

Sean M.
-
Posts
67 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Sean M.
-
All set now! Thanks for the prompt replies and awesome plugin!
-
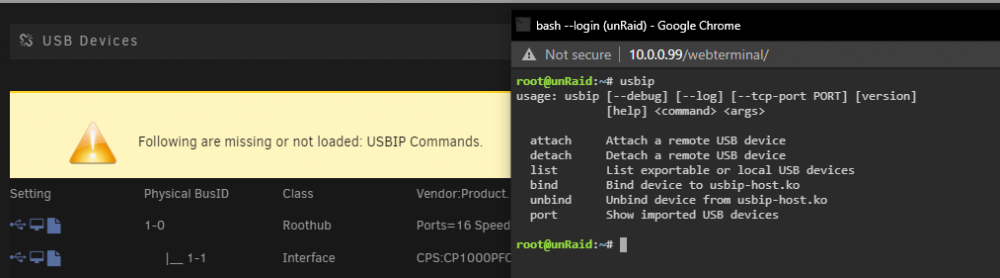
Results from command line: And yea if I disable USBIP in the plugin settings then no error and things look as expected
-
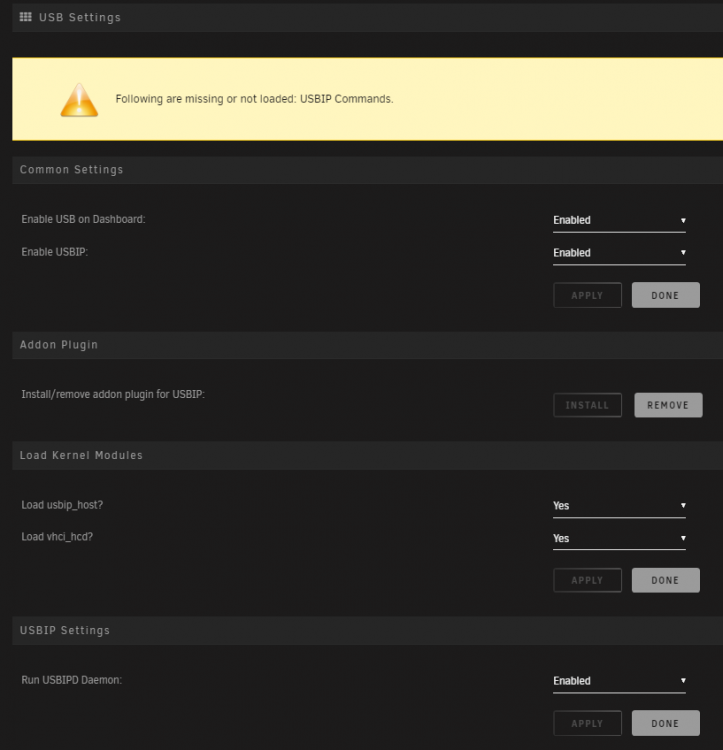
I am running 6.9.2 and not out of the gate planning to use USBIP but just wanted to make sure everything was setup correctly.
-
Looking to get this up and running but getting the following error message "Following are missing or not loaded: USBIP Commands." from the above replies it seems that the "usbip-1 package" is not being installed for whatever reason? I tried uninstalling both plug-ins, restarting unraid, etc however no luck. Any tips? I'm installing the latest "USB Manager (BETA)" from the App store and have not installed any versions of this plugin previously. I can see the libvirt.img was created under a system share. Here are my settings:
-
So figured I would give this a whirl, getting the error "No data in Elasticsearch index! After a crawl starts it can take up to 30 sec (refresh time) for index to be updated... Reload." I followed this guide from raqisasim. Installation right now looks like: Redis version = 6.0.9 Elasticsearch version = 5.6.16 Diskover version = v1.5.0.9 I saw from the latest Diskover Github readme that it mentions an Auth token; would that be the reason it's not crawling any data? Anyone tried to set this up recently with the latest versions have any tips? The UI loads fine and I don't see any errors or warnings in the log, they all appear to have started successfully.
