

Seige
-
Posts
58 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Seige
-
-
The LuaJIT error seems to be gone since the last push?! Thanks for taking care of that, if it is not just on my end 👍
-
 1
1
-
-
Would it be possible to run multiple instances of the letsencrypt container? All instances would have to have the same port mapping (i presume). Would this be possible by defining custom docker networks for each instance of letsencrypt and would http validation still work?
Thank you for the help!
-
I have the same issue, always comes back with "0 B pulled" on all of my containers. I think amazonaws have some issues, tracert does time out in my case, also.
-
8 hours ago, Ephoxia said:
I can't get port forwarding to work. Ports are set correctly in pfSense but i can't connect externally.
I noticed something in the logs: "Unable to open /config/licensekey.dat, falling back to limited functionality"
Can that have anything to do with it? Everything else I've port-forwarded in pfSense work without any issue.
These ports are required for running TS:
9987 (UDP)
10011 (TCP)
30033 (TCP) (for file transfers)
Did you specify the internal ports and protocols correctly? In what network type mode are you running the container? You might want to try it in "host".
The error message "Unable to open /config/licensekey.dat, falling back to limited functionality" is shown, because you have not purchased a full server licese and are operating a server which can only host up to 32 clients (i.e. limited functionality).
Also you might want to consider removing the "enable reporting to server list" option in the server settings, or you server will be listed in their public server list.
If you are still having issues you can also test the official TS docker. There is a short guide I wrote, just in case.
-
10 hours ago, slimshizn said:
Lets encrypt didn't give new certs, so something's up.
This is a very brief description of your problem. What is the exact error in the log?
If it used to work and now is suddenly broken, it might be because of an issue of your port 80 routing (at least in my experience this is very often the culprit). Do you know how to access the docker command line and run a cert renewal test? This usually gives you a more detailed error message.
-
2 hours ago, Marv said:
Hi,
thanks for this guide. I'm trying to set this up but unfortunately I'm too stupid to find the container via the Community Applications Plugin. ?
Any help please?
As @Squid mentioned, if you search for teamspeak, you can click a link to extend the search to dockerhub. I added a screenshot to my post.
-
Preface:
Unfortunately, the LSIO container based on LGSM has been deprecated (blog post). Since my friends and I use TS when gaming, I moved my old server to the official docker linked in the post . It is fairly straight forward, but I wanted to write a brief guide in case others would find it useful.
Please note that I am not associated with Teamspeak in any capacity and would consider myself a linux noob.

Guide:
Stop the LSIO Teamspeak container.
Use the Community Applications Plugin to install the official Teamspeak docker from the docker hub. Search for "teamspeak" and the click this button:

