
ken-ji
-
Posts
1245 -
Joined
-
Last visited
-
Days Won
4
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by ken-ji
-
-
40 minutes ago, sgraaf said:
Perhaps a bit... superfluous, but hereby the same script, but then in bash:
#!/bin/bash thresh=70; used=$(df --output=used /mnt/cache/ | awk '{print $1}' | tail -n 1); avail=$(df --output=avail /mnt/cache/ | awk '{print $1}' | tail -n 1); percent=$((100 * used / avail)); if (( $percent > $thresh )); then sh /usr/local/sbin/mover; fiWould also be helpful to note that ( used / avail ) is not quite what you want as while used increases, avail decreases. You want used / size
#!/bin/bash thresh=70 stats=( $( df --output=used,size /mnt/cache | tail -n 1) ) percent=$[ 100 * ${stats[0]} / ${stats[1]} ] [ $percent > $thresh ] && sh /usr/local/sbin/mover -
Seems like this little change in /etc/profile by @limetech is giving some of scripts grief
# limetech - modified for unRAID 'no users' environment export HOME=/root cd $HOMEIts causing my scripted tmux sessions to all open (uselessly) in /root rather than in the directories I've specified.
Can we not do this?
-
3 minutes ago, AgentXXL said:
I've reported the same earlier in the thread regarding the disk usage thresholds and incorrectly making them green. Upon 1st boot after upgrading, there were notifications from every array drive stating that the drives had returned to normal utilization. There's a note in the release notes about this stating that users not using the unRAID defaults will have to reconfigure them, but as you, I and others have found, resetting the disk usage thresholds in Disk Settings hasn't corrected the issue.
I and others are also seeing the IPV6 messages, but they seem pretty innocuous so not a big concern at this time. We'll get these small issues solved eventually.
I was fairly sure they were getting reported properly on my first boot post upgrade, but I don't have any evidence for that.
the IPv6 is harmless, but I worry people might break their servers network connectivity (until they reboot) if they try to delete the mishandled routing lines. I didn't try since I'm doing all of this remotely without an IPMI /KVM device
-
Anybody understand why the dashboard doesn't seem to be able to show the correct orange and red disk usage bars anymore?
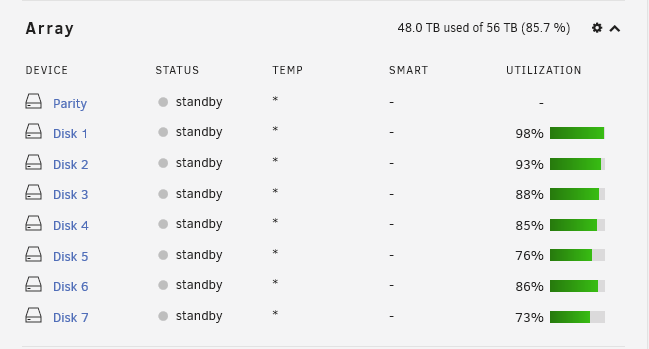
I've tried resetting the disk free thresholds, but no luck.
Also IPv6 routing has new entries the GUI is not parsing properly
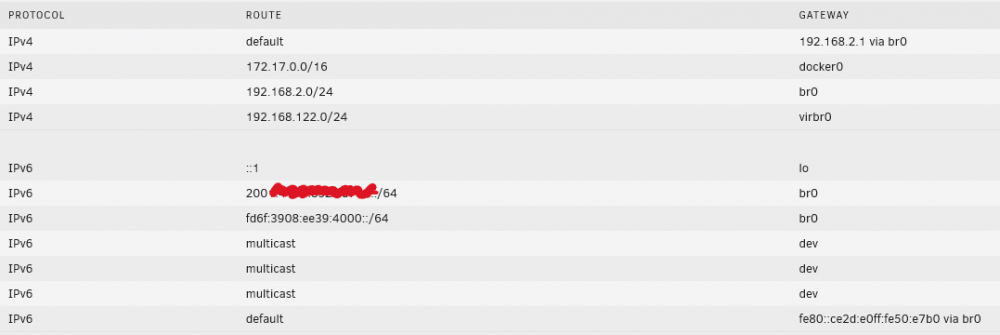
root@MediaStore:/usr/local/emhttp# ip -6 route ::1 dev lo proto kernel metric 256 pref medium 2001:xxxx:xxxx:xxxx::/64 dev br0 proto ra metric 216 pref medium fd6f:3908:ee39:4000::/64 dev br0 proto ra metric 216 pref medium fe80::/64 dev br0 proto kernel metric 256 pref medium fe80::/64 dev eth0 proto kernel metric 256 pref medium fe80::/64 dev vnet0 proto kernel metric 256 pref medium multicast ff00::/8 dev br0 proto kernel metric 256 pref medium multicast ff00::/8 dev eth0 proto kernel metric 256 pref medium multicast ff00::/8 dev vnet0 proto kernel metric 256 pref medium default via fe80::ce2d:e0ff:fe50:e7b0 dev br0 proto ra metric 216 pref medium-
 1
1
-
-
Upgraded from 6.8.3 - > 6.9.0 with only one weird issue.
* I tried to create a new pool out of my Unassigned Devices SSD (serving as VMs and appdata storage)
This returned "filesystem is unmountable" due to "partition alignment" (I think the message was)
So I made a backup of all the data, and proceeded to format the SSD (via the Main / Array Operation / Format button)
Then it mounted the SSD, but nothing seems to have been changed. even the partition table seemed untouched.
-
Odd. I've never seen any transcoding files - I'm transcoding to RAM vi a mounted directory under /tmp - unless I look while someones actively playing something. So I've never this issue.
-
or you have a properly defined plugin being installed after this one.

