

jcreynoldsii
-
Posts
100 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by jcreynoldsii
-
-
-
I'll buy. Dm sent.
-
For the last 3 nights I have experienced hard crashes. From the syslog there isn't any valuable information that I can gather just prior to crashing. Any insight/help is much appreciated.
Attached are the diagnostics and syslog
homeserver-diagnostics-20200927-0853.zip syslog-192.168.1.2.log
-
9 hours ago, trurl said:
Do you have other browsers or tabs open to your server on any computer or mobile device?
Not that I could tell, issue has resolved itself for now. Thanks.
-
unraid os: 6.8.3
Apps: 2020.07.13
My community apps section is no longer loading, get this message instead:
Something really wrong went on during get_content
Post the ENTIRE contents of this message in the Community Applications Support Thread
No data was returned. It is probable that another browser session has rebooted your server. Reloading this browser tab will probably fix this errorWhat can I do to determine cause?
Jay
-
So been stabled for ~10 days now with only running a few of the most critical dockers and only running the mover on sundays rather than each day. Next test was enable a few more dockers and take the mover back to daily. I'll run like this for a 4-5 days to make sure all is stable. From there proceed to enabling more dockers.
-
Last check completed on Tue 26 May 2020 03:33:54 PM CDT (today), finding 0 errors.That's good news.
-
Running a non-correcting parity check as we speak. I'll check cabling after parity check completes tomorrow.
-
No crashes over night, I did however changed the mover schedule so that it would not run. I did this simply because I wanted the parity check to finish as it had already found and corrected errors. Presumably because it hard crashed yesterday during the parity check from the previous hard crash.
Date Duration Speed Status Errors 2020-05-25, 08:25:18 21 hr, 39 min, 34 sec 102.6 MB/s OK 129I ran only the bare minimum of dockers last night, PiHole, Unifi-Controller and Plex. I will slowly introduce dockers over the next few days to see if these crashes are docker related. In the event that doesn't work I think I may change frequency of mover back to every night.
Also I have a drive reporting the following, it seems to be going in and out of good/bad, any insight on this?
199 UDMA CRC error count 0x000a 200 200 000 Old age Always Never 1It does however pass the overall smart health check. Attached is the smart report.
-
Used User Scripts and made the following script:
#!/bin/bash mkdir /tmp/PlexRam mount -t tmpfs -o size=4g tmpfs /tmp/PlexRamUpdated the docker command and the transcode setting in Plex
-
No I don't use Plex DVR and I don't have anything mapped for trans-coding. Should I make a directory on a share drive for it? Or should I transcode to RAM?
I'd have to give it a shot on shutting down docker, I planned on doing that tonight before turning in for the night. I don't want to run with it off during day as I use PiHole for DNS and without a secondary PiHole running it pretty much will shutdown the internet in the house.
The reason I initially suspected Plex to be my culprit is because I would experience a lot of hard crashes while casting Plex to the chromecasts in the house. As of lately that hasn't been the case. The last two nights have had hard crashes for no apparent reason.
-
I have a total of 22 containers installed, and out of those 22 I run 18 full time. Attached is a list of those containers along with their run commands.
-
My docker is image size is set to 50GB, I am using about 23GB of that. At one point in the past I ran out of docker image size so I increased it.
All of my dockers reside on the cache/appdata directory and I believe that all of my mapped directories reside on shares.
Plex docker configuration:
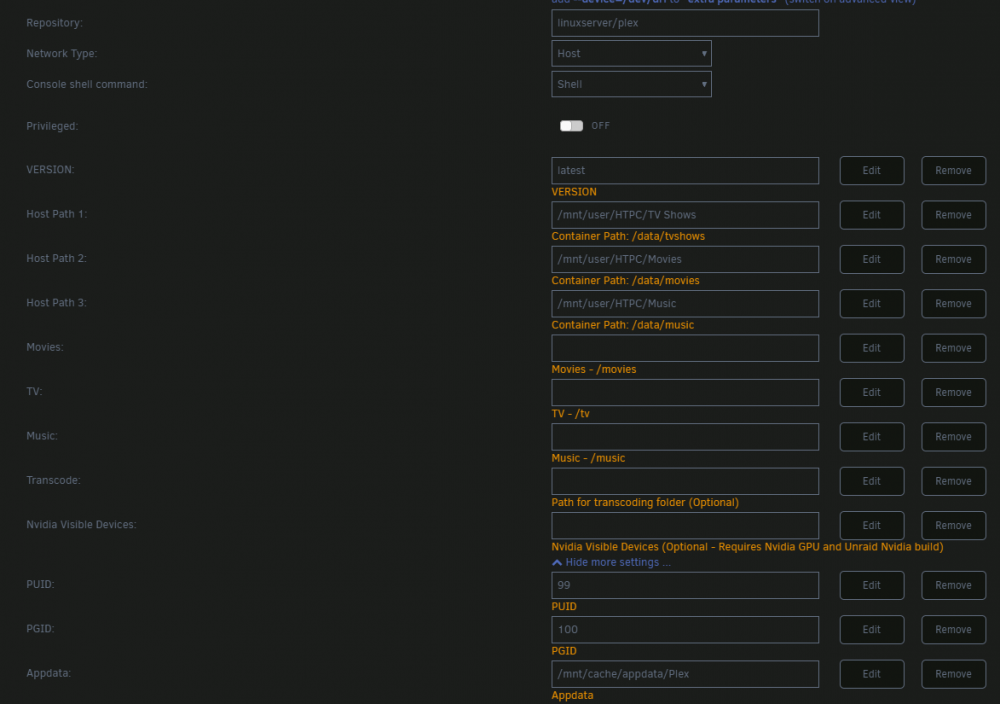
All of my dockers reside on the cache/appdata directory.
