

joshstrange
-
Posts
59 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by joshstrange
-
-
Sorry I missed this reply, unfortunately it doesn't solve my problem. It may make it so I can login with my keys (I already have that working) but it does nothing to prevent passwords when logging in. As in I can still `ssh root@MYIP` and get a password prompt that takes my password and logs me in. I want to completely prevent that. Make SSH key-ONLY. It's very odd to me that I've edited the `/etc/ssh/sshd_config` file and told it to not allow PasswordAuthentication and yet SSH still works without a key.
-
I know I had this working on <6.9 but I built a new UnRaid box recently, installed 6.10, and I think it broke.
In my /boot/config/go file I have:
mkdir -p /root/.ssh cp /boot/custom/ssh/* /root/.ssh chmod 700 /root/.ssh chmod 600 /root/.ssh/* echo "PubkeyAuthentication yes" >> /etc/ssh/sshd_config echo "PasswordAuthentication no" >> /etc/ssh/sshd_config /etc/rc.d/rc.sshd restartWhich should take my authorized keys file in /boot/custom/ssh/, move it to the right place, set the correct permissions, disable password login, and restart the ssh daemon. It does correctly allow me to login with a key but I can also still login with my password which I do not want. In past versions of UnRaid I know this configuration worked so I'm confused as to what I'm doing wrong this time around.
I also tried uncommenting the:
PermitRootLogin prohibit-passwordLine and restarting ssh but it didn't help.
Any assistance would be greatly appreciated. Thank you!
-
Sorry, I should have added a diagnostic from the start. I only have one from 6.6.7, I stupidly forgot to do one on 6.9.2 before I downgraded. If needed I can attempt another upgrade since I now have a clean up/downgrade path
-
After one my SATA cables died to one of my cache drives (something that UnRaid did not alert me to or alter the UI, it showed a gray ball next to the drive and reported no errors despite /var/log/syslog screaming about superblock issues) I decided to upgrade UnRaid finally. I upgraded to the newest version and while I could connect to it from my local network I was unable to access the internet from the UnRaid box (it could still see/ping everything on the local network). My DNS servers were set to 8.8.8.8/8.8.4.4.
It appears that in the upgrade my default route was set to go through br1 (on 6.6.7 it is showing br0) and I think that was my issue but I wasn't clear on how to change that safely and how to revert back to br1 if my guess that it should be br0 was wrong. After a failed attempt to update the DNS and having to pull the USB drive off the motherboard to manually edit the network config I wasn't in a mood to attempt any new network-related fixes so I downgraded. Apart from the panic when it didn't show my cache drives and pretended like they were new drives I was able to get back up and running on 6.6.7.
My questions is: Why did UnRaid change my default route to br1 in the upgrade and if this is the root of my problem, like I think it is, how do I safely switch from br1 to br0?
I have included a screenshot of 6.6.7 (working) config. I sadly didn't screenshot the 6.9.2 config but I can confirm it said it was going through br1 for the default traffic and on the command line when I listed the routes (`ip route` is what I think I ran) it showed the br1 as "linkdown".

-
Wow, I could kiss you all. I was 100% ready to write off this data (and that still may need to happen) but after replacing the sata cable disk 5 is showing up and I can see data on it. I'm starting another rebuild so wish me luck. THANK YOU, THANK YOU, THANK YOU. I've had sata cables go bad before but I was sure this was 100% my fault (still a true statement) and I had 2 drives on their last leg (again still could be the case but at least now I have some hope). Thank you again and I hope in a day or so I'll have it all rebuilt!
-
Ok, I ended up just holding down the power button to kill it. Here are the diagnostics. When I opened up the machine drive 5 (the second failing drive) looked like the sata power cable was ajar but I can't be sure if that was from me removing the sata data cable. After boot the drive isn't showing up at all now so I'm shutting it back down to replace the sata data cable but I grabbed diagnostics first.
-
Ok I tried:
root@Tower:~# poweroff -fAnd got no output/response and the machine is still up (pingable/sshable) a few minutes later. Am I not waiting long enough or is it hung?
I can see that 2 instances of "shutdown -h 0 w", 1 instance of "poweroff -f", and 1 instance of "/usr/local/sbin/emhttpd" are all stuck in uninterruptible sleep mode "D" using htop.
-
Tried that but after 8 minutes it doesn't appear to be shutting down. Normally I would tail the syslog to figure out what the issue was but it's not updating due to it not having any space...
root@Tower:~# poweroff Broadcast message from root@Tower (pts/1) (Wed Apr 1 11:52:26 2020): The system is going down for system halt NOW!