I copied the settings from the LSIO container:
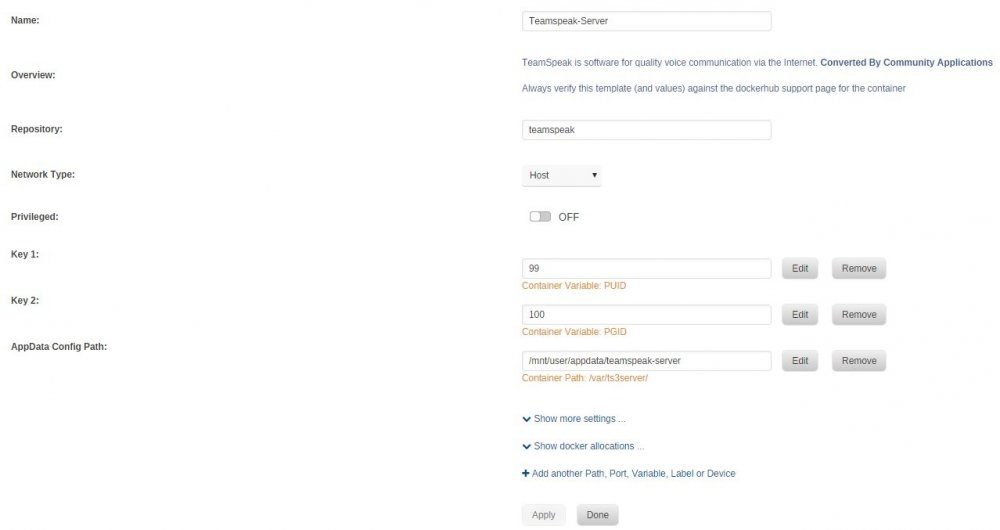
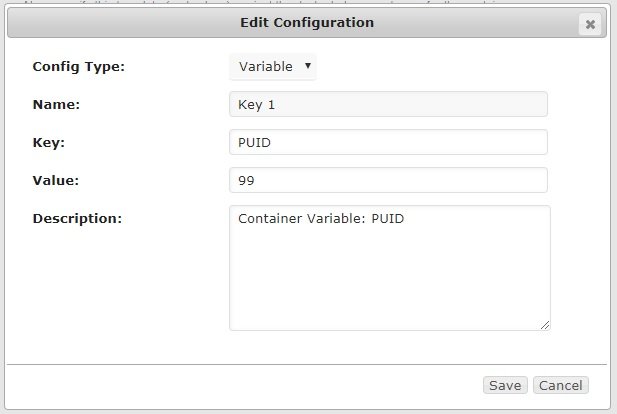
You have to create two variables (I called them Key 1 and Key 2) defining PUID and PGID to set the correct ownership and permissions:
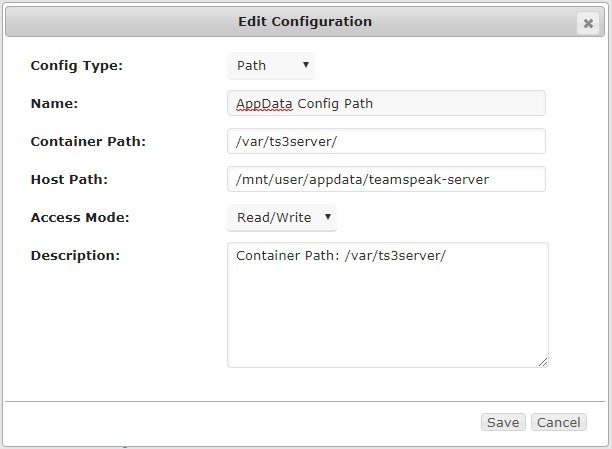
The config folder for this container is located in "/var/ts3server/", so map this path to your appdata folder accordingly:
If you switch to "Advanced View" with the switch in the top right corner you can add this link for the icon: https://i.imgur.com/bzkHhkb.png