-
I was reading through this thread: Overclocked.com in which they debate the same topic of FF being good vs an error, some users reported display errors they were having with FF so not sure if that's the case. I unfortunately do not have another monitor lying around with displayports or an adapter handy 😔 I was planning on relying on the iGPU alone for this build so my assumption would be that it was defaulting to per your description. I don't have a 'spare' PCIe GPU but I do have an old XFX Radeon HD 6950 in my desktop that I could pull out to test perhaps - seems like it is compatible. I triple checked the pins when I reseated everything this AM but truthfully I've never seen a bent pin in person so perhaps I just don't know what I'm looking for...
-
So I reseated everything once more, still ran into the same error when starting up 78 -> plug in mouse -> 64. However in frustration (or luck) I thought why not plug in my unraid flash and see what happens...well...the unraid server starts up and I'm able to get into the Unraid GUI by navigating through my network! Even with it started I am seeing "FF" as the error code on the bios display. I also cannot get anything from either of the display ports so I have no way to get into the BIOS...I don't think? The unraid GUI confirms the BIOS is at version F5 which is the latest but I still would like to get into the BIOS as I need to tweak the settings per my understanding to enable the iGPU passthrough for HW Transcoding. Any advice based upon my the latest troubleshooting?
-
Cleared both ways, result always ends up the same
-
Fair enough; I'll see if/when they get back to me and what they say. Perhaps they can use the serial # to identify the BIOS it shipped with at least. Thanks for taking the time to read through and reply!
-
Debating ordering a cheap supported 8th gen processor from Amazon (Intel Pentium Gold G5400) and then returning it after...not sure if that's a thing or if it will 100% solve the issue obviously.
-
Interesting! That's great ASRock would have customer service that helpful...I'm not sure if I'll get as lucky with Gigabyte but we'll see if they reply to my support ticket at all. This is the first motherboard I've ever had this much trouble finding the BIOS version on tbh, I read all through the manual and went over the board with my phone flashlight but could not find a BIOS callout just the board revision. 🤔
-
Thanks for reading about my issue! Yes, I tried 1 ram stick across the board A1, A2, B1, B2 with no luck unfortunately. Since I'm unable to get into the BIOS at all right now, I don't believe I have a way to update the BIOS. I don't have another CPU around that's compatible nor does this board have Q-Flash Plus (ability to flash bios with no boot screen).
-
Hello - I just completed a few upgrades on my unraid server and am now stuck in motherboard error purgatory...hoping someone smarter than I can offer some assistance as I'm at my wits end. Put CPU, MB, RAM together. Start it up. I first get an error 78, then I plug in a mouse to the usb slot and then it changes to an error 64. I have tried the following: Taking memory sticks out, have tried A1 only, A2, only, B1 only, B2 only, A1 & B1, A2 & B2 - always end up in the same place as described above Resetting CMOS using CMOS reset button as well as unplugging all power and removing battery than putting back in - end up in the same place as described above Reseating CPU and RAM - end up in the same place as described above Error Code 78 | ACPI Core initialization Error Code 63~67 | CPU DXE initialization started Source I have no hard drives or other devices plugged into the motherboard, it is only CPU, RAM and power supply. There is no separate GPU. I cannot get the BIOS version as I don't even get to the BIOS screen in the boot process and for whatever reason I cannot find it on the motherboard. Build: CPU: Intel Core i5-9600K 3.7 GHz 6-Core Processor ($199.99 @ Amazon) Motherboard: Gigabyte C246-WU4 ATX LGA1151 Motherboard ($261.99 @ Amazon) Memory: Corsair Vengeance LPX 32 GB (2 x 16 GB) DDR4-2666 CL16 Memory ($114.99 @ Amazon) Case: Fractal Design Define R5 Blackout Edition ATX Mid Tower Case Power Supply: SeaSonic G 550 W 80+ Gold Certified Semi-modular ATX Power Supply I've triple confirmed both the CPU and RAM are on the compatibility list for the MB. Greatly appreciate any advice or guidance. I have requested a call back from Gigabyte tech support as well as sent in a support request to their portal but I don't expect them to get back to me anytime soon... My guess is one of the 3 new components (CPU, RAM, MB) is defective, which ultimately is fine, I just want to quickly handle the return/replacement through Amazon to get this thing back up and running.
