

Mailman74
-
Posts
182 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Mailman74
-
-
I had my server built and do not know much about the troubleshooting. I had 2 failed disks and 2 parity drives. I replaced both failed disks and then removed one of my parity drives and upgraded my my unraid to Version 6.7.3-rc4. I think my shares disappeared before upgrading the version though. Guy who built my server is gonna fix it for me but wanted me to post this to get some opinions. He has a idea of what to do but wants to see what others think.
I am attaching my syslog and diagnostics.
Thanks so much for helpin
tower-syslog-20191003-0018.zip tower-diagnostics-20191003-0017.zip
-
Time to replace I guess
-
I didnt know if there was a dedicated section to ask for help with reports. So I posted here a smart report of my drive that had 532 errors and is disabled by unraid.
-
I am sure there are people on here who can figure out what a site tracks. I am looking for help from someone with knowledge about tracking and internet security. If anyone is interested please PM me so I can discuss in more detail. Thanks
-
The webUI is way out of date. CA if its installed is miles out of date, but the error itself isn't from CA, as the errors are on the dashboardIf you're still on 6.1.8 then update and reboot then try again.
I am on 6.1.9
Dunno then, your signature said 6.1.8....
Post some diagnostics. Ensure all your plugins are up to date as well. Community Applications especially. Also you could try installing the "Fix Common Problems" plugin and see if that throws any light on the information.
-
If you're still on 6.1.8 then update and reboot then try again.
I am on 6.1.9
-
There's at least going to be an update for the webUI (plugins - check for updates) install it and then post back (also wouldn't hurt to update to 6.1.9)When I try to search for Docker updates I get an error saying Not Available. I am attaching screen shots to show it better, Thanks
I installed the webUI updates and went to docker and checked for updates. I still have the same error showing not available and the errors
-
When I try to search for Docker updates I get an error saying Not Available. I am attaching screen shots to show it better, Thanks
-
Looking for some help reading my pre clear results on 2 drives. I am still running preclear on 2 8 tb drives that I will post later. I am attaching the results here if I do not attach correct files let me know, thank you
-
The problem is either my Supermicro SAS card or the sata breakout cables. I removed them and installed 2 rocket raid 2300's and my parity is now running at 100mb/sec and will be finished in 12 more hours. Thanks for the help
-