I am wondering if the mover app isn't what got me, considering the last two days I woke up to a hard crashed system.
-
Yet another one this morning. Last message before rebooting it this morning was:
May 24 02:30:07 HomeServer crond[1722]: exit status 1 from user root /usr/local/sbin/mover &> /dev/nullEdit: Mover is setup to go off at 2:30 am, however Mover logging was not enabled, I have since enabled it. I shutdown all non-essential dockers this morning so this system can finish a parity check, it has crashed two days in a row while performing the parity check due to the unclean hard reboots for the day prior.
syslog-192.168.1.2.log homeserver-diagnostics-20200524-1048.zip
-
Woke up to another hard crash this morning. Had to do a unclean reboot at 8:38 AM.
syslog-192.168.1.2.log homeserver-diagnostics-20200523-0840.zip
-
3 hours ago, trurl said:
Also that /boot/unmenu/uu line should be removed.
This look better?
#!/bin/bash # Start the Management Utility /usr/local/sbin/emhttp & # resize log partition mount -o remount,size=384m /var/logHow can I troubleshoot the crashes? The log has nothing tangible in there. I would like to be able to gracefully shutdown unraid, however the console keyboard doesnt work, web gui and web interfaces gone, the quick press of the power button doesn't work and neither does pulling UPS from mains power. It seems like unraid gets hung 100%.
-
Checked my log and there are several peculiar entries from dockers:
May 21 19:36:21 HomeServer kernel: docker0: port 9(vethfafdac9) entered blocking state May 21 19:36:21 HomeServer kernel: docker0: port 9(vethfafdac9) entered forwarding state May 21 19:36:21 HomeServer kernel: docker0: port 9(vethfafdac9) entered disabled state May 21 19:36:21 HomeServer kernel: eth0: renamed from veth7d7cd71 May 21 19:36:21 HomeServer kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethfafdac9: link becomes ready May 21 19:36:21 HomeServer kernel: docker0: port 9(vethfafdac9) entered blocking state May 21 19:36:21 HomeServer kernel: docker0: port 9(vethfafdac9) entered forwarding state May 21 19:38:07 HomeServer kernel: vethafb7e9d: renamed from eth0 May 21 19:38:07 HomeServer kernel: docker0: port 10(veth037a102) entered disabled state May 21 19:38:07 HomeServer kernel: docker0: port 10(veth037a102) entered disabled state May 21 19:38:07 HomeServer kernel: device veth037a102 left promiscuous mode May 21 19:38:07 HomeServer kernel: docker0: port 10(veth037a102) entered disabled state May 21 19:38:09 HomeServer kernel: docker0: port 10(vethbe1888a) entered blocking state May 21 19:38:09 HomeServer kernel: docker0: port 10(vethbe1888a) entered disabled state May 21 19:38:09 HomeServer kernel: device vethbe1888a entered promiscuous mode May 21 19:38:09 HomeServer kernel: IPv6: ADDRCONF(NETDEV_UP): vethbe1888a: link is not ready May 21 19:38:09 HomeServer kernel: docker0: port 10(vethbe1888a) entered blocking state May 21 19:38:09 HomeServer kernel: docker0: port 10(vethbe1888a) entered forwarding state May 21 19:38:09 HomeServer kernel: docker0: port 10(vethbe1888a) entered disabled state May 21 19:38:10 HomeServer kernel: eth0: renamed from veth0d0dee2 May 21 19:38:10 HomeServer kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethbe1888a: link becomes ready May 21 19:38:10 HomeServer kernel: docker0: port 10(vethbe1888a) entered blocking state May 21 19:38:10 HomeServer kernel: docker0: port 10(vethbe1888a) entered forwarding state May 21 19:38:20 HomeServer kernel: vethadbaa22: renamed from eth0 May 21 19:38:20 HomeServer kernel: docker0: port 11(vethd09af7a) entered disabled state May 21 19:38:20 HomeServer kernel: docker0: port 11(vethd09af7a) entered disabled state May 21 19:38:20 HomeServer kernel: device vethd09af7a left promiscuous mode May 21 19:38:20 HomeServer kernel: docker0: port 11(vethd09af7a) entered disabled state May 21 19:38:22 HomeServer kernel: docker0: port 11(veth0dcbe21) entered blocking state May 21 19:38:22 HomeServer kernel: docker0: port 11(veth0dcbe21) entered disabled state May 21 19:38:22 HomeServer kernel: device veth0dcbe21 entered promiscuous mode May 21 19:38:22 HomeServer kernel: IPv6: ADDRCONF(NETDEV_UP): veth0dcbe21: link is not ready May 21 19:38:22 HomeServer kernel: eth0: renamed from veth9b5b4d4 May 21 19:38:22 HomeServer kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth0dcbe21: link becomes ready May 21 19:38:22 HomeServer kernel: docker0: port 11(veth0dcbe21) entered blocking state May 21 19:38:22 HomeServer kernel: docker0: port 11(veth0dcbe21) entered forwarding stateHow do I correlate the port to a specific docker?