-
Thank you for the feedback and exactly the reason I posted! I'm fine with this memory $ range went back to the QVL and checked against the 3200 and PC part picker, this looks like a better option // Memory: Kingston HyperX Predator 64 GB (4 x 16 GB) DDR4-3200 CL16 Memory ($285.76 @ Amazon) Any other red flags or things that jump out? -- I guess one thing I hadn't thought through fully is if switching to AMD would be a + or - to my transcoding capabilities through plex which peaks around ~10 at any given time... Since I hadn't planned on an dedicated GPU, perhaps an intel quicksync build would be better to leverage hardware transcoding? Here's a quick view of that: CPU: Intel Core i7-9700K 3.6 GHz 8-Core Processor ($289.99 @ B&H) Motherboard: Asus PRIME Z390-A ATX LGA1151 Motherboard ($169.99 @ Amazon) Memory: G.Skill Trident Z RGB 32 GB (4 x 8 GB) DDR4-3200 CL16 Memory ($174.99 @ Amazon)
-
TL;DR: MB no longer working after 6+ years, manufacturer did not grant RMA, need to replace but debating pairing that with an upgrade which is outlined below - looking for any feedback/advice. Current: CPU: Intel Xeon E3-1240 V3 3.4 GHz Quad-Core Processor Motherboard: ASRock E3C226D2I Mini ITX LGA1150 Motherboard Memory: Crucial 16 GB (2 x 8 GB) DDR3-1600 CL11 Memory Upgrade: CPU: AMD Ryzen 7 3700X 3.6 GHz 8-Core Processor ($324.98 @ Newegg) Motherboard: MSI MAG B550 TOMAHAWK ATX AM4 Motherboard ($179.99 @ Newegg) Memory: G.Skill Ripjaws V 64 GB (4 x 16 GB) DDR4-3600 CL16 Memory ($299.99 @ Newegg) Static: Case: Fractal Design Define R5 Blackout Edition ATX Mid Tower Case Power Supply: SeaSonic G 550 W 80+ Gold Certified Semi-modular ATX Power Supply Custom: SAS9211-8I 8PORT Int 6GB Sata+sas Pcie 2.0 Storage: Cache/Apps | Crucial M500 120GB SSD Parity | Western Digital 12TB 5400RPM Data 1 | Toshiba X300 5TB 7200RPM Data 2 | Seagate ST6000DM003 6TB 5400RPM Data 3 | Seagate ST4000DM004 4TB 5400RPM Data 4 | Seagate ST3000DM008 3TB 7200RPM Data 5 | Seagate ST33000651AS 3TB 7200RPM Data 6 | Seagate ST33000651AS 3TB 7200RPM Dockers: Plex, Tutalli, Radarr, Sonarr, Bazarr, NZBGet, OpenVPN, Grafana, InfluxDB, Untelegraf VM: Windows 10 Long Story: Originally built first unraid machine back in 2014 in a Fractal Node case (upgraded to Define R5 in 2016) Turned off the machine for the first time in a while this past weekend; seems the MB no longer wants to work - reached out to ASRock tech support and went through all troubleshooting (CMOS reset, 1 memory stick test, VGA POST error failure, etc) and they said submit for an RMA which was ultimately denied so time for an upgrade In lieu of just replacing this very specific board or getting a very specific compliment that works with the current CPU & RAM figured might as well take the time to upgrade all 3 and future proof a bit more as I do hope to continue to tinker with the system in the future Looking for advice on if this may be overkill? Am I overlooking any other factors of compatibility conflicts? I don't believe I need a dedicated GPU (not doing gaming or video editing) but open to any and all suggestions! Thanks for reading! Edit: Perhaps worth noting average Plex transcode is 3-5 peaking at ~10, been reading lengthy discussions on AMD v. Intel on this and my head is spinning.