Looks normal, I'm out of ideas.
Maybe someone else will see something in your logs, in the meantime re-start the parity sync, hopefully with the crc issues resolved it will complete or help find the problem in case of more errors.
I tried with your awesome help and patience. I will be near prostuff1 who built my server years ago and take it to him to see what he finds wrong. I was hoping to get it working with the help of the users here, thanks so much
-
Screen shot of diskspeed
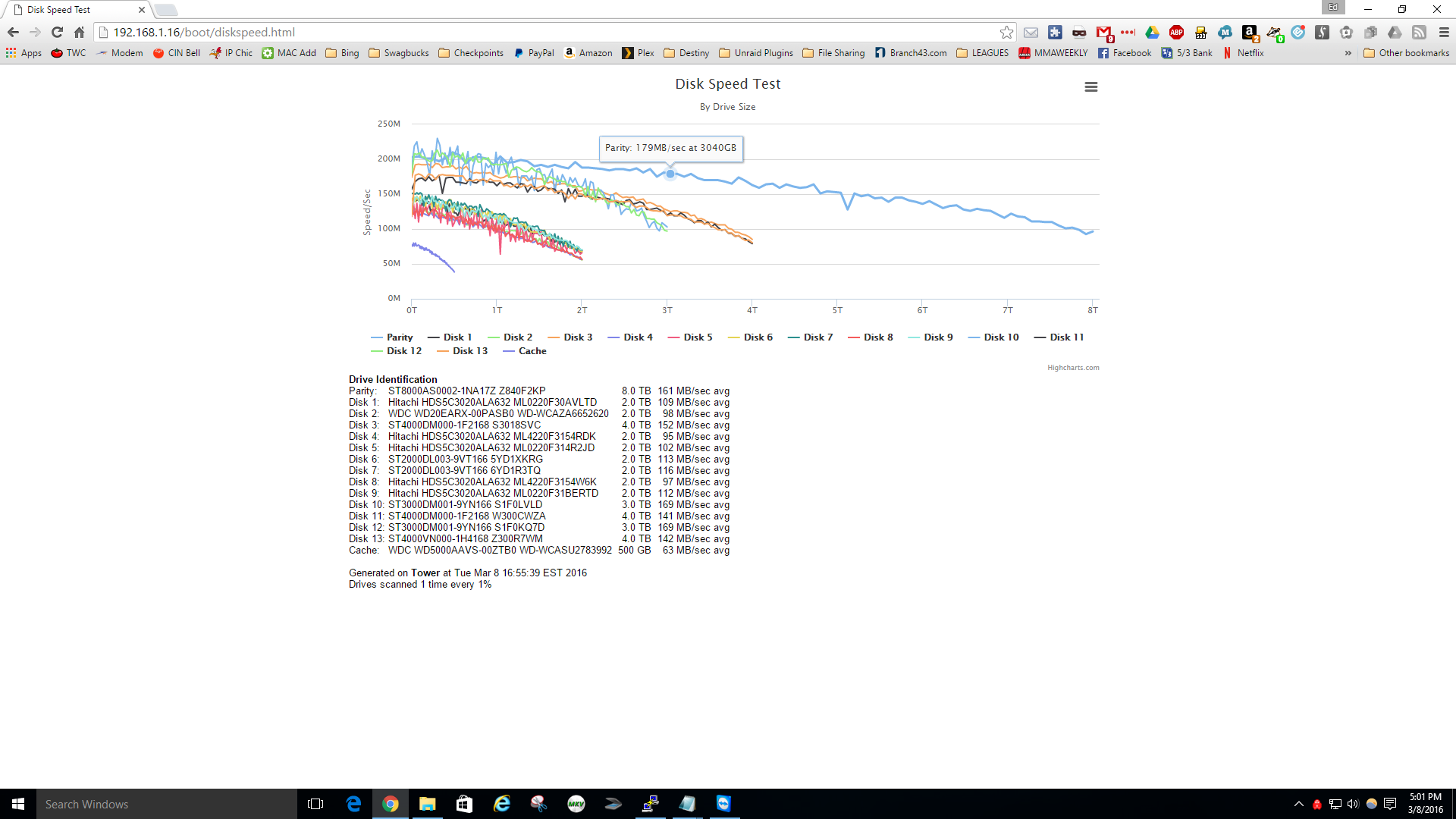
-
From syslog:
Mar 8 10:23:40 Tower kernel: ata8.00: exception Emask 0x10 SAct 0x0 SErr 0x280100 action 0x6 frozen Mar 8 10:23:40 Tower kernel: ata8.00: irq_stat 0x08000000, interface fatal error Mar 8 10:23:40 Tower kernel: ata8: SError: { UnrecovData 10B8B BadCRC } Mar 8 10:23:40 Tower kernel: ata8.00: failed command: READ DMA EXT Mar 8 10:23:40 Tower kernel: ata8.00: cmd 25/00:40:c8:af:45/00:05:00:00:00/e0 tag 15 dma 688128 in Mar 8 10:23:40 Tower kernel: res 50/00:00:47:00:00/00:00:41:00:00/e1 Emask 0x10 (ATA bus error) Mar 8 10:23:40 Tower kernel: ata8.00: status: { DRDY } Mar 8 10:23:40 Tower kernel: ata8: hard resetting link Mar 8 10:23:41 Tower kernel: ata8: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Mar 8 10:23:41 Tower kernel: ata8.00: configured for UDMA/133 Mar 8 10:23:41 Tower kernel: ata8: EH complete Mar 8 10:23:46 Tower kernel: ata8.00: exception Emask 0x10 SAct 0x0 SErr 0x280100 action 0x6 frozen Mar 8 10:23:46 Tower kernel: ata8.00: irq_stat 0x08000000, interface fatal error Mar 8 10:23:46 Tower kernel: ata8: SError: { UnrecovData 10B8B BadCRC } Mar 8 10:23:46 Tower kernel: ata8.00: failed command: READ DMA EXT Mar 8 10:23:46 Tower kernel: ata8.00: cmd 25/00:40:48:37:4a/00:05:00:00:00/e0 tag 11 dma 688128 in Mar 8 10:23:46 Tower kernel: res 50/00:00:47:00:90/00:00:42:00:00/e2 Emask 0x10 (ATA bus error) Mar 8 10:23:46 Tower kernel: ata8.00: status: { DRDY } Mar 8 10:23:46 Tower kernel: ata8: hard resetting link Mar 8 10:23:46 Tower kernel: ata8: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Mar 8 10:23:46 Tower kernel: ata8.00: configured for UDMA/133earlier smart report:
199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 600
smart from now:
199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 604
I removed the Norco that conataind the drives with the errors and replaced it with a new Norco that I had purchased for expansion. I also put the 8tb drive back in for the parity but I am still getting 3Mb/sec for parity sync. I am attaching a new diagnostic file
-
This disk is still getting UDMA_CRC errors, if you already replaced this cable it may be an enclosure issue, or less likely the SATA port or controller.