-
Hmm, ok I can't stop the rebuild. When I click to cancel and then confirm it makes a request to /update.htm with the following form data:
startState:STARTED file: csrf_token: A202<REMOVED>1BDA43 cmdNoCheck: Cancel
but it just hangs ("pending") and never completes. What is the safest way for me to take down this machine or is pulling the power my only option?
EDIT: It times out (504) after a while
-
On it! Thank you guys. I really appreciate the responses while I'm in panic mode, it helps a lot!
-
Crap, I just looked and /var/log is full so idk if that's what is causing the issue (my /var/log is 2GB in size for reference)
-
Well I was going to attach them but it's been working on it for 20min now, I'm going to leave the page open but should I expect it to ever finish?
Also here is an update on the rebuild process
QuoteTotal size: 8 TB
Elapsed time: 20 hours, 21 minutes
Current position: 2.20 TB (27.5 %)
Estimated speed: 398.3 KB/sec
Estimated finish: 168 days, 13 hours, 21 minutes
-
Let me start of by saying no, I did not do regular parity checks, no I didn't take good inventory of my data to know what I've lost, yes I understand if you don't a backup then that's your own fault, and yes, I am an idiot.
Now that that's out of the way. I had a data disk go bad in my array, I got a new drive put in mid-day yesterday and then right before I went to sleep I checked the progress one last time and saw this (first image). I knew I was screwed but couldn't deal with it last night. This morning it looks like this (second image).
I'm not going to beg for ways to save the data (I understand it's gone). What I want to do is stem the tide of damage. Should I kill the rebuild and just write off 10TB (old drive was 5TB that I replaced)? How can I do that while saving the remaining data? Again, I know this is my own fault and I've lost a good chunk of data but I would really appreciate any help in saving whatever I can.
-
I love the peace of mind Unraid gives me with my data.
It’s hard to narrow it down to just 1 thing I want to see in 2020 so I won’t:
1. User shares spanning multiple servers (ideally docker-swarm-like capabilities as well)
2. VPN support baked in with a toggle on a per container/VM basis
-
 1
1
-
-
I would like the ability to toggle on a VPN for a given container or VM. Bonus points for:
- Optional kill-switch if VPN drops
- Ability to have multiple containers/vms share the same connection (so 1 client instead of 1 per container/vm)
- Ability to toggle on the VPN for ALL containers and/or ALL VMs
I imagine this would require some VPN/WG config section where you enter in the config for your VPN and name it and then a drop down in the container/vm edit page that lets you choose "No VPN" ,"MY custom VPN 1", etc with a checkbox next to it to kill the internet if the VPN goes down.
-
I tried different browsers and different devices but the GUI stayed in that odd state. Once I was sure the rebuild was complete (mind you the array was accessible this whole time, it just didn't look like it was via the UI) I rebooted the machine through the web UI and everything came up correctly. That was a scary few days where I wasn't sure if it was working or not but it appears it was all fine and just some UI glitch.
Bottom line if your UI looks like my screenshot above then just ride it out until the rebuild is complete then reboot your server.
-
1
-
-
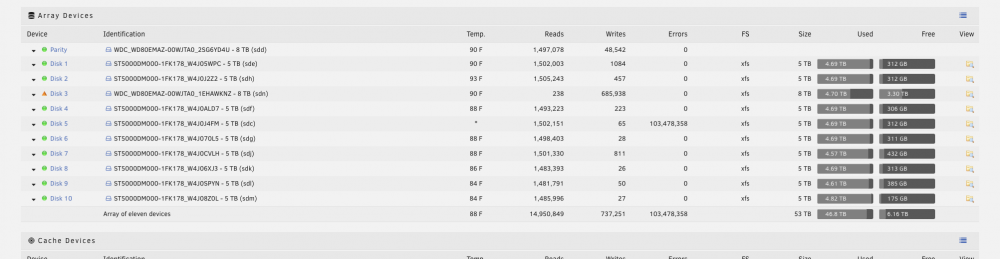
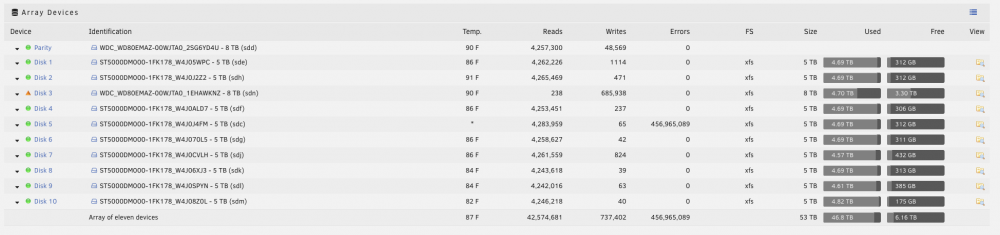
Just noticed a drive was emulated so I wrote down which drive was bad, stopped the array, shutdown the server, replaced the drive (with a bigger one 5->8TB), turned back on the server.