-
It's been a while since I had to set it up again or tweak it but I use a lot of SpaceInvaderOne's video guides. Here's his one on setting up OpenVPN
-
Updated Plugin, ran a pre-clear sucessfully, logs attached for reference. ############################################################################################################################ # # # unRAID Server Preclear of disk S246J9FB804046 # # Cycle 1 of 1, partition start on sector 64. # # # # # # Step 1 of 5 - Pre-read verification: [2:22:13 @ 117 MB/s] SUCCESS # # Step 2 of 5 - Zeroing the disk: [2:21:46 @ 117 MB/s] SUCCESS # # Step 3 of 5 - Writing unRAID's Preclear signature: SUCCESS # # Step 4 of 5 - Verifying unRAID's Preclear signature: SUCCESS # # Step 5 of 5 - Post-Read verification: [2:22:57 @ 116 MB/s] SUCCESS # # # # # # # # # # # # # # # ############################################################################################################################ # Cycle elapsed time: 7:07:04 | Total elapsed time: 7:07:06 # ############################################################################################################################ ############################################################################################################################ # # # S.M.A.R.T. Status default # # # # # # ATTRIBUTE INITIAL CYCLE 1 STATUS # # 5-Reallocated_Sector_Ct 0 0 - # # 9-Power_On_Hours 17347 17354 Up 7 # # 194-Temperature_Celsius 28 42 Up 14 # # 196-Reallocated_Event_Count 0 0 - # # 197-Current_Pending_Sector 0 0 - # # 198-Offline_Uncorrectable 0 0 - # # 199-UDMA_CRC_Error_Count 0 0 - # # # # # # # # # # # ############################################################################################################################ # SMART overall-health self-assessment test result: PASSED # ############################################################################################################################ --> ATTENTION: Please take a look into the SMART report above for drive health issues. --> RESULT: Preclear Finished Successfully!. TOWER-preclear.disk-20180507-0010.zip tower-diagnostics-20180507-0016.zip
-
Enabled smart, ran a short test, downloaded (attached). I saw gfjardim mentioned there was an issue with the plugin so I'll probably just wait and re-try once that's updated as I'm in no rush to move this drive over the array. Smart-20180429-1747.zip
-
Not 100% sure the disk is okay, part of the reason for the pre-clear. It came from an old desktop that had been decommissioned for a bit, last I remember it was working fine though. Full copy of diagnostics and pre-clear logs attached. The drive in question is: ST33000651AS_9XK0AKZH Preclear.disk-20180429-0756.zip Diagnostics-20180429-0756.zip
-
Were you using the pre-clear plugin? If so which version and which script and operation.
-
Right so since I'm just re-using my own drive, I skipped the erase. It aborted in the post-read verification Plugin Version: 018.04.24 Script: gfjardim - 0.9.5-beta Operation: Clear Preclear_Disk_Log: Apr 26 16:24:38 preclear_disk_9XK0AKZH_29218: Command: /usr/local/emhttp/plugins/preclear.disk/script/preclear_disk.sh --notify 4 --frequency 4 --cycles 1 --skip-preread --no-prompt /dev/sdb Apr 26 16:24:38 preclear_disk_9XK0AKZH_29218: Preclear Disk Version: 0.9.5-beta Apr 26 16:24:38 preclear_disk_9XK0AKZH_29218: S.M.A.R.T. info type: default Apr 26 16:24:39 preclear_disk_9XK0AKZH_29218: