0 metric 256 multicast ff00::/8 dev eth0 metric 256 default via fe80::ce2d:e0ff:fe50:e7b0 dev eth0 metric 1024 expires 0sec
As I don't have DHCPv6, I think this approach will work for DHCPv6, but only if the container is designed to do DHCPv6, otherwise docker will not do DCHPv6 (it doesn't do DHCPv4 either) and instead has an internal IPAM (IP address management) which will simply assign addresses from the configured pool in the docker network.
-
 2
2
-
Ok, we need to make some stuff clear first.
@stev067 you just replaced the switch connecting your Unraid server with the VLAN enabled switch, (POE not important here)so I assume your network looks like
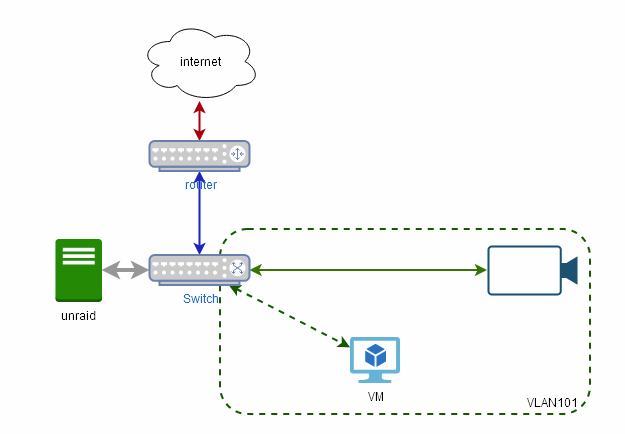
And I think your config looks good - save for using VLAN 102 as the general purpose (stick to VLAN1 unless your router and stuff need this level of control)
so your goal is to limit access between the cameras and blue iris PC vs unraid and and the rest of the network.Judging from your setup, you already cannot reach the cameras and the VM from the rest of the network.
and if the BR0.101 interface does not have an IP address, Unraid will also be unable to reach the VM.
You seem to want to access the VM also from the rest of the network and the easiest way (not the securest) is to simply add another NIC to the VM and connect it to BR0
Alternatively if you have a router with VLAN support is simply to put the camera in their own VLAN, then program the router to deny access from the cameras to your network, and allow the VM to connect to the cameras
-
1
-
-
Hmm that's seems to be the correct behavior.
Is your proftpd container network-linked to the mariadb?
ie did you create a custom docker network and then connect the proftpd and mariadb to that?
on the default bog standard bridge network its not going to work
otherwise it should work like this.
root@MediaStore:~# docker network create bridge2 89bbdd77e82561fb7223055c3f6c1bdf6092e66241c10f4c0172cb2b6cc9bcec root@MediaStore:~# docker run -d --network bridge2 --name box1 --rm alpine:latest sleep 3600 6fb56d0ef4ab42060930b1a01108467f5e26b61e52d212d16ff7e6158a1afee0 root@MediaStore:~# docker run -d --network bridge2 --name box2 --rm alpine:latest sleep 3600 28f4f19fd5e1c48832340b5639dd8abbd979f1909a5877cc367590fc54eae1be root@MediaStore:~# docker exec box1 nslookup box2 Server: 127.0.0.11 Address: 127.0.0.11:53 Non-authoritative answer: *** Can't find box2: No answer Non-authoritative answer: Name: box2 Address: 172.19.0.3 root@MediaStore:~# docker exec box2 nslookup box1 Server: 127.0.0.11 Address: 127.0.0.11:53 Non-authoritative answer: *** Can't find box1: No answer Non-authoritative answer: Name: box1 Address: 172.19.0.2How this maps in the GUI is beyond me.
-
127.0.0.11 is the embedded docker dns resolver for containers. It can only be accessed within containers and is mainly for resolving linked containers
what container are you using that's giving you issues and how?
-
A. when a disk goes bad, the parity protection of the array - like RAID 5 (or 6 if you have two parity discs) - allow the array to continue functioning in degraded mode. If you have hotswap, to replace the disk(s) you will need to stop the array, which will disable anything using it including the docker engine and VM engine. After replacing the disk(s), the array can be started in the same degraded mode, and Unraid will rebuild the replacement disk or recompute parity - depending on which disk(s) gone bad. Your total downtime is just the time to stop the array, replace disc, and start it up again.
2nd A.
Storage in Unraid is basically in three tiers: Array (usually parity protected and support shares that span the array), Cache (these are independent pools of drives if using btrfs, for either caching writes to the array or keeping data on faster disks) and Unassigned (this requires a plugin to simplify, but are storage not in previous tiers and mounted in whereever you want)
There is unfortunately only one Array per server, so most users backup to either unassigned disks that they periodically mount, backup, unmount or they target another remote server and use whatever backup tool (ie rsync, google drive, backblaze b2, etc)
and as I mentioned, docker containers and VMs are tied to array running, so stopping the array stops everything, but with hotswap bays you can be up and running in a few minutes it takes to stop the array and replace the drives.
-
The array needs to go offline to replace disks.
While the array is offline, this will also shutdown all VM's and docker containers.
Hotswap is your friend at this point as it will let you replaced failed drives without needing to mess with actual connections. Which many users in the past have managed to disconnect additional drives while the case is open.
Hotswap will not require a shutdown, but just about everything else built in, will be stopped. and resumed only once the array is back online.
Once the array is offline, any drive of the array can be replaced (including a parity drive), with Unraid prompting to start a rebuild of the drive based on the state of the array, once the array has been restarted.
-
I'd like to add my 2bits here that the issue seems to be present when doing parity checks, so it might not be a problem of the Diskspeed docker, but of the mpt3sas driver interacting with the LSI SAS2 controllers.
When I don't spin up my disks, my parity check gets capped to about 77MB/s ave vs the usual 140MB/s
I'm still looking into making tweaks to work around this as I don't see anything anywhere about this spinup issue.











ssh host keys self update
in General Support
Posted
Could also be some file corruption on your USB stick, where the SSH host keys became 0-byte files or were deleted
not copying from /boot during boot is usually an indicator of possible issues with the USB though