The array started automatically (wasn't expecting that) with the drive marked as missing. I stopped the array and then assigned the new drive to the missing slop and hit "start" on the array.
The page refreshed but all the drives still showed as dropdowns (like I could assign them. Picture: https://www.dropbox.com/s/diymtovifemqemb/Screenshot 2019-09-04 17.47.18.png?dl=0) and the only options at the bottom of the page are "Reboot" and "Powerdown". In the bottom status bar it shows:
Array Stopped•Parity-Sync / Data-Rebuild 0.1 %•stale configuration
(Note it is now up to 0.3% so it IS doing something).
I've never seen this before and in the past when I need to rebuild a drive the bottom section is expanded and show %, time, MB/s, MB total rebuilt, etc.
I googled around but couldn't find anyone describing what I'm seeing. I have attached my diagnosis.
I'm going to leave the server alone but I'm not sure what the stale config error means and if I need to stop the rebuild and do something else first.
-
I might be in the vast minority but I can only run desktop servers (i.e. towers not rack-mount). There are a number of reasons for this: sound, power, space, and knowledge (I’ve built computers since I was I was 14 and have a good grasp on that, SAS/backplane/etc is foreign to me and frankly scares me).
For all of these reasons I’m currently running 3 UnRaid servers. I have one “main” server where all the heavy lifting happens and then 2 “storage” servers that might have 1-2 containers running on them max.
My question is: do you foresee UnRaid as ever supporting “multiple servers acting in coordination”?
I’m fine paying for a license for each (and I have 3 pro license) but storage management across the servers is a pain and it would be nice if they could work together a little better. Currently I just use nfs mounts to the main server but I’m almost always running some rsync command to move data off a full drive/server to another one. Also with things like docker swarm or kubernetes I wonder if there is a better option that what I’m currently doing.
Thank you for an amazing product!
-
 1
1
-
-
I bought this adaptor off Amazon to connect to my APC BACK-UPS XS 1300 as it doesn't have a USB-B port on the back but instead an RJ45 data port. Unfortunately UnRaid can't seem to see it. I followed this guide here to determine my settings. My settings are:
USB Cable: Smart Custom USB Cable: <blank> UPS type: APCsmart Device: /dev/ttyUSB0
I got the device from following this post to find which tty to use:
root@Tower:~# lsusb Bus 002 Device 002: ID 8087:8001 Intel Corp. Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 006 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 005 Device 003: ID 0403:6001 Future Technology Devices International, Ltd FT232 Serial (UART) IC Bus 005 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 001 Device 002: ID 8087:8009 Intel Corp. Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 004 Device 002: ID 174c:3074 ASMedia Technology Inc. ASM1074 SuperSpeed hub Bus 004 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 003 Device 003: ID 174c:2074 ASMedia Technology Inc. ASM1074 High-Speed hub Bus 003 Device 002: ID 0781:5571 SanDisk Corp. Cruzer Fit Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
root@Tower:~# dmesg|grep tty [911515.835262] ftdi_sio ttyUSB0: FTDI USB Serial Device converter now disconnected from ttyUSB0 [911518.353748] usb 5-1: FTDI USB Serial Device converter now attached to ttyUSB0
I'm not sure where to go from here. I'm thinking it might be that my cable isn't compatible but I don't want to spend $40 (practically a battery replacement) for this cable unless I know it will work. I have tried just about every combo of dropdown options on that UPS page but I can't get it to connect. Thank you for any help you can provide.
-
I'm sorry, yes I was using virtio.