-
So should delete that line out of there?
-
As far as my docker file, i am currently using ~23gig.
23 minutes ago, itimpi said:You might want to check your ‘go’ file in case there are any other references to incompatible/obsolete features?
also do you have an ‘extras’ folder on the flash drive. If so that should probably be removed as it may be installing incompatible packages. In v6 any extra packages are normally installed via the Nerdpack or DevPack plugins.
I dont have an extras folder on the flash drive. I just got the nerdpack tonight and I have yet to install anything from it.
Content of Go File:
#!/bin/bash # Start the Management Utility /usr/local/sbin/emhttp & /boot/unmenu/uu # resize log partition mount -o remount,size=384m /var/log cd /boot/packages && find . -name '*.auto_install' -type f -print | sort | xargs -n1 sh -cThose packages are inside of the /boot/packages dir.
-
Good question, nothing i ever did. I used v5 before v6, perhaps stuff that didnt cleaned up?
-
2 hours ago, trurl said:
Why have you allocated 50G to docker image? Have you had problems filling it? 20G should be more than enough and when I see someone with a docker image larger I suspect they have something misconfigured with their dockers.
I use quite a few dockers and in the past I hit the default max docker image file size, so when I needed to increase it I set it so that I would have to keep doing it over and over again.
-
I experienced a couple more and each time the log doesn't show anything. Attached is the one from today. Came home to a non responsive server. I got to find a solution or at least a way to shutdown gracefully, the quick press of the power button does not work. I thought I'd be slick and pull the power on my UPS to initiate a controlled shutdown (didn't work). My system is hooked up to a TV via hdmi after a period of time the screen is black and will not wake up, which is weird why wouldn't the console stay up? This is annoying as hell. Any help is greatly appreciated.
I found these 4 lines interesting on the reboot of the server:
/var/tmp/go: line 4: /boot/unmenu/uu: Permission denied sh: ./apcupsd-3.14.10-x86_64-1_rlw.txz.auto_install: Permission denied sh: ./powerdown-2.06-noarch-unRAID.tgz.auto_install: Permission denied sh: ./screen-4.0.3-x86_64-4.txz.auto_install: Permission deniedEach of these items directly relates to a few problems I spoke of above.
Jay
-
I have been experiencing server hard crashes for quite a while now. I have gone through with various suggestions, increase ram, ramtests, writing log files to share etc. Nothing had really helped pinpoint the cause of the issue. I was originally thinking it was Plex transcoding related, not entirely sure if that is the problem now or not. I had another hard crash over the weekend. Attached is the log. Any help is appreciated.
The server was unreachable at around the 2PM time frame on the 24th. Last entry was: Apr 24 14:00:13 HomeServer kernel: mdcmd (97): spindown 5
Thanks in advance,
Edit: added diagnostic dump.
Jay
-
Cool'n'Quiet was set to always disabled inside of BIOS. Tips and Tweaks now shows:
CPU Frequency Scaling
Driver: ACPI CPU Freq
Governor: On Demand
Fix Common Problems doesn't throw the warning any longer.
Thanks for the suggestions.
[FS] [US-MO-KC] Over a dozen SSD's and 8TB HDD's. High Endurance Intel Enterprise SSD's, perfect for cache pools with write intensive tasks.
in Buy, Sell, Trade
Posted
Dm'd
Sent from my Pixel 6 Pro using Tapatalk