Zeroing: dd if=/dev/zero of=/dev/sdb bs=2097152 seek=2097152 count=3000590884864 conv=notrunc iflag=count_bytes,nocache oflag=seek_bytes 2>/tmp/.preclear/sdb/dd_output Apr 26 16:24:39 preclear_disk_9XK0AKZH_29218: Zeroing: dd pid [30378] Apr 26 17:39:55 preclear_disk_9XK0AKZH_29218: smartctl exec_time: 1s Apr 26 23:30:13 preclear_disk_9XK0AKZH_29218: smartctl exec_time: 8s Apr 26 23:56:51 preclear_disk_9XK0AKZH_29218: smartctl exec_time: 7s Apr 26 23:58:59 preclear_disk_9XK0AKZH_29218: Zeroing: dd - wrote 3000560017408 of 3000592982016. Apr 26 23:59:00 preclear_disk_9XK0AKZH_29218: Zeroing: dd exit code - 0 Apr 26 23:59:01 preclear_disk_9XK0AKZH_29218: Post-Read: verifying the beggining of the disk. Apr 26 23:59:01 preclear_disk_9XK0AKZH_29218: Post-Read: dd if=/dev/sdb bs=512 count=4095 skip=1 conv=notrunc iflag=direct 2>/tmp/.preclear/sdb/dd_output | cmp - /dev/zero &>/tmp/.preclear/sdb/cmp_out Apr 26 23:59:01 preclear_disk_9XK0AKZH_29218: Post-Read: dd pid [1437] Apr 26 23:59:01 preclear_disk_9XK0AKZH_29218: Post-Read: verifying the rest of the disk. Apr 26 23:59:01 preclear_disk_9XK0AKZH_29218: Post-Read: dd if=/dev/sdb bs=2097152 skip=2097152 count=3000590884864 conv=notrunc iflag=nocache,sync,count_bytes,skip_bytes 2>/tmp/.preclear/sdb/dd_output | cmp - /dev/zero &>/tmp/.preclear/sdb/cmp_out Apr 26 23:59:01 preclear_disk_9XK0AKZH_29218: Post-Read: dd pid [1459] Apr 27 07:08:15 preclear_disk_9XK0AKZH_29218: Post-Read: dd - read 3000523292672 of 3000592982016. Apr 27 07:08:15 preclear_disk_9XK0AKZH_29218: Post-Read: dd command failed, exit code [141]. Apr 27 07:08:15 preclear_disk_9XK0AKZH_29218: Post-Read: dd output -> 434+0 records in
-
Just recently re-installed the plugin. Plugin Version: 018.04.24 Script: gfjardim - 0.9.5-beta Operation: Erase and Clear the disk Should I just skip the erase part and clear it? In the past I've only used new drives and thus just cleared but this is being re-purposed from an old desktop.
-
Is this the right place to post the results and ask questions on the clear itself? I remember there used to be a thread for that before this plugin so wasn't sure. Was clearing an older drive using "erase and clear" option, got the following error which stopped the process. Apr 25 17:11:46 preclear_disk_9XK0AKZH_24453: Command: /usr/local/emhttp/plugins/preclear.disk/script/preclear_disk.sh --erase-clear --notify 4 --frequency 4 --cycles 1 --no-prompt /dev/sdb Apr 25 17:11:46 preclear_disk_9XK0AKZH_24453: Preclear Disk Version: 0.9.5-beta Apr 25 17:11:46 preclear_disk_9XK0AKZH_24453: S.M.A.R.T. info type: default Apr 25 17:11:47 preclear_disk_9XK0AKZH_24453: Pre-Read: dd if=/dev/sdb of=/dev/null bs=2097152 skip=2097152 count=3000590884864 conv=notrunc iflag=nocache,sync,count_bytes,skip_bytes Apr 25 17:11:47 preclear_disk_9XK0AKZH_24453: Pre-Read: dd pid [25616] Apr 25 18:34:22 preclear_disk_9XK0AKZH_24453: dd[25616]: pausing (sync command issued) Apr 25 18:34:54 preclear_disk_9XK0AKZH_24453: dd[25616]: resumed Apr 26 00:21:41 preclear_disk_9XK0AKZH_24453: Pre-Read: dd - read 3000592982016 of 3000592982016. Apr 26 00:21:41 preclear_disk_9XK0AKZH_24453: Pre-Read: dd exit code - 0 Apr 26 00:21:41 preclear_disk_9XK0AKZH_24453: Erasing: openssl enc -aes-256-ctr -pass pass:'oKM2mDN6kqiPry0mztZP3xtE9uQYyMy7pgsjCZEjsAVkcHSJZwPBXjXi9fn26Z7a03BkSRqAsebJYeIRyzKppVg+XEyWK+U/WNi+D0riDiF+Zq36MXHL2v3K2W1WiFUpAy7hNGXNq5aWQbClWKltpTCXXLHEMVHpndMRSCyKdTk=' -nosalt < /dev/zero 2>/dev/null | dd of=/dev/sdb bs=2097152 seek=2097152 count=3000590884864 conv=notrunc iflag=count_bytes,nocache oflag=seek_bytes iflag=fullblock 2>/tmp/.preclear/sdb/dd_output Apr 26 00:21:41 preclear_disk_9XK0AKZH_24453: Erasing: dd pid [13610] Apr 26 07:23:55 preclear_disk_9XK0AKZH_24453: smartctl exec_time: 7s Apr 26 07:30:11 preclear_disk_9XK0AKZH_24453: smartctl exec_time: 7s Apr 26 07:39:02 preclear_disk_9XK0AKZH_24453: smartctl exec_time: 1s Apr 26 07:39:09 preclear_disk_9XK0AKZH_24453: smartctl exec_time: 8s Apr 26 07:55:47 preclear_disk_9XK0AKZH_24453: dd process hung at 3000577818624, killing.... Apr 26 07:55:47 preclear_disk_9XK0AKZH_24453: Continuing disk write on byte 3000575721472 Apr 26 07:56:01 preclear_disk_9XK0AKZH_24453: /usr/local/emhttp/plugins/preclear.disk/script/preclear_disk.sh: line 446: 13609 Exit 1 openssl enc -aes-256-ctr -pass pass:'oKM2mDN6kqiPry0mztZP3xtE9uQYyMy7pgsjCZEjsAVkcHSJZwPBXjXi9fn26Z7a03BkSRqAsebJYeIRyzKppVg+XEyWK+U/WNi+D0riDiF+Zq36MXHL2v3K2W1WiFUpAy7hNGXNq5aWQbClWKltpTCXXLHEMVHpndMRSCyKdTk=' -nosalt < /dev/zero 2> /dev/null Apr 26 07:56:01 preclear_disk_9XK0AKZH_24453: 13610 Killed | dd of=/dev/sdb bs=2097152 seek=2097152 count=3000590884864 conv=notrunc iflag=count_bytes,nocache oflag=seek_bytes iflag=fullblock 2> /tmp/.preclear/sdb/dd_output Apr 26 07:56:01 preclear_disk_9XK0AKZH_24453: Erasing: openssl enc -aes-256-ctr -pass pass:'vhk+SaVdyeTevJEBVabhQeoj4g5qT1XuobgHBZJspcEN+iY84H6/Hl1ZBwJgrIaCCWziEn9HsE8iWI2/8dQzfWBbeY0Dsxl/KD6Yvslw/WxJOhXKnMZDAKT4oqH52+tX7WL3pQgtahw8YH8XhdYjYbNof45P5WTlroTf6LKP1g0=' -nosalt < /dev/zero 2>/dev/null | dd of=/dev/sdb bs=2097152 seek=3000575721472 count=17260544 conv=notrunc iflag=count_bytes,nocache oflag=seek_bytes iflag=fullblock 2>/tmp/.preclear/sdb/dd_output Apr 26 07:56:01 preclear_disk_9XK0AKZH_24453: Erasing: dd pid [16010] Apr 26 07:56:02 preclear_disk_9XK0AKZH_24453: Erasing: dd command failed -> 8+1 records in 8+1 records out 17260544 bytes (17 MB, 16 MiB) copied, 0.0164792 s, 1.0 GB/s
-
Was setting up NZBHydra this morning, configured the downloaders and indexers, restarted and am getting a "fatal error occurred" a little googling pointed me to that the port was already in use / another instance of hydra was already running but I don't see that being the case. Any tips? Thanks! 2018-04-08 12:32:59,218 - INFO - nzbhydra - Dummy-3 - Exit registered. Stopping and closing database 2018-04-08 12:32:59,219 - INFO - nzbhydra - Dummy-3 - Database shut down 2018-04-08 12:33:00,179 - NOTICE - nzbhydra - MainThread - Starting NZBHydra 0.2.233 2018-04-08 12:33:00,179 - NOTICE - nzbhydra - MainThread - Base path is /app/hydra 2018-04-08 12:33:00,179 - NOTICE - nzbhydra - MainThread - Loading settings from /config/hydra/settings.cfg 2018-04-08 12:33:00,184 - INFO - log - MainThread - Logging to file /config/hydra/nzbhydra.log as defined in the command line 2018-04-08 12:33:00,185 - INFO - log - MainThread - Setting umask of log file /config/hydra/nzbhydra.log to 0640 2018-04-08 12:33:00,185 - INFO - nzbhydra - MainThread - Started 2018-04-08 12:33:00,185 - INFO - nzbhydra - MainThread - Loading database file /config/hydra/nzbhydra.db 2018-04-08 12:33:00,189 - INFO - nzbhydra - MainThread - Starting db 2018-04-08 12:33:00,190 - INFO - indexers - MainThread - Activated indexer NZBCat 2018-04-08 12:33:00,192 - INFO - indexers - MainThread - Activated