Here are my results with the two you mentioned:
e1000-82545em:
Connecting to host <removed>, port 5201 Reverse mode, remote host <removed> is sending [ 4] local <removed> port 43176 connected to <removed> port 5201 [ ID] Interval Transfer Bandwidth [ 4] 0.00-1.00 sec 1.47 MBytes 12.3 Mbits/sec [ 4] 1.00-2.00 sec 4.02 MBytes 33.7 Mbits/sec [ 4] 2.00-3.00 sec 4.59 MBytes 38.5 Mbits/sec [ 4] 3.00-4.00 sec 4.80 MBytes 40.3 Mbits/sec [ 4] 4.00-5.00 sec 5.08 MBytes 42.6 Mbits/sec [ 4] 5.00-6.00 sec 4.39 MBytes 36.8 Mbits/sec [ 4] 6.00-7.00 sec 4.15 MBytes 34.8 Mbits/sec [ 4] 7.00-8.00 sec 4.47 MBytes 37.5 Mbits/sec [ 4] 8.00-9.00 sec 4.35 MBytes 36.5 Mbits/sec [ 4] 9.00-10.00 sec 4.45 MBytes 37.4 Mbits/sec - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bandwidth Retr [ 4] 0.00-10.00 sec 42.7 MBytes 35.8 Mbits/sec 102 sender [ 4] 0.00-10.00 sec 42.5 MBytes 35.7 Mbits/sec receiver iperf Done.
vmxnet3:
Connecting to host <removed>, port 5201 Reverse mode, remote host <removed> is sending [ 4] local <removed> port 37254 connected to <removed> port 5201 [ ID] Interval Transfer Bandwidth [ 4] 0.00-1.00 sec 1.66 MBytes 13.9 Mbits/sec [ 4] 1.00-2.00 sec 6.58 MBytes 55.2 Mbits/sec [ 4] 2.00-3.00 sec 6.60 MBytes 55.3 Mbits/sec [ 4] 3.00-4.00 sec 7.07 MBytes 59.3 Mbits/sec [ 4] 4.00-5.00 sec 7.50 MBytes 62.9 Mbits/sec [ 4] 5.00-6.00 sec 7.59 MBytes 63.7 Mbits/sec [ 4] 6.00-7.00 sec 7.16 MBytes 60.1 Mbits/sec [ 4] 7.00-8.00 sec 8.00 MBytes 67.1 Mbits/sec [ 4] 8.00-9.00 sec 5.04 MBytes 42.3 Mbits/sec [ 4] 9.00-10.00 sec 5.68 MBytes 47.6 Mbits/sec - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bandwidth Retr [ 4] 0.00-10.00 sec 63.8 MBytes 53.5 Mbits/sec 59 sender [ 4] 0.00-10.00 sec 63.8 MBytes 53.5 Mbits/sec receiver iperf Done.
So I'll stick with the vmxnet3 for now. Is there a list of these types somewhere so I can research/try some more? Thank you for all your help and I'm sorry I didn't understand your original question.
-
I am running Ubuntu 18.04.2 LTS (GNU/Linux 4.15.0-23-generic x86_64) in the VM and I'm using Br0 network bridge.
-
I have been thinking for years that my German host was throttling me or it was my ISP but due to a completely separate issue I found something pretty damning. I ran iperf3 out on my German host (iperf3 -s) and then ran the client from my MacBook, my unraid machine, and the VM in my unraid machine. My MBP and Unraid host performed the same so I'll just post one.
Here is the command I used:
iperf3 -c <IP-OF-GERMAN-SERVER> -ub 1G -R
Host:
Connecting to host <REMOVED>, port 5201 Reverse mode, remote host <REMOVED> is sending [ 4] local <REMOVED> port 38896 connected to <REMOVED> port 5201 [ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams [ 4] 0.00-1.00 sec 46.6 MBytes 391 Mbits/sec 0.027 ms 3655/37428 (9.8%) [ 4] 1.00-2.00 sec 54.0 MBytes 453 Mbits/sec 0.027 ms 2758/41888 (6.6%) [ 4] 2.00-3.00 sec 58.2 MBytes 488 Mbits/sec 0.031 ms 1/42115 (0.0024%) [ 4] 3.00-4.00 sec 54.3 MBytes 456 Mbits/sec 0.035 ms 2323/41664 (5.6%) [ 4] 4.00-5.00 sec 57.2 MBytes 480 Mbits/sec 0.035 ms 15769/57181 (28%) [ 4] 5.00-6.00 sec 55.6 MBytes 467 Mbits/sec 0.043 ms 40686/80979 (50%) [ 4] 6.00-7.00 sec 56.9 MBytes 477 Mbits/sec 0.044 ms 40272/81477 (49%) [ 4] 7.00-8.00 sec 54.4 MBytes 456 Mbits/sec 0.044 ms 43713/83089 (53%) [ 4] 8.00-9.00 sec 56.8 MBytes 476 Mbits/sec 0.032 ms 41376/82486 (50%) [ 4] 9.00-10.00 sec 54.9 MBytes 460 Mbits/sec 0.035 ms 43178/82930 (52%) - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams [ 4] 0.00-10.00 sec 1.12 GBytes 960 Mbits/sec 0.042 ms 333027/828960 (40%) [ 4] Sent 828960 datagrams iperf Done.
