allanp81
-
Posts
333 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by allanp81
-
I've got an N2 as well, great bit of kit and plays everything I've tried on it including near 100Gb UHD remuxes.
-
Large copy/write on btrfs cache pool locking up server temporarily
allanp81 replied to aptalca's topic in General Support
Sorry I'm only running beta on my backup server currently which has no cache drives. -
Large copy/write on btrfs cache pool locking up server temporarily
allanp81 replied to aptalca's topic in General Support
It's so annoying, I had to re-architect my server to get around this problem (and obviously there was expense involved),. -
No I realise that, just wasn't sure if anyone was experiencing the same "issue". It seems to be a DNS issue, I'm getting different IPs returned when I look up my domain name depending on what computer I'm using.
-
This seems to have stopped working for me this morning for no obvious reason. I've scanned all of the error logs and there's no errors logged that are any different to those that sporadically appear from time to time anyway. I'm perplexed.
-
[Support] Linuxserver.io - Nextcloud
allanp81 replied to linuxserver.io's topic in Docker Containers
*EDIT* I think I answered my own question, seems to be a let's encrypt issue. My nextcloud instance seems to have stopped working this morning for no obvious reason. The nginx log is showing the following that it wasn't showing before: 2020/06/30 09:31:14 [error] 370#370: *355 directory index of "/config/www/" is forbidden, client: 192.168.7.28, server: _, request: "GET / HTTP/1.1", host: "192.168.7.11:8443" 2020/06/30 09:31:14 [error] 370#370: *355 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.7.28, server: _, request: "GET / HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "192.168.7.11:8443" 2020/06/30 09:31:14 [error] 370#370: *355 open() "/config/www/favicon.ico" failed (2: No such file or directory), client: 192.168.7.28, server: _, request: "GET /favicon.ico HTTP/1.1", host: "192.168.7.11:8443" 2020/06/30 09:31:14 [error] 370#370: *355 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.7.28, server: _, request: "GET /favicon.ico HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "192.168.7.11:8443" Anyone got any ideas as to why this has suddenly happened? The docker hasn't updated for a while I think but the let's encrypt docker last night did update. -
[Support] Linuxserver.io - Kodi-Headless
allanp81 replied to linuxserver.io's topic in Docker Containers
I've been using kodi with sql backend for years, using different versions of kodi for front end (coreelec, libreelec, kodi for windows, kodi headless docker) and never had any issues, just works. -
Large copy/write on btrfs cache pool locking up server temporarily
allanp81 replied to aptalca's topic in General Support
What changed in Unraid itself though? -
[Solved] PERC H310 causing system not to boot
allanp81 replied to master.h's topic in Storage Devices and Controllers
Just thought I'd chime in and say this worked for me on an old H67 board that refused to POST with any SAS cards in. I was able to get this to boot with 2 H310 SAS cards installed -
So the only change I've made recently is to install an NVME drive on the m.2 slot. As support for this was added later in a BIOS update I'm starting to suspect I have issues with this drive as I'm also suddenly seeing random AER PCI-E errors as well.
-
Hi all, all of a sudden my server doesn't want to restart anymore. If I do a clean restart my server will post and then just sit on a black screen with a blinking cursor. BIOS is set to only boot this USB stick on legacy boot. I've just replaced the USB stick with a brand new one this morning and same issue. If I press the restart button on the server it will ALWAYS then successfully boot. My board is an Asrock X99 Extreme 4. downloadbox-diagnostics-20200403-1221.zip
-
Just wondering why people seem to get these errors all of a sudden. The errors do say Corrected though.
-
I've suddenly started getting these errors on my x99 chipset motherboard. Server is working fine as far as I can tell though. Mine is complaining about device [8086:6f02] which refers to "00:01.0 PCI bridge: Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D PCI Express Root Port 1 (rev 01)". Assuming that this refers to PCI-E slot 1 which had a graphics card I've tried moving it to a different slow but error is still appearing, albeit nowhere near as a frequently. I'm wondering if a docker update could somehow introduce this error as nothing has changed hardware wise.
-
Large copy/write on btrfs cache pool locking up server temporarily
allanp81 replied to aptalca's topic in General Support
I was seeing this with a pool of 2 512Gb SSDs. I have since switched to a single Intel NVME drive and the problem has gone. -
I had this issue before and it turned out to be memory related, even though the memory would always pass a memory test successfully.
-
This again sounds like a similar issue that I am seeing with cache enabled shares. If you create a share that has no cache enabled on it, do you see the same issue?
-
CPU maxing out when copying to array (cache)
allanp81 replied to sdamaged's topic in General Support
I logged the exact same issue. Copying to a non-cache enabled shared doesn't have the same issue. No-one seemed to have an answer as to why. -
I would've thought cache pool (or ssd shared via unassigned drives) was your only real option here as the drives are always available unlike normal array drives that will probably spin down.
-
@RedReddington Is this when copying to array with cache drives or straight to disks?
-
Copying large files makes server unresponsive
allanp81 replied to allanp81's topic in General Support
I have a mix of disks, could that be the problem? One is a Samsung SSD 850 PRO and the other is a SanDisk SD8SB8U512G1001. Running Trim didn't help either, I'll have to look into maybe replacing the drives then. I don't have anything spare though so if replacing doesn't fix I've wasted £100 or so. -
Copying large files makes server unresponsive
allanp81 replied to allanp81's topic in General Support
Unless I'm being stupid, surely they can handle more than 50Mb/sec and not fluctuate so much and also not cripple the server at the same time? -
Copying large files makes server unresponsive
allanp81 replied to allanp81's topic in General Support
@johnnie.black So by switching from "Auto" to "reconstruct write" seems to solve the issue when copying directly to the array, doesn't fix the issue with cache though obviously. This also seems to solve the issue of slow/intermittent speeds when backing up to my other server. Is there a potentially that my cache drives have issues even though nothing is reported as being wrong? I have 2 drives that aren't the same make but are the same size. -
Copying large files makes server unresponsive
allanp81 replied to allanp81's topic in General Support
I can understand that if copying to a share without cache enabled, I'd expect to see 40-50Mb/sec, but would it not be consistent rather than fluctuate so much? Also, when writing direct to cache I see exactly the same symptoms but it's worse in that it seems to basically cripple my server until sometime after the copy finishes! I don't recall seeing these issues prior to 6.8.x. I also see similar when backing up to my other server which is also now running 6.8.x and running on entirely different hardware with no cache drives specified. -
Copying large files makes server unresponsive
allanp81 replied to allanp81's topic in General Support
Interestingly as well, copying from the same client machine to my win10 VM on my server copies at ~110meg consistently until the copy finishes. The VM lives on a btrfs pool created outside of the array and mounted using the unassigned devices plugin so I know that there is no issue with the network cabling etc. Copying from the VM then to array then exhibits the same issue with the slowing down and then inconsistent speed fluctuations. -
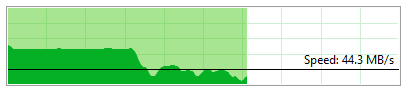
Copying large files makes server unresponsive
allanp81 replied to allanp81's topic in General Support
Here is a visual example of what happens: As you can see, it starts of maxed out and then just proceeds to drop and then go all over the place.