indexer nzb.su 2018-04-08 12:33:00,194 - INFO - indexers - MainThread - Activated indexer NZBGeek 2018-04-08 12:33:00,196 - INFO - indexers - MainThread - Activated indexer Drunken Slug 2018-04-08 12:33:00,197 - INFO - indexers - MainThread - Activated indexer NZB Finder 2018-04-08 12:33:00,198 - NOTICE - nzbhydra - MainThread - Starting web app on 192.168.1.154:5075 2018-04-08 12:33:00,199 - NOTICE - nzbhydra - MainThread - Go to http://192.168.1.154:5075 for the frontend 2018-04-08 12:33:00,199 - INFO - web - MainThread - Running threaded server 2018-04-08 12:33:00,202 - ERROR - nzbhydra - MainThread - Fatal error occurred Traceback (most recent call last): File "/app/hydra/nzbhydra.py", line 214, in run web.run(host, port, basepath) File "/app/hydra/nzbhydra/web.py", line 1730, in run app.run(host=host, port=port, debug=config.settings.main.debug, threaded=config.settings.main.runThreaded, use_reloader=config.settings.main.flaskReloader) File "/app/hydra/libs/flask/app.py", line 772, in run run_simple(host, port, self, **options) File "/app/hydra/libs/werkzeug/serving.py", line 625, in run_simple inner() File "/app/hydra/libs/werkzeug/serving.py", line 603, in inner passthrough_errors, ssl_context).serve_forever() File "/app/hydra/libs/werkzeug/serving.py", line 506, in make_server passthrough_errors, ssl_context) File "/app/hydra/libs/werkzeug/serving.py", line 440, in __init__ HTTPServer.__init__(self, (host, int(port)), handler) File "/app/hydra/libs/SocketServer.py", line 420, in __init__ self.server_bind() File "/app/hydra/libs/BaseHTTPServer.py", line 108, in server_bind SocketServer.TCPServer.server_bind(self) File "/app/hydra/libs/SocketServer.py", line 434, in server_bind self.socket.bind(self.server_address) File "/app/hydra/libs/socket.py", line 228, in meth return getattr(self._sock,name)(*args) error: [Errno 99] Address not available
-
unRAID OS version 6.4.0 Stable Release Available
Sean M. replied to limetech's topic in Announcements
Thanks, I used the unassigned devices to pull the data off as trurl mentioned above. Loaded it back mounted as cache and went to format through the UI, got the following error. Jan 14 14:01:57 Tower emhttpd: req (29): startState=STARTED&file=&cmdFormat=Format&unmountable_mask=1073741824&confirmFormat=OFF&optionCorrect=correct&csrf_token=**************** Jan 14 14:01:59 Tower emhttpd: shcmd (1127): /sbin/wipefs -a /dev/sdd1 Jan 14 14:01:59 Tower emhttpd: shcmd (1128): mkdir -p /mnt/cache Jan 14 14:01:59 Tower emhttpd: shcmd (1129): mount -t ext4 -o noatime,nodiratime /dev/sdd1 /mnt/cache Jan 14 14:01:59 Tower root: mount: /mnt/cache: wrong fs type, bad option, bad superblock on /dev/sdd1, missing codepage or helper program, or other error. Jan 14 14:01:59 Tower emhttpd: shcmd (1129): exit status: 32 Jan 14 14:01:59 Tower emhttpd: /mnt/cache mount error: No file system Jan 14 14:01:59 Tower emhttpd: shcmd (1130): umount /mnt/cache Jan 14 14:01:59 Tower kernel: EXT4-fs (sdd1): VFS: Can't find ext4 filesystem Jan 14 14:01:59 Tower root: umount: /mnt/cache: not mounted. Jan 14 14:01:59 Tower emhttpd: shcmd (1130): exit status: 32 Jan 14 14:01:59 Tower emhttpd: shcmd (1131): rmdir /mnt/cache Jan 14 14:01:59 Tower emhttpd: Starting services... Jan 14 14:01:59 Tower emhttpd: no mountpoint along path: /mnt/cache Should I just use the terminal instead of the UI or will it not make a difference? Thanks again!