VM:
Connecting to host <REMOVED>, port 5201 Reverse mode, remote host <REMOVED> is sending [ 4] local <REMOVED> port 52061 connected to <REMOVED> port 5201 [ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams [ 4] 0.00-1.00 sec 37.2 MBytes 312 Mbits/sec 0.141 ms 4022/8789 (46%) [ 4] 1.00-2.00 sec 40.8 MBytes 342 Mbits/sec 0.130 ms 3944/9163 (43%) [ 4] 2.00-3.00 sec 41.1 MBytes 345 Mbits/sec 0.217 ms 4276/9539 (45%) [ 4] 3.00-4.00 sec 40.1 MBytes 336 Mbits/sec 0.109 ms 4021/9154 (44%) [ 4] 4.00-5.00 sec 44.5 MBytes 373 Mbits/sec 0.122 ms 3001/8693 (35%) [ 4] 5.00-6.00 sec 28.4 MBytes 238 Mbits/sec 0.225 ms 6518/10157 (64%) [ 4] 6.00-7.00 sec 3.80 MBytes 31.9 Mbits/sec 0.389 ms 13215/13701 (96%) [ 4] 7.00-8.00 sec 2.62 MBytes 22.0 Mbits/sec 0.271 ms 14396/14731 (98%) [ 4] 8.00-9.00 sec 3.51 MBytes 29.4 Mbits/sec 0.184 ms 14265/14714 (97%) [ 4] 9.00-10.00 sec 3.35 MBytes 28.1 Mbits/sec 0.304 ms 13905/14334 (97%) - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams [ 4] 0.00-10.00 sec 1.13 GBytes 969 Mbits/sec 0.253 ms 115659/147876 (78%) [ 4] Sent 147876 datagrams iperf Done.
As you can see they both start out strong (the host is stronger but still 300Mb/s is not terrible) but then the VM takes a 10x nosedive. I've seen similar things using rsync on the VM countless times and wrote it off.
What could cause this? I setup this VM back when I first installed Unraid years ago and its network bridge in the VM settings is set to br0.
-
Not sure if this really qualifies as unraid specific but I'd love to hear how you all are handling this.
I set my TM share to be 3TB and a week or so ago it filled up. I still have around 6TB free on my server and while I can just increase the size I'd really like to prune it as my laptop is only 1TB and not even full. I have cloud and clone backups of my laptop as well so TM is not my primary backup so I'm ok if I don't have every version of a file back to the beginning of time. So how you clean out older backups safety?
-
Just now, John_M said:
It isn't obvious from your last post what your decision was - aborting the mover or leaving it to run its course. Personally, and having let it run for so long, I would just let it continue. Assuming, of course, that diagnostics don't reveal any problems.
I ended up stopping it "mover stop" and then I used rsync to copy the files over. That process is still going but already I've moved 20GB more in less than 3 hours so I'm probably going to move my appdata folder by hand with rsync then let mover run again to move my VM/Docker/etc since those things are big size-wise but only a handful of files.
Just to anyone that runs across this the command I am using is:
rsync -Pavh --remove-source-files /mnt/user0/appdata/ /mnt/cache/appdata/This won't remove the directories (of which I have MANY nested) but it will clear the files out behind it. My plan is to then just "rm -rf" each folder inside of appdata once I've doubled checked they are all empty.





{kind=link}
How do you disable SSH password login on 6.9+?
in General Support
Posted
So I just found this thread and removing/commenting out `PermitRootLogin yes` does prevent password login. SSH will still prompt for the password (odd, I've never seen this before when I've setup a server to be key-only) but it will not accept the correct root password. I guess this is better than nothing but it's frustrating that I had this working perfectly before upgrading and now sshd doesn't appear to respect the config I give it (notably `PubkeyAuthentication yes` and `PasswordAuthentication no`).