-
I took a lot at the Parity Check Tuning Plugin and it was packaged with the nobody:users for all the files including /

Slackware packages are simple tar files applied to root and the ownership and permissions of the folders will override the system one.
I think If you rebooted now, you'd find yourself unable to ssh in
@itimpi You should fix this by packaging as root with the correct permissions
-
 1
1
-
-
You are going to have to check each and every single plugin you have installed. Some of the plugins have incorrectly packaged files that muckup the ownership of the / directory.
A quickfix if it hits you is to use the Web-based Shell tool to login as root, then poke around with the permissions of the / directory
-
I did some tests and filed a bug report. But seems like no one has responded so far.
-
1
-
-
Looks like a bug with the shfs used by Unraid.
-
Sadly I don't have any.
Probably should document it for my own peace of mind.-
1
-
-
You can probably check your router to see which port does these mac address appear. Also have you tried shutting down everything (VMs, containers) on your Unraid to see if the issue occurs? It seems like you'll need to really check your network to see where the craziness is coming from.
-
On 1/8/2021 at 5:16 AM, Cosine said:
Pinging the unRAID box from various machines tries to ping the correct IP, or a wrong IP, or an IP on unRAIDs 172 network, or sometimes an IP6 address and each box changes what it's trying to talk to.
This sounds like you have a docker container running in bridge mode and its somehow announcing itself on the LAN with the incorrect internal IP
But I don't remember seeing anything like that in your diagnostics file
-
so I took a look at the ipmi plugin and plugin package it installs is badly built.