Then apply your settings. The log will show an error, that the license agreement has not been accepted. Create a blank text file, name it ".ts3server_license_accepted" and copy it to the appdata folder. Now, the container should be able to start. Connect with the Teamspeak client and claim admin with the token stored in the log file (in /appdata/teamspeak-server/logs/).
Congratulations, you are now set up and can enjoy the Teamspeak server.
Optional:
If you want to migrate your old server, shut down the container and copy over the following files and folder from /appdata/oldserver/serverfiles/
"libts3_ssh.so"
"libts3db_mariadb.so"
"libts3db_sqlite3.so"
"ts3server.sqlitedb"
"/files/"
Start the container and your old settings should be restored. After this, you can shut it down and deleted the files except "/files" and "ts3server.sqlitedb".
That's it. Please let me know if you have any questions or suggenstions.
Cheers
EDIT: Added link for docker icon
-
 1
1
-
-
4 hours ago, jbartlett said:
I've also found and fixed (in beta 5) the index out of range issue mentioned above.
It is working again, thank you!
-
For a while now, I also get the array index out of range error, when trying to run a benchmark. It does not spin up any drives. Scanning works fine. Here is a screenshor of the error:
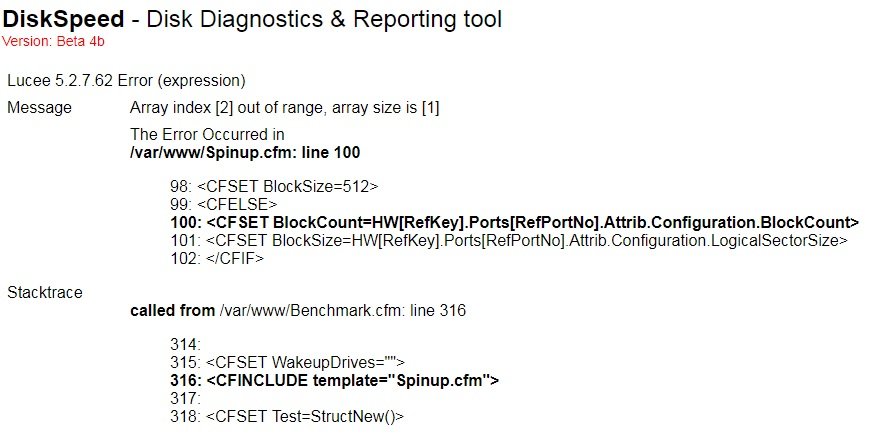
I tried to reboot the server and pulled a fresh image with a new appdata folder. No changes. Do you have any idea what might cause this?
Thank you!
-
Google says about 100 MB/s, so you should be right:
according to this https://www.tomshardware.com/reviews/wd-red-10tb-8tb-nas-hdd,5277-2.html
-
The 3/4 TB WD reds are rather slow in comparison. Their 10 TB model is a bit faster, and since the read/write speed is not linear it is hard to predict an exact value.
When going from a 4TB WD red parity to a 10 TB Ironwolf my parity check times went from 10 hrs to 19 with another 10tb data drive in the array. Once it is done with the 4 TB section involving the WD reds it picks up speed since the Seagates are notably faster. With only Ironwolfs or similar drives I guess it would be around 12 ish hours.
-
1 minute ago, Zonediver said:
Hi folks,
i want to ask, if someone can tell me, how long a Parity-Check with a 10TB HDD takes.
Thanks for your help
If you have a setup with a single parity and a somewhat decent cpu it is pretty much limited by the slowest drive in your array. I would estimate something between 12-20 hours.
-
2 minutes ago, Ockingshay said:
It would be really great to get scrolling in pop-up windows, so that on tablets I know when the process completes. I only ever see the first few lines and if I scroll, it scrolls the page behind the pop-up. ?
At at the moment I just wait 5 mins and click the Red Cross, hoping it’s finished in time. this is is on an iPad Pro 12.9, but I’m sure it happens on other tablets. It also happens on my iPhone.
+1 for that, not sure if we should put that in the feature request section?
Other than that, no issues with the update so far!
")
-
1
-
-
I am pretty sure this was because of your split level. You only allow to split at the top level and your disks are very full. Why not set split level to auto and see if that helps?
-
Quick questions, and maybe not related, but are your disks still in a hardware raid configuration?
What does the server do after this period? Webui is becoming unresponsive? Is it locking up?
I am not a syslog guru, but things that look weird:
Jun 6 01:58:41 DaneviServer kernel: DMAR-IR: This system BIOS has enabled interrupt remapping
Jun 6 01:58:41 DaneviServer kernel: on a chipset that contains an erratum making that
Jun 6 01:58:41 DaneviServer kernel: feature unstable. To maintain system stability
Jun 6 01:58:41 DaneviServer kernel: interrupt remapping is being disabled. Please
Jun 6 01:58:41 DaneviServer kernel: contact your BIOS vendor for an updateMaybe this is causing issues with your VMs. And this one:
Jun 6 01:58:41 DaneviServer kernel: ACPI BIOS Warning (bug): 32/64X length mismatch in FADT/Gpe0Block: 128/64 (20170728/tbfadt-603)
I'm afraid someone with more experience has to look at your diagnostics files.
-
How is you M1015 installed? These controller gets very warm, even under idle. With rising ambient temperatures this could also be the culprit. I would highly recommend installing the Noctua NF-A4x10 FLX on top of the heat sink. If you are up for it replace the thermal compound with something better. Mine was dried up and flaky. I used a small cable tie to hold the fan in place, but others are using screws (image is not from a M1015, but results are pretty much the same) :