Device Model: Hitachi HDS5C3020ALA632 Serial Number: ML0220F30AVLTD
Is that the only one you see getting the error. What file do you see the error in I tried looking
-
Look at the date/time and attach the most recent.
Sorry, open with notepad and check time:
Mar 8 04:40:01 Tower emhttp: shcmd (1307): rmmod md-mod |& loggerMar 8 04:40:01 Tower kernel: md: unRAID driver removed
Mar 8 04:40:01 Tower emhttp: shcmd (1308): modprobe md-mod super=/boot/config/super.dat slots=24 |& logger
Mar 8 04:40:01 Tower kernel: md: unRAID driver 2.5.3 installed
Sorry for being such a noob. We only use our server for storage, plex and nsb grabbing. Havent gotten new shows in 3 weeks because of this, thanks for dealing with my lack of knowledge about this. I deleted a few folders to reduce size
-
Look at the date/time and attach the most recent.

-
You're still getting UDMA_CRC errors, better to cancel the sync and attach full diagnostics.
My diagnostic it too large to attach. Inside the logs folder there are 2 syslog files on syslog(133kb) and the other syslog.1(128kb). Should I delete one to make attachment smaller?
-
Well parity sync speed are back to 3MB/sec anfd I attached an updated syslog to see if anything stands out, Thanks
-
If you haven’t written/deleted anything from the array since you last used this parity disk you can try this:
-take a screenshot of current disk assignments
-go to tools and click new config
-reassign all disks including old parity
-before starting array check “parity is already valid”, then start array
-check if disk9 mounts
This won’t solve your main problem, the UDMA_CRC errors are almost certainly the reason for the very slow parity sync and disable disk, and you have to fix those before attempting another sync, this is just to see if disk9 filesystem is actually ok.
Sweet now drive 9 is mounted. It is attempting another parity sync now with speeds around 30MB/sec, should I let it sync for a little?
-
Disk9 is not only unmountable, but also disabled, can you explain all the steps you made when changing back to old parity?
I just swapped the paritys around and replaced some sata cables. The new drive that I was wanting to use for parity never got past 1% synced. So I figured to just put the old parity back in server. I booted up and now disk 9 is doing this.
-
You are getting CRC errors from at least these three disks, change sata cable/enclosure.
Device Model: ST8000AS0002-1NA17Z Also would be a good idea to to an extended SMART test for this one, and if it fails replace it: [code]Device Model: Hitachi HDS5C3020ALA632 Serial Number: ML0220F31BERTD 197 Current_Pending_Sector 0x0022 100 100 000 Old_age Always - 1
Ok I have moved around some sata cables and installed some new ones. I went and purchased a new psu also the Corsair CS750M. My parity syncs were still super slow and I ran an extended smart test on this drive and it passed and also ran a smart test on disk 10 that also passed. Problem is now that drive 9 ML0220F31BERTD is showing unmountable. I installed my original parity drive back into the server until I know what to do with this unmountable drive. I am attaching a new diagnostics report but I had to delete a syslog file because the attachment was too large. Thanks again
-
You are getting CRC errors from at least these three disks, change sata cable/enclosure.
Device Model: ST8000AS0002-1NA17Z Serial Number: Z840EWNX 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 32 Device Model: Hitachi HDS5C3020ALA632 Serial Number: ML0220F30AVLTD 199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 586 Device Model: Hitachi HDS5C3020ALA632 Serial Number: ML4220F3154RDK 199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 520
All 3 of those disks are inside the same Norco SS-500 and I believe it is the oldest Norco I have.
-
Go to tools and click diagnostics, attach the complete zip.
Thanks so much, my speeds are back to 3mb/sec. I am attaching the diagnostics zip file. I apologize for being such a technie noob and greatly appreciate the help everyone offers here.
-
I had installed a rocket raid 2300 for the new norco ss500. I removed that from the system and now I am getting 30mb/sec. I checked all the wires and not loose connections. When I install the rocket raid do I need to do something in the bios? I am getting 20-30mb/sec but to be very honest I know replies say to post diagnostics but I do not know what that means.


Drive mounted read-only or completely full
in General Support
Posted
The fix common problems app shows 2 drives that are unable to be written to. I only use my server for media and do not mess with it too much as it usually runs fine. I am attaching the diagnostics here to see if anyone can help. Thanks so much
tower-diagnostics-20220807-2113.zip