Granted when the package is installed and doesn't have a derekmacias user or group, they will fallback to the numeric value which happens to be 1000 hence admin:1000 for @elkaboing.
This will break SSH access and maybe a few other such things. The plugin author @dmacias probably doesn't use ssh (and neither do the other IPMI users, hence they haven't seen this issue)
-
On 1/8/2021 at 5:16 AM, Cosine said:
zeppo-diagnostics-20210107-1310.zip 107.53 kB · 1 download
Thanks very much, attached.
Pinging the unRAID box from various machines tries to ping the correct IP, or a wrong IP, or an IP on unRAIDs 172 network, or sometimes an IP6 address and each box changes what it's trying to talk to. I changed unRAID to use a static IP and that seems to have made no difference.
How are you pinging? vi hostname?
-
On 1/5/2021 at 5:14 AM, elkaboing said:
I do see /etc is owned by the admin:1000 account I have set up while the rest of the root folders are owned by root:root. Within /etc, the only directory owned by admin:1000 is rc.d.
In my experience, this means you probably have a plugin that installed files owned by the user id 1000 (this is assigned to the first user created in any Unraid/Linux system) and group id 1000
So when you have a chance to reboot, try so to make sure its not an accidental chown.
And if it did comeback, you'll have to inspect each of your plugins to determine if any is incorrectly built.
-
You actually want to be using private keys and the builtin background capability of SSH
I'll assume you known how to generate private+public key pairs else see this for a primer
When you are sure the keys are working correctly (generate them without passphrase encryption) and can ssh to the other server without being prompted for anything, Try the ssh command below (which will be exact command you stick into your script or go file)
#!/bin/bash ssh -f -i path/to/ssh/private.key -R 8000:xxx.xxx.xxx.xxx:8000 [email protected] -
10 hours ago, learningunraid said:
Hmm, Is there any way I could use Public AWS Server to create a tunnel between my unraid server so that, I access my unraid server using the AWS IP?
Here's what I did in my own system (also behind CGNAT). Spun up a Mikrotik CHR (virtual router) on Linode (but any other VPS with completely unblocked ports is also fine). Made a site-to-site VPN between my home networks (3 different houses) and the VPS. then port forwarded port 80 + 443 to an nginx container (kinda like SWAG - but I prefer to roll my own). This could be done with a Linux VPS, but I wanted to play with a Mikrotik router (all of my edge routers are Mikrotiks) and have less issues with the rather performant IPSec site-to-site vpn
This means I can access my Emby server + Transmission container over HTTPS from anywhere. (Added DNS entries at the house with the Unraid server to avoid having to go out and back)
-
1
-
-
I have rclone plugin installed and run this using the User Scripts plugin
#!/bin/bash #argumentDescription=Backup Location #argumentDefault=/mnt/disks/VMs/appdata/backupFlash BACKUPDIR=$1 [ -z ${BACKUPDIR} ] && BACKUPDIR=/mnt/disks/VMs/appdata/backupFlash mkdir -p ${BACKUPDIR} tar -C /boot -zvcf ${BACKUPDIR}/`hostname`-flash-`date +%Y%m%d%H%M%S`.tgz --exclude config/super.dat --exclude 'previous*' --exclude 'bz*' --exclude "System Volume Information" . #cleanup - leave upto 14days worth of backups find ${BACKUPDIR} -ctime +14 -delete if [ -x /usr/local/bin/rclone ]; then # rclone sync ${BACKUPDIR} Drive:backupFlash --verbose rclone sync ${BACKUPDIR} OneDrive:backupFlash --verbose rclone sync ${BACKUPDIR} Dropbox:backupFlash --verbose fiThe script will tar + compress the entire USB flash drive into a timestamped file - skipping config/super.dat (since my array drive order are absolute and easy to rebuild) and the bz* files and store in an unassigned drive location and finally upload to One Drive and Dropbox
-
2
-
-
Self-signed certs are the CA themselves... unless you are using self-CA signed ones?
and I think the browsers will now warn on self-signed certs - even if they were trusted?
-
Haven't done this myself - but is there any reason why importing the OVA into LibVirt/KVM/QEMU not working for you?
-
for #1, by default the Dropbox data is shared over SMB. the defaults assume you are using Unraid in the default public share mode
If this is not the case (you are using user accounts, set User and User ID to the appropriate user)

refer to this for more details
For #2. Just set the autostart button to on on the Dockers page

-
I'm afraid I have no idea what's going on here. and as you can see from your logs, it contains nothing useful. Only the Dropbox devs probably know what's going on and I don't think they are going to be helpful at all . This headless client is something they are still supporting but they seem to be veering people away from it as its not too easy to find on the site anymore.








Additional Scripts For User.Scripts Plugin
in Plugin Support
Posted · Edited by ken-ji
Easiest is to use a lockfile (or semaphore)
Near the start of the script
if [ -e /var/lock/script.lock ]; then echo "Still running" exit fi touch /var/lock/script.lockThen at the end of your script
rm -f /var/lock/script.lock