I leave it running at full speed, it is rather quiet and the heat sink is cool to the touch, even under load.
Try the cables first, as suggested by @johnnie.black, but maybe also consider installing the fan.
-
I did some more tests today and I can confirm that it is caused by the smb folder that is mounted at the startup of the array. The can be replicated if the folder is not mounted immediately because the remote drive has to wake first. If the drive is already spinning, no error is thrown. Nonetheless the folder is mounted correctly in both cases so it is not a big deal.
Cheers,
Seige
-
Thank you @pwm for your additional explanation! I was not familiar with this, but it looks like that this is exactly what happened. I was able to replicate the issue depending on the way I use copy/paste from inside of windows.
-
After some additional testing it seems that this error is in fact caused by the network mount, if the remote drive is sleeping and has to wake up. The mounting is still completed, but the error is still created. Will do some additional testing and report back.
-
10 minutes ago, johnnie.black said:
There should be no problem with that.
Maybe putty does not like copy pasting from the web browser. I carefully ran it through Notepad++ and double checked all characters and seems to work for balance and stats. But command
btrfs fi df /mnt/cache
still produces the error. Also tried the build in web terminal, same results. I feel rather inapt

EDIT: It seems to work, when I type it manually. Not sure where this is coming from, never had any issues with copy paste before.
-
Thanks for the quick response!
I have copy pasted both commands from some of your posts. At the moment both commands work, but e.g.
btrfs fi df /mnt/cache
Does lead to the same "ERROR: cannot access '/mnt/cache': No such file or directory"
Could it be that these commands cannot be executed one after another?
-
Hi,
I recently installed a second SSD and created a btrfs cache pool. After a while I noticed performance degradation and came across several suggestions by @johnnie.black. After running:
btrfs balance start --full-balance /mnt/cache
and
fstrim -v /mnt/cache
performance was back to normal. Hence, I wanted to add a weekly script with:
btrfs balance start -dusage=75 /mnt/cache
This leads to the following error message: "ERROR: cannot access '/mnt/cache': No such file or directory" while the original command still works.
Running " btrfs device stats /mnt/cache" only worked once, usually I get "ERROR: cannot check /mnt/cache: No such file or directory" and "ERROR: '/mnt/cache' is not a mounted btrfs device".
Not sure what is going on here. Any help is much appreciated.
My diagnostics file:
EDIT: link removed
Thanks!
Seige
-
Hi,
I realised that I reveice the following error message when the server is starting up (it it not always being logged in the syslog file, but it always appears in the log window of the webui):
Jun 7 18:01:21 Tower emhttpd: error: send_file, 139: Broken pipe (32): sendfile: /usr/local/emhttp/logging.htm
Not sure what is causing this, I cannot detect any unusual behaviour. Here is my diagnostics file:
EDIT: link removed
Thank you for the help!
Cheers,
Seige
EDIT: Maybe this is caused by the mounted smb folder upon array startup?
-
This is really sad to hear. Despite being OS agnostic, I do not think MS could provide any benefit in this space.








{kind=link}
[Support] Linuxserver.io - SWAG - Secure Web Application Gateway (Nginx/PHP/Certbot/Fail2ban)
in Docker Containers
Posted
I do see those lines in the log as well. Not sure if it has anything to do with geoip2 or not